Prefácio: Esta série de notas já se passaram mais de três meses desde a última atualização, que é um pouco longa. A vida é difícil, de jeito nenhum. Esta aula é principalmente para introduzir o conhecimento de rastreamento dinâmico de objetos; a habilidade pessoal é insuficiente e alguns lugares podem ser mal interpretados. Espero que o grande deus não vá rir e me iluminar. Alguns amigos acham que o que escrevi está correto. Se você conseguir algo, solucione o problema três vezes com um clique.
Resumo
1. Introdução ao algoritmo de rastreamento
2. Algoritmo de rastreamento de alvo único
3. Algoritmo de rastreamento de vários alvos
4. Combate real, algoritmo de rastreamento de vários alvos baseado em correspondência de gráfico bipartido
1. Introdução ao algoritmo de rastreamento
1.1 Rastreamento
1) Definição: Em frames consecutivos [pode ser entendido como um vídeo], associar (determinar) o mesmo objeto de acordo com as informações do objeto
1-1) Modelo de movimento: construa um modelo baseado na posição histórica e velocidade (tamanho e direção) para prever a posição aproximada do objeto no quadro atual
1-2) Modelo de aparência: Construa um modelo de recurso com base na aparência histórica (cor, tamanho, quadro 2d / 3d, contorno, etc.) e pesquise próximo ao local previsto para obter informações de localização mais precisas. Se basicamente não houver mudança na aparência do objeto, você pode usar o modelo [modelo, por exemplo, pegar uma área A do objeto no quadro anterior e compará-la com o quadro atual (a área de aparência do objeto) (basicamente nenhuma alteração), e a área A pode ser considerada um modelo]
No entanto, na realidade, os objetos são frequentemente muito complexos, então um classificador de aprendizagem online é geralmente usado (usando "moldura de objeto" e "moldura de fundo" para treinamento de duas classes).
Dificuldade: o treinamento off-line pode coletar muitos exemplos, e os exemplos de aprendizagem on-line são muito limitados. Como resolver esse problema?
2) Online: Encontre a posição no quadro atual de acordo com as informações históricas do objeto (posição, cor, forma, etc.) (modo comum de rastreamento de alvo único)
3) Off-line: a trajetória obtida correlacionando toda a série temporal de acordo com as informações de cada objeto em cada quadro (rastreamento de múltiplos alvos / consideração geral) [consideração geral, refere-se às informações do quadro anterior, que também podem ser utilizadas mais tarde, mas online online não funcionará]
1.2 Exclusividade de rastreamento (em comparação com a detecção, há um significado)
1) Mantenha o ID consistente para rastreamento
2) Detecção auxiliar de rastreamento: Quando a detecção falha (por exemplo, é bloqueada por outros objetos durante a detecção / alguns objetos podem não ser detectados pelo detector [a informação do objeto não existe no conjunto de treinamento, não pode ser detectada]) , algum rastreamento pode ser processado
3) O rastreamento é mais rápido do que a detecção: a detecção não usa informações históricas e sempre começa a partir de 0. O rastreamento pode saber as informações "históricas" do objeto rastreado com antecedência. Com base nessas informações, ele pode prever aproximadamente a posição do próximo quadro e fazer uma pequena pesquisa e correspondência nas proximidades para obter o quadro de previsão final.
4) Mas também não é possível rastrear apenas sem detecção:
4-1) Rastreamento auxiliar de detecção: O rastreamento pode ser perdido (se encontrar oclusão, desfoque do modelo de movimento, etc.)
4-2) Detecção e correção do erro cumulativo de rastreamento: execução de intervalo geral Detectar, realizar rastreamento durante a inspeção e corrigir o rastreamento com inspeção em intervalos regulares
5) Resumo: a detecção é treinada usando dados de amostra em grande escala, tem uma compreensão mais profunda de uma determinada categoria e o rastreamento tem uma compreensão mais profunda de um objeto específico
1.3 Dificuldades de algoritmo de rastreamento
1) Mudanças na postura e forma, como pessoas sentadas, em pé, caminhando, etc.
2) Mudanças de escala
3) Oclusão de fundo
4) Mudanças de brilho da luz
5) etc.
