- Os terminais de usuário na LAN geralmente acessam a rede externa configurando um gateway padrão. Se o dispositivo de gateway padrão falhar neste momento, o acesso à rede de todos os terminais de usuário será interrompido, o que provavelmente causará perdas imprevisíveis aos usuários, então você Ao implantar vários gateways para resolver o problema do ponto único de falha, como fazer com que vários gateways funcionem juntos sem entrar em conflito entre si, tornou-se o problema mais urgente a ser resolvido.
- Assim surgiu o VRRP , que pode não apenas realizar backup de gateway, mas também resolver o problema de conflitos entre vários gateways. Então, como funciona o VRRP ? Como configurá-lo na rede?
Desvantagens de um único gateway
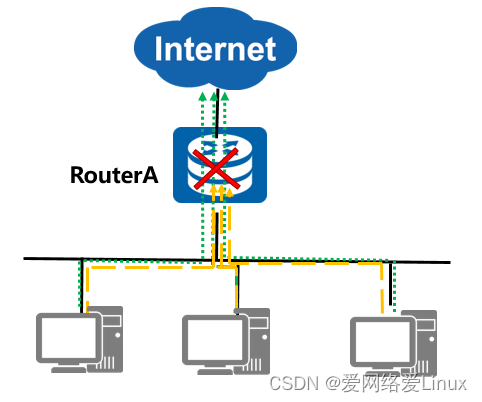
- Quando o roteador do gateway RouterA falha, os hosts neste segmento de rede que usam este dispositivo como gateway não podem se comunicar com a Internet .
Problemas com vários gateways
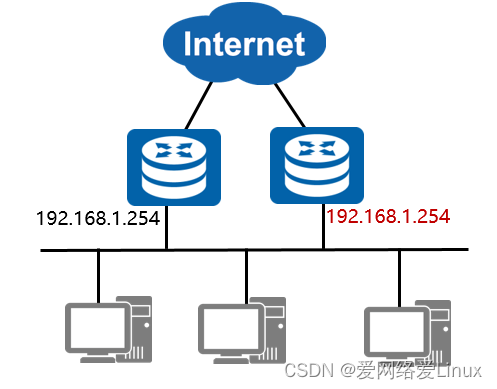
- O backup do gateway é obtido através da implantação de vários gateways.
- No entanto, pode haver alguns problemas com vários gateways: conflitos de endereço IP entre gateways; o host alternará frequentemente as saídas de rede.
Visão geral básica do VRRP
- VRRP pode virtualizar vários roteadores em um roteador virtual sem alterar a rede. Ao configurar o endereço IP do roteador virtual como o gateway padrão, o backup do gateway pode ser alcançado.
- Versão do protocolo: VRRPv2 (comumente usado) e VRRPv3 :
- VRRPv2 é aplicável apenas a redes IPv4 e VRRPv3 é aplicável a redes IPv4 e IPv6 .
- Mensagem do protocolo VRRP :
- Existe apenas um tipo de mensagem: mensagem publicitária ; seu endereço IP de destino é 224.0.0.18 , o endereço MAC de destino é 01-00-5e-00-00-12 e o número do protocolo é 112 .
Estrutura básica do VRRP
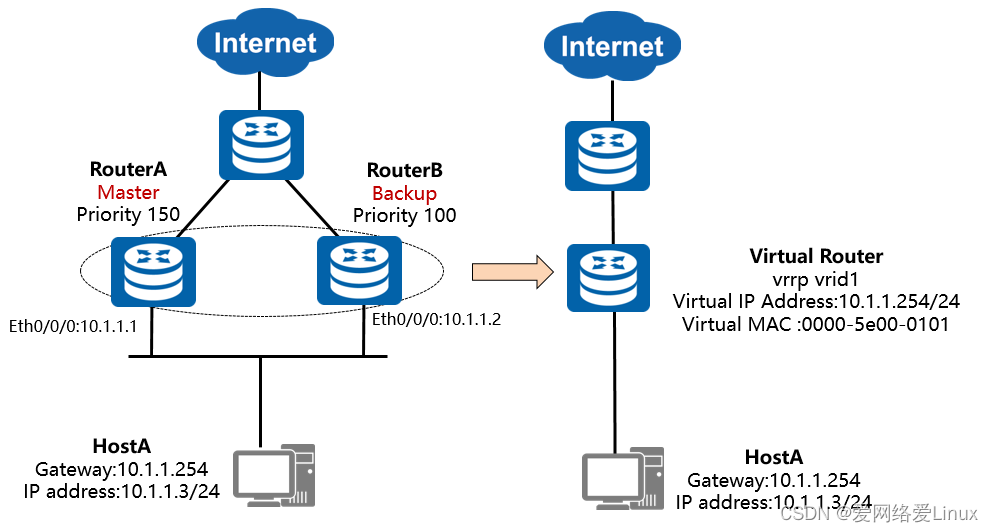
- Conceitos básicos de VRRP :
- Roteador VRRP : Um dispositivo executando o protocolo VRRP , como RouterA e RouterB .
