Algoritmo KMP
1. Por que usar o algoritmo KMP?
Quando os caracteres de comparação não são iguais em cada processo de correspondência, não há necessidade de retroceder o ponteiro, mas use o resultado de "correspondência parcial" obtido para "deslizar a string de padrão para a direita o
máximo possível e continuar a comparação.
Codifique primeiro:
int Kmp (sq s,sq p,int next[]){
int c = 0; //主串移动变量
int d = 0;
while(c < s.lenght && d < p.lenght) //合法长度之内
{
if(d == -1 || s.string[c] == p.string[d])
{
/* d == -1 或者匹配成功就累加继续比较下一个*/
c++;
d++;
}
else
d = next[d]; //利用next数组进行移动,通过移动最长真前缀,避免不必要的回溯
}
if (d == p.lenght)
return c-p.lenght;//匹配成功,返回和模式串中第一个字符等的字符在主串的序号
else
return -1; //匹配失败
}
2. O que vem a seguir[]?
Quando o jth caractere no padrão é "incompatível" com o caractere correspondente na string principal, a posição do caractere no padrão que precisa ser comparada com o caractere na string principal. Como determinar a localização? É usar o array next[] para determinar a posição.
3. O processo de construção da próxima matriz
Codifique primeiro:
void GetNext (sq q,int next[]){
int i = 0,j = -1;
/*next数组,默认为-1,避免长串与短串首字符不匹配时,短串首字符为,next[0]=0,造成长短串匹配位置不更新,进入死循环*/
netx[0] = -1;
while (i < q.lenght){
/*自动匹配过程*/
if (j == -1 || q.string[i] == q.string[j]){
//(与首字符进行匹配 || 两个字符相等)
/*当与首字符匹配时,因为首字符的next[j]=-1,此时i++;j++; 主串后移一位,模式串也刚好从首字符开始进行匹配 */
i++;
j++;
next [i] = j;
}
else
j = next[j];
}
}
Construir o próximo array pode ser entendido como comparar a string padrão consigo mesma, procurando o maior prefixo verdadeiro e combinando a string principal com o próximo bit do maior prefixo verdadeiro. O princípio é explicado da seguinte forma:
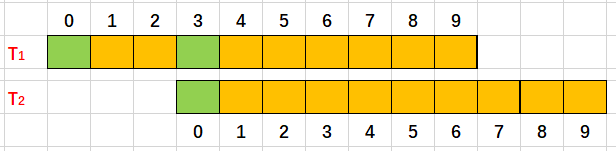
Aqui marcamos a string padrão em duas por conveniência. Tomamos T2 para combinar com T1. Descobrimos que a 0ª posição de T2 corresponde à 3ª posição de T1 com sucesso, pois T2 e T1 são a mesma string, então a 0ª posição de T1 deve ser a mesma que a 0ª posição de T2. Assim, podemos usar este princípio para calcular o prefixo verdadeiro máximo para cada posição.
Outro exemplo:
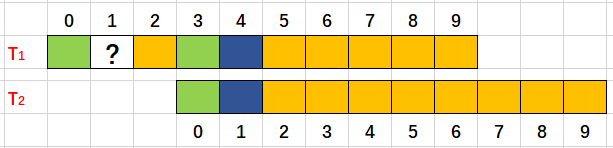
quando descobrimos que as posições 0 e 1 de T2 correspondem às posições 3 e 4 de T1 respectivamente, então qual é a cor da 1ª posição de T1?
A resposta é muito simples, é azul, porque é uma string em si.
Vemos que para cada correspondência bem-sucedida, o prefixo verdadeiro mais longo é +1.
