contente
Algoritmo de correspondência de força bruta (BF)
Complexidade de tempo do algoritmo BF
Complexidade de tempo do algoritmo KMP
Algoritmo de correspondência de força bruta (BF)
conceito básico
O algoritmo BF, o algoritmo Brute Force , é um algoritmo comum de correspondência de padrões. A ideia do algoritmo BF é combinar o primeiro caractere da string de destino S com o primeiro caractere da string padrão. Se forem iguais, continue para comparar S. O segundo caractere de S e o segundo caractere de T. Se não forem iguais, compare o segundo caractere de S e o primeiro caractere de T e compare-os sucessivamente até obter o resultado final correspondente. O algoritmo BF é um algoritmo de força bruta.
Analisando Algoritmos BF
Apenas olhar para a definição é obscuro e difícil de entender. A seguir, darei um exemplo para aprender com você:
Suponha que forneçamos a string "ababcabcdabcde" como a string principal e, em seguida, forneçamos a substring "abcd", agora precisamos descobrir se a substring aparece na string principal, retornar o primeiro subscrito correspondente na string principal, fail retorna - 1.

Para este problema, podemos facilmente pensar nisso: combinando da esquerda para a direita, se os caracteres forem iguais, todos serão deslocados para trás em um; Comece com 0 subscrito, da próxima vez comece com 1 subscrito)
Podemos inicializar assim:

De acordo com nossas ideias, então precisamos comparar se os números apontados pelo ponteiro i e pelo ponteiro j são consistentes. Se forem consistentes, eles retrocederão. Se forem inconsistentes, conforme mostrado abaixo:

Se b e d não forem iguais, então o ponteiro i é retornado para a próxima posição do ponteiro agora (o ponteiro começou do subscrito 0), e o ponteiro j é retornado para o subscrito 0 e começa novamente.

Código
Com base na análise acima, vamos começar a escrever o código:
Código C:
#include<stdio.h>
#include<string.h>
#include<assert.h>
int BF(char* str1, char* str2)
{
assert(str1 != NULL && str2 != NULL);
int len1 = strlen(str1);//主串的长度
int len2 = strlen(str2);//子串的长度
int i = 0;//主串的起始位置
int j = 0;//子串的起始位置
while (i < len1 && j < len2)
{
if (str1[i] == str2[j])
{
i++;//相等i和j都向后移动一位
j++;
}
else {//不相等
i = i - j + 1;//i回退
j = 0;//j回到0位置
}
}
if (j >= len2) {//子串遍历玩了说明已经找到与其匹配的子串
return i - j;
}
else {
return -1;
}
}
int main()
{
printf("%d\n", BF("ababcabcdabcde", "abcd"));//测试,为了验证代码是否正确尽量多举几个例子
printf("%d\n", BF("ababcabcdabcde", "abcde"));
return 0;
}
código java:
public class Test {
public static int BF(String str,String sub) {
if(str == null || sub == null) return -1;
int strLen = str.length();
int subLen = sub.length();
int i = 0;
int j = 0;
while (i < strLen && j < subLen) {
if(str.charAt(i) == sub.charAt(j)) {
i++;
j++;
}else {
i = i-j+1;
j = 0;
}
} i
f(j >= subLen) {
return i-j;
} r
eturn -1;
}
public static void main(String[] args) {
System.out.println(BF("ababcabcdabcde","abcd"));
System.out.println(BF("ababcabcdabcde","abcde"));
}
}Um pequeno teste
Através do estudo acima, tenho uma compreensão preliminar do algoritmo BF. Para ter um entendimento e aplicação mais profundos, responderei às seguintes perguntas do teste com você:
Perguntas de teste aqui >> Implemente strStr()
Os parceiros interessados podem experimentá-lo, e discutiremos juntos no próximo capítulo;
Complexidade de tempo do algoritmo BF
O melhor caso é que a complexidade de tempo de correspondência é O(1) desde a primeira vez;

O pior caso é que cada vez que o último é correspondido apenas para descobrir que é diferente da string principal, como "aaaaab", substring "aab"