- Roteador Virtual : Também conhecido como grupo de backup VRRP , consiste em um dispositivo Master e vários dispositivos de Backup e é usado como gateway padrão para hosts em uma LAN compartilhada. Por exemplo, RouterA e RouterB juntos formam um roteador virtual.
- Roteador mestre ( Virtual Router Master ): dispositivo VRRP responsável pelo encaminhamento de pacotes , como o RouterA .
- Roteador de backup ( Backup do roteador virtual ): Um grupo de dispositivos VRRP que não são responsáveis pelo encaminhamento de tarefas.Quando o dispositivo mestre falhar, eles se tornarão o novo dispositivo mestre por eleição, como o roteadorB .
- Prioridade : A prioridade do dispositivo no grupo de backup, a faixa de valores é de 0 a 255 . 0 indica que o dispositivo deixa de participar do grupo de backup VRRP , que é usado para fazer com que o dispositivo de backup se torne o dispositivo mestre o mais rápido possível, sem esperar que o temporizador expire; 255 é reservado para o proprietário do endereço IP e não pode ser configurado manualmente ; o valor de prioridade padrão do dispositivo é 100 .
- vrid : O identificador do roteador virtual. Na figura, o vrid do roteador virtual composto por RouterA e RouterB é 1 , que precisa ser especificado manualmente, variando de 1-255 .
máquina de estado
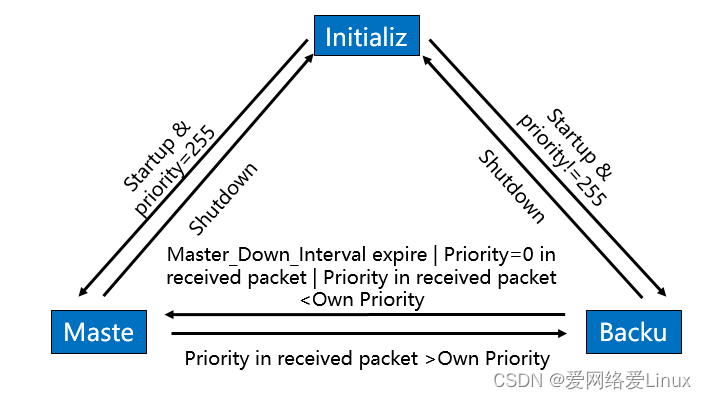
A máquina de estado do protocolo VRRP possui três estados: Inicializar (estado inicial), Mestre (estado ativo) e Backup (estado de espera).
As condições de transição entre os três estados são as seguintes:
Inicializar-> Mestre : Prioridade de inicialização = 255 ;
Inicializar->Backup : Prioridade de inicialização ! =255 ;
Master->Initialize : O dispositivo é desligado;
Master->Backup : Recebe pacotes de dados com prioridade maior que ele próprio;
Backup->Inicializar : O dispositivo é desligado;
Backup->Master : Nenhuma mensagem de notificação VRRP é recebida dentro do período de tempo limite ou a prioridade Master original da mensagem de notificação recebida é 0 , ou a prioridade do Master original na mensagem de notificação recebida é inferior à sua própria prioridade.
