 Este trabalho é licenciado sob o Acordo de Licença Internacional Creative Commons Atribuição-Uso Não-Comercial 4.0 da mesma forma .
Este trabalho é licenciado sob o Acordo de Licença Internacional Creative Commons Atribuição-Uso Não-Comercial 4.0 da mesma forma .
 Este trabalho ( Lizhao Long Bowen por Li Zhaolong criação) por Li Zhaolong confirmação, indique os direitos autorais.
Este trabalho ( Lizhao Long Bowen por Li Zhaolong criação) por Li Zhaolong confirmação, indique os direitos autorais.
Artigo Diretório
introdução
O mesmo problema é entendido de maneira diferente em diferentes estágios de aprendizagem. No início não havia compreensão suficiente deste campo. O ângulo de visão do problema não é apenas baixo, mas também único, o que tornará mais fácil olhar para o problema de acordo com uma determinada solução, como esta " simples "problema, isto é 数据冗余, bem no começo Naquela época, esse problema é o mesmo aos meus olhos 一致性协议, porque podemos fazer redundância de dados com base no protocolo de consistência. Claro, o mais importante é que essa é uma consistência forte, mas é sabido que é a consistência forte (consistência forte do ponto de vista do servidor, é claro, nós Ignorando o atraso da rede todos os dias) está afetando extremamente o desempenho, então na maioria das vezes não faremos isso. Podemos recuar e escolher outro modelos de consistência. Isso levará a mudanças na estratégia de redundância de dados. Isso é meu. Não percebi em [1] este artigo. Estava ocupado pensando em consistência e esqueci completamente que o comportamento de mostrar consistência é, na verdade, redundância de dados.
Em segundo lugar, este artigo não é uma definição muito geral como [2], mas para descrever várias estratégias de redundância usadas na vida real, inferir a consistência e combinar os conceitos em [2].
A maior parte das informações do artigo vem de jornais de grandes empresas, e não há problema em termos de correção.
Neste artigo, mencionamos apenas a estratégia de redundância de dados, sem mencionar mais nada.
Acordo de Conformidade
O protocolo de forte consenso pode ser o primeiro obstáculo que a maioria dos amigos que estudam a teoria distribuída encontrou desde que entraram na indústria. Eles foram primeiro abusados por Raft (multi), depois devastados por Paxos e, finalmente, descobriram que existem transmissões atômicas como o ZAB. protocolo. Além do problema dos generais bizantinos, existem inúmeros algoritmos usados para Bitcoin, como PBFT, Pow, PoS e DPoS; sem a limitação de consistência forte, também existem protocolos de consenso muito fracos, como Gossip (geralmente usado para manter a associação ao cluster) ; a restrição é mais fraca e existem protocolos de replicação como a replicação ViewStamped. Claro, não sei muito sobre isso. Amigos interessados podem conferir [5].
A manutenção da redundância de dados baseada no protocolo de consistência não quer dizer, é essencialmente o processo de sincronização de logs entre nós.
ceph
A distribuição de eventos no ceph é feita por meio de CRUSHalgoritmos, ou seja master, inodepodemos calcular um obtendo- o do cluster pgid, por meio do qual podemos pgidobter um conjunto OSDde informações, e então podemos obter suas informações reais de armazenamento por meio do mapa.
OSDO primeiro nó da lista é Primary, e os demais são todos Replica. O cliente conclui todas as gravações no objeto PG no OSD principal (host principal). Esses objetos e o PG recebem um novo número de versão e, em seguida, são gravados no OSD de réplica. Quando cada cópia é concluída e responde ao nó mestre, o mestre O nó é atualizado e o cliente concluiu a gravação. Aqui está um commit de duas fases. Quando as cópias são gravadas na memória Ack, o nó mestre pode responder quando todas as Ack forem recebidas. Quando as cópias forem enviadas para o disco, ele responderá Commit. O nó mestre também responderá quando todos os commits são recebidos. Dê Clientuma resposta, o que reduz bastante a velocidade de resposta do cliente.
O cliente lê diretamente no nó mestre. Este método economiza a sincronização e serialização complicadas entre as réplicas do cliente. A configuração W visível desse método é de todos os nós, o que significa que a consistência da cópia pode ser mantida de forma confiável durante a recuperação de erros. Claro, se um Replicafalhar, a operação falhará, porque não há como receber todas as respostas.
