1. Estrutura de armazenamento lógico:


Espaço de tabela (arquivo ibd): Uma instância do Mysql pode corresponder a vários espaços de tabela para armazenar registros, índices e outros dados.
Segmento: dividido em segmento de dados, segmento de índice, segmento de reversão,
InnoDB é uma tabela de organização de índice, o segmento de dados é o nó folha da árvore B+, o segmento de índice é o nó não folha da árvore B+ e o segmento é usado para gerenciar várias áreas (Extensão)
Área: A estrutura da unidade no espaço da tabela. O tamanho de cada área é 1M. Por padrão, o tamanho da página do mecanismo de armazenamento InnoDB é 16K, ou seja, há 64 páginas consecutivas em uma área.
Página: É a menor unidade de gerenciamento de disco do mecanismo de armazenamento InnoDB. Cada tamanho de página é de 16 KB. Para garantir a continuidade da página, o mecanismo de armazenamento InnoDB aplica-se a 4-5 áreas do disco a cada vez.
Linha: o mecanismo de armazenamento InnoDB é armazenado por linha
Trx_id: Sempre que um registro for alterado, o ID da transação correspondente será atribuído à coluna oculta trx_id, que é o ID da última transação da operação
Roll_pointer: Toda vez que um registro for modificado, a versão antiga será gravada no log de desfazer, e então esta coluna oculta é equivalente a um ponteiro, através do qual as informações antes da modificação do registro podem ser encontradas
2. Arquitetura InnoDB

