MapReuduce
1, conceito MapReduce
Mapreduce é uma estrutura de programação para programas de computação distribuída, cuja função principal é integrar código de lógica de negócios escrito por usuários e seus próprios componentes padrão em um programa de computação distribuído completo, que é executado simultaneamente em um cluster Hadoop.
Mapreduce é fácil de programar, tem boa escalabilidade e é adequado para processamento de dados em nível de petabyte; no entanto, não é adequado para processamento de dados em tempo real, computação de rotatividade e computação gráfica direcionada.
2. Conceito de projeto MapReduce
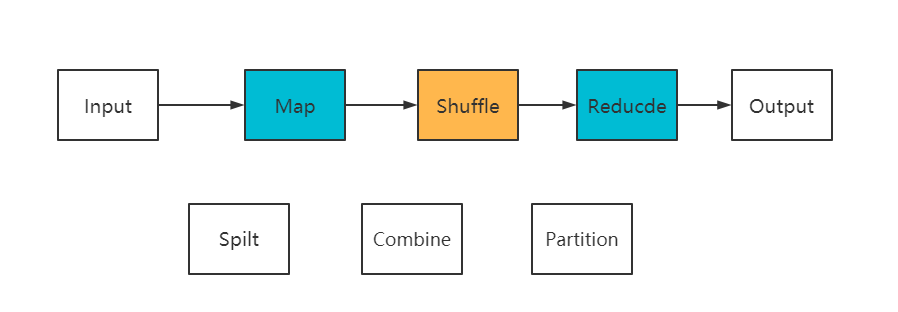
Os módulos de pensamento MapReduce são divididos principalmente em: Input、Spilt、Map、Shuffle、Reduceetc.
Input:Read lê dados; InputFormat divide o arquivo em vários InputSplits e RecordReaders converte InputSplits em pares de valores-chave <chave, valor> como a saída do mapa;
Spilt: Neste processo, os dados são divididos aproximadamente em linhas para obter dados do tipo <Key, Value>;
Map: Segmentação refinada para obter dados do tipo <Key, List>; classificar e particionar arquivos no buffer de anel, quando a quantidade de dados for grande, será sobrescrito no disco e o tamanho do buffer determinará o desempenho da tarefa de RM. O tamanho padrão é 100M. Neste processo, a tarefa Combinar pode ser definida, e a agregação inicial será realizada de acordo com a mesma Chave (partição>3 será combinada);
combine: Agregação preliminar de Merge, que inclui principalmente estratégias como número de partição e a mesma chave, e os dados na mesma partição são ordenados;
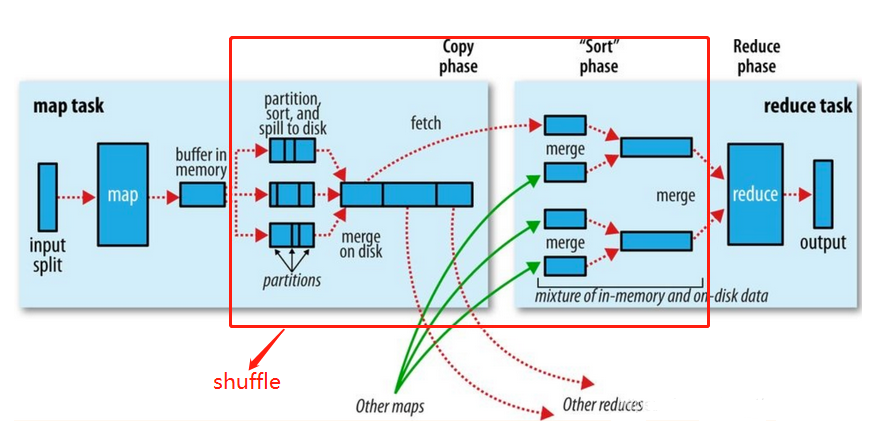
Shuufle: Embaralhando, ou seja, combinando os resultados de cada MapTask e enviando-os para Reduce. A saída desses dados do processo é um processo de Cópia. Esse processo envolve E/S de rede, que é um processo demorado e um processo central.
Reduzir: Mesclar os fragmentos de dados divididos. A classificação de mesclagem estará envolvida.