O documento não mencionou o que fazer neste momento. Acho que neste momento (após o tempo limite), o OSD pode ser recalculado e, em seguida, replicado novamente. Quando o OSD for restaurado, será adicionado à parceria original, e também será baseado no registro de alterações recentes do PG. Para sincronizar os registros, isso garante a consistência.
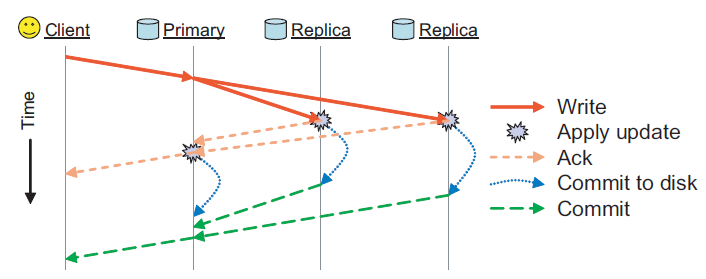
GFS
A redundância de dados do GFS vem de dois aspectos, um é Mastera cópia de estado do nó e o outro é ChunkServera cópia de dados. Isso envolve outro problema, a saber, a seleção do mestre. O primeiro usa o Chubby para escolher o mestre de forma confiável (adquirindo um bloqueio) e o último determina o nó mestre Masteremitindo leases. Vemos que nenhum dos métodos usa um protocolo de consenso. No entanto, o nó mestre pode ser designado exclusivamente.
Na verdade, não masterhá muita descrição sobre a implementação no papel redundante, mas é mencionado que todos os logs de operação e arquivos de ponto de verificação do servidor mestre são copiados para várias máquinas. Além disso, o pré-requisito para o envio bem-sucedido da operação de modificação para o estado do servidor mestre é que o log de operação seja gravado no nó de espera do servidor mestre e no disco local. Desta forma, uma vez que a seleção do mestre por meio do Chubby é bem-sucedida quando o servidor mestre está inativo, a cópia desses dados muito completos pode ser rapidamente alternada para o estado operacional normal, porque tem todos os dados do nó mestre original e foi colocado no disco.
Além da primeira vez, há outro tipo de servidor no GFS chamado servidores de sombra.Esses servidores de sombra fornecem acesso somente leitura ao sistema de arquivos quando o servidor mestre "mestre" está inativo. Eles são sombras, não espelhos, portanto, seus dados podem ser atualizados mais lentamente do que o servidor mestre "mestre", geralmente menos de 1 segundo. Tal operação faz com que o mestre "mestre" fique offline, mas o serviço não ficará offline como um todo, porque a sombra também pode fornecer acesso aos dados originais. Para aqueles arquivos que não mudam com frequência ou aplicativos que permitem uma pequena quantidade de dados desatualizados, o servidor de sombra pode melhorar a eficiência de leitura e melhorar a disponibilidade de todo o sistema .
Por que os dados de sombra gerais são mais lentos? Porque as informações do Chunk são mantidas pela própria sombra e pela comunicação do Chunk, mas a criação e modificação da cópia só podem ser concluídas pelo mestre, se a modificação for para notificar a sombra primeiro e, em seguida, atualizar após receber a resposta pode causar a sombra dados sejam mais novos que o mestre. Isso é intolerável, então a sombra no GFS escolhe ler uma cópia do log da operação em andamento no momento e altera a estrutura de dados interna exatamente na mesma ordem do servidor mestre principal, garantindo a consistência ao mesmo tempo, mas é claro que vai. Há um tempo de sincronização, que faz com que os dados sejam um pouco mais antigos.