Processo de trabalho de backup primário e secundário VRRP
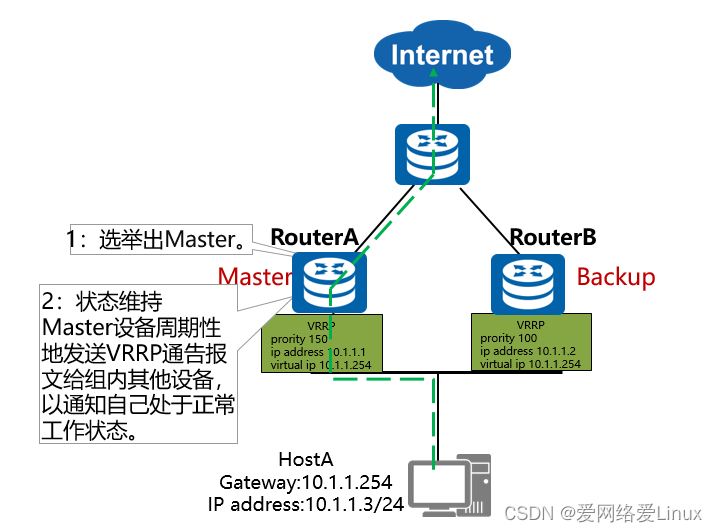
O processo de trabalho do VRRP
é o seguinte:
- Eleja o Mestre :
- Os dispositivos no grupo de backup VRRP elegem o mestre com base na prioridade . O dispositivo mestre notifica o endereço MAC virtual ao dispositivo ou host conectado a ele, enviando pacotes ARP gratuitos , realizando assim a tarefa de encaminhamento de pacotes .
- Regras de eleição: Compare as prioridades e aquele com maior prioridade é eleito como dispositivo Master . Quando as prioridades de dois dispositivos forem iguais, se já existir um Master , ele continuará sendo o Master e não precisará continuar a eleição; se não houver Master , o tamanho do endereço IP da interface continuará a ser comparado, e o dispositivo com o endereço IP da interface maior será eleito como dispositivo Master .
- Notificação do status do dispositivo mestre ( manutenção do status do grupo de backup VRRP ):
- O dispositivo mestre envia periodicamente mensagens de notificação VRRP e anuncia suas informações de configuração (prioridade, etc.) e status de funcionamento no grupo de backup VRRP . O dispositivo Backup determina se o dispositivo Master está funcionando corretamente ao receber pacotes VRRP . Quando o dispositivo Master desiste voluntariamente de seu status de Master (por exemplo, o dispositivo Master sai do grupo de backup), ele enviará uma mensagem de notificação com prioridade 0 , que é usada para mudar rapidamente o dispositivo Backup para o dispositivo Master sem esperar para que o temporizador Master_Down_Interval expire. O tempo de comutação é denominado Skew_Time , e o método de cálculo é: ( 256 - a prioridade do dispositivo de Backup ) / 256 , em segundos.
- Quando ocorre uma falha de rede no dispositivo Master e ele não consegue enviar mensagens de notificação, o dispositivo Backup não pode saber imediatamente seu status de funcionamento. Depois que o temporizador Master_Down_Interval expirar, o dispositivo Master será considerado incapaz de funcionar corretamente e o status será alterado para Master . Dentre eles, o valor do temporizador Master_Down_Interval é: 3×Advertisement_Interval + Skew_Time , em segundos.
Processo de comutação de roteador mestre e backup VRRP (1)
- Se o Master falhar, o processo de comutação ativo/standby é o seguinte:
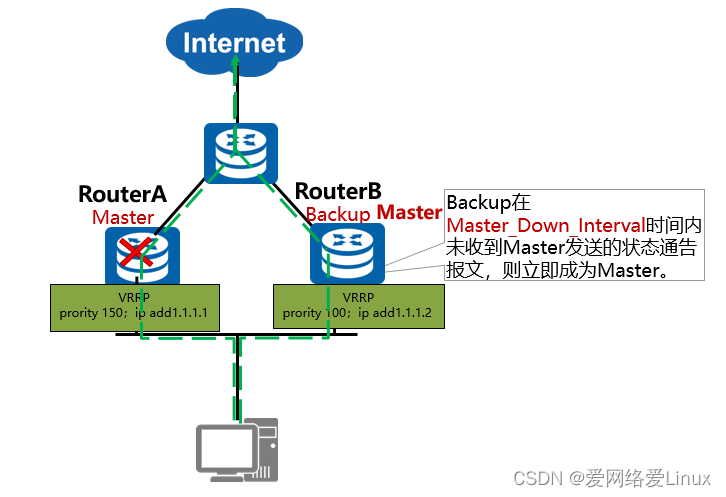
Processo de trabalho de falha de equipamento mestre :
- Quando o dispositivo de backup do grupo não receber uma mensagem do dispositivo Master dentro de um período de tempo ( o valor do temporizador Master_Down_Interval é 3×Advertisement_Interval + Skew_Time , em segundos) , ele se transformará no dispositivo Master .
