Diretório de artigos
- prefácio
- 1. O que é leveldb?
- Em segundo lugar, o uso de leveldb
-
- 1. Abra um banco de dados
- 2.Estado
- 3. Feche um banco de dados
- 4. Leitura e gravação do banco de dados
- 5. Atualizações atômicas
- 6. Gravação síncrona
- 7. Simultaneidade
- 8. Iteradores
- 9. Instantâneos instantâneos
- 10. Fatia
- 11. Comparador
- 12. Compatibilidade com versões anteriores
- 13. Ajuste de desempenho
- 14. Somas de verificação
- 15. Tamanho aproximado do espaço
- 16. Variáveis de ambiente
- 17. Portátil
- 3. Exploração do princípio
- Resumir
prefácio
O recrutamento de outono está quase no fim e a empresa para a qual irei está basicamente determinada. Não há teste escrito, entrevista e estágio, e estou livre recentemente.
Pretendo fazer alguns projetos de código aberto com meus amigos, e a direção provisória é o armazenamento de dados. Portanto, essas duas semanas também estão aprendendo conhecimentos relacionados ao armazenamento de dados, como SSD, sistema de arquivos subjacente, lsm-tree e assim por diante.
Sempre tive o hábito de registrar o que aprendi, mas recentemente está registrado no wps na forma de um mapa cerebral do conhecimento. Considerando que não publico uma postagem técnica no blog há muito tempo, ainda planejo separar o que aprendi recentemente e gravá-lo no blog na forma de notas para futura revisão e compartilhamento para aprendizado conjunto.
1. O que é leveldb?
LevelDB é uma biblioteca rápida de armazenamento de valor-chave escrita no Google que fornece um mapeamento ordenado de chaves de string para valores de string.
Leveldb é um sistema KV para armazenamento persistente.
Na verdade, é o que costumamos chamar de mecanismo de armazenamento subjacente, ou banco de dados. O mecanismo de armazenamento rocketdb usado na parte inferior do redis que geralmente sabemos que é uma evolução do leveldb.
Em segundo lugar, o uso de leveldb
Aqui está uma experiência de olhar para o código-fonte. Quando você obtiver o código-fonte de um projeto desconhecido, dê uma olhada em como ele é usado. Comece com o uso e use-o como um ponto de entrada para ler o código-chave, que irá ser muito mais fácil.
ps: No diretório doc do projeto leveldb, há um documento index.md que apresenta seu uso. A seguir, a maioria são trechos de sua tradução.
1. Abra um banco de dados
O banco de dados leveldb tem um nome, que corresponde a um diretório no sistema de arquivos, e todo o conteúdo do banco de dados é armazenado nesse diretório. O exemplo a seguir mostra como abrir um banco de dados e criá-lo, se necessário:
#include <cassert>
#include "leveldb/db.h"
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
assert(status.ok());
...
Se você deseja disparar uma exceção quando o banco de dados já existe, adicione a seguinte linha de configuração antes da chamada para leveldb::DB::Open:
options.error_if_exists = true;
2.Estado
Você deve ter notado o tipo de retorno de leveldb::Status acima, a maioria dos métodos em leveldb retornará esse tipo de valor ao encontrar um erro, você pode verificar se está ok e imprimir a mensagem de erro relevante:
leveldb::Status s = ...;
if (!s.ok()) cerr << s.ToString() << endl;
3. Feche um banco de dados
Quando o banco de dados não estiver mais em uso, basta excluir o objeto de banco de dados diretamente da seguinte maneira:
... open the db as described above ...
... do something with db ...
delete db;
4. Leitura e gravação do banco de dados
leveldb fornece os métodos Put, Delete e Get para modificar/consultar o banco de dados. O código a seguir mostra que o valor correspondente a key1 é movido para key2.