Então falamos sobre ChunkServerredundância de dados, o seguinte é o processo de atualização:
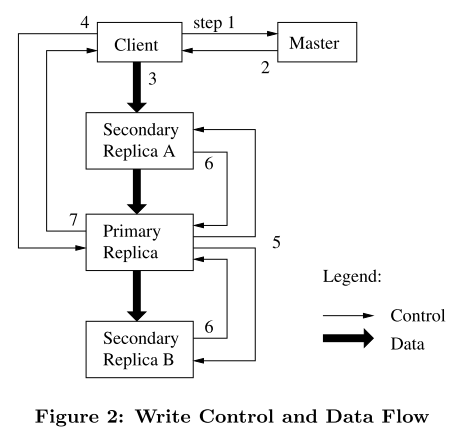
cada vez que vejo essa imagem, quero dizer que a separação do fluxo de controle e do fluxo de dados só pode ser considerada inteligente. .
O GFS usa um mecanismo de concessão para manter a consistência da ordem das alterações entre várias réplicas. O nó mestre estabelece um lease para uma cópia do Chunk, que é chamado de Chunk mestre. O Chunk principal serializa todas as operações de alteração do Chunk e todas as cópias seguem esta sequência para as operações de modificação.
Pode-se verificar na seção 3.1 do artigo que a cópia de dados é um processo fortemente consistente, pois quaisquer erros gerados por qualquer cópia serão devolvidos ao cliente. Primeiramente, os dados devem ser executados com sucesso no trecho principal, caso contrário lá não haverá sequência de operações. Portanto, se alguma Replicasequência de operações de execução falhar, esta mensagem será passada para o bloco principal. Nesse momento, a solicitação do cliente é considerada uma falha e os dados estão em um estado inconsistente em desta vez, e o cliente lida com isso repetindo a operação que falhou.
Quanto ao motivo pelo qual os arrendamentos são usados para garantir a consistência entre várias cópias e os arrendamentos são usados, a explicação dada no artigo é esta: o objetivo de projetar o mecanismo de arrendamento é minimizar a carga de gerenciamento do nó Mestre . Na verdade, isso não é fácil de entender. Minha ideia é a seguinte. Deve-se dizer que é para um gerenciamento mais eficiente de pedaços . Como o gerenciamento de blocos é um processo dinâmico aos olhos do GFS, o gerenciamento de blocos do mestre inclui, mas não se limita aos seguintes pontos:
- O mestre verifica a distribuição atual de cópias e, em seguida, move as cópias para usar melhor o espaço do disco rígido e balancear a carga de forma mais eficaz
- A seleção de um novo Chunk é semelhante ao que foi criado: balanceando o uso do disco rígido, limitando o número de operações de clonagem em andamento no mesmo servidor Chunk e distribuindo cópias entre racks
- Quando o número de cópias efetivas do Chunk for menor do que o fator de replicação especificado pelo usuário, o nó Master irá replicá-lo novamente
Se cada Chunk for configurado como um Paxos/Raftgrupo, a migração (para a utilização do disco rígido) será muito problemática [9], e a sobrecarga do Chunk também se tornará relativamente grande, porque a sobrecarga do próprio protocolo de consistência forte é muito ampla.
Claro que o acima é apenas meus pensamentos pessoais.
Dínamo
O que Dynamo descreve é na verdade a parte do nó sem proprietário em [2], porque [2] este artigo é um artigo que escrevi depois de ler DDIA, e agora parece que o conteúdo dessa seção em DDIA está realmente relacionado a [10] Escrito em este papel.
O Dynamo usa hashing consistente otimizado para distribuição de dados. Obviamente, existem dois métodos mais intuitivos para redundância de dados. Cada nó é contado como mestre e escravo (o tipo de cadeia também é possível) ou para disponibilidade extrema como o Dynamo A introdução de gravações de nó sem proprietário.
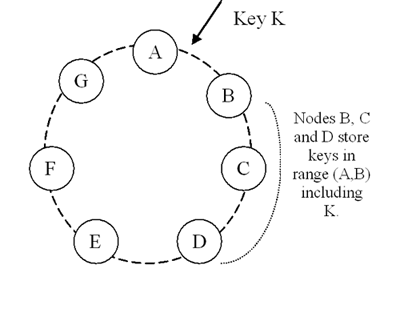
Além de armazenar cada chave em seu intervalo localmente, o Dynamo também copia essas chaves para os nós sucessores N-1 no sentido horário no anel. Veja o exemplo acima. Se uma chave for inserida no intervalo [A, B), o nó BCD armazenará essa chave. Em outras palavras, o nó D armazenará a chave no intervalo (A, B], (B, C) e (todas as chaves em C, D].