2. Algoritmo de rastreamento de alvo único
2.1 Introdução
2.1.1 Rastreamento de alvo único
Processo:
1) O primeiro quadro [entrada manual ou gerado automaticamente pelo detector] entra no quadro inicial -> os quadros subsequentes geram a posição do objeto
2) um único alvo
3) online: tempo real
2.1.2 Tipos de algoritmos típicos de rastreamento de alvo único
1) Modelo de produção:
Métodos clássicos de rastreamento de alvo (antes de 2010): Desvio médio, Filtro de partícula, Filtro de Kalman, rastreamento de fluxo óptico com base em pontos de recursos (incapaz de lidar e se adaptar a mudanças de rastreamento complexas, robustez e precisão são ambos superados por algoritmo)
2) Modelo discriminativo:
Combinação de algoritmos de detecção e rastreamento: BOOSTING, MIL, MEDIIANFLOW, TLD (após 2010)
3) O algoritmo de rastreamento baseado em filtragem de correlação [também pertence ao modelo discriminativo, mas isso é excelente e o sistema de formação é muito grande, por isso é listado separadamente; é também o foco desta lição]:
MOSSE KCF (2012)
4) Métodos de rastreamento baseados em aprendizado profundo [acadêmicos fazem muito, mas não muitos na indústria, então esta lição não envolverá muito]:
GOTURN ....
2.1.3 Conjunto de dados
VOT, OTB [Esses dois são muito comumente usados], ...
2.2 Modelo de produção
2.2.1 Desvio médio / fluxo óptico
1) Desvio médio:
1-1) Modele o alvo (por exemplo, use a distribuição de cores do alvo para descrever o alvo e calcular a distribuição de probabilidade do alvo no próximo quadro da imagem)
1-2) A busca do alvo ocorreu ao longo da direção do gradiente de probabilidade crescente e converge iterativamente para o pico local da distribuição de densidade de probabilidade [Princípio de encontrar o alvo no próximo quadro]
1-3) É adequado para situações onde o modelo de cor do alvo e do fundo são bastante diferentes, e a velocidade de cálculo é rápida
2) Algoritmo de fluxo óptico com base em pontos característicos:
2-1) Modelagem do alvo: Extraia alguns pontos característicos no alvo (use uma coleção de pontos característicos para caracterizar o alvo)
2-2) Calcule os pontos de correspondência de fluxo óptico desses pontos característicos no próximo quadro e calcule a posição do alvo (método de fluxo óptico esparso)
2-3) No processo de rastreamento, adicione constantemente novos pontos de característica e exclua pontos de característica com pouca confiança para se adaptar à mudança de forma do alvo em movimento
3) Filtro Kalman
(Filtragem de Kalman, foco. O aplicativo não é apenas no rastreamento e posicionamento [refletido na estimativa de estado], mas também na fusão de dados do sensor, que é muito importante no aplicativo)
Exemplo de introdução:

3-1) Descrição básica do
carro : ---- O carro está no estado no tempo t: pt posição vt velocidade
---- a quantidade de controle do carro no tempo t: o motorista pisa no acelerador ou freia para dar ao carro uma aceleração ut (se o o motorista não pisa no acelerador nem no freio, então ut é igual a 0. Isso quando o carro se move em linha reta a uma velocidade constante)
3-2) Equação do estado de movimento:
---- De acordo com o último tempo t-1, o estado do carrinho prevê o estado do carrinho no tempo atual t
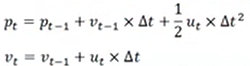
---- A variável de saída na fórmula é linear combinação das variáveis de entrada e uma relação linear pode ser usada. Representação da Matriz
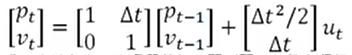
---- Abstraia vários conceitos gerais e descrições de equações mais gerais:
-------- Matriz de transição de estado A (representando como inferimos o atual estado do estado anterior)
----- --- Matriz de controle B (representando como a quantidade de controle u age no estado atual)
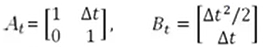
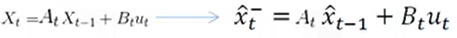
---- O chapéu na parte superior de X [a fórmula à direita] indica que é um valor estimado (não o valor verdadeiro); [a fórmula à direita] a marca superior direita "-" na extremidade esquerda da equação indica que o estado é inferido. Posteriormente, ele será revisado para obter a melhor estimativa antes que "-" possa ser removido. [A fórmula à esquerda indica que o estado anterior obtém a expressão relacional do estado atual, e à direita é o texto detalhado à esquerda]
---- Ela pode descrever a transição de estado de todas as relações lineares (X pode ser qualquer outro estado como dimensão)
3-3) Filtro de Kalman (previsão)
3-3-1) Covariância
- para estimar o valor verdadeiro, o ruído deve ser considerado. Normalmente, assume-se que o ruído é uma distribuição gaussiana com um valor médio de 0. A expansão para dimensões altas é a covariância.