2.1 Estrutura da memória
2.1.1 BufferPool: buffer pool
O pool de buffer é uma área da memória que pode armazenar em cache os dados reais que são frequentemente operados no disco. Ao realizar adições, exclusões, modificações e consultas, os dados no pool de buffer serão operados primeiro (se não houver dados no buffer neste momento, eles serão carregados do disco e do cache) e, em seguida, atualize o disco em uma determinada frequência ou regra para reduzir o número de IOs do disco e acelerar o processamento.
Se não houver buffer, todas as operações de adição, exclusão, modificação e consulta operarão no espaço em disco e haverá um grande número de IOs de disco. Nos negócios, IO de disco é IO aleatório, que consome muito tempo e consumindo desempenho, por isso é necessário reduzir o disco IO tanto quanto possível.
A unidade de processamento do buffer pool é uma página, e a camada inferior usa uma estrutura de dados de lista encadeada para gerenciar a página. De acordo com o estado, a página é dividida em três tipos:
- página livre: página livre, não usada
- página limpa: página usada, os dados não foram modificados
- Página suja: página suja, página usada, dados foram modificados e os dados são inconsistentes com os dados no disco
2.2.2 Alterar Buffer: Alterar o buffer
Ao executar uma instrução DML, se as páginas de dados não estiverem no Buffer Pool, o disco não será operado diretamente, mas as alterações de dados atuais serão armazenadas no Change Buffer (buffer de alteração) e quando os dados forem lidos no future e, em seguida, mescle e restaure os dados no Buffer Pool e, em seguida, atualize os dados mesclados no disco.
Função: Cada operação de disco causará muito disco IO. Com ChangeBuffer, o processo de mesclagem pode ser executado no buffer pool, o que reduzirá bastante o disco IO
2.2.3 Índice de hash adaptável:
O índice de hash adaptável é usado para otimizar a consulta de dados do Buffer Pool (buffer pool). O InnoDB monitorará a consulta de cada página de índice na tabela e criará um índice de hash se descobrir que o índice de hash pode melhorar a velocidade. Nota: O índice Adaptive Hash, sem intervenção manual, é preenchido automaticamente pelo sistema de acordo com a situação.
O índice de hash adaptável possui uma opção de sinalizador para definir se deve ser ativado: adaptive_hash_index.
2.2.4 Buffer de log: buffer de log
Buffer de log, salve os dados de log (redo log, undo log) para serem gravados no disco, o padrão é 16 MB, o log será atualizado periodicamente no disco, se você precisar atualizar, inserir ou excluir muitas linhas de transações, aumentar o tamanho do buffer de log Pode salvar disco IO
parâmetro:
InnoDB_log_buffer_size: tamanho do buffer,
InnoDB_flush_log_at_trx_commit: Quando o log é liberado para o disco (esse parâmetro tem 3 valores: 1, 0, 2)
1. Toda vez que uma transação é confirmada, ela é descarregada no disco
0. Os logs são gravados e liberados no disco a cada segundo
2. Depois que cada transação é confirmada, ela é atualizada no disco a cada segundo
2.2 Estrutura do disco
2.2.1 Tablespace do sistema: O tablespace do sistema é a área de armazenamento do [Change Buffer ] na estrutura de memória. Parâmetros: innodb_data_file_path
2.2.2 Espaço de tabela de arquivo por tabela: O espaço de tabela de cada arquivo de tabela contém os dados e índices de uma única tabela InnoDB e é armazenado em um único arquivo de dados no sistema de arquivos. Parâmetro: innodb_file_per_table (ativado por padrão)
2.2.3 Tablespace Geral: Tablespace geral , que precisa ser criado através da sintaxe create TableSpace, que pode ser especificada ao criar uma tabela. (equivalente ao fato de que podemos criar manualmente o espaço de tabela e, em seguida, especificar o espaço de tabela que criamos manualmente ao criar uma nova tabela)
2.2.4 Undo Tablespace: undo tablespace , a instância do MySQL criará automaticamente dois tablespaces de undo padrão (padrão 16 MB) durante a inicialização para armazenar logs de log de undo.
2.2.5 Espaço de tabela temporário: espaço de tabela temporário , InnoDB usará espaço de tabela temporário de sessão e espaço de tabela temporário global para armazenar dados de tabela temporária criados por usuários, etc.
2.2.6 Arquivos de buffer de gravação dupla: Buffer de gravação dupla Antes de o mecanismo InnoDB liberar a página de dados do pool de buffers para o disco, ele primeiro grava a página de dados no arquivo de buffer de gravação dupla, o que é conveniente para a recuperação de dados quando o sistema está anormal.
2.2.7 Redo Log: Redo log , que realiza a persistência das transações, consiste em redo log buffer (redo buffer) e redo log file (redo log) , o primeiro fica na memória e o segundo no disco. Quando a transação for confirmada, todas as informações de modificação serão colocadas no log, que é usado para recuperação de dados quando ocorrem erros ao liberar páginas sujas no disco.
2.3 Tópicos de fundo
Função: atualizar os dados no pool de buffer InnoDB para o arquivo de disco no momento certo.
2.3.1 Linha Mestra
O thread principal de segundo plano é responsável por agendar outros threads e também por atualizar assincronamente os dados no buffer pool para o disco para manter a consistência dos dados.Também inclui atualizar páginas sujas, mesclar e inserir caches e reciclar páginas de desfazer.
2.3.2 Segmento IO
No mecanismo de armazenamento InnoDB, o AIO é amplamente usado para processar solicitações de IO, o que pode melhorar muito o desempenho do banco de dados, e o IO Thread é o principal responsável pelo retorno de chamada dessas solicitações de IO

