Visão de máquina (4) - Aplicação de visão de máquina
índice
Um, reconhecimento de rosto
O reconhecimento facial precisa determinar a posição, o tamanho e a postura do rosto (se houver) na imagem de entrada e é frequentemente usado em aplicativos como reconhecimento biométrico, monitoramento de vídeo e interação humano-computador. Em 2001, Viola e Jones propuseram um algoritmo de detecção de objetos classificadores em cascata com base nos recursos do Haar, que foi aprimorado por Lienhart e Maydt em 2002, fornecendo um método eficaz para aplicações de detecção de rosto rápidas e confiáveis. O OpenCV integrou a implementação de código aberto do algoritmo, usando os recursos Haar de um grande número de amostras para treinamento do classificador e, em seguida, chamando a cascata do classificador em cascata treinada para correspondência de padrões.
O algoritmo de reconhecimento de rosto no OpenCV primeiro converte a imagem adquirida em tons de cinza e executa o processamento de bordas e a filtragem de ruído; em seguida, a imagem é reduzida, o histograma é equalizado e o classificador correspondente é ampliado pelo mesmo múltiplo até que corresponda ao classificador. o tamanho é maior do que a imagem detectada, o resultado correspondente será retornado. No processo de correspondência, a correspondência pode ser realizada de acordo com os diferentes tipos no classificador em cascata, como face frontal e face lateral.
OpenCV integrou o algoritmo de reconhecimento facial, só precisa chamar a interface correspondente do OpenCV para realizar a função de reconhecimento facial.
Realização do código-fonte
1. Parte de
inicialização A parte de inicialização completa principalmente a configuração de nós ROS, imagens e parâmetros de reconhecimento.
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 获取haar特征的级联表的XML文件,文件路径在launch文件中传入
cascade_1 = rospy.get_param("~cascade_1", "")
cascade_2 = rospy.get_param("~cascade_2", "")
# 使用级联表初始化haar特征检测器
self.cascade_1 = cv2.CascadeClassifier(cascade_1)
self.cascade_2 = cv2.CascadeClassifier(cascade_2)
# 设置级联表的参数,优化人脸识别,可以在launch文件中重新配置
self.haar_scaleFactor = rospy.get_param("~haar_scaleFactor", 1.2)
self.haar_minNeighbors = rospy.get_param("~haar_minNeighbors", 2)
self.haar_minSize = rospy.get_param("~haar_minSize", 40)
self.haar_maxSize = rospy.get_param("~haar_maxSize", 60)
self.color = (50, 255, 50)
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
2. Função de retorno de chamada de imagem ROS Depois de
receber os dados da imagem RGB liberados pela câmera, o nó de rotina entra na função de retorno de chamada, converte a imagem em formato de dados OpenCV e então começa a chamar a função de reconhecimento de rosto após o pré-processamento e, finalmente, publica o reconhecimento resultado.
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
grey_image = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 创建平衡直方图,减少光线影响
grey_image = cv2.equalizeHist(grey_image)
# 尝试检测人脸
faces_result = self.detect_face(grey_image)
# 在opencv的窗口中框出所有人脸区域
if len(faces_result)>0:
for face in faces_result:
x, y, w, h = face
cv2.rectangle(cv_image, (x, y), (x+w, y+h), self.color, 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(cv_image, "bgr8"))
3.
Reconhecimento facial O reconhecimento facial chama diretamente a interface de reconhecimento facial fornecida pelo OpenCV para corresponder às características faciais no banco de dados.
def detect_face(self, input_image):
# 首先匹配正面人脸的模型
if self.cascade_1:
faces = self.cascade_1.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
# 如果正面人脸匹配失败,那么就尝试匹配侧面人脸的模型
if len(faces) == 0 and self.cascade_2:
faces = self.cascade_2.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
return faces
Existem alguns parâmetros e nomes de tópicos no código que precisam ser definidos no arquivo de inicialização, portanto, você também precisa escrever um arquivo de inicialização para executar a rotina.