Olhando para a foto acima, exceto pela última vez, o resto é combinado até o final todas as vezes, apenas para descobrir, ah, somos diferentes.
Neste caso, na figura acima, a string do padrão está nas 3 primeiras vezes, e cada vez corresponde 3 vezes, e não corresponde, até a 4ª vez, todas as correspondências, não há necessidade de continuar a se mover, então o número de partidas é (6 - 3 + 1) * 3 = 12 vezes.
Pode-se ver que, para o comprimento da cadeia principal de n e o comprimento da cadeia padrão de m, a complexidade de tempo do pior caso é O((n - m + 1) * m) = O(n * m ).
Acredito que amigos pensantes descobrirão que, se for para pesquisar, não há necessidade de mover i para a posição 1, porque os caracteres anteriores são todos correspondentes, então mova i para a posição 1 e mova j para a posição de 0 , a posição é escalonada, e obviamente não vai corresponder, então podemos descartar as etapas desnecessárias acima, reduzir o retrocesso do ponteiro para simplificar o algoritmo, há uma ideia, i posição não se move, só precisa mover a posição j , que nos leva hoje O algoritmo KMP protagonista.
Algoritmo KMP
conceito básico
O algoritmo KMP é um algoritmo aprimorado de correspondência de strings proposto por DEKnuth, JH Morris e VRratt, então as pessoas o chamam de operação Knuth-Morris-Platt (algoritmo KMP para abreviar). O núcleo do algoritmo KMP é usar as informações após a falha de correspondência para minimizar os tempos de correspondência entre a string padrão e a string principal para atingir o objetivo de correspondência rápida . A implementação específica é por meio de uma função next() , e a própria função contém as informações de correspondência local da string padrão. A complexidade de tempo do algoritmo KMP é O(m+n).
Diferença: A única diferença entre K MP e BF é que i da minha string principal não voltará e j não se moverá para a posição 0.
Analisando algoritmos KMP
Suponha que forneçamos a string "ababcabcdabcde" como a string principal e, em seguida, forneçamos a substring "abcd", agora precisamos descobrir se a substring aparece na string principal, retornar o primeiro subscrito correspondente na string principal, fail retorna - 1.
1. Primeiro, dê um exemplo, por que a string principal não é revertida

2.j Localização de reserva

Então, como j retorna à cápsula na posição do subscrito 2? Abaixo levamos ao próximo array
Traga a próxima matriz
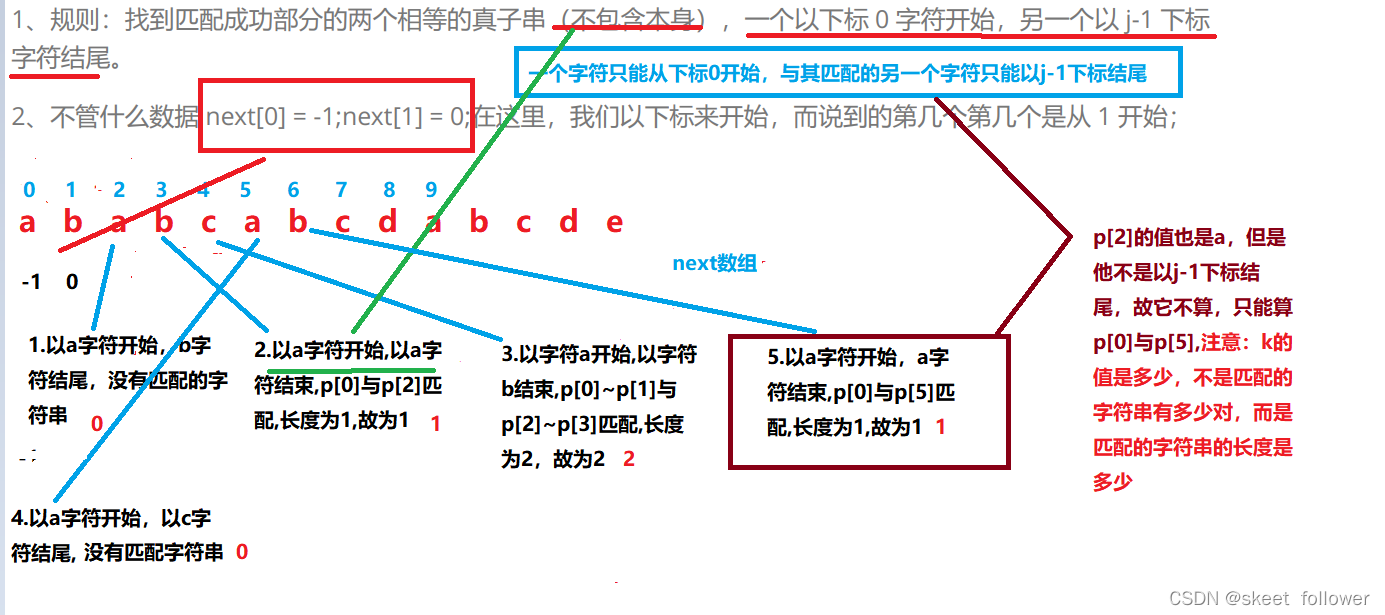
A essência do KMP é o próximo array: ou seja, ele é representado por next[j] = k ;, diferente j corresponde a um valor K, e este K é a posição do j que você deseja mover no futuro . E o valor de K é calculado assim:
- Regra: Encontre duas substrings próprias iguais (excluindo-se) que correspondam à parte bem-sucedida, uma começando com o caractere subscrito 0 e a outra terminando com o caractere subscrito j-1.
- Não importa quais dados next[0] = -1; next[1] = 0; aqui, começamos com subscritos e o número de vezes mencionado começa em 1;
Exercícios para encontrar o próximo array:
Exercício 1: Por exemplo, para "ababcabcdabcde", encontre seu próximo array?
-1 0 0 1 2 0 1 2 0 0 1 2 0 0
Exercício 2: Encontre a próxima matriz de "abcabcabcabcdabcde"? "
-1 0 0 0 1 2 3 4 5 6 7 8 9 0 1 2 3 0
Aqui vem a coisa principal:
aqui todos não devem ter problemas em como encontrar o próximo array. A próxima pergunta é, se sabemos que next[i] = k; como encontrar next[i+1] =
? pass next O valor de [i], através de uma série de conversões para obter o valor de next[i+1], então podemos implementar essa parte.
Então, como fazê-lo?
Primeiro suponha: next[i] = k é estabelecido, então esta fórmula é estabelecida: P0...Pk-1 = Px...Pi-1, obtenha: P0...Pk-1 = Pi-k. .Pi -1; Análise conforme mostrado abaixo:

Então assumimos que se Pk = Pi; podemos obter P0...Pk = Pi-k..Pi; então este é o próximo[i+1] = k+1;

Então: e quanto a Pk != Pi ?

Código
Código C:
#include<stdio.h>
#include<string.h>
#include<assert.h>
void GetNext(int* next, char* sub, int len2)
{
next[0] = -1;//规定第一个为-1,第二个为0,则直接这样定义就好了;
next[1] = 0;
int k =0;//前一项的k
int j = 2;//下一项
while (j < len2)
{
if (k==-1||sub[j-1] == sub[k])
{
next[j] = k + 1;
j++;
k++;
}
else
{
k = next[k];
}
}
}
int KMP(char* str, char* sub, int pos)
{
assert(str != NULL && sub != NULL);
int len1 = strlen(str);
int len2 = strlen(sub);
assert(pos >= 0 && pos < len1);
int i = pos;//i从指定下标开始遍历
int j = 0;
int* next = (int*)malloc(sizeof(int) * len2);//动态开辟next和子串一样长
assert(next != NULL);
GetNext(next, sub, len2);
while (i < len1 && j < len2)
{
if (j == -1||str[i] == sub[j])//j==-1是防止next[k]回退到-1的情况
{
i++;
j++;
}
else {
j = next[j];//如果不相等,则用next数组找到j的下个位置
}
}
if (j >= len2)
{
return i - j;
}
else {
return -1;
}
}
int main()
{
char* str = "ababcabcdabcde";
char* sub = "abcd";
printf("%d\n", KMP(str, sub, 0));
return 0;
}código java:
public static void getNext(int[] next, String sub){
next[0] = -1;
next[1] = 0;
int i = 2;//下一项
int k = 0;//前一项的K
while(i < sub.length()){//next数组还没有遍历完
if((k == -1) || sub.charAt(k) == sub.charAt(i-1)) {
next[i] = k+1;
i++;
k++;
}else{
k = next[k];
}
}
}
public static int KMP(String s,String sub,int pos) {
int i = pos;
int j = 0;
int lens = s.length();
int lensub = sub.length();
int[] next= new int[sub.length()];
getNext(next,sub);
while(i < lens && j < lensub){
if((j == -1) || (s.charAt(i) == sub.charAt(j))){
i++;
j++;
}else{
j = next[j];
}
}
if(j >= lensub) {
return i-j;
}else {
return -1;
}
}
public static void main(String[] args) {
System.out.println(KMP("ababcabcdabcde","abcd",0));
System.out.println(KMP("ababcabcdabcde","abcde",0));
System.out.println(KMP("ababcabcdabcde","abcdef",0));
}Explicação do código-chave
outro{
j=próximo[j]
}

