guia
Este artigo foi compilado a partir do compartilhamento de tópicos de mesmo nome sobre infraestrutura de IA na QCon Global Software Development Conference (Beijing Station) em fevereiro de 2023. Aplicativos como ChatGPT, Bard e o "Wen Xin Yi Yan" que irão atender você são todos baseados nos grandes modelos lançados por cada fabricante. O GPT-3 possui 175 bilhões de parâmetros e o modelo grande Wenxin possui 260 bilhões de parâmetros. Tomando como exemplo o uso da GPU NVIDIA A100 para treinar GPT-3, teoricamente, leva 32 anos para uma única placa, e um cluster distribuído com escala de quilocalorias, após várias otimizações, ainda precisa de 34 dias para concluir o treinamento. Este discurso apresentou os desafios do treinamento de modelo em grande escala para infraestrutura, como paredes de poder de computação, paredes de armazenamento, design de rede de alto desempenho de máquina única e cluster, acesso a gráficos e aceleração de back-end, divisão e mapeamento de modelos, etc., Baidu compartilhado O método de resposta e a prática de engenharia da nuvem inteligente construíram uma infraestrutura de pilha completa da estrutura ao cluster, combinando software e hardware e acelerando o treinamento de ponta a ponta de grandes modelos.
Nos últimos dois anos, o grande modelo teve o maior impacto na arquitetura de tecnologia de IA. No processo de geração, iteração e evolução de grandes modelos, ele apresenta novos desafios para a infraestrutura subjacente.
O compartilhamento de hoje é dividido principalmente em quatro partes: a primeira parte é apresentar as principais mudanças trazidas pelo grande modelo do ponto de vista dos negócios. A segunda parte é sobre os desafios que o treinamento de modelos grandes representa para a infraestrutura na era dos modelos grandes e como o Baidu Smart Cloud responde. A terceira parte é combinar as necessidades de modelos em grande escala e construção de plataformas e explicar a otimização conjunta de software e hardware feita pelo Baidu Smart Cloud. A quarta parte são os pensamentos do Baidu Smart Cloud sobre o desenvolvimento futuro de grandes modelos e novos requisitos para infraestrutura.

1. GPT-3 abre a era dos modelos grandes
A era dos grandes modelos foi inaugurada pelo GPT-3, que possui as seguintes características:
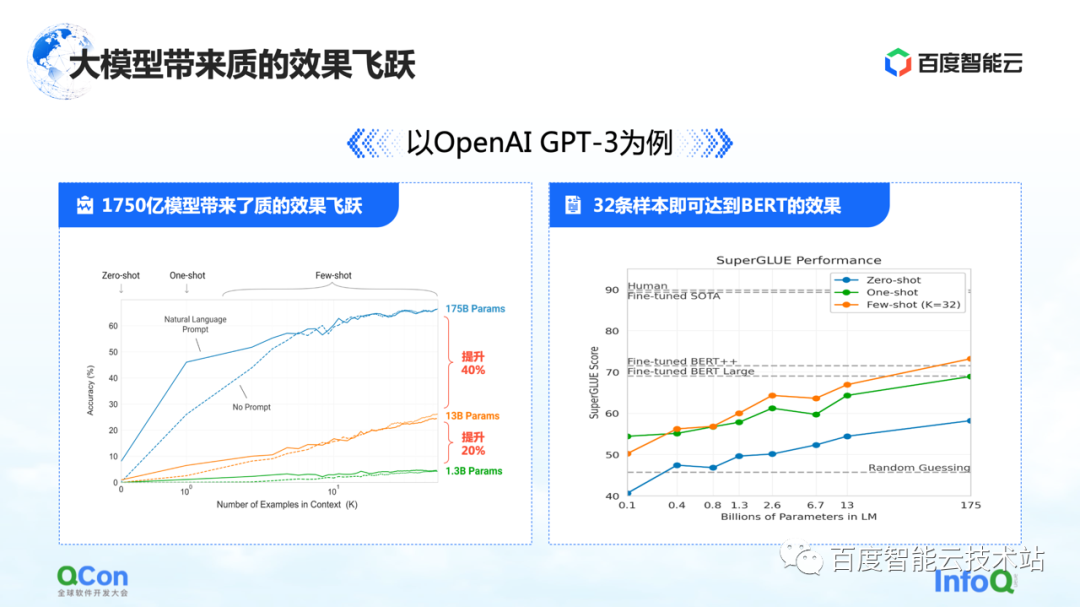
A primeira característica é que os parâmetros do modelo foram muito melhorados.Um único modelo atingiu 175 bilhões de parâmetros, o que também trouxe um aumento significativo na precisão. Na figura à esquerda, podemos ver que com mais e mais parâmetros do modelo, a precisão do modelo também está melhorando.
A imagem à direita mostra suas características mais chocantes: com base no modelo pré-treinado de 175 bilhões de parâmetros, ele só precisa ser treinado com um pequeno número de amostras e pode se aproximar do efeito do BERT após usar um grande treinamento de amostras. Isso reflete em certa medida que a escala do modelo se torna maior, o que pode trazer melhorias no desempenho e na versatilidade do modelo.
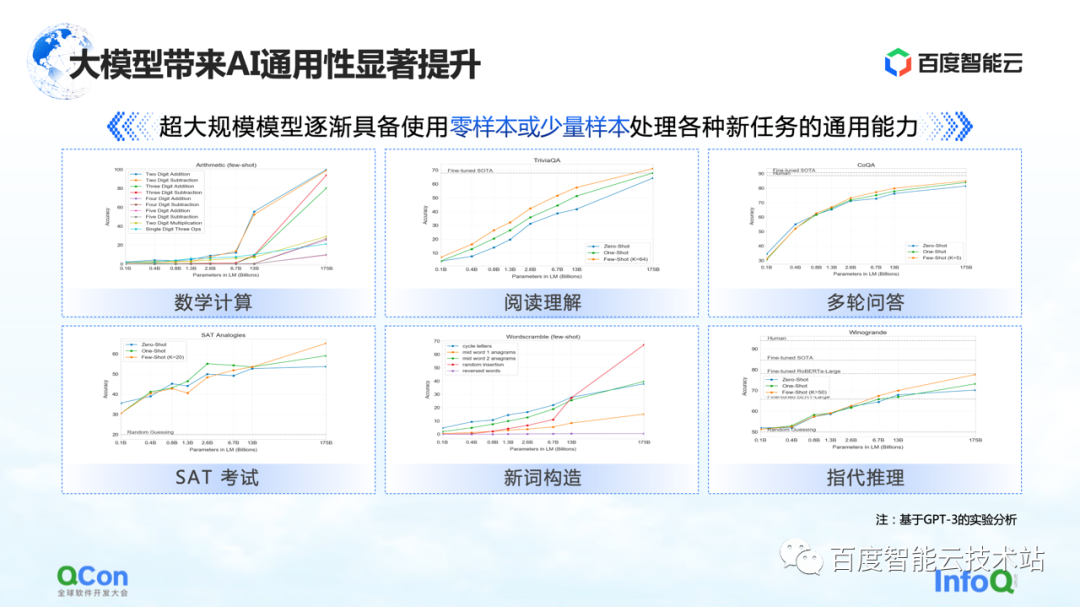
Além disso, o GPT-3 também mostra um certo grau de versatilidade em tarefas como cálculos matemáticos, compreensão de leitura e várias rodadas de perguntas e respostas. Apenas um pequeno número de amostras pode fazer com que o modelo alcance maior precisão, mesmo próximo da precisão humana .
Por causa disso, o modelo grande também trouxe novas mudanças no modelo geral de pesquisa e desenvolvimento de IA. No futuro, podemos pré-treinar um modelo grande primeiro e, em seguida, executar o ajuste fino com um pequeno número de amostras para tarefas específicas para obter bons resultados de treinamento. Em vez de treinar o modelo como agora, cada tarefa precisa ser completamente iterada e treinada do zero.
O Baidu começou a treinar modelos grandes muito cedo, e o modelo grande Wenxin com 260 bilhões de parâmetros foi lançado em 2021. Agora, com difusão estável, gráfico AIGC Vincent e o recentemente popular robô de bate-papo ChatGPT, etc., que atraíram a atenção de toda a sociedade, todos realmente percebem que a era dos modelos grandes chegou.
Os fabricantes também estão lançando produtos relacionados a modelos grandes: o Google acaba de lançar o Bard antes e o Baidu lançará em breve "Wen Xin Yi Yan" em março.
Quais são as diferentes características do treinamento de modelos grandes?
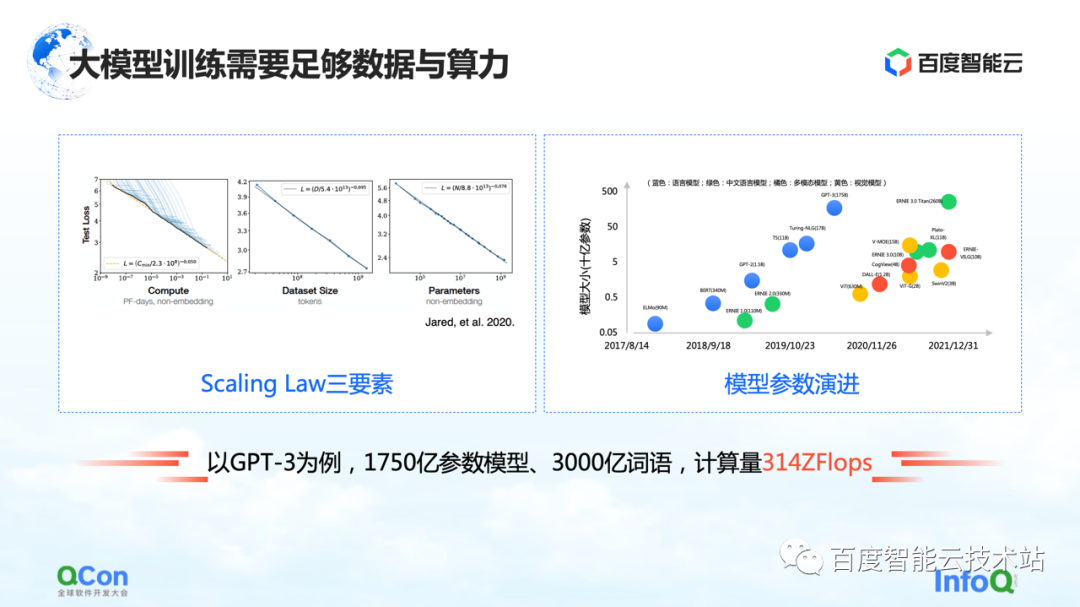
O modelo grande tem uma Lei de Escala, conforme mostrado na figura à esquerda, à medida que a escala do parâmetro do modelo e os dados de treinamento aumentam, o efeito se torna cada vez melhor.
Mas há uma premissa aqui, os parâmetros devem ser grandes o suficiente e o conjunto de dados é suficiente para suportar o treinamento de todo o parâmetro. A consequência disso é que a quantidade de cálculos aumenta exponencialmente. Para um modelo pequeno comum, uma única máquina e um único cartão podem ser feitos. Mas para um modelo grande, seus requisitos de volume de treinamento exigem recursos de grande escala para suportar seu treinamento.
Tomando o GPT-3 como exemplo, é um modelo com 175 bilhões de parâmetros e precisa de 300 bilhões de palavras de treinamento para apoiá-lo para obter um bom efeito. Seu cálculo é estimado em 314 ZFLOPs no papel. Comparado com NVIDIA GPU A100, um cartão ainda tem apenas 312 TFLOPS AI de poder de computação, e o valor absoluto no meio é diferente em 9 ordens de magnitude.
Portanto, para melhor suportar o cálculo, treinamento e evolução de grandes modelos, como projetar e desenvolver a infraestrutura tornou-se uma questão muito importante.