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) s = db->Put(leveldb::WriteOptions(), key2, value);
if (s.ok()) s = db->Delete(leveldb::WriteOptions(), key1);
5. Atualizações atômicas
Deve-se observar que na seção anterior, se o processo travar depois de colocar a chave2 e antes de excluir a chave1, o mesmo valor será armazenado em várias chaves. Problemas semelhantes podem ser evitados usando WriteBatch para aplicar atomicamente um conjunto de operações.
#include "leveldb/write_batch.h"
...
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) {
leveldb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(leveldb::WriteOptions(), &batch);
}
WriteBatch contém uma série de operações que serão aplicadas ao banco de dados e essas operações serão executadas na ordem em que foram adicionadas. Observe que executamos Delete primeiro e depois Put, para que não percamos dados por engano se key1 e key2 forem iguais.
Além da atomicidade, o WriteBatch também pode acelerar o processo de atualização, pois um grande número de operações independentes podem ser adicionadas ao mesmo lote e executadas de uma só vez.
6. Gravação síncrona
Por padrão, cada operação de gravação do leveldb é assíncrona: o processo retorna imediatamente após lançar o conteúdo a ser gravado no sistema operacional, e a transmissão da memória do sistema operacional para o armazenamento persistente subjacente é realizada de forma assíncrona.
Você pode ativar o sinalizador de sincronização para uma operação de gravação específica: write_options.sync = true, para aguardar até que os dados sejam realmente gravados no armazenamento persistente antes de retornar (em sistemas Posix, isso é feito chamando fsync(…) antes da operação de gravação retorna ou fdatasync(…) ou msync(…, MS_SYNC)).
leveldb::WriteOptions write_options;
write_options.sync = true;
db->Put(write_options, ...);
As gravações assíncronas são normalmente 1.000 vezes mais rápidas do que as síncronas. A desvantagem das gravações assíncronas é que as últimas operações de atualização podem ser perdidas se a máquina travar. Observe que apenas a falha do processo de gravação (em vez de reiniciar a máquina) não causará nenhuma perda, porque mesmo que o sinalizador de sincronização seja falso, a operação de gravação foi enviada da memória do processo para o sistema operacional antes que o processo seja encerrado.
As gravações assíncronas geralmente são seguras de usar. Por exemplo, se você deseja gravar uma grande quantidade de dados no banco de dados, se perder as últimas operações de atualização, também poderá refazer todo o processo de gravação. Se a quantidade de dados for muito grande, um ponto de otimização é adotar uma solução híbrida e executar uma gravação síncrona para cada N operações de gravação assíncrona. Se ocorrer uma falha durante o período, reinicie a partir da última operação de gravação síncrona bem-sucedida. (As operações de gravação síncronas também podem atualizar um sinalizador que descreve onde reiniciar em caso de falha)
WriteBatch pode ser usado como um substituto para operações de gravação assíncrona. Várias operações de atualização podem ser colocadas no mesmo WriteBatch e, em seguida, gravadas juntas por meio de uma gravação síncrona (ou seja, write_options.sync = true).
7. Simultaneidade
Um banco de dados só pode ser aberto por um processo por vez. O leveldb adquirirá um bloqueio do sistema operacional para impedir que vários processos abram o mesmo banco de dados ao mesmo tempo. Dentro de um único processo, o mesmo objeto leveldb::DB pode ser usado com segurança por vários threads simultâneos, ou seja, diferentes threads podem gravar, obter iteradores ou chamar Get (a implementação leveldb garante a sincronização necessária). Mas outros objetos, como Iterator ou WriteBatch, requerem garantias de sincronização externa.Se dois threads compartilham tais objetos, eles precisam usar seus próprios bloqueios para acesso mutuamente exclusivo. Consulte o arquivo de cabeçalho correspondente para obter detalhes.
8. Iteradores
O caso de uso a seguir mostra como imprimir todos os pares (chave, valor) no banco de dados.