Distribuição Gaussiana:
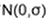
Covariância:
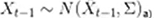
---- A incerteza de cada momento no sistema é dada pela matriz de covariância ∑, esta incerteza também será transmitida a cada momento, ou seja, não apenas o estado atual do objeto (como Posição ou velocidade) será ser transmitida, e a incerteza do estado do objeto também será transmitida (a cada momento)
---- Além disso, o próprio modelo de previsão não é absolutamente preciso. É necessário introduzir um
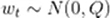
ruído que represente o próprio modelo de previsão (ou seja, a incerteza do ruído no processo de transmissão)
---- De acordo com o conhecimento da teoria da probabilidade [conforme afirmado acima, a seguinte transformação de covariância pode ser obtida]:
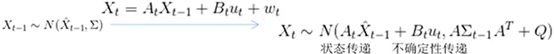
3-4) filtro de kalman (atualização)
3-4-1) Equação de observação:
---- Na verdade não sabemos o verdadeiro estado, apenas o estimamos por meio de observações, assumindo que um monitor de velocidade está disposto na lateral da estrada para exibir a velocidade do veículo em tempo real
---- Tome um exemplo: o valor observado do carrinho no tempo t é Zt, e há uma relação de transformação h (*) do estado real do carrinho para o seu estado observado. Presume-se aqui que ele ainda está uma função linear. Ao mesmo tempo, considerando o ruído de observação como V_t, existem:
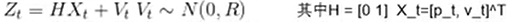
- Nota: O estado é uma grandeza bidimensional e a observação é uma grandeza escalar. Explique que as dimensões do estado e da observação podem ser diferentes
- A equação de movimento fornece um valor estimado X_predict, e a equação de observação também pode obter uma avaliação de estado X_observation. Devemos combinar essas duas estimativas para obter uma estimativa que seja mais precisa do que as duas?
- [Responder às dúvidas acima, mesclar as duas estimativas] Idéia do filtro de Kalman: Xupdate = Xpredict + g (Xabscrvation-Xpredict), 0 <= g <= 1, g é calculado com base na variância dos dois g = E_predict / (E_predito + E_observação). Quando a variância de X_predict é 0 -> g = 0 [pode ser calculado pela fórmula anterior] -> Acredite totalmente em X_predict; quando a variância de X_observation é 0, quando g = 1, acredite totalmente em X_observation
---- Status de atualização do filtro de Kalman:
---- Z_t-Hx_t é
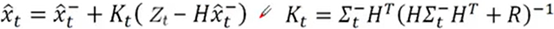
a fórmula da captura de tela das observações reais e X com chapéu, que é uma fórmula que corresponde ao pensamento de Kalman. Cada parâmetro tem uma parte correspondente, e a análise a seguir também é É para a análise desta fórmula de captura de tela.
---- K é chamado de coeficiente de Kalman / ganho de Kalman, ele tem duas funções:
------ mapeamento do resíduo do domínio de observação para o domínio do estado
------ assumindo o papel de g: em dois Um meio-termo entre a variância das duas estimativas estaduais
---- Incerteza de atualização do filtro de Kalman:
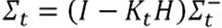
3-5) filtro de Kalman (previsão e atualização)
Resumo:
Previsão: Estime o estado atual com base no estado anterior
Atualização: Corrija as informações de previsão com base nas informações de observação para obter a melhor estimativa
É frequentemente usado para descrever o modelo de movimento do alvo. Não modela as características do alvo, mas simula o modelo de movimento do alvo. Freqüentemente, é usado para estimar a posição do alvo no próximo quadro

[percepção pessoal , Filtro de Kalman, é o valor de observação e Como escolher o cálculo do peso entre os valores previstos para obter a melhor informação de fusão. 】
3-6) combate real: Filtro de Kalman
( filtro de Kalman é integrado no opencv) Na

tela, a cor vermelha indica a quantidade correspondente do parâmetro na fórmula.