- Quando há vários dispositivos de backup em um grupo VRRP, vários dispositivos mestres podem ser gerados em um curto período de tempo. Neste momento, o dispositivo irá comparar a prioridade do pacote VRRP recebido com a prioridade local para selecionar aquele com a maior prioridade.O dispositivo se torna o Master .
- Após o status do dispositivo mudar para Master, ele enviará imediatamente ARP gratuito para atualizar as entradas da tabela MAC no switch , direcionando assim o tráfego do usuário para este dispositivo. Todo o processo é totalmente transparente para o usuário.
Processo de comutação de roteador mestre e backup VRRP (2)
- Se o Master original falhar e se recuperar, o processo de switchback master/backup será o seguinte:
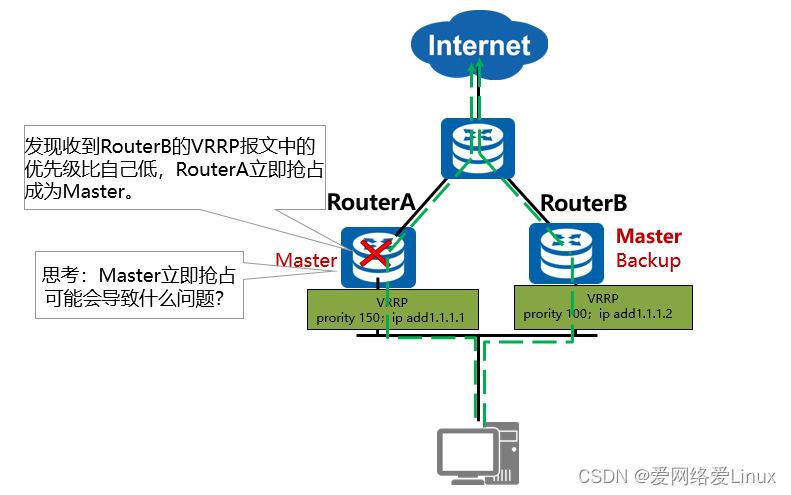
Modo de preempção :
- Controla se o roteador de backup com prioridade mais alta pode substituir o roteador mestre com prioridade mais baixa e se tornar o mestre . O padrão é o modo de preempção.
- Nota: A exceção é que se o proprietário do endereço IP estiver disponível, ele estará sempre em preempção e se tornará o dispositivo mestre .
Atraso de preempção ( Tempo de atraso ):
- Tempo de atraso de preempção, o padrão é 0 , o que significa preempção imediata.
- Após o roteador A se recuperar da falha na figura , a preempção imediata pode causar interrupção do tráfego porque o protocolo de roteamento do uplink do roteador A pode não ter concluído a convergência. Nesse caso, você precisa configurar o atraso de preempção do dispositivo mestre .
- Além disso, em uma rede com desempenho instável, o congestionamento da rede pode fazer com que o dispositivo Backup não receba pacotes do dispositivo Master durante o período Master_Down_Interval , e o dispositivo Backup mudará ativamente para o dispositivo Master . Se os pacotes do dispositivo mestre original chegarem novamente neste momento, o novo dispositivo mestre mudará novamente para Backup . Nesse caso, o status do membro do grupo de backup VRRP mudará com frequência. Para aliviar esse fenômeno, você pode configurar o atraso de preempção para que o dispositivo de backup aguarde o tempo Master_Down_Interval antes de aguardar o tempo de atraso de preempção. Se nenhuma mensagem de notificação for recebida durante esse período, o dispositivo Backup mudará para o dispositivo Master .