Uma lista de nós responsáveis por armazenar uma chave específica é chamada de lista de preferências, e qualquer nó de armazenamento no Dynamo é elegível para receber qualquer operação de leitura e gravação na chave do cliente, o que significa que ela pode aparecer aqui. escrever. Para garantir a consistência, na configuração geral W+R > N, chamamos de coordenador o nó que processa as operações de leitura ou escrita.O processo de leitura e escrita é o seguinte:
-
Ao receber uma solicitação de gravação, o coordenador gera uma nova versão do relógio vetorial e grava a nova versão localmente. O coordenador então envia a nova versão (junto com o novo relógio vetorial) para os N principais nós alcançáveis na lista preferida. Se pelo menos os nós W-1 retornarem uma resposta, a operação de gravação será considerada bem-sucedida.
-
Ao receber um pedido de leitura, o coordenador solicita todas as versões existentes de dados dos N nós alcançáveis principais na lista preferencial para a chave, em seguida, aguarda as respostas R e, em seguida, retorna os resultados ao cliente. Se o coordenador final coletar várias versões dos dados, ele retornará todas as versões que acredita não serem causais. Versões diferentes serão coordenadas e substituir a versão atual e, finalmente, escritas de volta.
Amigos que não sabem sobre relógios vetoriais podem verificar as informações.
Há outro problema aqui, ou seja, como sincronizar os valores diretos de vários nós, porque a gravação é multi-nós, não sabemos quais chaves outros nós têm diferentes de nós, precisamos enviar todas eles toda vez que sincronizamos a chave? Claro, não é necessário. O Dynamo usa para MerkleTreeconseguir a sincronização entre as réplicas. Aqui está uma lacuna de hash consistente com nós virtuais. Isso causará muitas MerkleTreefalhas quando o nó mestre for adicionado recentemente e é difícil de recuperar. árvore pode ser reconstruída a partir dos dados existentes, porque key rangeé destruída, como otimizar este artigo não discutirei.
Não será discutido neste artigo como o Dynamo atinge extrema usabilidade por meio de tais gravações de nós não proprietários.
repetir
O esquema de redundância de dados do Redis é a replicação mestre-escravo, e o esquema de alta disponibilidade é Sentinelque a sentinela atua como um nó de eleição. Quando em uso Redis Cluster, sloto nó mestre que tem pelo menos um serve como nó de votação de eleição e o nó escravo é o nó de eleição. Após a eleição do nó escravo ser bem-sucedida, ela será executada slave no onee a atribuição de slot do nó mestre original será revogado para que esses slots apontem para si mesmo. Transmitido após o host PONG, este pacote Gossip é usado para notificar a conclusão do failover.
Devido ao problema de implementação do Redis, na verdade, a replicação mestre-escravo não tem a menor consistência, pois o escravo será atualizado após a atualização do mestre ser bem-sucedida e o processo de atualização é assíncrono, e não há Quorumconceito Os dados a serem enviados são primeiro armazenados na redisClientestrutura.No buffer de resposta buf, a sincronização só será realizada após o recebimento de um evento gravável deste cliente, e este é pelo menos o próximo loop de eventos.
Isso significa que não há consistência na redundância de dados do Redis. Usar o Redis como um bloqueio distribuído é teoricamente absurdo. Claro, teoricamente. Afinal, o nó mestre está inativo e os dados principais não estão sincronizados com o servidor escravo. a probabilidade é muito baixa, mas depois que a base for grande, tudo pode acontecer.
O Redis Clusteresquema de redundância de dados na China ainda é a replicação mestre-escravo. O processo básico de sincronização é igual ao anterior, mas a descoberta da falha, o processo de failover são diferentes e a função de iniciar a seleção também é diferente. Este artigo não discuta isso.
grande conto
Redundância de dados bigtable para nos dar uma nova ideia, ou seja, o auxílio de outros componentes para redundância de dados, Bigtableo uso de GFSvir para a direita Tablete Redo Pointredundância de dados.