Fonte Código:https://github.com/andylei77/kalman_particle_demo/blob/master/circle_tracker.cpp
- Filtro de partícula
Para entender essa ideia algorítmica de uma forma metafórica:
---- Coloque um grupo de cães policiais para procurar o prisioneiro
Passo 1: Deixe o cachorro se familiarizar com o cheiro do prisioneiro: modele o alvo (como um histograma colorido) para obter a expressão de característica alvo
Passo 2: Distribua uniformemente as posições iniciais de alguns cães (a posição aproximada do prisioneiro não é conhecida no início), e deixe-os avaliar se há pegadas de prisioneiro pelo cheiro próximo: Polvilhe algumas "partículas" de acordo com o uniforme distribuição, e extrair as características de "partículas" próximas, por meio de uma certa medida de similaridade, para determinar o grau de correspondência entre a "partícula" e o alvo
Passo 3: Alguns cães encontraram as pegadas do prisioneiro, outros não. Em seguida, coloque os cães que não encontraram as pegadas perto do local onde as pegadas foram encontradas e continue a busca. De acordo com a distribuição gaussiana, mais partículas são espalhadas perto do ponto suspeito, as características são extraídas e o grau de correspondência com o alvo é avaliado. Garanta uma maior probabilidade de rastreamento do alvo.
Etapa 4: Repita a etapa 3
2.3 Modelo discriminativo
2.3.1 Formulário básico
1) Modelo de movimento: Geralmente, vários quadros candidatos são gerados perto da posição do quadro anterior.
2) Modelo de aparência: Use o classificador para calcular a pontuação do quadro candidato ("objeto" ou "fundo") para determinar se o candidato quadro é a posição prevista
3) A ideia é quase a mesma da detecção (caixa candidata + classificação)
4) Os métodos de rastreamento discriminativos são mais adequados para mudanças complexas no processo de rastreamento, e o rastreamento por detecção gradualmente se tornou o principal
2.3.2 Introdução básica de alguns algoritmos (não chave)
Modelo de movimento: geralmente, vários quadros candidatos são gerados perto da posição do quadro anterior
1) REFORÇO:
---- O modelo de movimento é o mesmo que o descrito acima.
---- Modelo de aparência: versão online do AdaBoost, amostra positiva: quadro inicial; amostra negativa: muitos blocos de imagem além da amostra positiva
---- Princípio: Calcule a pontuação de classificação em cada posição próxima à "posição do quadro anterior" na nova imagem. Aquele com a pontuação mais alta é considerado a nova posição. A nova caixa de posição é novamente usada como uma nova amostra para treinar o classificador (cada quadro)
---- Características: o algoritmo é relativamente antigo, o efeito é médio e a falha de rastreamento é desconhecida
2) MIL:
---- O modelo de movimento é o mesmo que o geral
---- Modelo de aparência: Melhora o quadro de amostra positivo:
quadro do objeto + pequena área ao redor do quadro.
A maioria dos objetos no quadro de amostra positiva não estão centralizados (incluindo a nova estrutura de posição), os sacos de amostra positivos e negativos ("sacos") só precisam de uma amostra positiva no centro
---- Princípio: Calcule a pontuação de classificação em cada posição próxima à "posição do quadro anterior" na nova imagem. A nova posição é aquela com a maior pontuação. A nova posição + a caixa circundante é novamente usada como uma amostra positiva para treinar o classificador (cada quadro)
---- Características: O efeito é muito bom e o desempenho também é bom sob oclusão parcial. Em comparação com BOOSTING, o deslocamento não é tão grande. A falha de rastreamento é desconhecida e a oclusão total não é possível.