Cenário de falha do VRRP
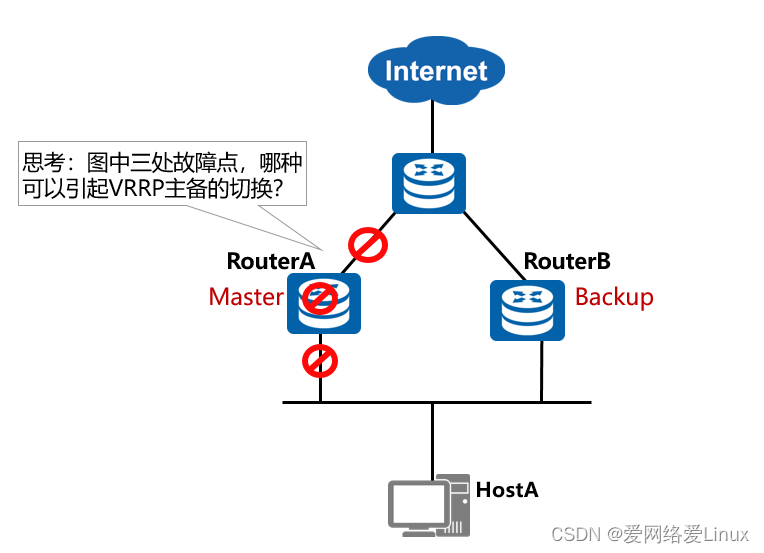
- Na figura, a falha de uplink do roteador A não causará uma alternância VRRP ativo/em espera. Isso fará com que o tráfego de Internet do HostA seja descartado no roteador A. Portanto, o dispositivo VRRP precisa ser capaz de detectar a falha de uplink e executar ativo/em espera transição em tempo hábil.
- Se o RouterA ou a interface conectada ao RouterB falhar , ocorrerá uma alternância VRRP mestre/backup porque o dispositivo Backup não pode receber os pacotes de protocolo enviados pelo dispositivo Master dentro do tempo Master_Down_Interval .
Função de ligação VRRP
Solução: Use a função de ligação do VRRP para monitorar a interface de uplink ou falhas de link e executar proativamente a alternância ativo/em espera.
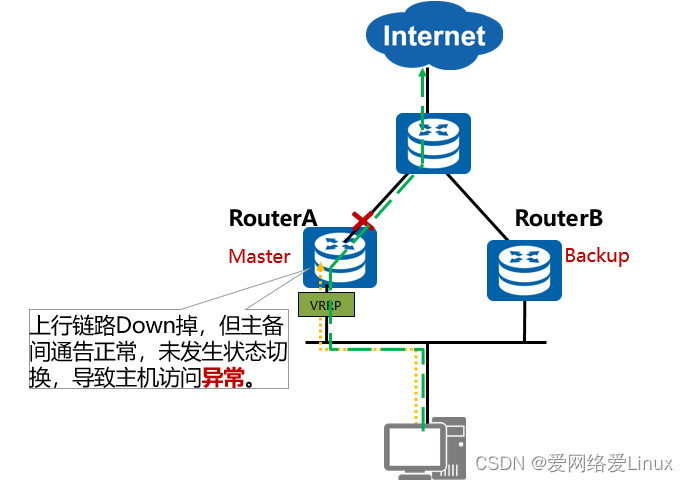
Problemas resolvidos: O VRRP não consegue detectar as mudanças de status das interfaces VRRP que não estão em execução . Portanto, quando o uplink falha, o VRRP não consegue detectá-lo e não realizará a alternância ativa/em espera, resultando na interrupção do serviço.
Solução: Use a função de ligação do VRRP para monitorar a interface de uplink ou falhas de link e executar proativamente a alternância ativo/em espera.