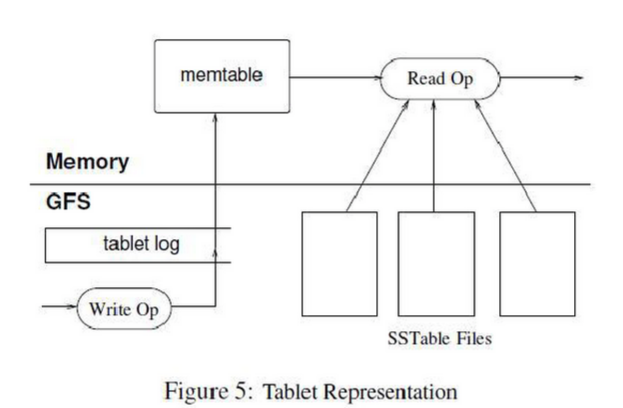
Acho que este é o método mais comum, ou seja, usar um componente de armazenamento distribuído maduro como um sistema de arquivos de rede, o que pode dar ao aplicativo superior uma abstração simples e poderosa. Claro, há uma coisa que deve ficar bem clara em sua mente Não é um cache distribuído, o que significa que é muito comum operar por várias centenas de milissegundos de cada vez, por isso é necessário usar a localidade de espaço / tempo para armazenar esses dados no modo de usuário e também é necessário ao gravar buffer. Ou seja, na figura memtable, é verdade que isso pode causar perda de dados, afinal os dados não ficam armazenados no disco, aqui você pode implementar um redo log Redo pointpara restaurar um memtable.
Para envio de log, o bigtable fez uma otimização, consulte a seção [11] commit log.
Como uma operação GFS é muito cara, o modo de usuário precisa de uma grande quantidade de cache (cache), BigTable usa dois níveis de cache, o cache de varredura é o primeiro nível de cache, o cache principal é o par chave-valor obtido pelo Servidor Tablet por meio da interface SSTable; Bloco; O cache é o cache de segundo nível e o cache é o Bloco do SSTable lido do GFS. Para aplicativos que costumam ler os mesmos dados repetidamente, a varredura do cache é muito eficaz.
memcache
O nível mais alto de redundância de dados é que não há necessidade de redundância de dados!
Como um cache de memória completa tem redundância de dados? Você está falando sobre redundância. Mesmo as informações de roteamento são armazenadas no cliente, é claro, se for para segurança de dados, é claro, não há necessidade de redundância de dados. Mas pode haver redundância devido à eficiência .
Mas, obviamente, quando um novo cluster é adicionado, a taxa de acerto de cache será muito baixa neste momento, o que enfraquecerá a capacidade de isolar serviços de back-end. Isso pode ser considerado uma avalanche especial de cache. Neste momento, a equipe do Facebook abordagem [12] é o aquecimento de cluster frio , ou seja, podemos deixar o cliente deste novo cluster recuperar dados do cliente de cluster que está em execução por um longo tempo, para que o tempo para este cluster frio chegue ao máximo a carga será bastante reduzida.
A seguir está a arquitetura da equipe do Facebook usando o cluster memcache: Eu
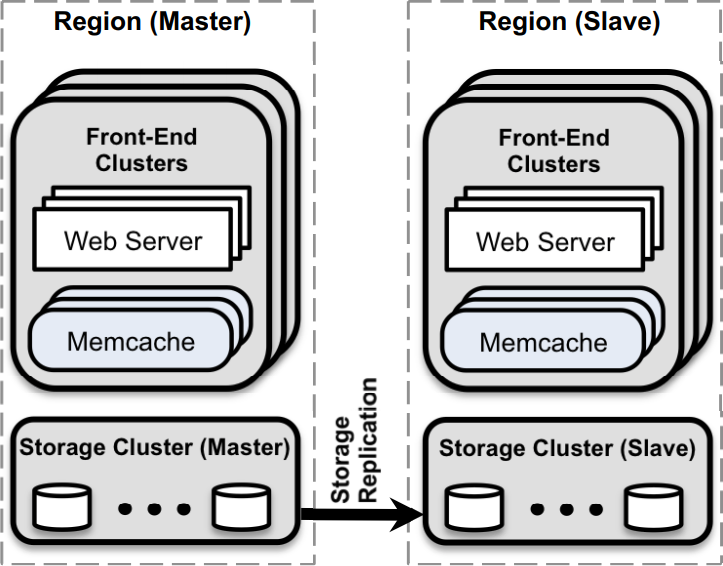
acabei de dizer que não há necessidade de redundância, por que aconteceu de novo? Conforme mencionado anteriormente, para ser eficiente, a equipe do Facebook não só conseguiu regionredundância de dados entre os dois, mas também alcançou regionredundância de dados interna.