3) MEDIANFLOW :
---- Princípio: Rastreie para frente e para trás para minimizar o erro das duas trajetórias
---- Características: Perda de rastreamento de feedback confiável, trajetória confiável, adequado para movimento pequeno sem cenas de obstrução, falha de rastreamento de grande movimento facilmente
4) TLD :
---- Princípio:
------ Rastreador: Rastreando objetos entre quadros, usando métodos clássicos para rastrear o alvo, o papel usa o método estatístico de pontos de recurso com base no fluxo óptico para determinar a posição de rastreamento do alvo no próximo quadro
------ Detector: detecta todos os objetos que apareceram e integra-se com os resultados do rastreamento para obter o resultado final de saída
------ Aluno: Avalie o erro do detector e atualize o detector para evitar que erros semelhantes ocorram novamente. Depois de determinar a melhor posição do alvo, o módulo de aprendizagem (Aprendizagem) é responsável por corrigir o rastreador e o detector (selecione mais amostras positivas e negativas em torno do alvo e atualize o modelo do detector online)
---- Características: Adequado para objetos com alterações em grande escala, objetos em movimento, vários quadros são bloqueados por colunas e mais oclusão (por exemplo, completamente bloqueado por outro objeto), muitas amostras positivas erradas tornam-no quase inutilizável (Fácil de rastrear objetos não-alvo) Na
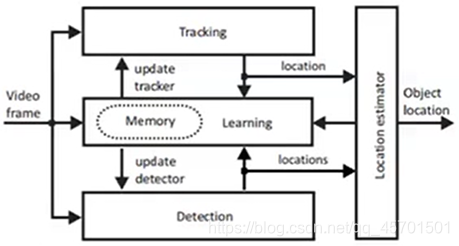
figura, o rastreamento é o rastreador; a detecção é o detector; a aprendizagem é o aprendiz; o resultado da saída de fusão também pode ser devolvido ao aprendiz para aprendizagem, é claro, também pode ser atualizado para o rastreador e o detector.
5) Combate real: Os algoritmos de rastreamento comuns mencionados acima integrados no
Opencv : –opencv API –code
:https://github.com/andylei77/learnopencv/tree/master/tracking
2.4 Algoritmo de rastreamento com base na filtragem de correlação
2.4.1 Conhecimento básico
1) O método CSK proposto por P.Martins em 2012, resolve matematicamente o problema de amostragem densa e aprendizado do classificador de forma perfeita.
---- O processo de amostragem densa pode ser realizado pela matriz circulante
---- O processo de aprendizagem do classificador pode ser convertido em cálculo no domínio da frequência por transformada rápida de Fourier, sem ser restringido por métodos de aprendizagem como SVM ou Impulso. Seja usando classificação linear ou classificação de kernel, todo o processo de aprendizagem é muito eficiente
2) Vantagens: tempo real
3) Desvantagens: o movimento rápido do alvo, grandes mudanças na forma, resultando em mais fundo sendo aprendido, etc., afetarão os métodos da série CF
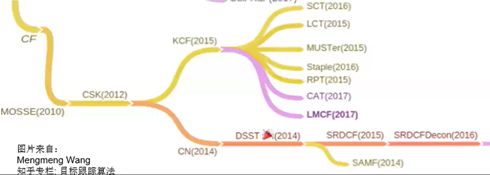

2.4.2 Representante Típico
2.4.2.1 MOSSE
1) MOSSE (Soma de saída mínima do erro quadrático)
---- Modelo de aparência: correlação adaptativa para rastreamento de objetos que produz filtros de correlação estáveis (introduzindo CF: uma medida de similaridade que pode ser aprendida)
2) Características:
- Tome cuidado, dimensione, postura, deformação não rígida, desempenho robusto
- pode detectar oclusão (rádio de pico a lóbulo lateral), pausar e retomar o rastreamento
- Alta taxa de quadros (450 fps)
-Fácil de implementar, mas não há muitos algoritmos de rastreamento com precisão e complexidade [em comparação com os comuns, o efeito de precisão e complexidade é quase o mesmo, compreensão pessoal]
- O efeito não é tão bom quanto o método baseado em aprendizagem profunda
2.4.2.1 KCF
1) KCF (Filtros de Correlação Kernlized)
---- Modelo de aparência: use a relação de sobreposição entre várias amostras positivas [amostragem de matriz circular] para melhorar a velocidade e a precisão do rastreamento ao mesmo tempo:
------ As amostras positivas geradas no novo local e seus arredores podem ser rapidamente geradas pela matriz circulante
------ A diagonalização de Fourier da matriz circulante simplifica muito o processo de aprendizagem de computação e aceleração do classificador
- ---- -Classificador baseado em recursos HOG, (DeepSRDCF: recursos extraídos por aprendizado profundo + método KCF)
2) Características: A precisão e velocidade são maiores que MIL, e a falha de rastreamento de feedback é melhor que BOOSTING e MIL, e não pode resolver a situação de oclusão total.