2.3.3 Linha de Purga
É usado principalmente para reciclar o log de desfazer que foi enviado pela transação. Após a confirmação da transação, o log de desfazer não pode ser usado, por isso é usado para reciclar
2.3.4 Limpador de página
Um thread que auxilia o Master Thread a liberar páginas sujas no disco, o que pode reduzir a pressão de trabalho do Master Thread e reduzir o bloqueio
3. Princípio de negócios
Uma transação é uma coleção de operações. É uma unidade de trabalho indivisível. Uma transação envia ou revoga uma solicitação de operação para o sistema como um todo. Essas operações são bem-sucedidas ou falham ao mesmo tempo .
1. Atomicidade Uma transação deve ser considerada como uma unidade mínima indivisível. Todas as operações em toda a transação são submetidas com sucesso ou falham. Para uma transação, é impossível realizar apenas parte das operações
2. Consistência (Consistency) Se o banco de dados é consistente antes de executar a transação, então o banco de dados ainda é consistente após a execução da transação;
3. Isolamento As operações de transações são independentes e transparentes, sem afetar umas às outras. As transações são executadas de forma independente. Isso geralmente é obtido usando bloqueios. Se o resultado do processamento de uma transação afetar outras transações, outras transações serão retiradas. 100% de isolamento de transações requer sacrifício de velocidade.
4. Durabilidade (Durability) Uma vez que a transação é confirmada, o resultado é permanente. Mesmo que ocorra uma falha no sistema, ela pode ser recuperada.
Atomicidade, consistência e durabilidade são controladas por redolog e undo log
O isolamento é controlado por fechaduras e MVCC
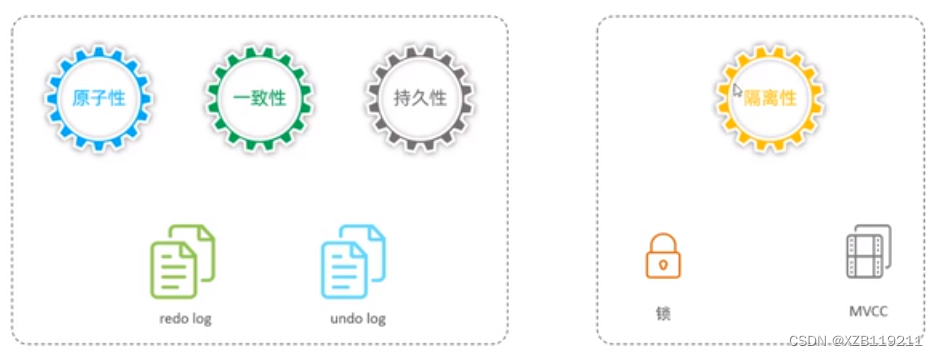
—> A persistência é garantida pelo redo log
Redo Log: redo log, que realiza a persistência das transações. É composto por redo log (redo buffer) e redo log (redo log). O primeiro fica na memória e o segundo no disco. Após o commit da transação, todos os as informações de modificação são colocadas no log, que é usado para recuperação de dados quando ocorre um erro ao liberar páginas sujas no disco.