if (j == -1||str[i] == sub[j])
{ i++; j++; }
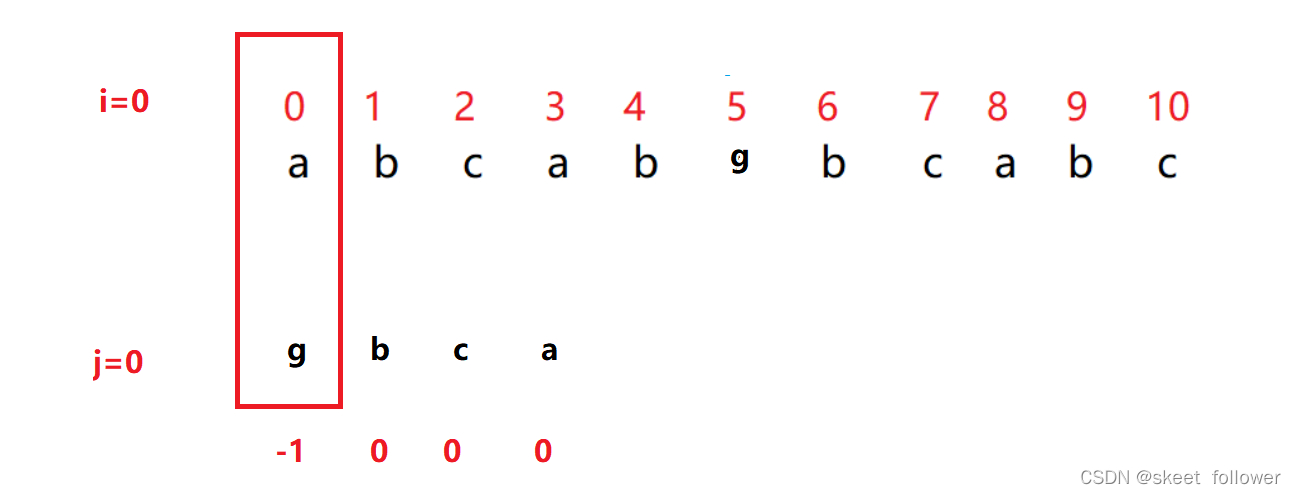
Pergunta : Por que ainda existe um j==-1?
Como mostrado na figura abaixo: quando o primeiro caractere não corresponde, i, j são ambos 0 neste momento , j=next[j] >> j=next[0] >> j=-1; neste momento j é -1 , Se você não adicionar j==-1, o programa terminará e não retornará nenhuma correspondência, mas se você observar atentamente a figura abaixo, P[5]~P[8] corresponderá à substring, então o a resposta está obviamente errada, então devemos adicionar o caso de j==-1 e deixá-lo percorrer desde o início;
next[0] = -1;
next[1] = 0;
int k =0;//k
int j = 2 do item anterior;//próximo item
De acordo com nossos regulamentos, o primeiro e o segundo números da próxima matriz são -1 e 0, portanto, não há problema. k=0 é o valor do item anterior k, e j=2 é o próximo item.

if (k==-1||sub[j-1] == sub[k])
{ next[j] = k + 1; j++; k++; }
De acordo com o conteúdo acima, podemos saber que p[j]==p[k], next[i]=k; então podemos deduzir next[i+1]=k+1; como mostra a figura abaixo, mas aqui i é j- 1, todos deveriam prestar atenção nisso, p[j]==p[k]>>sub[j-1]==sub[k];next[i+1]=k+1 >>próximo[j]= k+1;

senão
{ k = próximo[k]; }
Este ponto de conhecimento foi mencionado acima, quando p[j]!=p[k], k reverte, sempre encontra p[j]==p[k] e então usa este next[i+1]=k+1 ;
Um pequeno teste
tópico aqui >> substrings repetidas
Os parceiros interessados podem experimentá-lo, e discutiremos juntos no próximo capítulo;
Complexidade de tempo do algoritmo KMP
Suponha que para encontrar a posição inicial da string N na string M, os comprimentos são m e n respectivamente, usando o algoritmo KMP, geralmente considera-se que a complexidade de tempo é O(m+n), ou seja, a complexidade de tempo de calcular a próxima matriz é O (n) e O(m) ao combinar.
O acima é a explicação do algoritmo KMP. Se houver alguma falha ou melhor compreensão do código, por favor, deixe uma mensagem na área de comentários para discutir e progredir juntos! !