Esta figura mostra que o uso de momentos cíclicos [a matriz é diferente , a imagem resultante é diferente, como mostrado na imagem A posição da pessoa na imagem muda] A comparação do efeito da amostragem de burst
Algoritmo de rastreamento 2,5 (alvo único) com base em aprendizagem profunda
2.5.1 GOTURN
1) É um método de ponta a ponta baseado em aprendizagem profunda
2) Princípio: Rede Neural Convolucional
3) Características: Robusta para mudanças de ângulo de visão, mudanças de iluminação e mudanças de forma são todas muito boas. No entanto, a situação de oclusão não pode ser tratada de forma eficaz
4) Referência: Para os https://www.learnopencv.com/goturn-deep-learning-based-object-tracking/
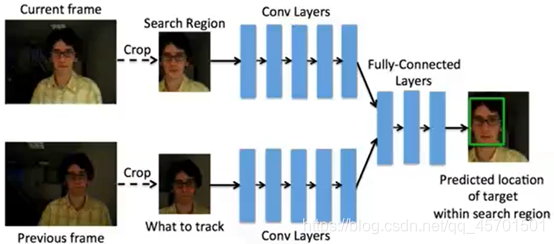
quadros atual e anterior, corte um quadro de área, insira-o na rede e envie diretamente um quadro de predição sem qualquer outro processamento.
Na figura, o aprendizado profundo é CNN indo para a esquerda; CSK indo para a direita está relacionado à filtragem
3. Algoritmo de rastreamento de múltiplos alvos
3.1 Introdução
1) Alvo único -> alvos múltiplos: tanto a dificuldade de um alvo único quanto a dificuldade de alvos múltiplos são adicionados
2) Método de classificação:
- De acordo com a seqüência de tempo de formação da pista:
---- Online: Rastreie o alvo quadro a quadro, semelhante ao olho humano, obtenha o resultado da detecção de cada quadro da imagem e associe o resultado da detecção à trajetória de rastreamento existente
---- Offline: O algoritmo de rastreamento é executado quando o vídeo obtém os resultados e todos os resultados de detecção são obtidos com antecedência. O algoritmo de rastreamento de múltiplos alvos offline considera o conjunto de resultados de detecção como uma observação e a trajetória como uma divisão do conjunto de detecção, de modo que o problema de rastreamento é transformado em um processo de otimização de subconjunto
-De acordo com o mecanismo do algoritmo: correção preditiva / método de associação [por exemplo, cada quadro tem um resultado de detecção, basta associar o resultado com a imagem]
–De acordo com a expressão matemática do algoritmo: probabilidade e maximização estatística / derivação determinística
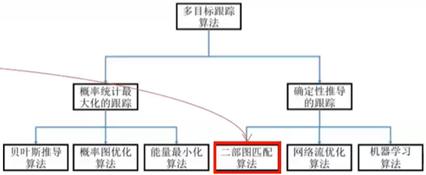
[a outra ponta da seta vermelha é a "derivação determinística" da linha anterior]
Referências:
- Uma revisão dos algoritmos de rastreamento de múltiplos alvos visuais (Parte 1)
- Uma revisão do rastreamento de múltiplos alvos
- Uma revisão dos algoritmos de rastreamento de múltiplos alvos profundos
3.2 Algoritmo Huangarian (Algoritmo Húngaro)
1) A correspondência bipartida de grafos é um problema de algoritmo muito comum. Geralmente, o algoritmo húngaro é usado para resolver o problema de correspondência máxima bipartida de grafos
2) O que é um gráfico bipartido?
---- Grafo bipartido, também chamado de grafo bipartido, é um modelo especial na teoria dos grafos. Suponha que G = (V, E) seja um gráfico não direcionado [V representa o conjunto de vértices; E, representa a aresta], como fazer o conjunto de vértices V pode ser dividido em dois subconjuntos disjuntos (A, B), e o gráfico O dois vértices i e j associados a cada aresta E (i, j) pertencem a esses dois conjuntos de vértices diferentes (i em A, j em B), então o grafo G é chamado de grafo bipartido
3) O que está combinando?
- Imagine a imagem a seguir como 3 trabalhadores e 4 tipos de trabalho. A conexão significa que o trabalhador está disposto a fazer um determinado trabalho, mas no final, um trabalhador só pode fazer um tipo de trabalho. O resultado final correspondente é uma correspondência. A partida pode estar vazia. Correspondente à tarefa de rastreamento está a correspondência da trajetória de movimento com o objeto no quadro atual.
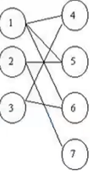
Como mostrado na figura, 3 trajetórias estão à esquerda e agora há 4 objetos à direita. Associar a trajetória ao objeto é Coincidindo.
4) Qual é a correspondência máxima?