2. Panorama da infraestrutura do modelo em grande escala
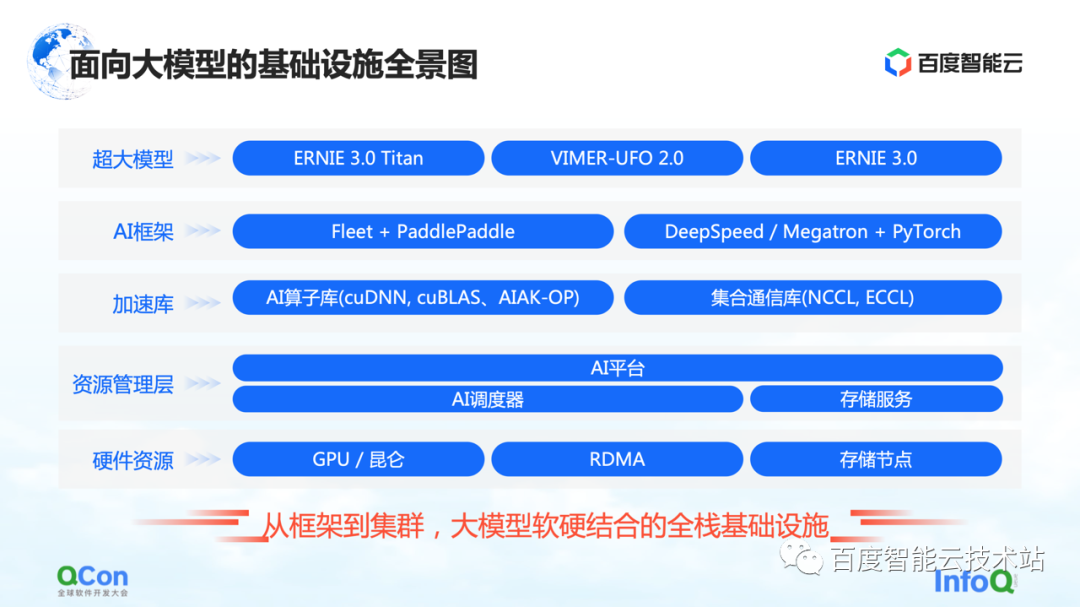
Este é um panorama da infraestrutura do Baidu Smart Cloud para grandes modelos. Trata-se de uma infraestrutura full-stack que abrange desde o framework até o cluster, combinando hardware e software.
No modelo grande, a infraestrutura não cobre mais apenas a infraestrutura tradicional, como hardware e redes subjacentes. Também precisamos trazer todos os recursos relevantes para a categoria de infraestrutura.
Especificamente, é dividido em vários níveis:
-
A camada superior é a camada de modelo, incluindo modelos publicados internos e externos e alguns componentes de suporte. Por exemplo, PaddlePaddle e Fleet, o remo voador do Baidu , Fleet é uma estratégia distribuída no remo voador . Ao mesmo tempo, na comunidade de código aberto, como PyTorch, existem algumas estruturas de treinamento de modelo em larga escala e recursos de aceleração baseados na estrutura PyTorch, como DeepSpeed/Megatron.
-
Sob a estrutura, também desenvolveremos recursos relacionados à biblioteca de aceleração, incluindo aceleração de operador de IA, aceleração de comunicação, etc.
-
A seguir estão alguns recursos relacionados de gerenciamento parcial de recursos ou gerenciamento parcial de cluster.
-
Na parte inferior estão os recursos de hardware, como placa única autônoma, chips heterogêneos e recursos relacionados à rede.
O acima é um panorama de toda a infraestrutura. Hoje vou me concentrar em começar com a estrutura de IA e, em seguida, estender para a camada de aceleração e camada de hardware para compartilhar alguns trabalhos específicos do Baidu Smart Cloud.
Comece com a estrutura de IA superior primeiro.
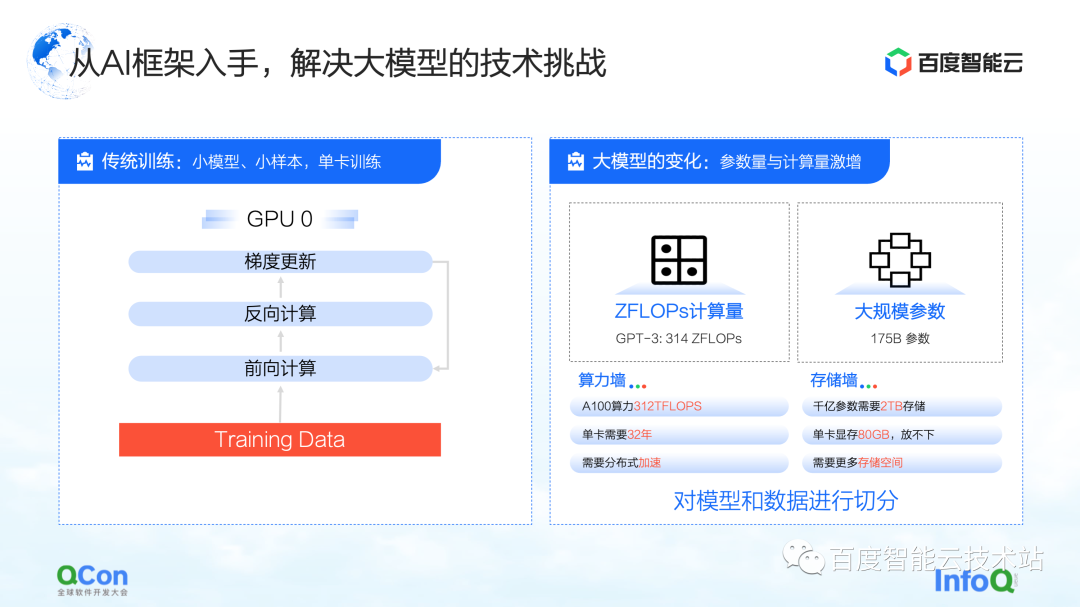
Para o treinamento tradicional de modelo pequeno em um único cartão, podemos concluir todo o treinamento usando os dados de treinamento para atualizar continuamente os gradientes direto e reverso. Para o treinamento de grandes modelos, existem dois desafios principais: a parede de poder de computação e a parede de armazenamento.
A parede de poder de computação refere-se a como podemos usar métodos distribuídos para quebrar o problema de muito tempo para poder de computação único, se quisermos concluir o treinamento do modelo de GPT-3, que requer poder de computação de 314 ZFLOPs, mas o cartão único só tem Poder de computação de 312 TFLOPS. Afinal, são necessários 32 anos para treinar um modelo com um cartão, o que obviamente não é viável.
Em seguida é a parede de armazenamento. Este é um desafio maior para modelos maiores. Quando um único cartão não pode conter o modelo, o modelo deve ter algum método de segmentação.
Por exemplo, o armazenamento de um modelo grande de 100 bilhões de níveis (incluindo parâmetros, valores intermediários de treinamento, etc.) requer 2 TB de espaço de armazenamento, enquanto a memória de vídeo máxima de um único cartão é atualmente de apenas 80 GB. Portanto, o treinamento de grandes modelos requer algumas estratégias de segmentação para resolver o problema de que um único cartão não cabe.
A primeira é a parede de poder de computação, que resolve o problema de poder de computação insuficiente de um único cartão.
Uma ideia muito simples e familiar é o paralelismo de dados, que corta as amostras de treinamento em diferentes cartões. No geral, o processo de treinamento de modelo grande que estamos observando agora adota principalmente uma estratégia de atualização de dados síncrona.

O foco está na solução para o problema da parede de armazenamento. A chave é a estratégia e o método de segmentação do modelo.
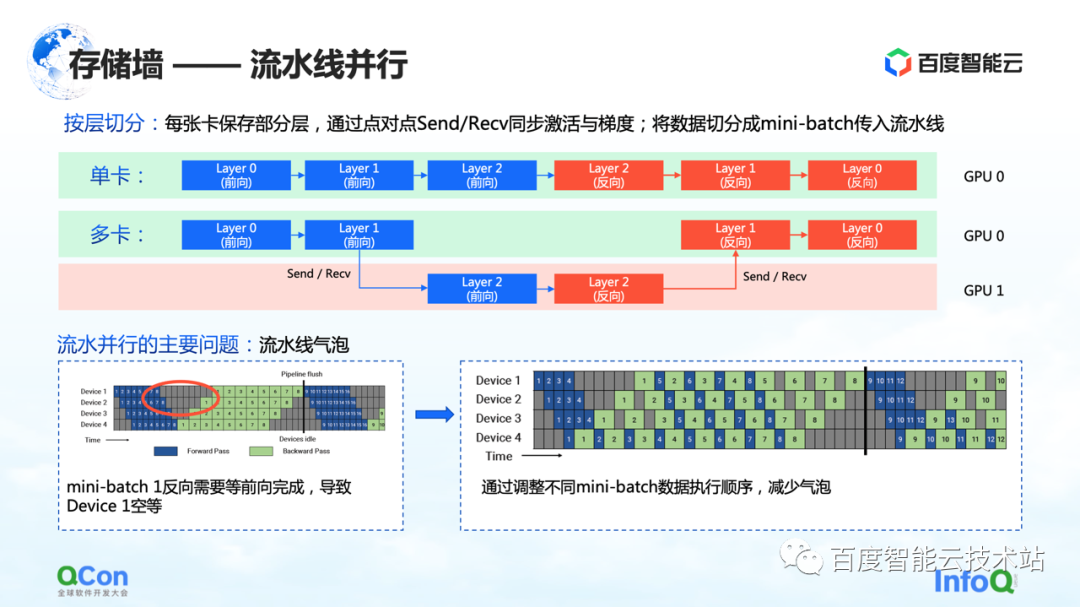
O primeiro método de divisão é o paralelismo em pipeline.
Vamos usar o exemplo da figura abaixo para ilustrar. Para um modelo, ele é composto de várias camadas. Ao treinar, primeiro avance e depois inverta. Por exemplo, as três camadas 0, 1 e 2 da imagem não cabem em um cartão, depois de dividirmos por camada, vamos colocar algumas camadas desse modelo no primeiro cartão. Por exemplo, na figura abaixo, a área verde representa a GPU 0 e a área vermelha representa a GPU 1. Podemos colocar as primeiras camadas na GPU 0 e as outras camadas na GPU 1. Quando os dados estão fluindo, ele primeiro fará dois avanços na GPU 0, depois um avanço e um reverso na GPU 1 e, em seguida, retornará à GPU 0 para fazer dois retrocessos. Como esse processo é particularmente parecido com um pipeline, nós o chamamos de paralelismo de pipeline.
Mas há um grande problema com o paralelismo de pipeline, ou seja, bolhas de pipeline. Como haverá dependências entre os dados, e o gradiente depende do cálculo da camada anterior, portanto, no processo de fluxo de dados, serão geradas bolhas, o que causará vazio. Em resposta a tais problemas, reduzimos o tempo vazio das bolhas ajustando as estratégias de execução de diferentes mini-lotes.
A descrição acima é a perspectiva de um engenheiro de algoritmo ou de um engenheiro de estrutura para examinar esse problema. Do ponto de vista dos engenheiros de infraestrutura, estamos mais preocupados com as diferentes mudanças que isso trará para a infraestrutura.
Aqui nos concentramos em sua semântica de comunicação. Está entre o avanço e o retrocesso e precisa passar seu próprio valor de ativação e valor de gradiente, o que trará operações adicionais de envio/recebimento. E Send/Receive é ponto a ponto, vamos mencionar a solução mais adiante no artigo.
A descrição acima é a primeira estratégia de segmentação de modelo paralelo que quebra a parede de armazenamento: paralelismo de pipeline.
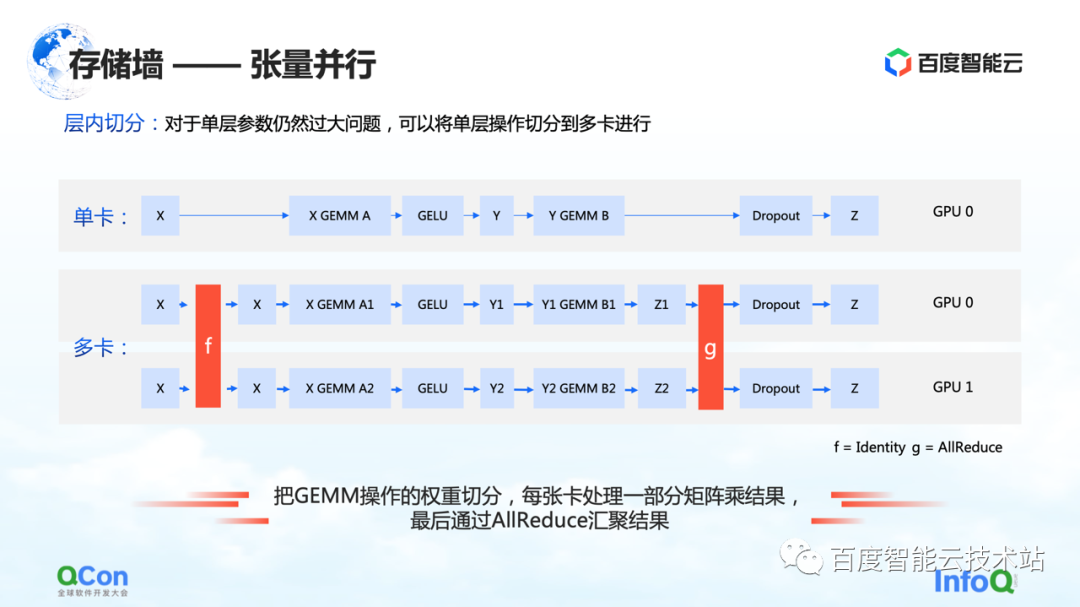
O segundo método de segmentação é o paralelismo tensor , que resolve o problema de parâmetros de camada única muito grandes.