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
cout << it->key().ToString() << ": " << it->value().ToString() << endl;
}
assert(it->status().ok()); // Check for any errors found during the scan
delete it;
O caso de uso a seguir mostra como imprimir dados no intervalo [início, limite):
for (it->Seek(start);
it->Valid() && it->key().ToString() < limit;
it->Next()) {
...
}
Claro, você também pode percorrer no sentido inverso (observe que o percurso reverso pode ser mais lento do que o percurso direto, consulte o benchmark de desempenho de leitura anterior para obter detalhes):
for (it->SeekToLast(); it->Valid(); it->Prev()) {
...
}
9. Instantâneos instantâneos
Os instantâneos fornecem exibições consistentes somente leitura de todo o armazenamento KV. Se ReadOptions::snapshot não for nulo, significa que a operação de leitura deve atuar em uma versão específica do banco de dados; se for nulo, a operação de leitura atuará em um instantâneo implícito da versão atual.
Os instantâneos são criados chamando o método DB::GetSnapshot():
leveldb::ReadOptions options;
options.snapshot = db->GetSnapshot();
... apply some updates to db ...
leveldb::Iterator* iter = db->NewIterator(options);
... read using iter to view the state when the snapshot was created ...
delete iter;
db->ReleaseSnapshot(options.snapshot);
Observe que quando um instantâneo não é mais usado, ele deve ser liberado por meio da interface DB::ReleaseSnapshot.
10. Fatia
it->key() it->value()O valor retornado pela chamada and é leveldb::Slicedo tipo (semelhante ao slice slice na linguagem go). Slice é uma estrutura de dados simples que contém um comprimento e um ponteiro para uma matriz de bytes externa. Retornar um Slice é mais eficiente do que retornar um std::string porque não há necessidade de copiar implicitamente um grande número de chaves e valores. Além disso, os métodos leveldb não retornam \0strings estilo C de terminação, pois as chaves e valores do leveldb permitem \0bytes.
Strings estilo C++ e strings com terminação nula estilo C são facilmente convertidas em um Slice:
leveldb::Slice s1 = "hello";
std::string str("world");
leveldb::Slice s2 = str;
Um Slice também é facilmente convertido de volta para uma string no estilo C++:
std::string str = s1.ToString();
assert(str == std::string("hello"));
Tenha cuidado ao usar o Slice, cabe ao chamador garantir que a matriz de bytes externa apontada pelo Slice seja válida. Por exemplo, o seguinte código tem um bug:
leveldb::Slice slice;
if (...) {
std::string str = ...;
slice = str;
}
Use(slice);
Quando a instrução if terminar, str será destruído e o ponteiro para Slice também desaparecerá e haverá problemas se for usado posteriormente.
11. Comparador
Nos exemplos anteriores, é utilizada a função de comparação padrão, ou seja, comparação byte a byte e comparação lexicográfica. Você pode personalizar a função de comparação e passá-la ao abrir o banco de dados. Você só precisa herdar leveldb::Comparator e definir a lógica relacionada. Aqui está um exemplo:
class TwoPartComparator : public leveldb::Comparator {
public:
// Three-way comparison function:
// if a < b: negative result
// if a > b: positive result
// else: zero result
int Compare(const leveldb::Slice& a, const leveldb::Slice& b) const {
int a1, a2, b1, b2;
ParseKey(a, &a1, &a2);
ParseKey(b, &b1, &b2);
if (a1 < b1) return -1;
if (a1 > b1) return +1;
if (a2 < b2) return -1;
if (a2 > b2) return +1;
return 0;
}
// Ignore the following methods for now:
const char* Name() const {
return "TwoPartComparator"; }
void FindShortestSeparator(std::string*, const leveldb::Slice&) const {
}
void FindShortSuccessor(std::string*) const {
}
};
Agora crie um banco de dados com este comparador personalizado:
TwoPartComparator cmp;
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
options.comparator = &cmp;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
...