Partição: suporta partição de saída personalizada, o classificador padrão é HashPartition. Fórmula: (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
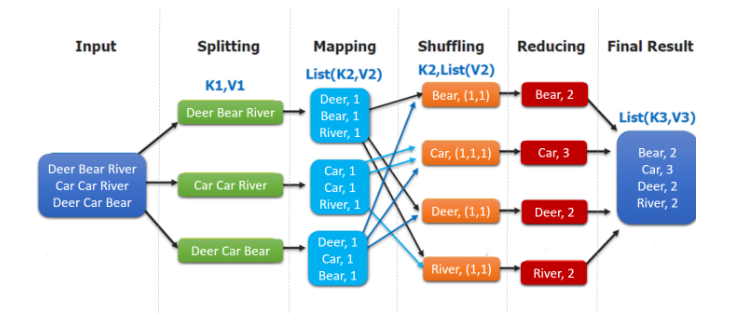
Vamos tentar explicar o processo específico de execução do MapReduce:
- Antes que o cliente envie a tarefa, (InputFormat) irá dividir os dados em fatias de acordo com a estratégia de configuração (SpiltSize padrão para blockSize 128M), e cada fatia é submetida a um MapTask (YARN é responsável pelo envio);
- O MapTask executa tarefas, gera pares <K, V> de acordo com a função map, envia os resultados para o buffer de anel e, em seguida, particiona, classifica e transborda;
- Shuffle, ou seja, divida os resultados do mapa em várias partições e atribua-os a várias tarefas de redução.Esse processo é chamado de Shuffle.
- Reduza, copie os dados da partição após o mapa (processo de busca, padrão 5 threads para executar a cópia) e execute a operação de mesclagem após a conclusão de todos.
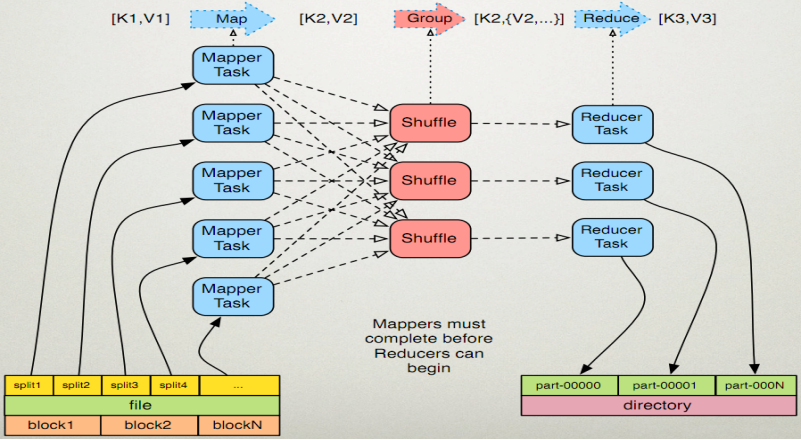
O recurso distribuído é que um trabalho tem várias MapperTasks, Shuffles e Reduces. A figura a seguir é uma boa ilustração do processo paralelo distribuído.
3. Escreva o programa mapreduce:
Estrutura de programação MR:
1) Estágio do mapeador
(1) Mapeador definido pelo usuário deve herdar sua própria classe pai
(2) Os dados de entrada do Mapper estão na forma de pares KV (o tipo de KV pode ser personalizado)
(3) A lógica de negócios no Mapper é escrita no método map()
(4) Os dados de saída do Mapper estão na forma de pares KV (o tipo de KV pode ser personalizado)
(5) O método map() (processo maptask) é chamado uma vez para cada <K, V>
2) Estágio redutor
(1) Redutor definido pelo usuário deve herdar sua própria classe pai
(2) O tipo de dados de entrada do Redutor corresponde ao tipo de dados de saída do Mapeador, que também é KV
(3) A lógica de negócios do Redutor é escrita no método reduce()
(4) O processo Reducetask chama o método reduce() uma vez para cada grupo de <k,v> grupos do mesmo k
3) Estágio do motorista
Todo o programa requer um Drvier para enviar, e o envio é um objeto de trabalho que descreve várias informações necessárias.
4, caso clássico de estatísticas de frequência de palavras do MapReduce
Agora escreva o primeiro programa MapReduce para implementar o caso WordCount:
Preparação do ambiente:
O IDEA cria um novo projeto maven, introduz as dependências principais da versão correspondente do hadoop e incorpora o arquivo de configuração no gerenciamento de recursos:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
1. Escreva um programa de mapa
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
//重写map方法,实现业务逻辑
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1,获取一行
String line = value.toString();
//2,切割
String[] words = line.split(" ");
for(String word:words){
k.set(word);
context.write(k,v);
}
}
}
2. Escreva o programa de redução
public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//子类构造方法中会有一个默认隐含的super()方法,用于调用父类构造
//super.reduce(key, values, context);
int sum = 0;
for(IntWritable count:values){
sum += count.get();
}
context.write(key,new IntWritable(sum));
}
}
3. Escreva a classe do driver
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1,获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance();
//2,设置jar加载路径
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
// 4 设置 map 输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置 Reduce 输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
Em seguida, use a ferramenta para transformar o arquivo principal em um pacote jar:
Em project structre->join Artifacts, selecione From moudles from dependencies, selecione sua própria mainclasse e defina o jardiretório de saída do pacote; em seguida, através da barra de ferramentas Build, selecione build Artifacts->buildpara obter o jarpacote. Por fim, por meio da FTPferramenta , envie o jarpacote para o ambiente de cluster e use o comando a seguir para executar.