Embora o modelo tenha muitas camadas, uma das camadas é computacionalmente intensiva. Neste momento, esperamos que o valor do cálculo desta camada seja calculado conjuntamente entre máquinas ou entre cartões. Do ponto de vista de um engenheiro de algoritmos, a solução é dividir diferentes entradas em várias partes, depois usar partes diferentes para realizar cálculos parciais e, finalmente, realizar a agregação.
Mas, do ponto de vista dos engenheiros de infraestrutura, ainda prestamos atenção em quais operações adicionais são introduzidas nesse processo. No cenário mencionado, as operações extras são f e g no gráfico. O que significam f e g? Ao avançar, f é uma operação invariante e x é transmitido de forma transparente por meio de f, e alguns cálculos podem ser feitos posteriormente. No entanto, quando os resultados são agregados no final, todo o valor precisa ser repassado. Para este caso, é necessário introduzir a operação de g. g é a operação de AllReduce, que agrega semanticamente dois valores diferentes para garantir que a saída z consiga obter os mesmos dados em ambos os cartões.
Portanto, do ponto de vista dos engenheiros de infraestrutura, você verá que ele apresenta operações de comunicação AllReduce adicionais. O tráfego de comunicação desta operação ainda é relativamente grande, porque os parâmetros nela são relativamente grandes. Também mencionaremos o método de enfrentamento mais adiante no artigo
Este é o segundo método de otimização que pode quebrar as paredes de armazenamento.
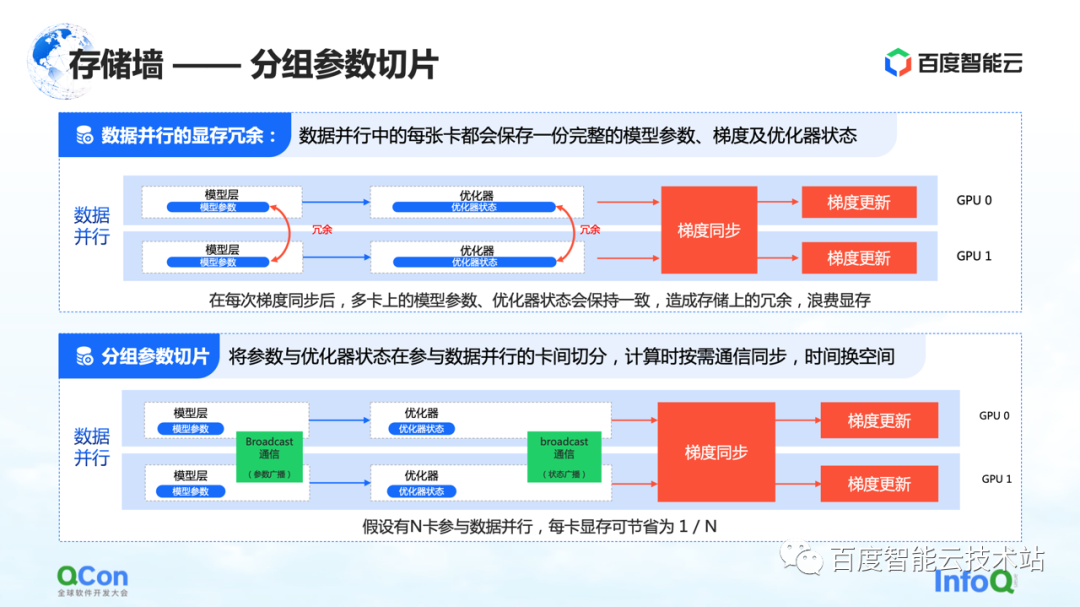
O terceiro método de divisão é a divisão de parâmetros agrupados . Este método reduz a redundância de memória no paralelismo de dados até certo ponto. Em execuções de dados tradicionais, cada cartão terá seus próprios parâmetros de modelo e estado do otimizador. Como precisam ser sincronizados e atualizados durante seus respectivos processos de treinamento, esses estados são totalmente copiados em diferentes cartões,
Para o processo acima, de fato, os mesmos dados e parâmetros são armazenados de forma redundante em cartões diferentes. Esse armazenamento redundante é inaceitável porque os modelos grandes têm requisitos de espaço de armazenamento extremamente altos. Para resolver este problema, dividimos os parâmetros do modelo e mantemos apenas uma parte dos parâmetros em cada cartão.
Quando os cálculos são realmente necessários, trocamos tempo por espaço: primeiro sincronizamos os parâmetros e depois descartamos os dados redundantes após a conclusão do cálculo. Dessa forma, a demanda por memória de vídeo pode ser ainda mais comprimida e o treinamento pode ser melhor realizado nas máquinas existentes.
Da mesma forma, do ponto de vista dos engenheiros de infraestrutura, precisamos introduzir operações de comunicação como transmissão, e o conteúdo da comunicação é o estado desses otimizadores e os parâmetros do modelo.
O acima é o terceiro método de otimização para quebrar a parede de armazenamento.
Além dos métodos e estratégias de otimização de memória mencionados acima, existe outra maneira de reduzir a quantidade de cálculo do modelo.
Quando a quantidade de dados é grande o suficiente, quanto mais parâmetros do modelo, melhor a precisão do modelo. Porém, com o aumento dos parâmetros, a quantidade de cálculo também aumenta, exigindo mais recursos e, ao mesmo tempo, o tempo de cálculo será maior.
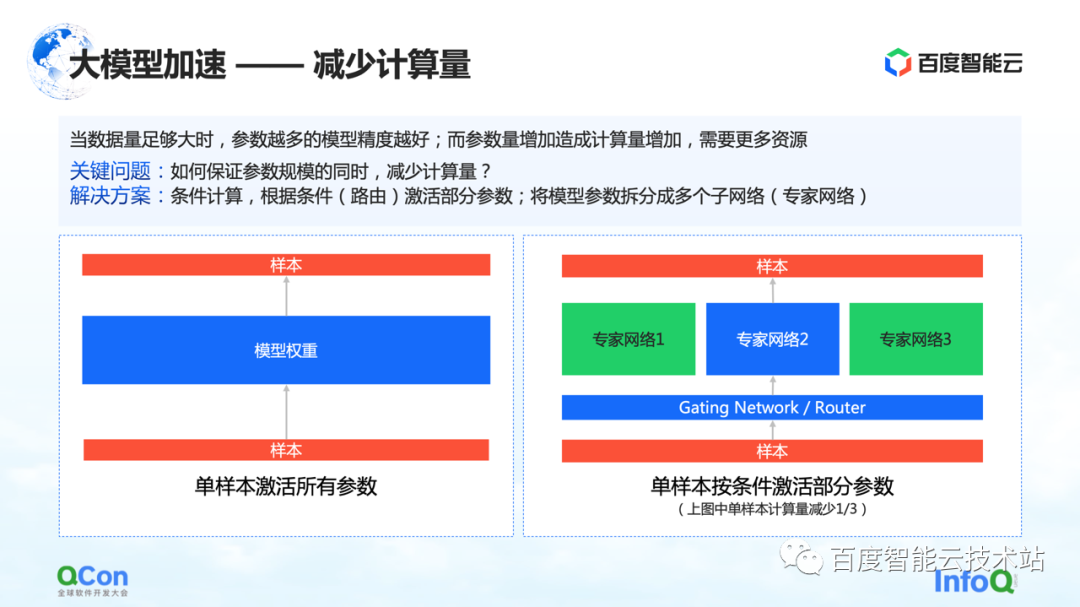
Então, como garantir que a quantidade de cálculo seja reduzida enquanto a escala de parâmetros permanece inalterada? Uma das soluções é a computação condicional: de acordo com certas condições (isto é, a camada Gating na figura à direita, ou chamada camada de roteamento), para selecionar e ativar alguns dos parâmetros.
Por exemplo, na figura à direita, dividimos os parâmetros em três partes e, de acordo com as condições do modelo, apenas parte dos parâmetros é ativada para cálculo na rede especialista 2. Alguns parâmetros no expert 1 e no expert 3 não são calculados. Desta forma, o valor do cálculo pode ser reduzido enquanto garante a escala do parâmetro.
O acima é um método baseado no cálculo condicional para reduzir a quantidade de cálculo.
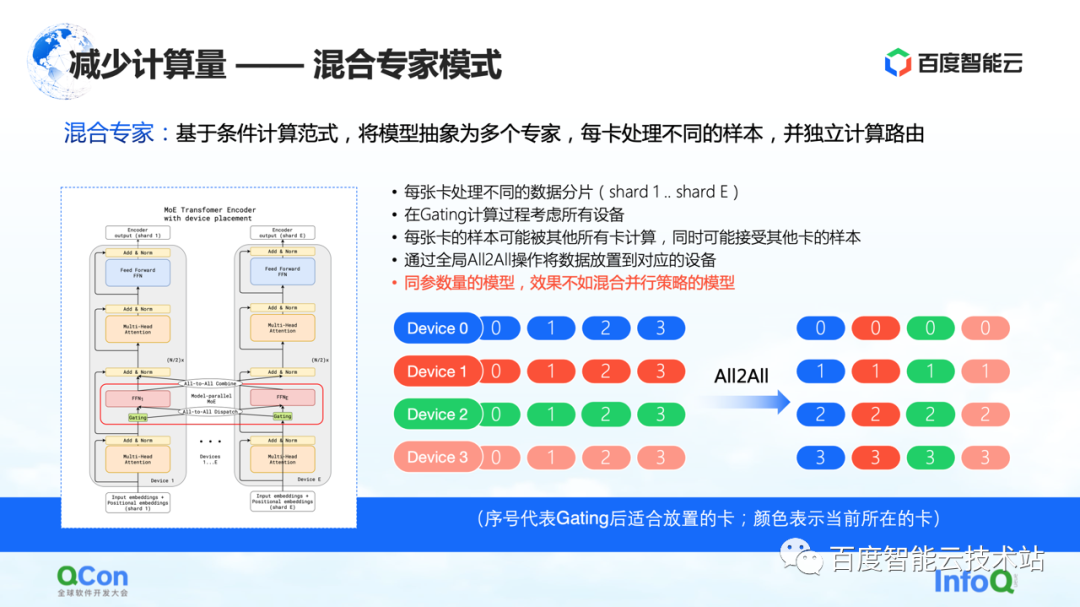
Com base no método acima, a indústria propôs um modelo misto de especialistas , que consiste em abstrair o modelo em vários especialistas, e cada cartão processa diferentes amostras. Especificamente, algumas opções de roteamento são inseridas na camada de modelo e, a seguir, apenas alguns dos parâmetros são ativados de acordo com essa escolha. Ao mesmo tempo, os parâmetros de diferentes especialistas serão mantidos em cartões diferentes. Desta forma, no processo de distribuição da amostra, eles serão alocados em diferentes cartões para cálculo.
Mas, do ponto de vista de um engenheiro de infraestrutura, descobrimos que a operação All2All foi introduzida nesse processo. Conforme mostrado na figura à direita abaixo, amostras como 0, 1, 2 e 3 são armazenadas em vários dispositivos. O valor em Dispositivo indica qual cartão é adequado para cálculo ou qual especialista é adequado para cálculo. Por exemplo, 0 significa que é adequado para ser calculado pelo especialista nº 0, ou seja, cartão nº 0 e assim por diante. Cada cartão determinará quem é adequado para os dados armazenados a serem calculados. Por exemplo, o cartão nº 1 julga que alguns parâmetros são adequados para cálculo pelo cartão nº 0 e outros parâmetros são adequados para cálculo pelo cartão nº 1. Em seguida, a próxima ação é distribuir as amostras em diferentes cartões.