12. Compatibilidade com versões anteriores
Name() O resultado retornado pelo método Comparator será vinculado ao banco de dados quando o banco for criado e será verificado toda vez que for aberto.Se o nome for alterado, leveldb::DB::Open a chamada para falhará. Portanto, altere o nome do comparador se e somente se o novo formato de chave e a função de comparação não forem compatíveis com o banco de dados existente e os dados existentes não forem mais necessários. Em suma, um banco de dados pode corresponder apenas a um comparador, e o comparador é determinado exclusivamente por seu nome. Uma vez que o nome ou a lógica do comparador é modificado, a lógica de operação do banco de dados estará errada. Afinal, leveldb é um KV ordenado armazenar.
E se você tiver que modificar a lógica de comparação? Você pode evoluir seu formato de chave pouco a pouco de acordo com o pré-planejamento, observe que o planejamento pré-evolução é muito importante. Por exemplo, você pode armazenar um número de versão no final de cada chave (na maioria dos cenários, um byte é suficiente), quando quiser mudar para um novo formato de chave (como as chaves processadas por TwoPartComparator no exemplo acima), Então o que precisa ser feito é:
- manter o mesmo nome do comparador
- Incrementar o número da versão das novas chaves
- Modifique a função de comparação para usar o número da versão para decidir como classificar
13. Ajuste de desempenho
O desempenho do leveldb é ajustado modificando os valores padrão dos tipos definidos em include/leveldb/options.h.
Tamanho do bloco
leveldb organiza chaves adjacentes no mesmo bloco, e um bloco é a unidade básica de transferência de dados entre a memória e o armazenamento persistente. O tamanho padrão do bloco descompactado é de cerca de 4 KB. Os aplicativos que verificam frequentemente grandes quantidades de dados em lotes podem querer aumentar esse valor, enquanto os aplicativos que apenas fazem "leitura de ponto" dos dados podem querer que esse valor seja menor. No entanto, não há evidências de que o desempenho seja melhor com valores menores que 1KB ou maiores que alguns MB. Outra coisa a observar é que, com um tamanho de bloco maior, a eficiência da compactação será mais eficiente
compressão
Cada bloco é compactado individualmente antes de ser gravado no armazenamento persistente. A compactação é habilitada por padrão, porque o algoritmo de compactação padrão é muito rápido e desativa automaticamente a compactação de dados incompactáveis. Existem poucos cenários em que os usuários desejam desativar a compactação completamente, a menos que os benchmarks mostrem que desativar a compactação melhorará significativamente o desempenho. A compactação pode ser desativada da seguinte maneira:
leveldb::Options options;
options.compression = leveldb::kNoCompression;
... leveldb::DB::Open(options, name, ...) ....
cache
O conteúdo do banco de dados é armazenado em um conjunto de arquivos no sistema de arquivos. Cada arquivo armazena uma série de blocos compactados. Se options.block_cache for não NULL, ele será usado para armazenar em cache o conteúdo do bloco descompactado usado com frequência.
#include "leveldb/cache.h"
leveldb::Options options;
options.block_cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache
leveldb::DB* db;
leveldb::DB::Open(options, name, &db);
... use the db ...
delete db
delete options.block_cache;
Observe que o cache armazena dados não compactados, portanto, seu tamanho deve ser definido de acordo com o tamanho dos dados solicitados pelo aplicativo. (O cache de buffer dos dados compactados é deixado para o cache de buffer do sistema operacional ou a implementação Env definida pelo usuário.)
Ao executar uma operação de leitura de dados grandes, o aplicativo pode querer cancelar a função de armazenamento em cache, para que a leitura de dados grandes não faça com que a maioria dos dados no cache atual seja substituído. Podemos fornecer um iterador separado para conseguir isso propósito:
leveldb::ReadOptions options;
options.fill_cache = false;
leveldb::Iterator* it = db->NewIterator(options);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
...