<launch>
<node pkg="test2" name="face_detector" type="face_detector.py" output="screen">
<remap from="input_rgb_image" to="/usb_cam/image_raw" />
<rosparam>
haar_scaleFactor: 1.2
haar_minNeighbors: 2
haar_minSize: 40
haar_maxSize: 60
</rosparam>
<param name="cascade_1" value="$(find robot_vision)/data/haar_detectors/haarcascade_frontalface_alt.xml" />
<param name="cascade_2" value="$(find robot_vision)/data/haar_detectors/haarcascade_profileface.xml" />
</node>
</launch>
2. Rastreamento de objeto
O rastreamento de objetos e o reconhecimento de objetos têm semelhanças, e o mesmo método de detecção de pontos de feições é usado, mas o foco é diferente. O objeto para reconhecimento de objeto pode ser estático ou dinâmico, e o modelo estabelecido com base nos pontos de característica do objeto é usado como base de dados para reconhecimento; rastreamento de objeto enfatiza o posicionamento preciso da posição do objeto, e a imagem de entrada geralmente precisa têm características dinâmicas.
A função de rastreamento de objeto primeiro mostra os pontos de característica do objeto no quadro atual da imagem de acordo com o fluxo de imagem de entrada e o objeto selecionado a ser rastreado; em seguida, compara o valor de cinza do quadro atual e o próximo quadro para estimar as características do objeto rastreado no quadro atual A posição do ponto no próximo quadro da imagem; em seguida, filtre os pontos de recurso com a mesma posição, os pontos restantes são os pontos de recurso do objeto de rastreamento no segundo quadro da imagem e o cluster de ponto de recurso é a localização do objeto de rastreamento. Esta função ainda é baseada no algoritmo de processamento de imagem fornecido pelo OpenCV.
Tente escolher um objeto de teste com um fundo de cor sólida e uma grande diferença de cor. Mova o objeto reconhecido na tela, você pode ver que o quadro retangular identifica a posição em tempo real do objeto em movimento, e a área de reconhecimento, limiar e outros parâmetros podem ser ajustados para o ambiente experimental.
Realização do código-fonte
1. Parte de
inicialização A parte de inicialização completa principalmente a configuração de nós ROS, imagens e parâmetros de reconhecimento.
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 设置参数:最小区域、阈值
self.minArea = rospy.get_param("~minArea", 500)
self.threshold = rospy.get_param("~threshold", 25)
self.firstFrame = None
self.text = "Unoccupied"
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
2. Depois que o
nó da rotina de processamento de imagem recebe os dados da imagem RGB liberados pela câmera, ele entra na função de retorno de chamada para converter a imagem no formato OpenCV; após o pré-processamento da imagem ser concluído, os dois quadros das imagens são comparados e o objeto em movimento é identificado com base na diferença de imagem, para identificar os resultados de reconhecimento e publicá-los.
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
# 使用两帧图像做比较,检测移动物体的区域
if self.firstFrame is None:
self.firstFrame = gray
return
frameDelta = cv2.absdiff(self.firstFrame, gray)
thresh = cv2.threshold(frameDelta, self.threshold, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
binary, cnts, hierarchy= cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
# 如果检测到的区域小于设置值,则忽略
if cv2.contourArea(c) < self.minArea:
continue
# 在输出画面上框出识别到的物体
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (50, 255, 50), 2)
self.text = "Occupied"
# 在输出画面上打当前状态和时间戳信息
cv2.putText(frame, "Status: {}".format(self.text), (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(frame, "bgr8"))
Existem alguns parâmetros e nomes de tópicos no código que precisam ser definidos no arquivo de inicialização, portanto, você também precisa escrever um arquivo de inicialização para executar a rotina.