Após as operações acima, as amostras no cartão nº 0 são todas 0s e as amostras no cartão nº 1 são todas 1s. O processo acima é chamado All2All na comunicação. Do ponto de vista dos engenheiros de infraestrutura, essa operação é relativamente pesada e precisamos fazer algumas otimizações relacionadas com base nisso. Também apresentaremos mais no texto a seguir.
Neste modo, um dos fenômenos que observamos é que, se o modo especialista misto for usado, sua precisão de treinamento não é tão boa quanto as várias estratégias paralelas e estratégias de superposição híbrida mencionadas agora sob o modelo dos mesmos parâmetros. à situação real.
Acabei de apresentar várias estratégias paralelas e, a seguir, compartilharei uma prática interna do Baidu Smart Cloud.
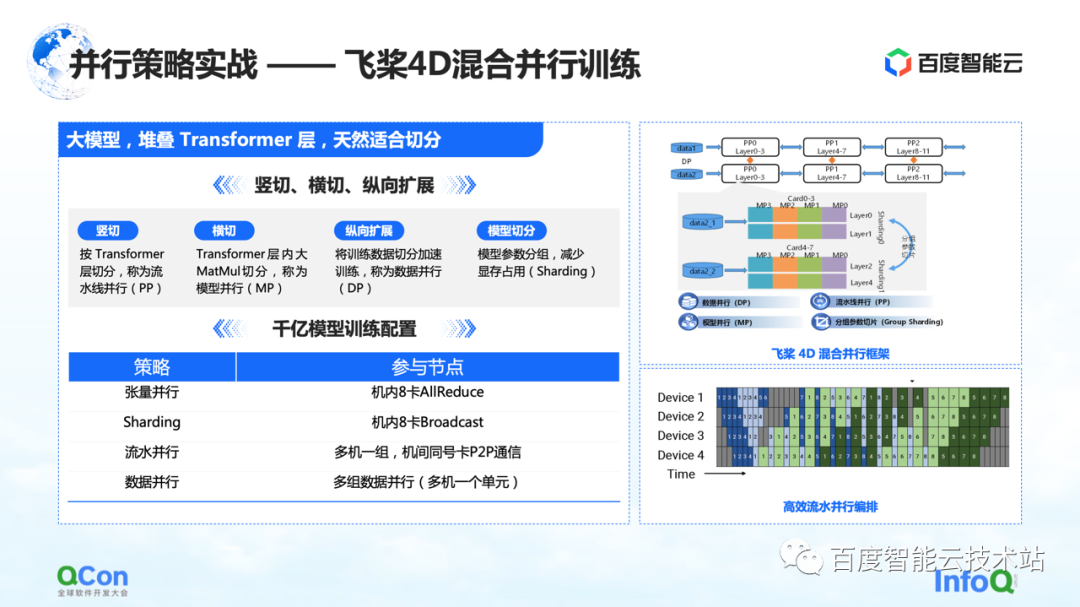
Treinamos um grande modelo com 260 bilhões de parâmetros usando Paddle , empilhando algumas camadas de classes Transformer otimizadas. Podemos cortá-lo horizontalmente e verticalmente, por exemplo, fatiar verticalmente o modelo de acordo com a camada Transformer usando a estratégia paralela de pipeline. O corte transversal é usar a estratégia paralela do modelo/estratégia paralela do tensor para dividir o cálculo da multiplicação de grandes matrizes, como MetaMul dentro do Transformer. Ao mesmo tempo, complementamos com otimização vertical de paralelismo de dados e otimização de memória de vídeo de segmentação de parâmetros de modelo de agrupamento em paralelismo de dados. Através dos quatro métodos acima, introduzimos a estrutura do treinamento paralelo híbrido 4D de remos voadores .
Na configuração de treinamento do modelo de parâmetro de 100 bilhões, usamos oito cartões na máquina para fazer o paralelismo tensor e, ao mesmo tempo, cooperamos com o paralelismo de dados para realizar algumas operações de segmentação de parâmetros de agrupamento. Ao mesmo tempo, vários grupos de máquinas são usados para formar um pipeline paralelo para transportar 260 bilhões de parâmetros de modelo. Finalmente, o método paralelo de dados é usado para computação distribuída para completar o treinamento mensal do modelo.
O exposto acima é um combate real de toda a nossa estratégia paralela de modelo de parâmetro paralelo.
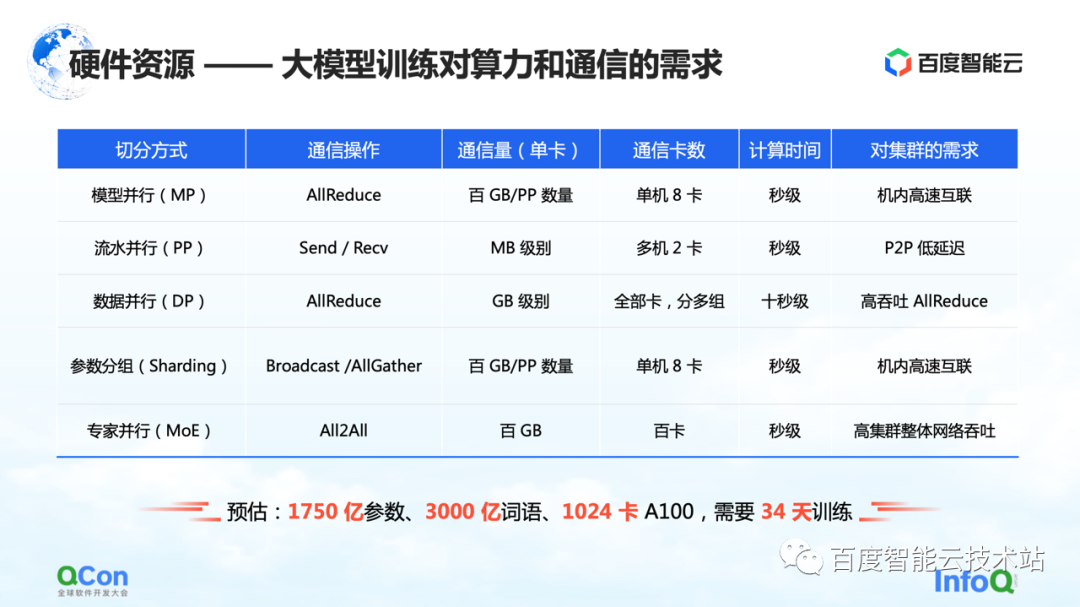
Em seguida, vamos retornar à perspectiva da infraestrutura para avaliar os requisitos de comunicação e poder de computação de diferentes estratégias de segmentação no treinamento do modelo.
Conforme mostrado na tabela, listamos o tráfego de comunicação e o tempo de computação necessário para diferentes métodos de segmentação de acordo com a escala de 100 bilhões de parâmetros. Da perspectiva de todo o processo de treinamento, o melhor efeito é que o processo de cálculo e o processo de comunicação podem ser completamente cobertos ou sobrepostos um ao outro.
A partir dessa tabela, podemos deduzir os requisitos do modelo de 100 bilhões de parâmetros para clusters, hardware, redes e modos gerais de comunicação. Com base em um modelo com cerca de 175 bilhões de parâmetros treinados em 1.024 cartões A100 usando 300 bilhões de palavras, são necessários 34 dias para concluir o treinamento completo de ponta a ponta.
A descrição acima é nossa avaliação do lado do hardware.
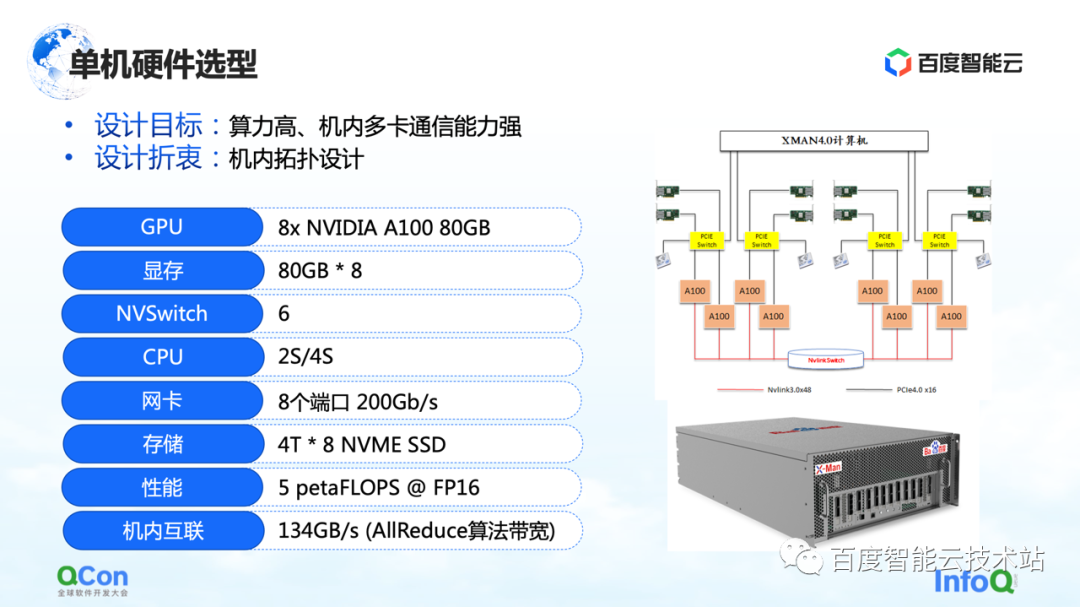
Com os requisitos de hardware, a próxima etapa é a seleção dos níveis autônomo e de rede.
No nível autônomo, uma vez que um grande número de operações AllReduce e Broadcast precisam ser executadas na máquina, esperamos que a máquina possa suportar conexões de alta largura de banda e alto desempenho. Então, usamos o pacote A100 80G mais avançado na seleção de modelos da época, usando 8 A100s para formar uma única máquina.
Além disso, no método de conexão de rede externa, o mais importante é o método de conexão de topologia. Esperamos que a placa de rede e a placa GPU possam estar sob o mesmo PCIe Switch tanto quanto possível, e o gargalo de taxa de transferência da interação entre as placas durante todo o processo de treinamento pode ser melhor reduzido de maneira simétrica. Ao mesmo tempo, tente evitar que eles passem pela porta raiz PCIe da CPU.
Depois de falar sobre o autônomo, vamos dar uma olhada no design da rede de cluster.
Em primeiro lugar, vamos avaliar os requisitos. Se nossa expectativa de negócios é concluir o treinamento de modelo de ponta a ponta em um mês, precisamos atingir o nível de quilocalorias no treinamento de trabalho único e o nível de 10.000 calorias no modelo grande agrupamentos de treinamento. Portanto, no processo de projeto de rede, devemos levar em consideração dois pontos:
Primeiramente, para atender a operação ponto-a-ponto de Send/Receive no pipeline, é necessário reduzir o atraso P2P.
Em segundo lugar, como o tráfego do lado da rede no treinamento de IA está concentrado na operação AllReduce do mesmo cartão, também esperamos que ele tenha uma alta taxa de transferência de comunicação.
para esta necessidade de comunicação. Projetamos a topologia da arquitetura CLOS de três camadas mostrada à direita. Em comparação com o método tradicional, o mais importante nesta topologia é a otimização dos oito trilhos de guia, para que o número de saltos na comunicação de qualquer cartão com o mesmo número em máquinas diferentes seja o menor possível.
Na arquitetura CLOS, a camada inferior é Unit. Existem 20 máquinas em cada Unidade e conectamos as placas GPU do mesmo número em cada máquina ao mesmo grupo de TORs com números correspondentes. Desta forma, todos os cartões do mesmo número em uma única unidade podem completar a comunicação com apenas um salto, o que pode melhorar muito a comunicação entre os cartões do mesmo número.
No entanto, existem apenas 20 máquinas com um total de 160 cartões em uma unidade, que não atendem aos requisitos de treinamento de modelo grande. Então, projetamos a segunda camada Folha. A camada Leaf conecta cartões com o mesmo número em unidades diferentes aos dispositivos de comutação do mesmo grupo de Leafs, o que ainda resolve o problema de interconectar cartões com o mesmo número. Através desta camada, podemos interligar 20 Unidades novamente. Até agora, conseguimos conectar 400 máquinas com um total de 3200 cartões. Para tal cluster de 3200 cartões, a comunicação entre quaisquer dois cartões do mesmo número pode ser realizada saltando até 3 saltos.