}
Esquema de teclas
Observe que a unidade de transmissão de disco e cache é um bloco, e as chaves adjacentes (ordenadas) estão sempre no mesmo bloco, portanto o aplicativo pode juntar as chaves que precisam ser acessadas e juntar as chaves pouco usadas. uma região de keyspace separada para melhorar o desempenho.
Como exemplo, suponha que estamos implementando um sistema de arquivos simples baseado em leveldb. Os tipos de dados que pretendemos armazenar neste sistema de arquivos são os seguintes:
filename -> permission-bits, length, list of file_block_ids
file_block_id -> data
Podemos adicionar um prefixo de caractere à chave que representa o nome do arquivo acima, como '/' e, em seguida, adicionar outro prefixo diferente à chave que representa file_block_id, como '0', para que essas chaves para finalidades diferentes tenham seus próprios espaços de chave independentes área, não precisamos ler e armazenar em cache grandes blocos de dados de conteúdo de arquivo ao verificar metadados.
filtro
Tendo em vista a forma de organização dos dados leveldb no disco, uma chamada Get() pode envolver várias operações de leitura de disco, e o mecanismo FilterPolicy configurável pode ser usado para reduzir significativamente o número de leituras de disco.
leveldb::Options options;
// 设置启用基于布隆过滤器的过滤策略
options.filter_policy = NewBloomFilterPolicy(10);
leveldb::DB* db;
// 用该设置打开数据库
leveldb::DB::Open(options, "/tmp/testdb", &db);
... use the database ...
delete db;
delete options.filter_policy;
O código acima associa uma estratégia de filtragem baseada em filtro Bloom ao banco de dados. A filtragem baseada em filtro Bloom depende do fato de que uma parte dos bits de cada chave (no exemplo acima, 10 bits, porque o parâmetro que passamos para NewBloomFilterPolicy é 10), esse filtro reduzirá as operações desnecessárias de leitura de disco na chamada Get() em cerca de 100 vezes, e o aumento no número de bits usados para o filtro por chave reduzirá ainda mais as leituras de disco O número de vezes, é claro, ocupará mais espaço de memória. Recomendamos definir uma política de filtro para aplicativos em que o conjunto de dados não pode ser totalmente armazenado na memória e há um grande número de leituras aleatórias.
Se você estiver usando um comparador personalizado, verifique se a estratégia de filtro que está usando é compatível com seu comparador. Por exemplo, se um comparador ignora espaços à direita ao comparar chaves, NewBloomFilterPolicy não deve coexistir com esse comparador. Em vez disso, o aplicativo deve fornecer uma estratégia de filtro personalizada e também deve ignorar os espaços à direita da chave, conforme mostrado no exemplo a seguir:
class CustomFilterPolicy : public leveldb::FilterPolicy {
private:
FilterPolicy* builtin_policy_;
public:
CustomFilterPolicy() : builtin_policy_(NewBloomFilterPolicy(10)) {
}
~CustomFilterPolicy() {
delete builtin_policy_; }
const char* Name() const {
return "IgnoreTrailingSpacesFilter"; }
void CreateFilter(const Slice* keys, int n, std::string* dst) const {
// Use builtin bloom filter code after removing trailing spaces
std::vector<Slice> trimmed(n);
for (int i = 0; i < n; i++) {
trimmed[i] = RemoveTrailingSpaces(keys[i]);
}
return builtin_policy_->CreateFilter(&trimmed[i], n, dst);
}
};
Obviamente, você também pode fornecer sua própria estratégia de filtro baseada em filtro não Bloom, consulte para obter detalhes leveldb/filter_policy.h.
14. Somas de verificação
leveldb associa somas de verificação com todos os dados que armazena no sistema de arquivos e há dois controles separados para essas somas de verificação:
ReadOptions::verify_checksums pode ser definido como true para forçar a verificação de todos os dados lidos do sistema de arquivos. O padrão é falso, ou seja, essa validação não será executada.