<launch>
<node pkg="test2" name="motion_detector" type="motion_detector.py" output="screen">
<remap from="input_rgb_image" to="/usb_cam/image_raw" />
<rosparam>
minArea: 500
threshold: 25
</rosparam>
</node>
</launch>
Três, reconhecimento de código QR
Os códigos bidimensionais são usados em cada vez mais cenas da vida. Quer seja nas compras em shoppings ou no compartilhamento de bicicletas, os códigos bidimensionais têm sido amplamente usados como um sinal de entrada. ROS fornece uma variedade de pacotes de função de reconhecimento de código QR- (ar_track_alvar)
1. pacote de função ar_track_alvar
A instalação do pacote de função ar_track_alvar é muito simples, basta usar o seguinte comando:
sudo apt-get install ros-kinetic-ar-track-alvar
Após a conclusão da instalação, encontre o pacote de funções ar_track_alvar no diretório de instalação padrão do ROS. Abra a pasta de lançamento no pacote de funções, você pode ver vários arquivos de lançamento. Estas são as rotinas de reconhecimento de código QR utilizadas pelo robô PR2, que podem ser modificadas a partir desses arquivos, para que sua visão de máquina tenha a função de reconhecimento de código QR.
2. Criar código QR O
pacote de funções ar_track_alvar fornece a função de gerar rótulos de código QR. Você pode usar os seguintes comandos para criar rótulos de código QR com os rótulos correspondentes:
rosrun ar_track_alvar createMarker AR_ID
O AR_ID pode ser qualquer número de 0 a 65535, por exemplo:
rosrun ar_track_alvar createMarker 0
Você pode criar uma imagem de rótulo de código QR com um rótulo de 0, nomeá-lo MarkerData_0.png e colocá-lo sob o caminho atual do terminal. Você também pode usar diretamente o visualizador de imagens do sistema para abrir o arquivo de código QR.
A ferramenta createMarker também possui muitos parâmetros que podem ser configurados.Use o seguinte comando para ver a ajuda.
rosrun ar_track_alvar createMarker
createMarker pode não apenas usar rótulos digitais para gerar rótulos de código QR, mas também usar strings, nomes de arquivo, URLs, etc., e também pode usar o parâmetro -s para definir o tamanho do código QR gerado.
Você pode usar os seguintes comandos para criar uma série de rótulos de código QR:
roscd robot_vision/config
rosrun ar_track_alvar createMarker -s 5 0
rosrun ar_track_alvar createMarker -s 5 1
rosrun ar_track_alvar createMarker -s 5 2
3. O
pacote de funções ar_track_alvar de código QR de reconhecimento de câmera suporta câmera USB ou câmera RGB-D como um sensor visual para reconhecer o código QR, correspondendo aos dois nós de reconhecimento diferentes de individualNoKinect e individualMarkers respectivamente.
4. O Kinect reconhece
códigos bidimensionais. Câmeras RGB-D como o Kinect também podem ser usadas para reconhecer códigos bidimensionais.
Quarto, reconhecimento de objeto
O ROS integra uma poderosa estrutura de reconhecimento de objetos - Object Recognition Kitchen (ORK), que contém uma variedade de métodos tridimensionais de reconhecimento de objetos.
1. Pacote de funções ORK
A operação é realizada no Ubuntu 16.04. Como esta versão do kinetic não integra todos os pacotes de funções ORK, as etapas a seguir são necessárias para instalar o código-fonte.
Primeiro instale as bibliotecas dependentes usando o seguinte comando:
sudo apt-get install meshlab
sudo apt-get install libosmesa6-dev
sudo apt-get install python-pyside.qtcore
sudo apt-get install python-pyside.qtgui
Baixe o arquivo rosinstall e compile o
link do arquivo: https://github.com/wg-perception/object_recognition_core
Crie um novo espaço de trabalho ork_ws, baixe o arquivo ork.rosinstall.kinetic.plus diretamente para ork_ws e proceda da seguinte forma:
cd ork_ws
wstool init src [文件路径]/ork.rosinstall.kinetic.plus
Baixe o código-fonte da função:
cd src
wstool update -j8
git clone https://github.com/jbohren/xdot.git
cd ..