E se quisermos suportar a comunicação de cartões com números diferentes? Adicionamos uma camada Spine no topo para resolver o problema de comunicação entre cartões com números diferentes.
Por meio dessa arquitetura de três camadas, criamos uma arquitetura geral que suporta 3.200 cartões otimizados para operações AllReduce. Se estiver no equipamento de rede do IB, a arquitetura pode suportar a escala de 16.000 cartões, que também é a maior escala de rede do tipo caixa IB atualmente.
Comparamos a arquitetura CLOS com algumas outras arquiteturas de rede, como Dragonfly, Torus, etc. Em comparação com eles, a largura de banda de rede dessa arquitetura é mais suficiente e o número de saltos entre os nós é mais estável, o que é muito útil para estimar o desempenho previsível do treinamento.
O acima é um conjunto de ideias de construção de autônomo para rede de cluster.

3. Otimização conjunta da combinação de software e hardware
O treinamento em modelo em larga escala não significa comprar o hardware e colocá-lo lá para concluir o treinamento. Também precisamos de otimização conjunta de hardware e software.
Em primeiro lugar, vamos falar sobre otimização de cálculo. O treinamento de grandes modelos ainda é um processo computacionalmente intensivo como um todo. Em termos de otimização de computação, muitas ideias e ideias atuais são baseadas na aceleração multibackend de gráficos estáticos. Os gráficos construídos pelos usuários, seja Paddle , PyTorch ou TensorFlow, primeiro converterão os gráficos dinâmicos em gráficos estáticos por meio da captura de gráficos e, em seguida, permitirão que os gráficos estáticos entrem no back-end para aceleração.
A figura abaixo mostra toda a nossa arquitetura multi-backend baseada em gráfico estático, que é dividida nas seguintes partes**. **
O primeiro é o acesso gráfico, que converte gráficos dinâmicos em gráficos estáticos.
O segundo é o método de acesso multibackend, que fornece recursos de otimização baseados em tempo por meio de diferentes backends.
A terceira é a otimização de gráficos. Fizemos algumas otimizações de cálculo e conversão de gráficos para gráficos estáticos, de modo a melhorar ainda mais a eficiência da computação.
Por fim, usaremos alguns operadores personalizados para agilizar o processo de treinamento do modelo grande como um todo.
Vamos apresentá-los separadamente abaixo.

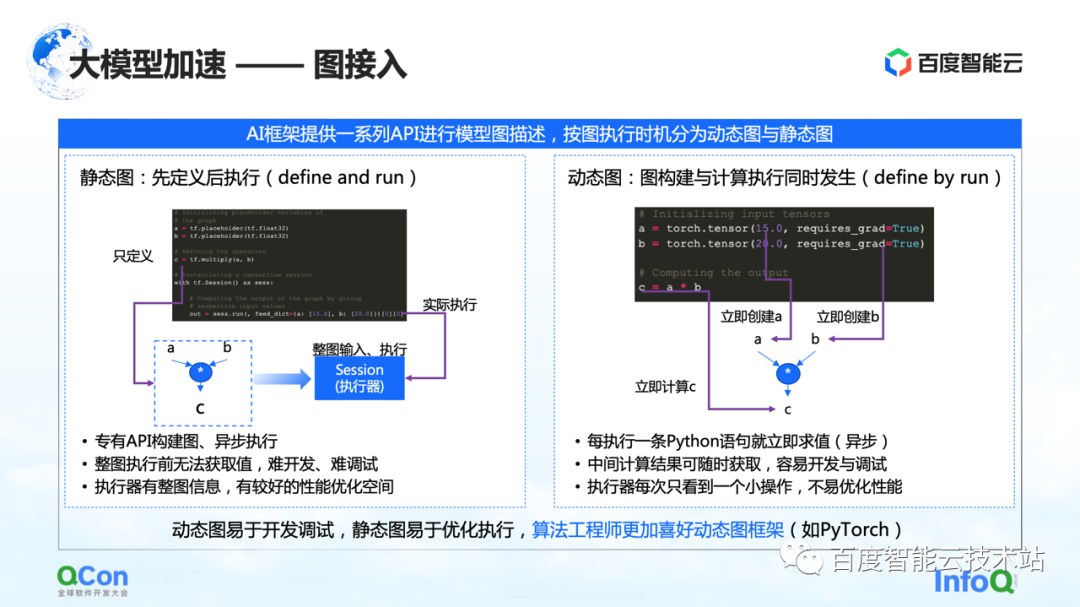
Na arquitetura de treinamento de modelos grandes, a primeira parte é o acesso ao grafo. Ao descrever gráficos no framework AI, eles geralmente são divididos em gráficos estáticos e gráficos dinâmicos.
O gráfico estático é que o usuário constrói o gráfico antes de executá-lo e, em seguida, executa-o em combinação com sua entrada real. Combinado com tais características, alguma otimização de compilação ou otimização de agendamento pode ser feita com antecedência durante o processo de cálculo, o que pode melhorar melhor o desempenho do treinamento.
Mas correspondente a ele está o processo de construção do grafo dinâmico. O usuário escreve algum código casualmente e é executado dinamicamente durante o processo de escrita. Por exemplo, PyTorch, após o usuário escrever uma instrução, ele executará a execução e avaliação relacionadas. Para os usuários, a vantagem dessa abordagem é que ela é fácil de desenvolver e depurar. Mas para o executor ou o processo de aceleração, porque cada vez que é visto é uma pequena parte da operação, não é muito bem otimizado.
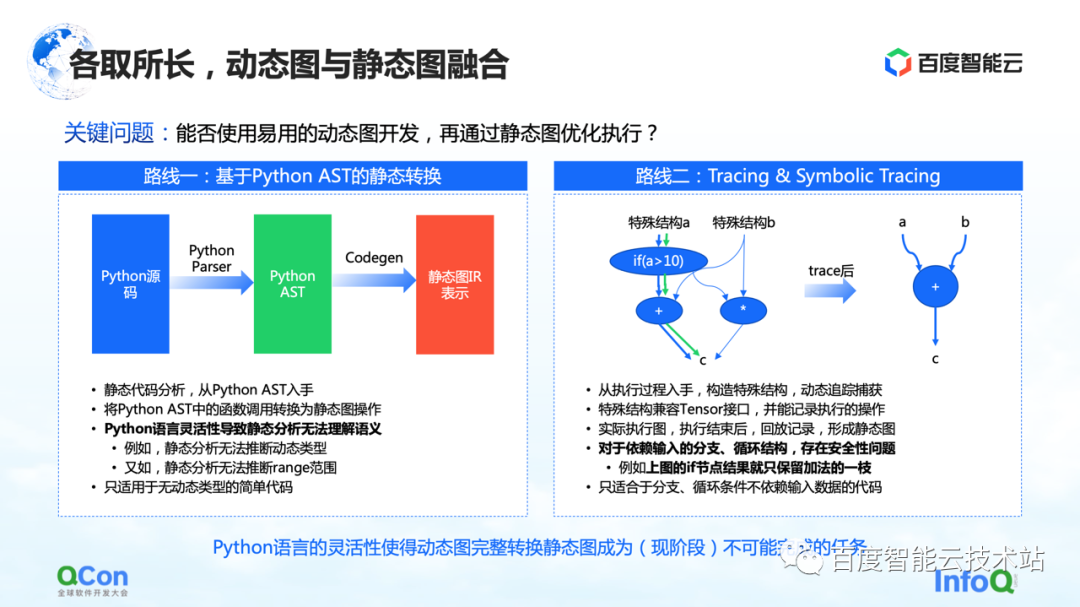
Para resolver esse problema, a ideia geral é integrar grafos dinâmicos e grafos estáticos, usar grafos dinâmicos para desenvolvimento e depois executar por meio de grafos estáticos. Existem basicamente dois caminhos para a implementação que vemos agora.
A primeira é fazer a conversão estática baseada no Python AST. Por exemplo, obtemos o código-fonte Python escrito pelo usuário, o convertemos em uma árvore AST Python e, em seguida, fazemos o CodeGen com base na árvore AST. Nesse processo, o código-fonte dinâmico do Python pode ser convertido em um grafo estático usando o método e a API do grafo de grupo estático.
Mas nesse processo, o maior problema é a flexibilidade da linguagem Python, que leva à incapacidade da análise estática de entender bem a semântica, e então a conversão de imagens dinâmicas em imagens estáticas falha. Por exemplo, no processo de análise estática, não tem como inferir o tipo dinâmico, e por exemplo, a análise estática não consegue inferir o intervalo do intervalo, resultando em falhas frequentes no próprio processo de conversão. Portanto, a conversão estática só pode ser aplicada a alguns cenários de modelo simples.
A segunda rota é fazer execução e simulação simples por meio de Rastreamento ou Rastreamento Simbólico. O Tracer registra alguns nós de computação encontrados durante o processo de gravação. Após registrar esses nós de computação, ele constrói um grafo estático inteiro a posteriori por meio de reprodução ou reorganização. A vantagem desse método é que ele pode capturar e calcular o gráfico dinâmico geral simulando alguns métodos de entrada ou construindo métodos de estrutura especial e, então, pode capturar um caminho com mais sucesso.
Mas, na verdade, existem alguns problemas nesse processo. Para estruturas de ramificação ou loop que dependem de entrada, como o Tracer constrói gráficos estáticos construindo entradas simuladas, o Tracer irá apenas para algumas das ramificações, o que leva a problemas de segurança.
Depois de comparar esses métodos, descobrimos que, com a flexibilidade de linguagem existente do Python, é basicamente uma tarefa impossível concluir a conversão de gráficos dinâmicos em gráficos estáticos nesse estágio. Portanto, nosso foco mudou para como fornecer aos usuários recursos de conversão de imagem mais seguros e fáceis de usar na nuvem. Nesta fase, existem várias opções da seguinte forma.
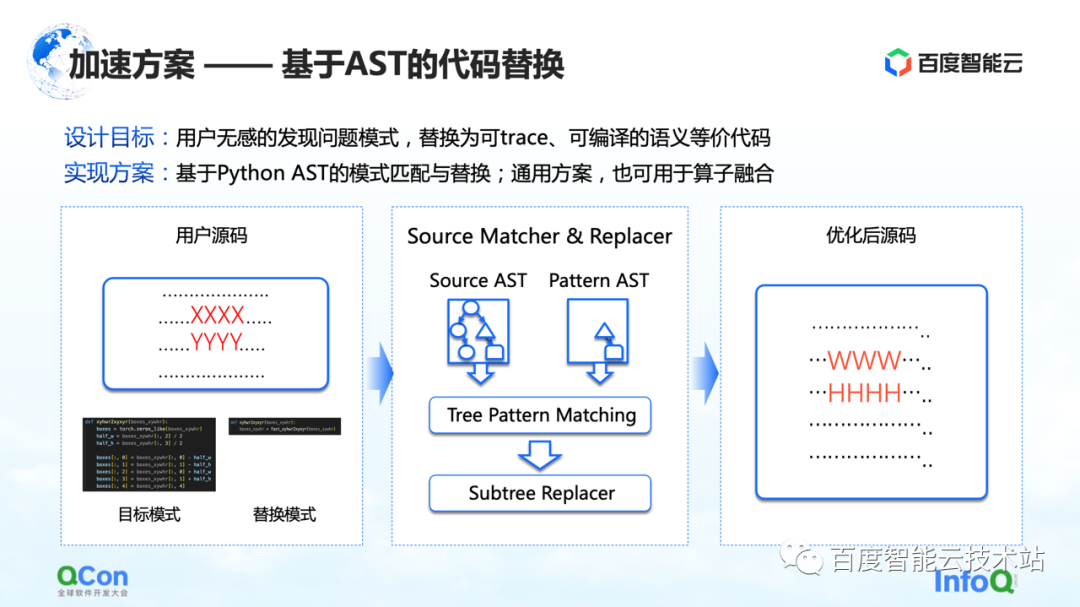
A primeira solução é desenvolver um método baseado na substituição do código AST. Nesse método, o Baidu Smart Cloud fornece os recursos de conversão e otimização de modelo correspondentes, que são insensíveis aos usuários. Por exemplo, o usuário insere uma parte do código-fonte, mas parte do código (mostrado como XXXX e YYYY na figura) está em processo de captura de imagem estática, otimização de gráfico e otimização de operador. Descobrimos que essa parte do o código não pode converter o gráfico dinâmico em um gráfico estático ou o código tem espaço para otimização de desempenho. Em seguida, escreveremos um código de substituição, conforme mostrado na figura do meio. À esquerda está um trecho de código Python que achamos que pode ser substituído e, à direita, outro trecho de código Python que substituímos. Em seguida, usaremos o método de correspondência AST para converter a entrada do usuário e nosso padrão de destino original em AST e executar nosso algoritmo de correspondência de árvore de subárvore nele.