Options::paranoid_checks é definido como true antes do banco de dados ser aberto, para que o banco de dados relate um erro assim que detectar corrupção de dados. Dependendo de onde o banco de dados está danificado, o erro pode ser relatado depois que o banco de dados é aberto ou quando uma determinada operação é executada posteriormente. Essa configuração está desabilitada por padrão, ou seja, o banco de dados que estiver parcialmente danificado no armazenamento persistente pode continuar sendo utilizado.
Se o banco de dados estiver corrompido (o que pode não ser possível quando Options::paranoid_checks estiver ativado), a função leveldb::RepairDB() pode ser usada para reparar o máximo de dados possível.
15. Tamanho aproximado do espaço
O método GetApproximateSizes é usado para obter o tamanho aproximado do sistema de arquivos ocupado por um ou mais intervalos de chave (unidade, byte)
leveldb::Range ranges[2];
ranges[0] = leveldb::Range("a", "c");
ranges[1] = leveldb::Range("x", "z");
uint64_t sizes[2];
db->GetApproximateSizes(ranges, 2, sizes);
O resultado do código acima é que size[0] armazena o número aproximado de bytes no sistema de arquivos correspondente ao intervalo [a…c). size[1] salva o número aproximado de bytes no sistema de arquivos correspondente ao intervalo de chaves [x…z).
16. Variáveis de ambiente
Todas as operações de arquivo e outras chamadas do sistema operacional iniciadas por leveldb são roteadas para um objeto leveldb::Env. Os usuários também podem fornecer suas próprias implementações de Env para um controle mais preciso. Por exemplo, se um aplicativo deseja introduzir um atraso artificial para o arquivo IO do leveldb para limitar o impacto do leveldb em outros aplicativos no mesmo sistema:
// 定制自己的 Env
class SlowEnv : public leveldb::Env {
... implementation of the Env interface ...
};
SlowEnv env;
leveldb::Options options;
// 用定制的 Env 打开数据库
options.env = &env;
Status s = leveldb::DB::Open(options, ...);
17. Portátil
leveldb pode ser portado para uma plataforma particular se fornecer implementações de tipos/métodos/funções exportadas por leveldb/port/port.h, veja leveldb/port/port_example.h para mais detalhes.
Além disso, novas plataformas também podem exigir uma nova implementação padrão leveldb::Env. Para obter detalhes, consulte leveldb/util/env_posix.h para implementação.
3. Exploração do princípio
1. Comece com lsm-tree
A ideia de design do leveldb começa com a estratégia de armazenamento do lsm-tree.
lsm-tree é essencialmente uma estratégia de armazenamento e um método para otimizar o desempenho de gravação.
Ele altera nossa operação usual de adição, exclusão, modificação e verificação de pares chave-valor kv de gravação aleatória para gravação sequencial , melhorando assim o desempenho da gravação.
A ideia central do lsm-tree é manter uma estrutura de dados ordenada na memória (pode ser uma lista de atalhos, árvore classificada, etc.). Quando uma operação de gravação entra, apenas modificamos a estrutura de dados na memória. Para evitar o problema de perda de dados causado por circunstâncias especiais (como tempo de inatividade e falha do processo) durante esta modificação, a modificação será convertida em um log neste momento e será gravada no arquivo de log para evitar dados perda.
Quando o tamanho da estrutura de dados na memória excede um determinado limite e, em seguida, a estrutura de dados na memória persiste no disco rígido, a gravação neste momento também é uma gravação sequencial. O desempenho vem naturalmente.
Mas isso não é isento de desvantagens: a desvantagem é que, quando eu consulto, se o valor da chave não estiver na memória, tenho que procurá-lo no disco rígido. Neste momento, ele é dividido em vários pequenos arquivos diferentes para o conteúdo que procuramos, portanto, em casos extremos, pode ser lido várias vezes para encontrar o par chave-valor correspondente.