Se o prefixo verdadeiro mais longo atual for next[i], depois que a correspondência for bem-sucedidanext[i+1]=next[i]+1
Se a string do padrão não corresponder conforme mostrado na figura abaixo

, T2 retrocede e T1 não se move
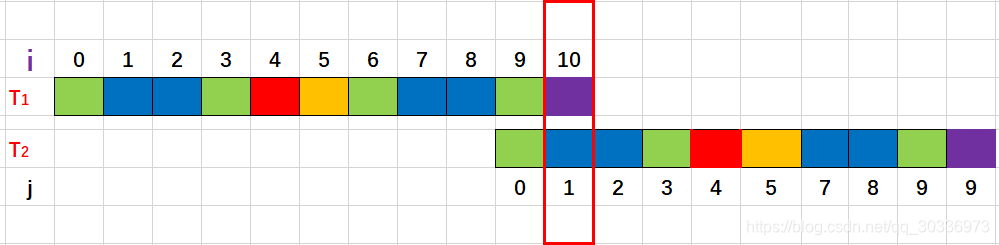
. Vemos que T2 precisa retroceder da posição 4 para a posição 1. Aqui next[4]=1, indicando que o comprimento do prefixo verdadeiro mais longo é 1, queremos apenas comparar os caracteres após o prefixo verdadeiro mais longo e queremos voltar para a posição rotulada como 1. Como o subscrito da string começa em 0, é equivalente a retroceder para a posição de next[4] e depois comparar novamente j = next[j]
Simplificando, quando a correspondência de T2 j号位com T1 não for bem- i号位sucedida, T2 precisa retroceder j号的最大真前缀的下一个位置e compará-la com o i-bit de T1. Se a correspondência for bem-sucedida, volte respectivamente, se a correspondência não for bem-sucedida, continue a encontrar o maior prefixo e correspondência verdadeiros.
A seguir, uma análise detalhada da correspondência bem-sucedida: conforme mostrado na

figura, quando combinamos a 9ª posição de T1 com a 3ª posição de T2, na verdade estamos calculando o próximo valor da 10ª posição de T1.
next[10] = next[9]+1
Como o valor de next[9] foi comparado, sabe-se que é 3. Observamos que é o 3º bit de T2 que corresponde a ele neste momento,
a saber:next[i+1] = next[i] + 1= j + 1;
i+1号位Para simplificar novamente, ao calcular a posição da próxima i号位correspondência quando T1 não corresponder, se a j号位correspondência com T2 for bem-sucedida, significa que já existe pelo menos um prefixo verdadeiro de comprimento j. Aqui, você só precisa executar +1 manipulação para fazê-lo mudar.
Vamos dar uma olhada na parte do código que corresponde com sucesso:
if (j = = -1 || q.string[i] == q.string[j]){
//(与首字符进行匹配 || 两个字符相等)
i++;
j++;
next [i] = j;
}
Descobrimos que no código, antes de atribuir next[i],i e j foram incrementados em 1, então escreva diretamente
próximo [i] = j;
4. Por que definir next[0]=-1?
Ao retroceder para o bit 0, a correspondência ainda não foi bem-sucedida. Atribuímos o bit 0 a next[j] a j, de modo que da próxima vez que inserirmos a instrução if para satisfazer as condições, a string principal e a string padrão serão movidas para trás, respectivamente para continuar combinando. Se você definir next[0]=0 de acordo com o princípio de encontrar next[j], sempre haverá correspondência malsucedida, formando um loop infinito.
5. Strings são armazenadas a partir da posição 1. O código tem algum efeito?
A resposta é definitivamente não.
Quando escrevemos manualmente next[j], devemos prestar atenção que o valor de next[j] neste momento não é apenas o comprimento do prefixo mais longo, mas também +1. As
duas diferenças são as seguintes:
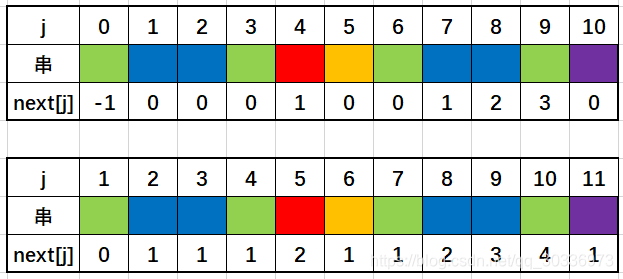
quando ocorre uma incompatibilidade e retrocedendo, dizemos Como a string é marcada a partir de 0, a correspondência continua retrocedendo até a posição do maior prefixo verdadeiro. O código é: i = next[j]. Quando começamos a marcar a string a partir de 1, as posições iniciais de i e j são armazenadas a partir do subscrito, portanto, no computador, a implementação do código permanece inalterada, sendo necessário apenas prestar atenção ao cálculo manual.