Dessa forma, podemos alterar nossa entrada original XXXX, YYYY para WWWW, HHHH e transformá-la em uma solução que pode ser executada melhor, o que melhora a taxa de sucesso da conversão de imagens dinâmicas em imagens estáticas até certo ponto e melhora o operador ao mesmo tempo, desempenho, e pode conseguir o efeito que o usuário é basicamente insensível.
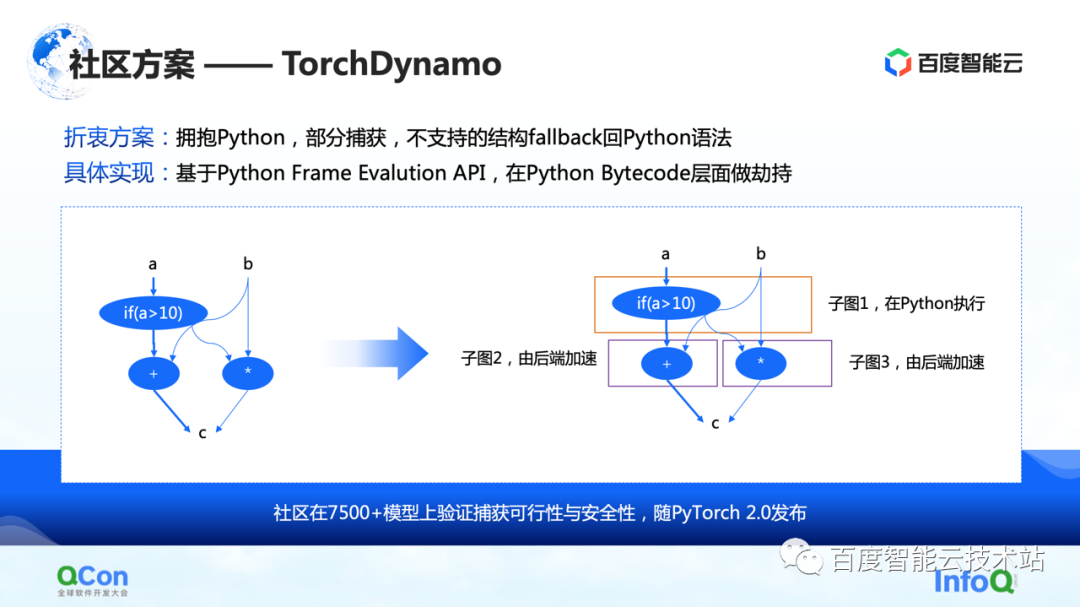
A segunda são algumas soluções da comunidade, principalmente a solução TorchDynamo proposta pelo PyTorch 2.0, que também é uma solução que vimos até agora que é mais adequada para otimização de computação. Ele pode obter captura de gráfico parcial e estruturas não suportadas podem retornar ao Python. Dessa forma, ele pode cuspir alguns dos subgráficos para o back-end até certo ponto e, em seguida, o back-end pode acelerar ainda mais os cálculos nesses subgráficos.
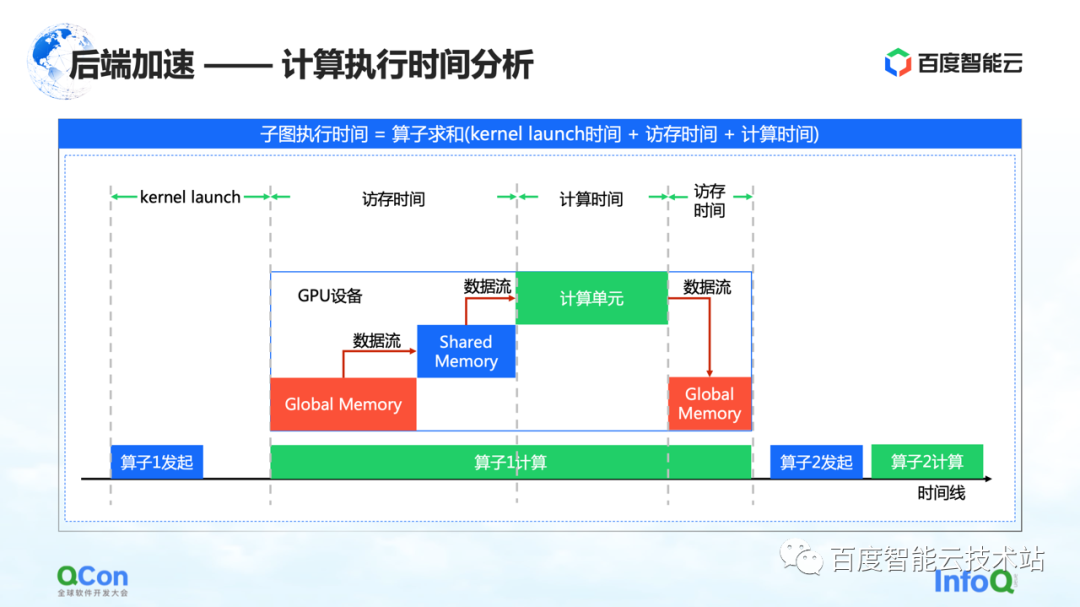
Depois de capturar todo o gráfico, a próxima etapa é realmente começar a calcular a aceleração, ou seja, a aceleração de back-end.
Acreditamos que os pontos-chave no diagrama de tempo da computação GPU são o tempo de acesso à memória e o tempo de computação. Nós aceleramos desta vez a partir dos seguintes ângulos.
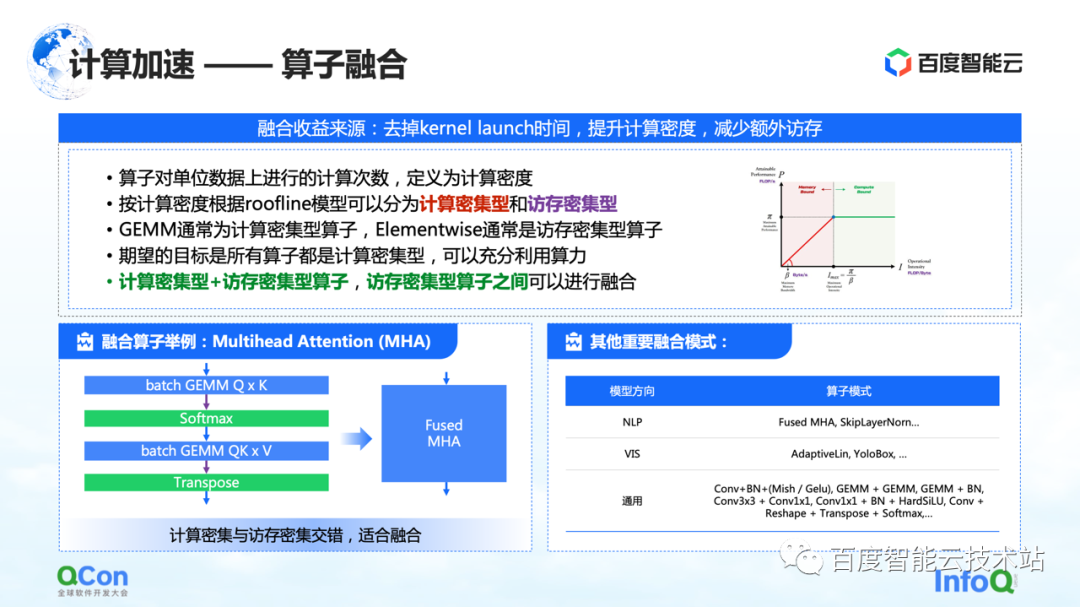
A primeira é a fusão de operadores. O principal benefício da fusão de operadores é reduzir o tempo gasto na inicialização do kernel, aumentar a densidade de computação e reduzir o acesso adicional à memória. Definimos o número de cálculos por unidade de acesso à memória de um operador como densidade de cálculo.
De acordo com a diferença na densidade de computação, dividimos os operadores em dois tipos: intensivos em computação e intensivos em memória. Por exemplo, GEMM é um operador típico de uso intensivo de computação e Elementwise é um operador típico de uso intensivo de memória. Descobrimos que uma boa fusão pode ser feita entre "operadores intensivos em computação + operadores intensivos em memória" e "operadores intensivos em memória + operadores intensivos em memória".
Nosso objetivo é converter todos os operadores executados na GPU em operadores de cálculo intensivo parcial, para que possamos fazer pleno uso de nosso poder de computação.
À esquerda está um exemplo nosso, por exemplo, na estrutura do Transformer, o mais importante Multihead Attention pode fazer uma boa fusão. Ao mesmo tempo, existem alguns outros modelos que encontramos à direita, e não os listaremos um a um devido a limitações de espaço.
Outro tipo de otimização de computação é a otimização da implementação do operador.
A questão essencial da implementação do operador é como combinar a lógica de computação com a arquitetura do chip, de modo a realizar melhor todo o processo de computação. Atualmente vemos três tipos de cenários:
A primeira categoria são os operadores manuscritos. Os fabricantes relevantes fornecerão bibliotecas de operadoras como cuBLAS e cuDNN. O desempenho do operador que ele fornece é o melhor, mas as operações que ele oferece são limitadas e o suporte para desenvolvimento personalizado é relativamente ruim.
A segunda categoria são os modelos semiautomáticos, como o CUTLASS. Este método faz uma abstração de código aberto, permitindo que os desenvolvedores façam desenvolvimento secundário nele. Esse também é o método que usamos atualmente para obter a fusão de operadores intensivos em computação e intensivos em memória.
A terceira é a otimização baseada em pesquisa. Prestamos atenção a alguns métodos de compilação como Halide e TVM na comunidade. No momento, descobriu-se que esse método é eficaz em alguns operadores, mas precisa ser aprimorado em outros operadores.
Na prática, esses três métodos têm suas próprias vantagens, portanto, forneceremos a você a melhor implementação por meio da seleção de tempo.

Depois de falar sobre otimização de computação, vamos compartilhar vários métodos de otimização de comunicação.
A primeira é a resolução do problema de colisão de hash de switch. A figura abaixo é um experimento que fizemos. Configuramos uma tarefa de 32 cartões e realizamos 30 operações AllReduce de cada vez. A figura abaixo mostra a largura de banda de comunicação que medimos, podemos ver que há uma grande probabilidade de que ela fique lenta. Este é um problema sério no treinamento de modelos grandes.