hadoop jar jar包名 main类的全类名 输入目录 输出目录

5. Habilidades de desenvolvimento
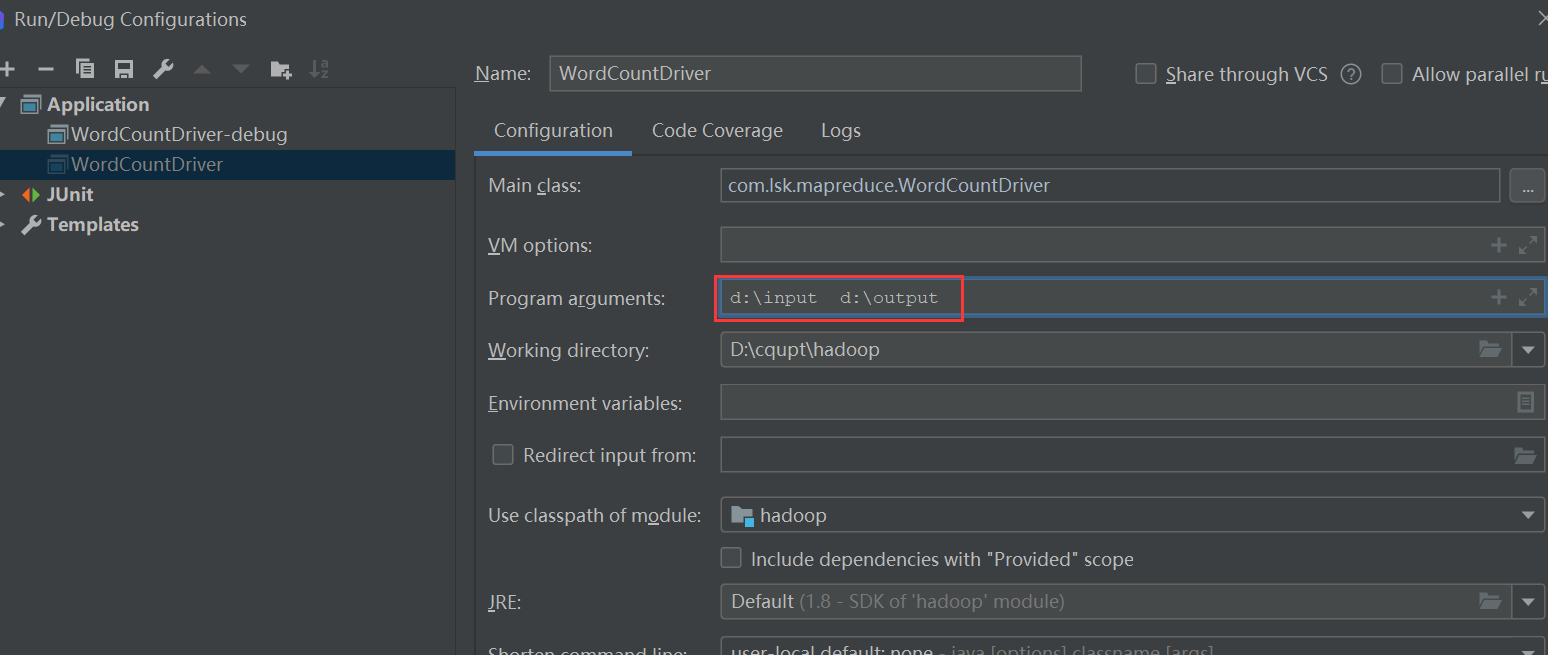
Então, como você executa o mapreduceprograma ?
No desenvolvimento de produção real, o programa precisa ser testado localmente antes de ser jarempacotado liberado para o cluster.
Primeiro, precisamos definir a mainclasse configuratione adicionar os parâmetros de entrada e saída antecipadamente:
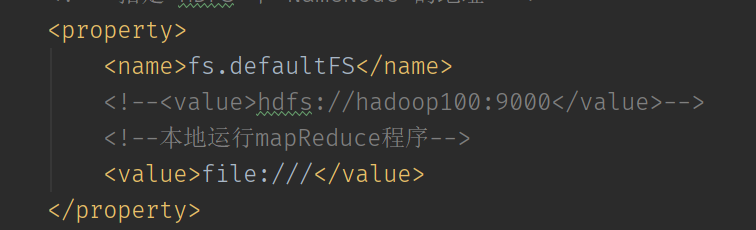
Em seguida, defina para modificar o sistema de arquivos para o modo de operação local:
Link de referência