- Com base na vontade de trabalhar, quantas equipes podem ser combinadas no máximo
Referência: Fun Writing Algorithm Series-Hungarian Algorithm ( https://blog.csdn.net/dark_scope/article/details/8880547)
"Teng": Se você tiver uma chance, você também deve ir se não tiver a chance de criar uma oportunidade.
Código: A https://github.com/andylei77/HungarianAlgorithm/blob/master/hungarian_algorithm.py
essência do algoritmo húngaro: quando recorrente, é o primeiro a chegar primeiro a ser servido e, se houver insatisfação depois, deixe-o ser permitido e, se houver insatisfação, ele corresponderá ao resto de uma vez.
4. Combate real, algoritmo de rastreamento de múltiplos alvos baseado em correspondência de gráfico bipartido
Código:https://github.com/andylei77/object-detector/blob/ROS/object_detection_tutorial.py
(Implementação do algoritmo de rastreamento de appllo) Efeito de caso, quadro dinâmico para objetos em cada quadro de imagem e rastreamento dinâmico de quadro.
Entendimento simples (pessoalmente pense):
1) Primeiro, dê um quadro para o objeto de cada quadro da imagem, dê uma operação id, esta é uma parte A; então, de acordo com o algoritmo relevante (a especificidade não é clara), muitas trajetórias são obtidas e a parte de bits B é nomeada. O algoritmo húngaro interno associa o objeto em A com a trajetória em B. Entre eles, o ponto central deste caso é a função de correspondência do algoritmo húngaro.
O algoritmo húngaro usa um mecanismo de pontuação ao combinar trajetórias e objetos. Os mecanismos de pontuação são os seguintes:
---- Cs2d: pontuação de acordo com a forma (combinando o ponto central e o tamanho do quadro. Em relação ao quadro anterior, o ponto central o deslocamento não é grande, o tamanho do quadro Se a mudança não for grande, a pontuação é relativamente alta)
---- Dlf: Use recursos de aprendizado profundo para pontuar
---- Kcf: Cada quadro do quadro anterior e o próximo , ambos usam o kcf para aprender suas próprias características e usam a filtragem relacionada. Pontuação
A sessão de perguntas e respostas do professor deu algumas opiniões:
1) O veículo não tripulado usa um algoritmo de rastreamento de múltiplos alvos;
2) Capaz de entender o código já é muito bom
3) A janela deslizante considerada no gráfico bipartido é muito pequena, e considera apenas o quadro atual e o quadro anterior, que também é mais adequado para uso em cenários de direção não tripulada (os recursos de computação não precisam ser grandes)
4) O método de filtragem é relativamente econômico e prático, sendo muito usado na área de drones;
5) O algoritmo de rastreamento com base no gráfico bipartido, em comparação com o aprendizado profundo, é relativamente leve e tem uma quantidade relativamente pequena de cálculo
Resumo pessoal: esta lição apresenta o conhecimento de algoritmos de rastreamento. Comece com rastreamento de alvo único, introduza o conhecimento básico e, em seguida, introduza algoritmos comuns baseados em vários tipos, mas desta vez falta muita literatura, o que é bom. Em seguida, são apresentadas as características do filtro de Kalman. Hahaha, a princípio achei que fosse uma espécie de filtro, denoising, acabou por ser uma espécie de ideia de fusão de informações, que é especialmente adequada para estimativa de estado. No algoritmo de rastreamento, o gráfico bipartido e o algoritmo húngaro usados quando a trajetória é combinada com o objeto são especialmente introduzidos. O algoritmo de rastreamento deve dividir o quadro nos quadros frontal e traseiro, e então determinar se o mesmo objeto é o mesmo, e então a trajetória e o objeto são combinados. Na verdade, é muito complicado e fascinante agora. Resumindo, esta lição enfoca o filtro de Kalman, o algoritmo húngaro usado para correspondência e o algoritmo de rastreamento de múltiplos alvos baseado em correspondência de gráfico bipartido. Vendo o professor, ele assumiu a função no caso e analisou seu significado interno, era poderoso demais. Espero poder ser tão forte algum dia.
########################### Se você
não acumular etapas de silício, terá milhares de quilômetros. Uma
boa memória não é tão boa quanto uma caneta ruim
. Os direitos autorais pertence ao autor original.
Agradeço a dedicação do professor e
acho que é gratificante. Se você fizer isso, me dê um polegar para cima