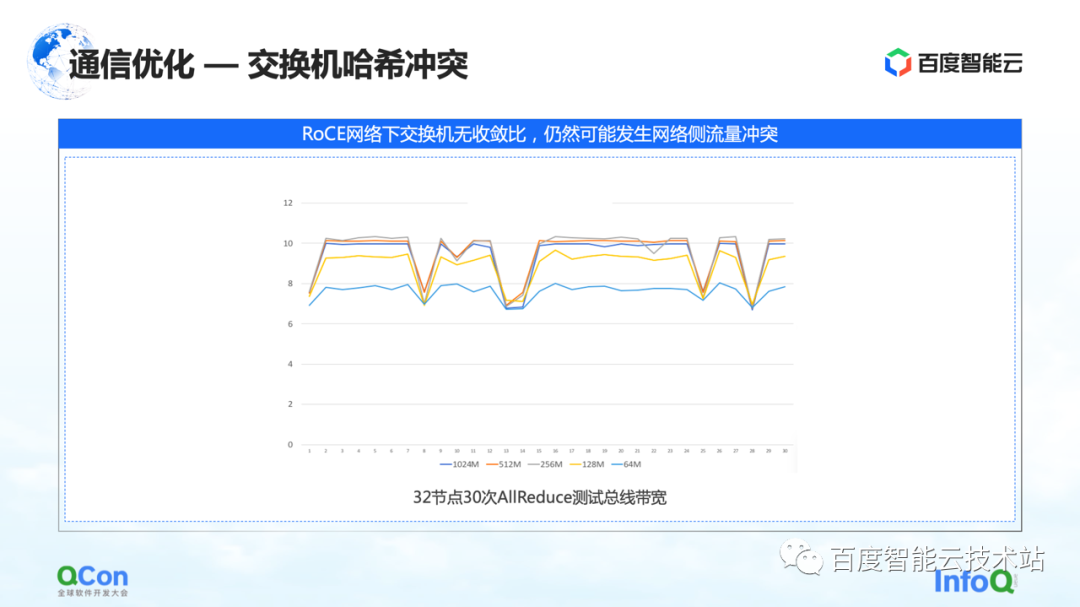
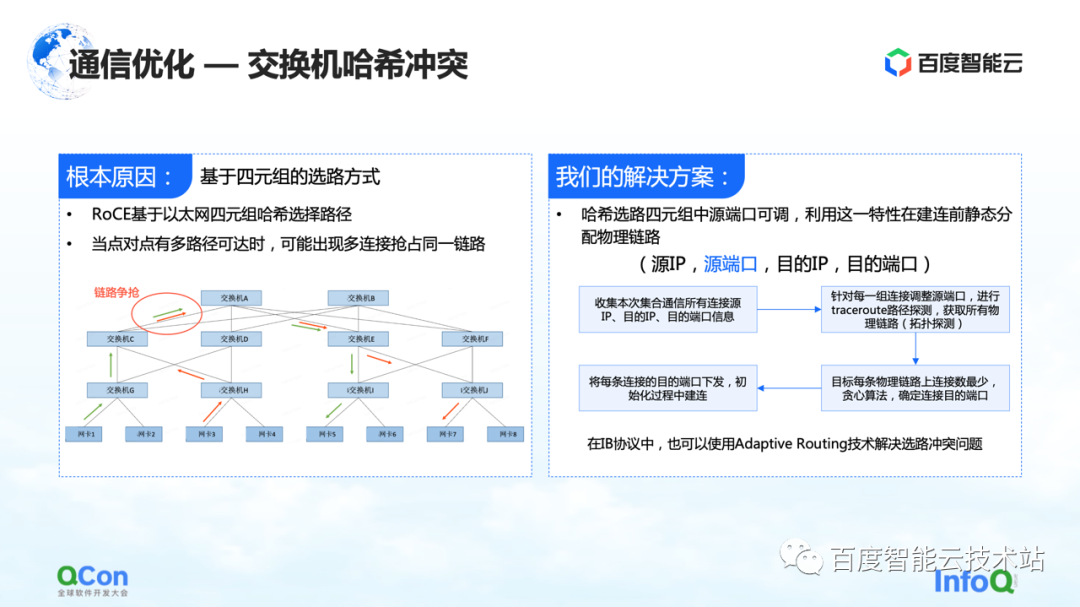
O motivo da desaceleração é devido a colisões de hash. Embora no projeto de rede o switch não tenha taxa de convergência, ou seja, os recursos de largura de banda em nosso projeto de rede são suficientes, mas devido ao uso de RoCE, um método baseado em roteamento quádruplo Ethernet, conflitos de tráfego no lado da rede ainda podem ocorrer.
Por exemplo, no exemplo da figura abaixo, as máquinas verdes precisam se comunicar umas com as outras, e as máquinas vermelhas também precisam se comunicar umas com as outras. Então, durante o processo de seleção de rota, a comunicação de todos competirá pela mesma largura de banda devido a conflitos de hash, resultando em Embora a largura de banda geral da rede seja suficiente, os pontos de acesso da rede local ainda se formarão, resultando em uma redução no desempenho da comunicação.
Nossa solução é realmente bastante simples. Em todo o processo de comunicação, existem quatro tuplas de IP de origem, porta de origem, IP de destino e porta de destino. O IP de origem, o IP de destino e a porta de destino são fixos, enquanto a porta de origem pode ser ajustada. Aproveitando esse recurso, ajustamos continuamente a porta de origem para selecionar diferentes caminhos e, em seguida, usamos o algoritmo guloso geral para minimizar a ocorrência de colisões de hash.
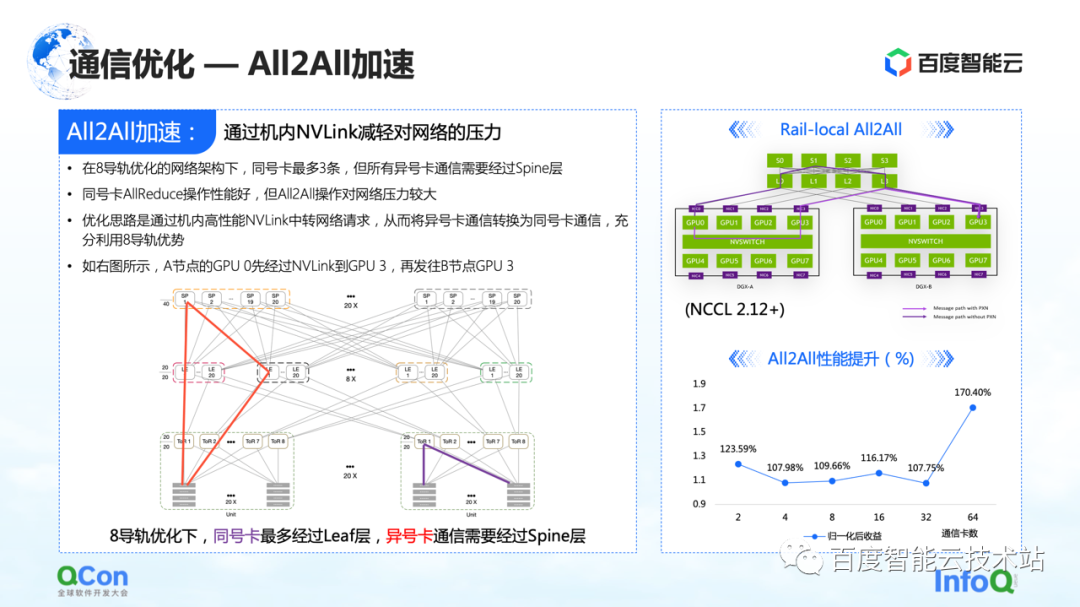
Na otimização da comunicação, além de algumas otimizações no AllReduce que acabamos de mencionar, também existe um certo espaço para otimização no All2All, principalmente nossa rede especialmente customizada para oito trilhos.
Essa rede colocará muita pressão no interruptor da coluna da camada superior na operação de todo o All2All. O método de otimização é usar o Rail-Local All2All no NCCL, ou a otimização do PXN. O princípio é converter a comunicação entre cartões de números diferentes para a comunicação entre cartões de mesmo número através do NVLink de alto desempenho dentro da máquina.
Dessa forma, convertemos toda a comunicação de rede entre as máquinas que originalmente subia até a camada da espinha em comunicação intra-máquina, de modo que apenas a comunicação da camada TOR ou da camada folha pode ser usada para realizar a comunicação de cartões com números diferentes e o desempenho também será melhorado.Há uma grande melhoria.
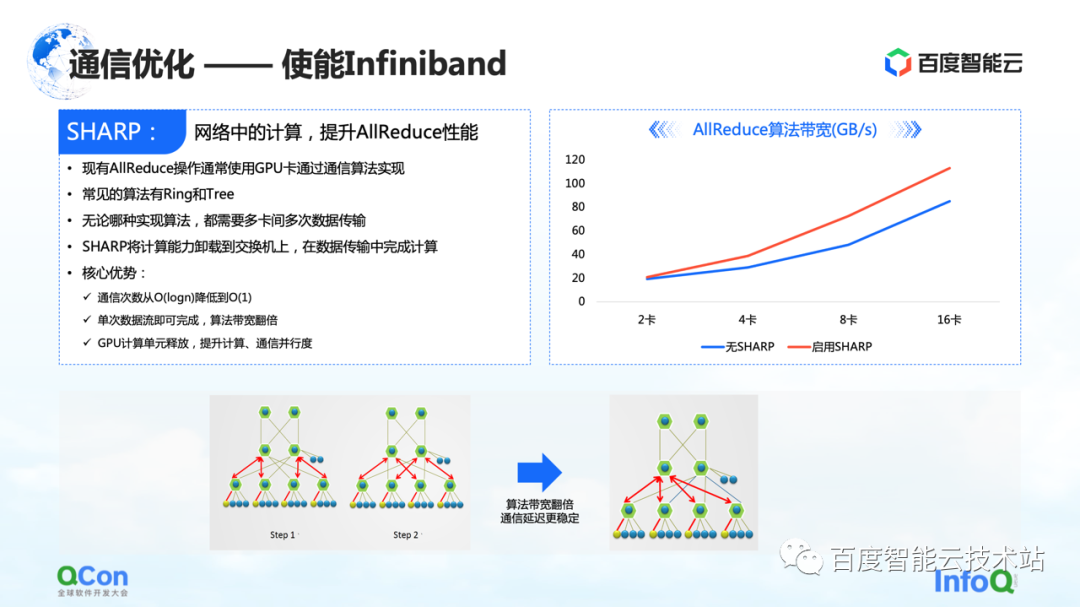
Além dessas otimizações feitas no RoCE, há outro efeito direto que pode ser obtido habilitando o Infiniband. Por exemplo, o conflito de hash do switch que acabamos de mencionar pode ser tratado por seu próprio roteamento adaptativo. Para o AllReduce, ele também possui alguns recursos avançados, como o Sharp, que pode descarregar parte das operações de computação do AllReduce para nossos dispositivos de rede, de modo a liberar unidades de computação e melhorar o desempenho da computação. Através deste método, podemos melhorar o efeito de treinamento de AllReduce novamente.
Acabei de falar sobre a otimização da computação e da comunicação, vamos analisar esse problema de ponta a ponta.
Do ponto de vista de todo o treinamento de modelo grande, ele é realmente dividido em duas partes, a primeira parte é o código do modelo e a segunda parte é a rede de alto desempenho. Nestes dois níveis diferentes, há um problema a ser resolvido com urgência: qual cartão é o mais adequado para posicionar o modelo após múltiplas estratégias de segmentação?
Vamos dar um exemplo: ao fazer paralelismo tensorial, precisamos dividir o cálculo de um tensor em duas partes. Como é necessário um grande número de operações AllReduce entre os resultados de cálculo dos blocos, é necessária uma alta largura de banda.
Se colocarmos dois pedaços de um tensor cortado em paralelo em duas placas de máquinas diferentes, a comunicação de rede será introduzida, causando problemas de desempenho. Pelo contrário, se colocarmos essas duas peças na mesma máquina, podemos concluir com eficiência as tarefas de computação e melhorar a eficiência do treinamento. Portanto, o apelo central do problema de posicionamento é encontrar o relacionamento de mapeamento mais adequado ou de melhor desempenho entre o modelo segmentado e o hardware heterogêneo.
Em nosso treinamento de modelo inicial, o mapeamento foi feito manualmente com base no conhecimento empírico especializado. Por exemplo, a imagem abaixo mostra que, quando cooperamos com a equipe de negócios, quando pensamos que a largura de banda da máquina é boa, recomendamos colocá-la na máquina. Se acharmos que pode haver melhorias na casa de máquinas, é recomendável colocá-lo na casa de máquinas.
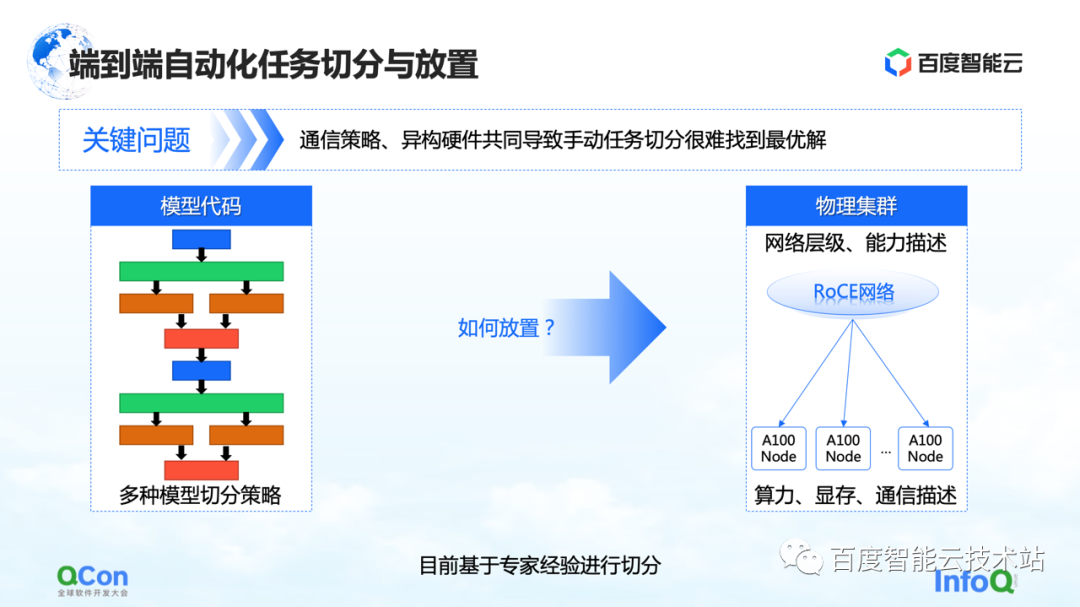
Existe alguma solução de engenharia ou sistemática?