É descrito em [12] 5 da seguinte forma:
- Designamos uma região para conter os bancos de dados principais e as outras regiões para conter réplicas somente leitura; contamos com o mecanismo de replicação do MySQL para manter os bancos de dados de réplica atualizados com seus mestres.
- Designamos uma região para manter o banco de dados primário e outras regiões contêm réplicas somente leitura; contamos com o mecanismo de replicação do MySQL para manter o banco de dados de réplica em sincronia com o banco de dados primário.
Neste caso, você pode fazer uso das vantagens de um centro multi-dados, e pode fazer a operação de leitura na região, seja memcacheou Storage Clusteratraso são muito baixos.
Na segunda regioncópia, há a seguinte descrição em [12]:
Usamos a replicação para melhorar a latência e a eficiência do servidor memcached.
Obviamente, quando o volume de solicitação de uma determinada chave excede a carga de uma única máquina, precisamos fazer algumas otimizações, caso contrário, pode haver 缓存击穿problemas. De um modo geral, existem dois métodos neste momento:
- Divisão com base na chave primária (com base no hash ou nas características dos dados).
- Cópia completa (operação de leitura otimizada)
O último é uma redundância de dados. Então, como escolher as duas opções acima? Acho que existem dois fatores:
- O tamanho da coleção de teclas de atalho
- A diferença de custo entre solicitar várias chaves e solicitar chaves únicas
O primeiro é fácil de entender, como ter apenas uma tecla de atalho e como dividi-la é inútil. Neste momento, a replicação completa é a maneira real. Acho que essa também é a razão pela qual Alibaba Cloud Tair [13] escolheu o solução de várias cópias para evitar pontos de acesso. Cada vez que menciono Tair, tenho que dizer algo, estou tão feliz! Feliz Deus Deus eterno! !
Mas quando os pontos de acesso são relativamente uniformes e não há uma tecla de atalho super, obviamente a fragmentação de dados é um método muito bom.
O custo de chave única e multi-chave é o problema descrito em [12]:
- Considere um servidor memcached contendo 100 itens e capaz de responder a 500 mil solicitações por segundo. Cada pedido pede 100 chaves. A diferença na sobrecarga do memcached para recuperar 100 chaves por solicitação em vez de 1 chave é pequena. Para dimensionar o sistema para processar solicitações de 1M / s, suponha que adicionemos um segundo servidor e dividamos o espaço da chave igualmente entre os dois. Os clientes agora precisam dividir cada solicitação de 100 chaves em duas solicitações paralelas de 50 chaves. Conseqüentemente, os dois servidores ainda precisam processar 1 milhão de solicitações por segundo. No entanto, se replicarmos todas as 100 chaves para vários servidores, uma solicitação do cliente para 100 chaves pode ser enviada para qualquer réplica. Isso reduz a carga por servidor para 500 mil solicitações por segundo
- Considere um servidor memcached com 100 itens de dados, capaz de processar 500 mil solicitações por segundo. Encontre 100 chaves primárias para cada solicitação. No memcached, a diferença de custo entre consultar 100 chaves primárias para cada solicitação e consultar 1 chave primária é muito pequena . Para expandir o sistema para lidar com solicitações de 1M / s, suponha que adicionemos um segundo servidor e distribuamos uniformemente a chave primária para os dois servidores. Agora o cliente precisa dividir cada solicitação contendo 100 chaves primárias em duas solicitações paralelas contendo 50 chaves primárias. Como resultado, ambos os servidores ainda precisam lidar com solicitações de 1 milhão por segundo. Então, se replicarmos todas as 100 chaves primárias para dois servidores, uma solicitação do cliente contendo 100 chaves primárias pode ser enviada para qualquer réplica. Isso reduz a carga em cada servidor para 500 mil solicitações por segundo.