2. Projeto de arquitetura e ideias básicas de projeto
2.1 Projeto de Arquitetura
O design da arquitetura do leveldb é o seguinte:
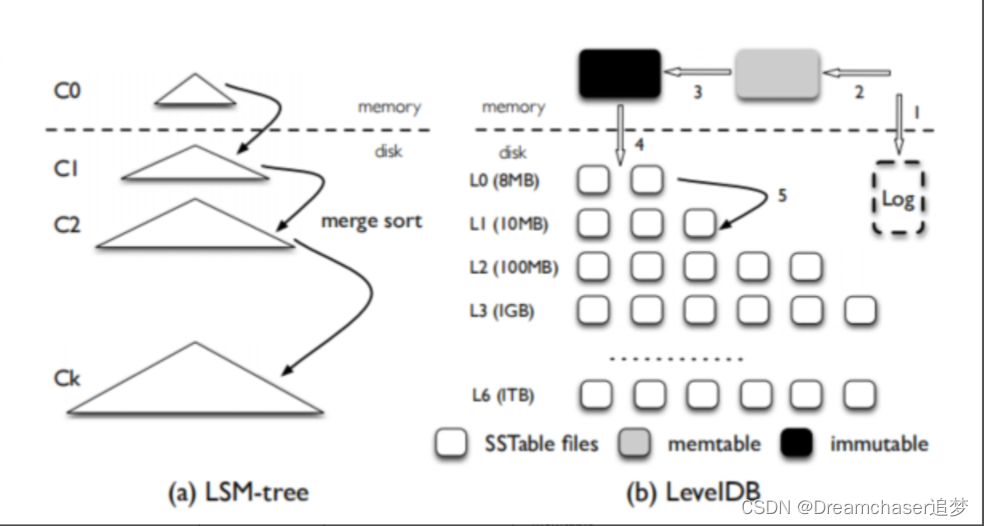
Existem várias funções na figura acima:
- Log: arquivo de log do disco
- memtable, imutável: tabela de salto ordenada na memória, memtable pode ser gravada, imutável significa estrutura de dados fechada, somente leitura, aguardando para ser persistido no disco
- Arquivos SSTable: arquivos de tabela de strings classificados (SSTable), divididos em sete níveis
A ideia principal é usar o armazenamento lsm-tree
2.2 Processo de leitura e gravação
A seguir, vamos explicar brevemente o diagrama de arquitetura acima através da operação no processo de leitura e escrita.
processo de escrita de dados
- Converta esta inserção em um log e insira-o no arquivo de log
- Aplique os dados inseridos desta vez ao memtable na memória
Normalmente, as duas operações acima completam uma gravação de dados. Em comparação com a gravação aleatória tradicional, este método usa apenas uma gravação sequencial e gravação de memória, e o desempenho é naturalmente muito mais rápido.
Processo de exclusão de dados
A exclusão de dados não apaga realmente os dados do disco, mas assume a forma de marcação.
- Quando os dados ainda estão na memória e não persistem no disco, você só precisa excluir a estrutura de dados correspondente na memória neste momento
- Quando os dados forem persistidos no disco, marcarei uma Chave para exclusão neste momento, indicando que foi excluído. Quanto à exclusão real, aguardará até que a operação de compactação seja executada posteriormente
Processo de modificação de dados
A modificação aqui pode ser entendida como excluir primeiro e depois inserir. O valor antigo se tornará inválido, mas não será realmente excluído.
Processo de consulta de dados
- Encontrar memtable e imutável na memória
- Caso não seja encontrado na memória, então é necessário buscar o disco, neste momento, os componentes serão buscados a partir de C0 de forma cascateada até que os dados desejados sejam encontrados no menor componente Ci.
A primeira vez que você entender leveldb, você pode se perguntar o que é L0-L6.
Na verdade, essa também é a inovação do leveldb e a origem de seu nome. Não disse antes que a pesquisa lsm-tree precisa encontrar todos os arquivos?