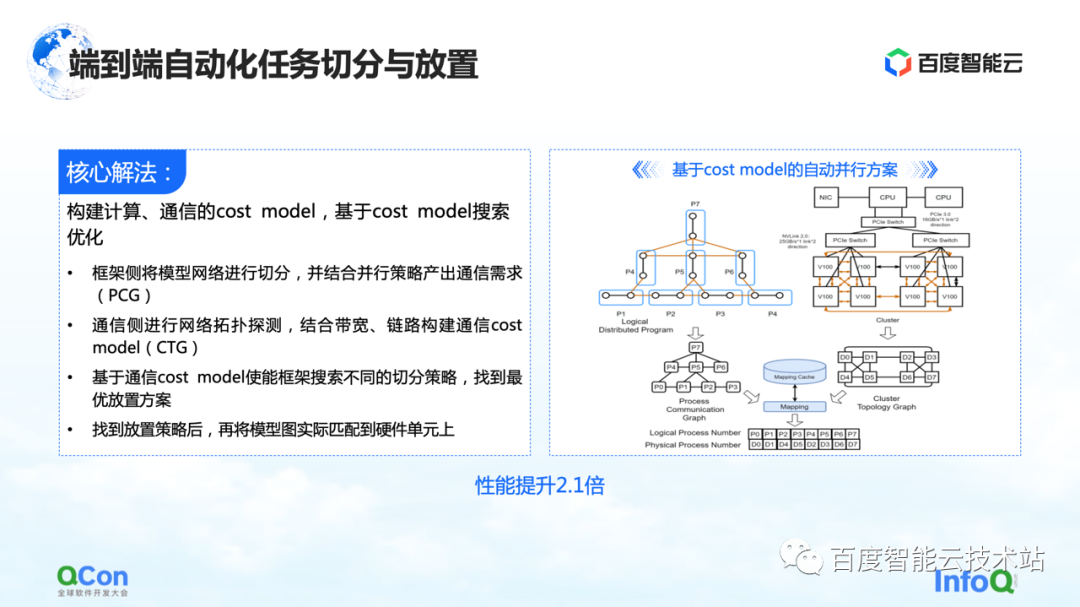
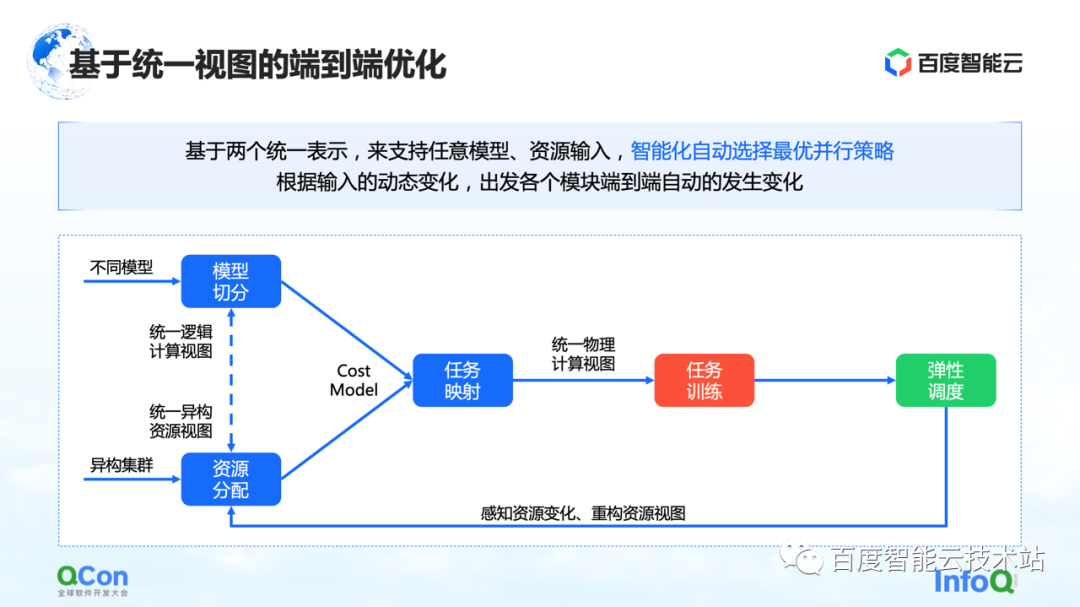
Nossa solução principal é criar um modelo de custo para computação e comunicação e, em seguida, fazer a otimização de pesquisa com base no modelo de custo. Desta forma, um mapeamento ideal é produzido.
Em todo o processo, a rede modelo no lado da estrutura será abstraída e segmentada primeiro e mapeada em um diagrama de estrutura de computação. Ao mesmo tempo, os recursos de computação e comunicação do autônomo e do cluster serão modelados para criar um mapa de topologia do cluster.
Quando temos os requisitos de computação e comunicação no modelo no lado esquerdo da imagem à direita e os recursos de computação e comunicação no hardware no lado direito da imagem, podemos dividir e mapear o modelo por meio de algoritmos de gráfico ou outros métodos de pesquisa. métodos e, finalmente, obtenha Uma solução ótima na parte inferior da figura à direita.
No processo real de treinamento de modelo grande, o desempenho final pode ser melhorado em 2,1 vezes dessa maneira.
4. O desenvolvimento de grandes modelos promove a evolução da infraestrutura
Por fim, discutirei com você quais novos requisitos o modelo grande imporá à infraestrutura no futuro.
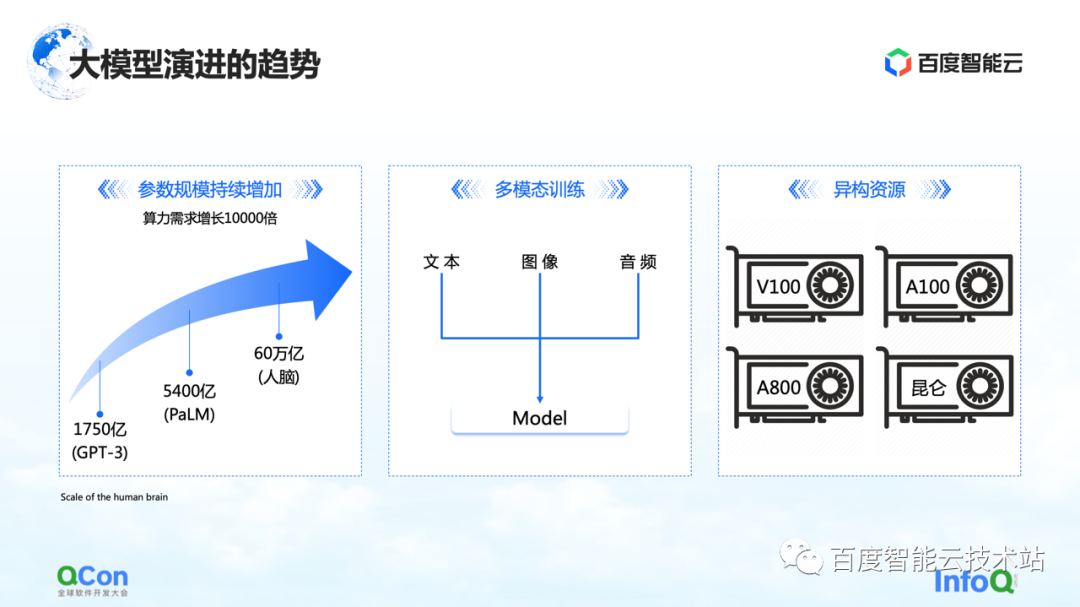
Há três mudanças que estamos vendo até agora. O primeiro são os parâmetros do modelo, e os parâmetros do modelo continuarão a crescer, de 175 bilhões no GPT-3 para 540 bilhões no PaLM. Com relação ao valor final do crescimento futuro dos parâmetros, podemos nos referir ao cérebro humano com uma escala de cerca de 60 trilhões de parâmetros.
O segundo é o treinamento multimodal. No futuro, vamos lidar com mais dados modais. Dados modais diferentes trarão mais desafios para armazenamento, computação e memória de vídeo.
O terceiro são os recursos heterogêneos. No futuro teremos cada vez mais recursos heterogêneos. No processo de formação, vários tipos de poder de computação, como melhor utilizá-los também é um desafio urgente a ser resolvido.
Ao mesmo tempo, de uma perspectiva de negócios, pode haver diferentes tipos de trabalhos em um processo de treinamento completo, e pode haver treinamento tradicional GPT-3, treinamento de aprendizado por reforço e tarefas de rotulagem de dados ao mesmo tempo. Como colocar melhor essas tarefas heterogêneas em nosso cluster heterogêneo será um problema maior.
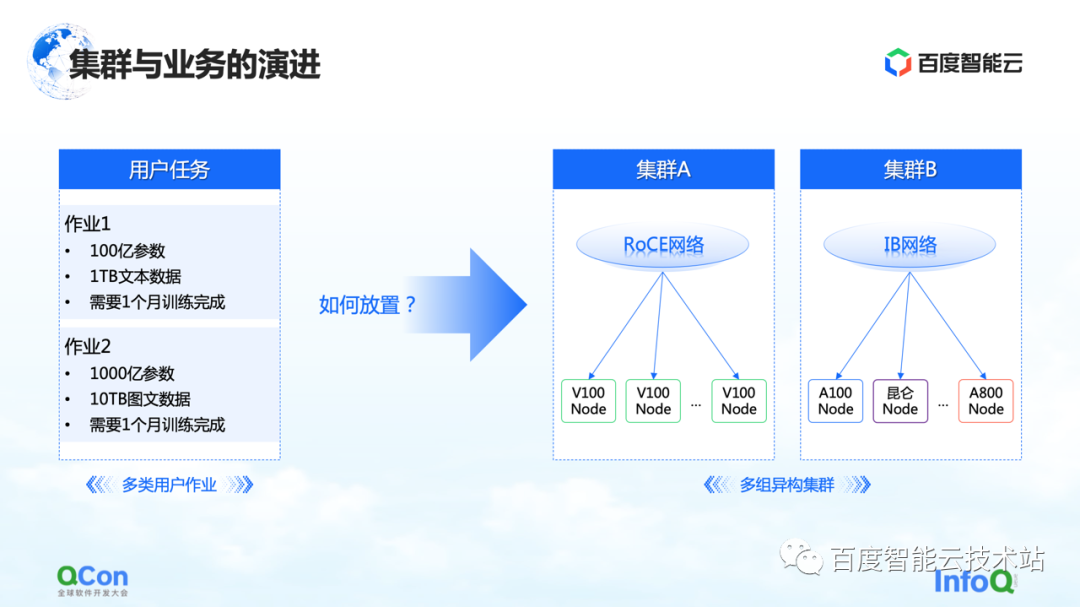
Vimos vários métodos agora, um dos quais é a otimização de ponta a ponta com base em uma visão unificada: unificar todo o modelo e recursos heterogêneos na visão e estender o modelo de custo com base na visão unificada, que pode suportar um único tarefa e multitarefa na colocação em clusters de recursos heterogêneos. Combinado com a capacidade de agendamento elástico, ele pode detectar melhor as mudanças nos recursos do cluster.
Todos os recursos mencionados acima foram integrados à plataforma de computação heterogênea AI da Baidu Baige.
--FIM--
Leitura recomendada :
Falando sobre a aplicação do algoritmo gráfico na cena de atividade no antitrapaça
Sem servidor: prática de dimensionamento flexível com base em retratos de serviço personalizados
Método de decomposição de ação em aplicativo de animação de imagem
Estrada de aceleração de dados da plataforma de desempenho
Prática de arranjo do processo de produção de vídeo AIGC
Engenheiros da Baidu falam sobre compreensão de vídeo