Explicação: A figura mostra o mecanismo de processamento no InnoDB para garantir a persistência da transação depois que uma transação é confirmada. Primeiro, depois que a transação é confirmada, ela irá para a página de dados correspondente no Buffer Pool na estrutura de memória para modificar o dados. Aguarde a operação, após a conclusão da operação, a transação na memória foi executada neste momento, mas não foi atualizada no disco a tempo, a página de dados atualizada na memória atual é chamada de página suja, e quando a operação é executada no Buffer Pool, a página de dados na memória Todas as operações serão gravadas no Redolog Buffer na área e, em seguida, atualizadas periodicamente para o Redo Log no disco pelo thread de segundo plano e, em seguida, quando um ocorre quando os dados no Buffer Pool são atualizados para o disco, os dados podem ser processados por meio do Redo Log na recuperação do disco. Quando os dados do Buffer Pool são sincronizados corretamente com o disco, o redolog no disco é inútil, portanto, os dois redologs no disco são copiados um para o outro para obter atualizações oportunas. Este método de gravar primeiro os logs e depois sincronizar os dados é chamado de WAL (Write-Ahead Log)
Então, por que se preocupar, primeiro escreva no Redolog Buffer e depois transfira para o Redo Log, não seria suficiente atualizar os dados do Buffer Pool para o disco após cada transação? Há um problema aqui. A maioria das operações nas páginas de dados em uma transação são aleatórias. Se cada transação for imediatamente liberada para o disco, vários IOs de disco serão gerados, o que consumirá muito desempenho. Portanto, passamos Redolog garante dados persistência dessa forma.
—> A atomicidade é garantida pelo registro de desfazer
log de desfazer: log de reversão, usado para registrar as informações antes que os dados sejam modificados, a função inclui: fornecer reversão e MVCC (simultaneidade de controle de várias versões)
Desfazer log e redo log registram logs físicos de maneira diferente. É um log lógico. Pode-se considerar que quando um registro é excluído, um registro de inserção correspondente será gravado no log de undo e vice-versa. Quando um registro é atualizado, um registro correspondente será gravado. registros de atualização, ao executar a reversão, você pode ler o conteúdo correspondente dos registros lógicos no log de desfazer e reverter.
Destruição do log de undo: É gerado quando a transação é executada. Quando a transação é confirmada, o log de undo não será excluído imediatamente. Esses logs também podem ser usados para MVCC.
Armazenamento de log de desfazer: É gerenciado e registrado na forma de segmentos, armazenados no segmento de rollback rollback, que contém 1024 segmentos de log de desfazer.
4、MVCC
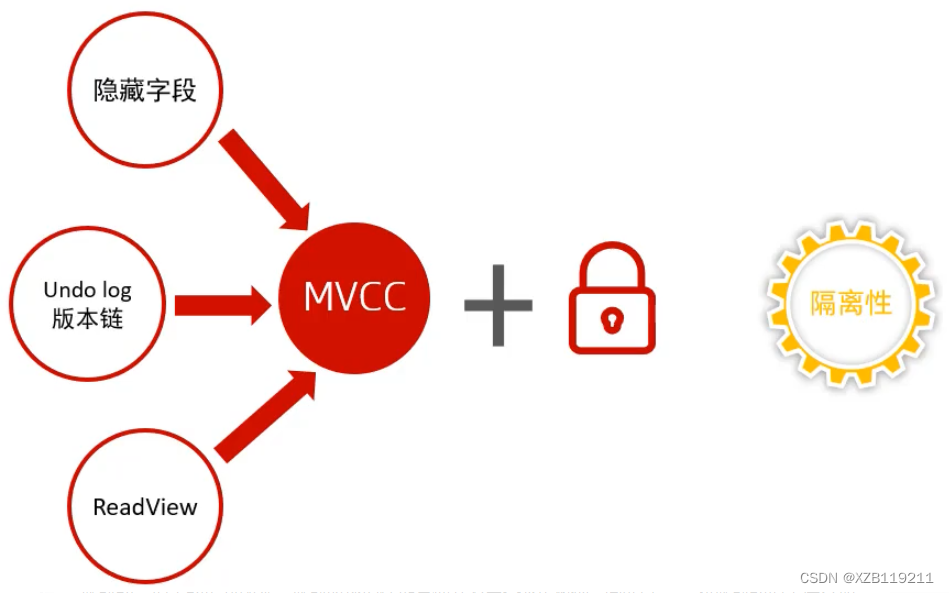
4.1 Conceito
O que é MVCC?
O MVCC é para gerenciar várias versões de dados ao acessar o banco de dados simultaneamente, para evitar o bloqueio da solicitação de leitura de dados devido à necessidade de adicionar um bloqueio de gravação ao gravar dados, resultando no problema de que os dados não podem ser lidos ao gravar dados.
Em termos leigos, o MVCC salva a versão histórica dos dados e decide se deseja exibir os dados de acordo com o número da versão dos dados comparados. Ele pode obter o efeito de isolamento da transação sem adicionar um bloqueio de leitura e, finalmente, pode ler os dados Modifique ao mesmo tempo, ao modificar os dados, você pode lê-los ao mesmo tempo, o que melhora muito o desempenho de simultaneidade das transações.
4.2 Principais pontos de conhecimento da implementação do InnoDB MVCC
4.2.1 Número da versão da transação
Antes de cada transação ser iniciada, um ID de transação de aumento automático será obtido do banco de dados e a ordem de execução das transações pode ser julgada a partir do ID da transação.
4.2.2 Colunas ocultas de tabelas
| DB_TRX_ID | Registre o ID da transação da transação de dados; |
| DB_ROLL_PTR | Ponteiro para o ponteiro de posição dos dados da versão anterior no log de desfazer; |
| DB_ROW_ID | ID oculto, ao criar uma tabela sem um índice adequado como um índice clusterizado, o ID oculto será usado para criar um índice clusterizado; |
4.2.3 Registro de desfazer
Undo Log é usado principalmente para registrar o log antes que os dados sejam modificados. Antes que as informações da tabela sejam modificadas, os dados serão copiados para o log de undo. Quando a transação for revertida, os dados no log de undo podem ser restaurados.
Finalidade do registro de desfazer
(1) Garantir a atomicidade e consistência quando a transação é revertida.Quando a transação é revertida, os dados do log de desfazer podem ser usados para recuperação.
(2) Os dados usados para a leitura do instantâneo MVCC. No controle de várias versões do MVCC, ao ler os dados da versão histórica do log de desfazer, diferentes números de versão da transação podem ter suas próprias versões de dados instantâneos independentes.
4.2.4 Relação entre o número da versão da transação, a coluna oculta da tabela e o log de desfazer
Usamos um processo de simulação de modificação de dados para entender a relação entre o número da versão da transação, colunas ocultas e undolog
(1) Primeiro prepare uma tabela de dados original
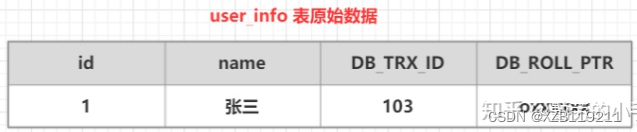
(2) Inicie uma transação A: execute update user_info set name = "Li Si" onde id=1 na tabela user_info, e o seguinte processo será executado
| 1. Primeiro obtenha um número de transação 104 |
| 2. Copie os dados antes da modificação da tabela user_info para o log de desfazer |
| 3. Modifique os dados da tabela user_info id=1 |
| 4. Altere o número da versão da transação de dados modificados para o número da versão da transação atual e aponte o endereço DB_ROLL_PTR para o endereço dos dados do log de desfazer. |
(3) O resultado da execução final é mostrado na figura