Claro, você pode pesquisar dados de forma aleatória e sequencial, mas não se esqueça de que a pesquisa de dados geralmente é localizada e os dados quentes geralmente têm mais oportunidades de serem acessados.
Assim, leveldb projeta arquivos de sete níveis. Sua ideia é a seguinte:
- o armazenamento de arquivos em disco leveldb é dividido em 7 níveis (L0-L6), quanto maior o nível, maior o nível de quantidade e maior a capacidade de armazenamento (a diferença é a ordem de grandeza)
- Os dados persistentes que acabaram de ser gravados geralmente estão no nível L0. Quando o arquivo atingir um determinado tamanho, um novo arquivo será aberto para gravação
- Quando o número de arquivos atingir o limite, ele compactará vários arquivos no nível no tamanho especificado pelo próximo nível e, em seguida, entrará no próximo nível
O efeito disso é que os dados modificados recentemente são frequentemente acessados primeiro (porque o nível é pequeno), mas essa parte dos dados geralmente representa uma pequena proporção e os dados mais antigos terão uma prioridade de acesso menor.
A vantagem disso é que ele obedece ao princípio da localidade de tempo e, teoricamente, o acesso aos dados será mais rápido.
2.3 Compressão
Ao escrever mais e mais, o número de arquivos de um determinado nível também aumentará.
E sabemos que os descritores de arquivo do sistema de arquivos são limitados e muitos arquivos causarão o problema de eficiência de pesquisa reduzida.
Além disso, mencionamos anteriormente que a operação de exclusão de leveldb não é uma exclusão real, mas uma marca primeiro, portanto, inevitavelmente causará o problema de armazenamento redundante.
Portanto, quando um limite for atingido em um nível, a compactação será acionada e vários arquivos desse nível serão compactados para o próximo nível. A compactação aqui é a fusão de vários arquivos em um ou mais novos arquivos. Esse processo pode ser entendido da seguinte forma: várias pequenas árvores ordenadas são mescladas em uma grande árvore ordenada, e os dados que foram marcados para exclusão serão removidos durante esse processo.
Outra razão muito importante é que a necessidade de compactação decorre dos requisitos de design do LSM, ou seja, acesso sequencial ao disco e manutenção dos dados classificados no disco .
3. Composição do arquivo
Para o estudo do armazenamento de dados, é necessário estudar sua composição de arquivos persistentes.
Arquivos de registro
Cada atualização será gravada neste arquivo. Quando o tamanho do arquivo atingir o limite (4KB por padrão), ele será convertido em uma tabela classificada e um novo log será criado para lidar com a próxima atualização.
tabelas classificadas
- O arquivo que realmente armazena os dados
- Quanto maior o nível, maior o nível de quantidade e maior a capacidade de armazenamento
Manifesto
contente:
- O nome do arquivo da tabela classificada para cada nível
- intervalo de chaves
- alguns outros metadados
Este arquivo é criado sempre que o banco de dados é reaberto
atual
Um arquivo de texto que registra os nomes dos arquivos MANIFEST mais recentes
registros de informações
As informações serão impressas em um arquivo chamado LOG e LOG.old
outro
Também podem existir outros arquivos usados para outros fins (LOCK, *.dbtmp)
4. Recuperação de dados
O que é considerado aqui é o processo de refazer as operações de dados sequencialmente de acordo com os arquivos de log gravados anteriormente após o tempo de inatividade. As etapas são as seguintes:
- Leia CURRENT para encontrar o nome do MANIFEST confirmado mais recentemente
- Leia o arquivo MANIFEST nomeado
- Limpe arquivos antigos
- Converter blocos de log para o novo nível 0 sstable
- Comece a direcionar novas gravações para um novo arquivo de log com sequência de recuperação
Resumir
leveldb é um mecanismo de armazenamento projetado com base em lsm-tree, que pode melhorar muito a eficiência das operações de gravação e é adequado para cenários em que são executadas mais gravações do que leituras.