Processo de trabalho de compartilhamento de carga VRRP
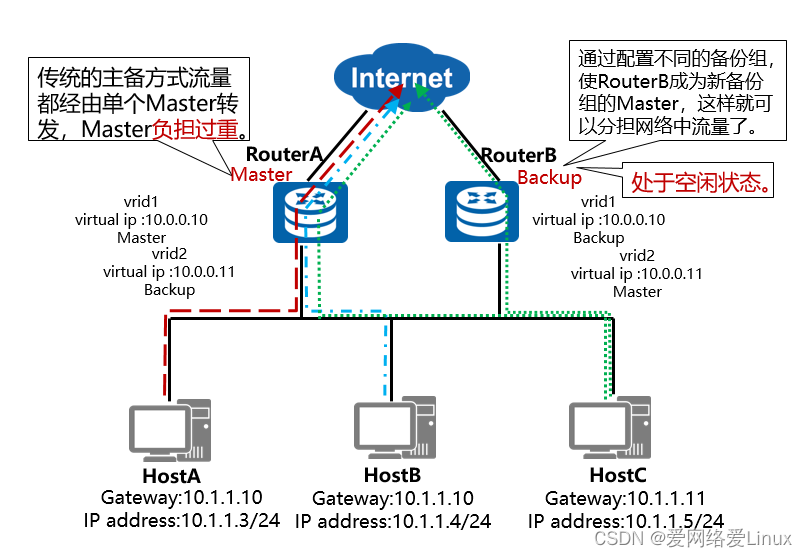
- Balanceamento de carga significa que vários grupos de backup VRRP são responsáveis pelo encaminhamento de serviço ao mesmo tempo.Os princípios básicos e processos de negociação de mensagens do balanceamento de carga VRRP e do backup ativo/em espera VRRP são os mesmos. Cada grupo de backup VRRP contém um dispositivo mestre e vários dispositivos de backup .
- A diferença do método de backup mestre-backup é que o método de compartilhamento de carga requer o estabelecimento de vários grupos de backup VRRP , e os dispositivos mestres de cada grupo de backup são compartilhados em dispositivos diferentes; um único dispositivo pode ingressar em vários grupos de backup e desempenhar funções em diferentes grupos de backup.Diferentes funções.
Implementação de configuração VRRP
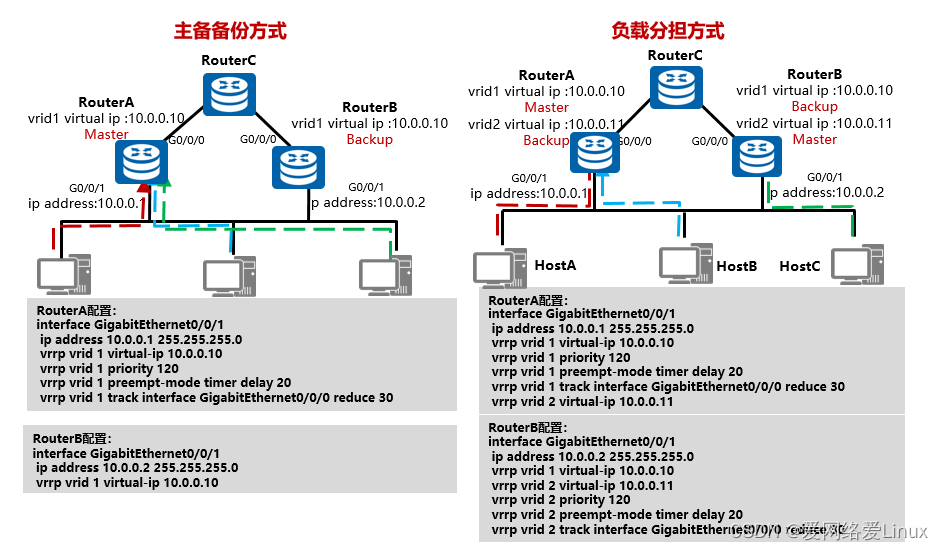
- O método de compartilhamento de carga é igual ao método de backup mestre/backup. Tomando um único grupo de backup VRRP como exemplo, a configuração do dispositivo mestre é a seguinte:
- vrrp vrid 1 virtual-ip 10.0.0.10 // Configure o endereço IP virtual em vrid1 .
- vrrp vrid 1 prioridade 120 // A prioridade configurada em vrid1 é 120. As prioridades dos outros dispositivos não são especificadas manualmente. O padrão é 100 , então este dispositivo é o Master .
- vrrp vrid 1 preempt-mode timer delay 20 // Configure o atraso de preempção do dispositivo Master para 20 segundos.
- vrrp vrid 1 track interface GigabitEthernet0/0/0 reduz 30 // Rastreia o status da interface uplink G0/0/0 . Se a porta falhar, a prioridade VRRP do dispositivo Master é reduzida em 30 .
- Configuração do dispositivo de backup :
- vrrp vrid 1 virtual-ip 10.0.0.10 // Configure o endereço IP virtual em vrid1 .