4.2.5 cadeia de versão undolog
Modificar o mesmo registro por transações diferentes ou a mesma transação fará com que o log de desfazer do registro gere uma lista vinculada da versão do registro. registro.

4.2.6 Visualização de leitura
Depois que cada transação for aberta no InnoDB, você obterá uma (visualização de leitura). A cópia salva principalmente os números de ID das transações que estão ativas (sem commit) no sistema de banco de dados atual.Na verdade, simplesmente falando, essa cópia salva uma lista de outros IDs de transação no sistema que não devem ser vistos por essa transação. ( A cada transação aberta, será atribuído um ID a ela, que é incrementado, de forma que a última transação tenha um valor de ID maior )
Portanto, sabemos que Read View é usado principalmente para julgamento de visibilidade, ou seja, quando executamos uma leitura instantânea para uma determinada transação, criamos uma exibição de leitura Read View para o registro e comparamos com uma condição para julgar se a transação atual pode ver Qual versão dos dados pode ser os dados atuais mais recentes ou uma determinada versão dos dados no log de desfazer registrado nesta linha.
O Read View segue um algoritmo de visibilidade, tirando principalmente o DB_TRX_ID (ou seja, o ID da transação atual) no último registro dos dados a serem modificados e comparando-o com os IDs de outras transações ativas no sistema (mantido pelo Read View ), se DB_TRX_ID segue Os atributos de Read View fizeram algumas comparações, que não estão em conformidade com a visibilidade, então use o ponteiro de reversão DB_ROLL_PTR para tirar o DB_TRX_ID no Undo Log e compare-os novamente, ou seja, percorra o DB_TRX_ID de a lista encadeada (do início da cadeia até o final da cadeia, ou seja, do Modificar e verificar mais recente), até encontrar um DB_TRX_ID que atenda a certas condições, então o registro antigo onde este DB_TRX_ID está localizado é o última versão antiga que a transação atual pode ver
Várias propriedades importantes da Visualização de Leitura:
| m_ids: conjunto de número de versão de transação ativo (não confirmado) do sistema atual |
| min_trx_id: ID mínimo de transação ativa |
| max_trx_id: ID de transação pré-alocado, o ID de transação máximo atual+1 (porque o ID de transação é autoincrementado) |
| Creator_trx_id: Cria o número da versão da transação da visualização de leitura atual |
Leia as condições de correspondência de visualização:

1. ID da transação de dados==creator_trx_id
Se estabelecido, você pode acessar esta versão, indicando que os dados foram alterados pela transação atual
2. Se o ID da transação de dados for <min_trx_id, ele será exibido
Se o ID da transação de dados for menor que o ID mínimo da transação ativa na visualização de leitura, é certo que os dados já existiam antes da transação atual ser iniciada, para que possam ser exibidos.
3. ID da transação de dados>=max_trx_id não será exibido
Se o ID da transação de dados for maior que o ID máximo da transação do sistema atual na exibição de leitura, isso significa que os dados são gerados após a criação da exibição de leitura atual, portanto, os dados não serão exibidos.
4. Se min_trx_id<=ID da transação de dados<max_trx_id, corresponde ao conjunto de transações ativas trx_ids
Se o ID da transação dos dados for maior que o menor ID da transação ativa e menor ou igual ao maior ID da transação do sistema, essa situação indica que os dados podem não ter sido enviados quando a transação atual foi iniciada.
Portanto, neste momento, precisamos corresponder ao ID da transação dos dados com o conjunto trx_ids da transação ativa na visualização de leitura atual:
Caso 1: Se o ID da transação não existir na coleção trx_ids (isso significa que a transação foi confirmada quando a exibição de leitura é gerada), os dados neste caso podem ser exibidos.
Caso 2: Se o ID da transação existir em trx_ids, significa que os dados não foram enviados quando a visualização de leitura é gerada, mas se o ID da transação dos dados for igual a Creator_trx_id, significa que os dados são gerados pelo a própria transação atual, e os dados gerados por si podem ser vistos por si mesmos, portanto, neste caso, os dados também podem ser exibidos.
Caso 3: Se o ID da transação existir em trx_ids e não for igual a Creator_trx_id, significa que os dados não foram enviados quando a visualização de leitura é gerada e não são gerados por si só, portanto, os dados não podem ser exibidos neste caso .
5. Quando a condição de exibição de leitura não é satisfeita, os dados são obtidos do registro de desfazer
Quando o ID da transação dos dados não atende à condição de exibição de leitura, a versão histórica dos dados é obtida do log de desfazer e, em seguida, o número da transação da versão histórica dos dados é correspondido com a condição de exibição de leitura até que uma parte dos dados históricos que atendem à condição são encontrados ou, se não forem encontrados, retorna um resultado vazio;
4.3 O princípio do InnoDB implementando MVCC

4.3.1 Simular o processo de implementação do MVCC
Abaixo simulamos o fluxo de trabalho do MVCC abrindo duas transações simultâneas.
(1) Crie uma tabela user_info e insira um dado de inicialização

(2) A transação A e a transação B modificam e consultam user_info ao mesmo tempo
Transação A: atualizar user_info set name = "Lisi"
Transação B: selecione * fom user_info onde id=1
pergunta:
Inicie a transação A primeiro e execute a transação B depois que a transação A modificar os dados, mas não confirmar. Qual é o resultado final do retorno.
O fluxo de execução é o seguinte:

A descrição do fluxo de execução na figura acima:
1. Transação A: Para iniciar uma transação, primeiro obtenha um número de transação 102;
2. Transação B: Abra a transação e obtenha o número da transação 103;
3. Transação A: Para modificar a operação, primeiro copie os dados originais para o log de desfazer, depois modifique os dados, marque o número da transação e o endereço da última versão dos dados no log de desfazer.

4. Transação B: Neste momento, a transação B obtém uma visualização de leitura e o valor correspondente da visualização de leitura é o seguinte

5. Transação B: Execute a instrução de consulta e os dados modificados da transação A são obtidos neste momento

6. Transação B: Correspondência de dados com exibição de leitura

Verificou-se que as condições de exibição da exibição de leitura não foram atendidas, portanto, os dados da versão histórica são obtidos de undo lo e, em seguida, combinados com a exibição de leitura e, finalmente, os dados retornados são os seguintes.

4.4 Leitura instantânea e leitura atual
Lendo atualmente:
O que é lido é a versão mais recente do registro. Ao ler, deve-se garantir que outras transações simultâneas não possam modificar o registro atual e o registro lido será bloqueado. Para operações diárias, como: selecionar ... bloquear no modo de compartilhamento (bloqueio compartilhado), selecionar ... para atualizar, atualizar, inserir, excluir (bloqueio exclusivo) são todos lidos atuais
Leitura instantânea:
Uma seleção simples (sem bloqueio) é uma leitura de instantâneo. A leitura de instantâneo lê a versão visível dos dados registrados, que podem ser dados históricos. Desbloqueado é um bloqueio sem bloqueio
Leitura confirmada: toda vez que é selecionada, uma leitura de instantâneo é gerada
Leitura repetível: a primeira instrução select após iniciar a transação é onde o instantâneo é lido
Serializável: a leitura do instantâneo degenerará na leitura atual
Existem três tipos de cenários de simultaneidade de banco de dados:
read-read: sem problemas e sem necessidade de controle de concorrência
Leitura-gravação: há problemas de segurança de encadeamento, que podem causar problemas de isolamento de transação e podem encontrar leituras sujas, leituras fantasmas e leituras não repetíveis
Write-write: há problemas de segurança de encadeamento e pode haver problemas com atualizações perdidas, como a primeira categoria