CRAQ
O que eu falei antes é como alguns softwares industriais usam mecanismo de redundância de dados, mas não importa como ele mude, ele basicamente não pode escapar do destino da replicação mestre-escravo (exceto por nenhum mestre), mas a estratégia de implementação é diferente por causa da diferença na consistência. Não importa, há apenas uma carga mestre-escravo para redundância de dados?
Claro que não, a replicação em cadeia também é uma escolha excelente, sem mencionar o CRAQ otimizado de replicação em cadeia.
Vamos dar uma olhada nos resultados da comparação de desempenho em [14]:

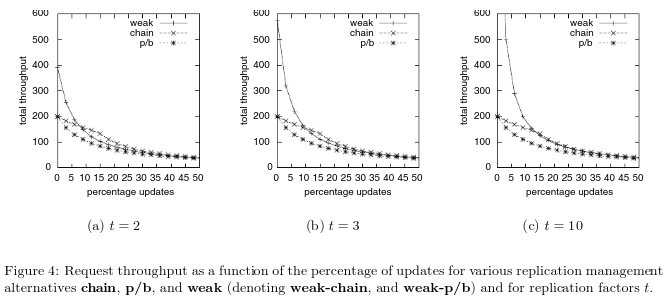
Como o armazenamento em cadeia lê e grava em dois nós, essas duas operações podem ser simultâneas, garantindo consistência forte, e se o mestre e o escravo desejam garantir consistência forte, tanto as leituras quanto as gravações precisam passar pelo nó mestre, como zk Desta forma , a consistência FIFO da perspectiva do cliente não é considerada. Portanto, o desempenho do armazenamento em cadeia é superior ao das operações de gravação no intervalo de 0% a 25% para operações de atualização. E mesmo que o armazenamento em cadeia não garanta uma consistência forte, ele naturalmente garante o FIFO da perspectiva do cliente e não precisa manter um como o zk zxid.
O CRAQ otimizado de armazenamento em cadeia pode melhorar muito a taxa de transferência de leitura ao mesmo tempo que garante uma consistência forte. E para maior rendimento de gravação, o CRAQ também permite reduzir os requisitos de consistência, ou seja, consistência final. Isso significa que os dados antigos podem ser retornados dentro de um período de tempo (ou seja, antes que a gravação seja aplicada a todos os nós).
Simplesmente mencione sem entrar em detalhes, consulte [14] [15] para detalhes.
Resumindo
Posteriormente, pretendo escrever outro artigo sobre distribuição de eventos em armazenamento distribuído, o que também é uma questão muito interessante.
Depois de resumi-los, imediatamente sinto que minha mente está mais clara. Acho que há poucos artigos na Internet mais detalhados, mas simples de descrever esse conteúdo. Isso pode ser considerado uma pequena contribuição para iniciantes neste campo.
Como o resumo do conteúdo como este é um longo processo de linha de frente e acaba sendo um recrutamento rápido recentemente, este artigo só pode ser escrito depois de revisar o conhecimento relacionado à distribuição, portanto, este artigo ainda não acabou e eu aprenderei de novo coisas mais tarde. Eu ainda vou adicionar coisas.
O nível do autor é limitado e Haihan é solicitado a corrigir os erros.
referência:
- " Fale sobre um pouco de compreensão da consistência distribuída "
- " Replicação de dados entre nós "
- " Algoritmo de consenso "
- " Visão geral e derivação do algoritmo Paxos "
- 《Replicação ViewStamped revisitada 解读》
- Ceph: um sistema de arquivos distribuído escalonável e de alto desempenho
- Sistema de arquivos do Google
- O serviço de bloqueio Chubby para sistemas distribuídos fracamente acoplados
- " Algoritmo de jangada: problema de mudança de membro de cluster "
- Dynamo: o armazenamento de valor-chave altamente disponível da Amazon
- Bigtable: um sistema de armazenamento distribuído para dados estruturados
- Escalando Memcache no Facebook
- " 2017 Double 11 Technology Revelado-Distributed Cache Service Tair's Hot Data Hashing Mechanism "
- Replicação de cadeia para oferecer suporte a alto rendimento e disponibilidade
- Armazenamento de objeto no CRAQ