rosdep install --from-paths src -i -y
Compilar:
cd ork_ws
catkin_make
Processo de reconhecimento de objeto:
(1) Criar um modelo de objeto que precisa ser reconhecido
(2) Treinar o modelo para gerar um modelo de reconhecimento
(3) Usar o modelo de reconhecimento treinado para reconhecimento de objeto
2. Construir uma biblioteca de modelo de objeto
Criar um banco de dados
Instalar CouchDB Ferramentas:
sudo apt-get install couchdb
Teste se a instalação foi bem-sucedida:
curl -X GET http://localhost:5984
Crie um dado do modelo da Coca-Cola:
rosrun object_recognition_core object_add.py -n "coke " -d "A universal can of coke " --commit
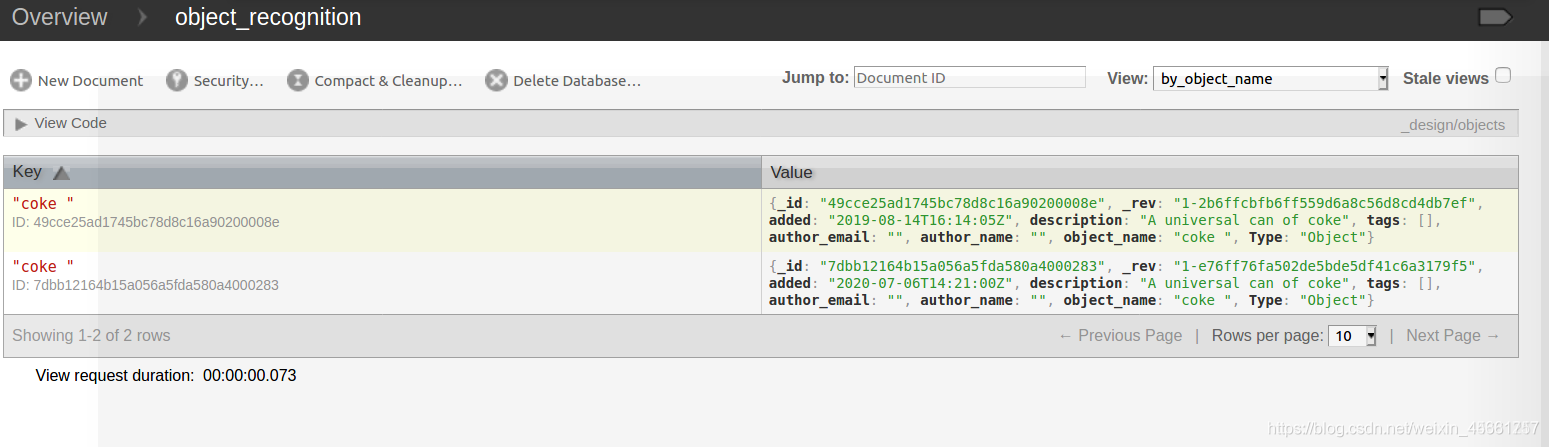
Carregar o modelo 3D
Baixe o modelo coke.stl existente e baixe-o via github:
git clone https://github.com/wg-perception/ork_tutorials
Baixe para o arquivo src; em
seguida, carregue o modelo da Coca-Cola no banco de dados:
rosrun object_recognition_core mesh_add.py 49cce25ad1745bc78d8c16a90200008e [path]/ork_tutorials/data/coke.stl --commit
Veja o modelo:
sudo pip install git+https://github.com/couchapp/couchapp.git
rosrun object_recognition_core push.sh
Clique em object_listing:
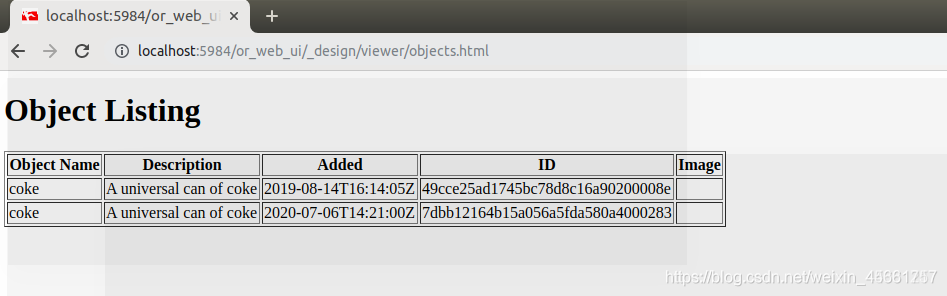
clique em malhas:
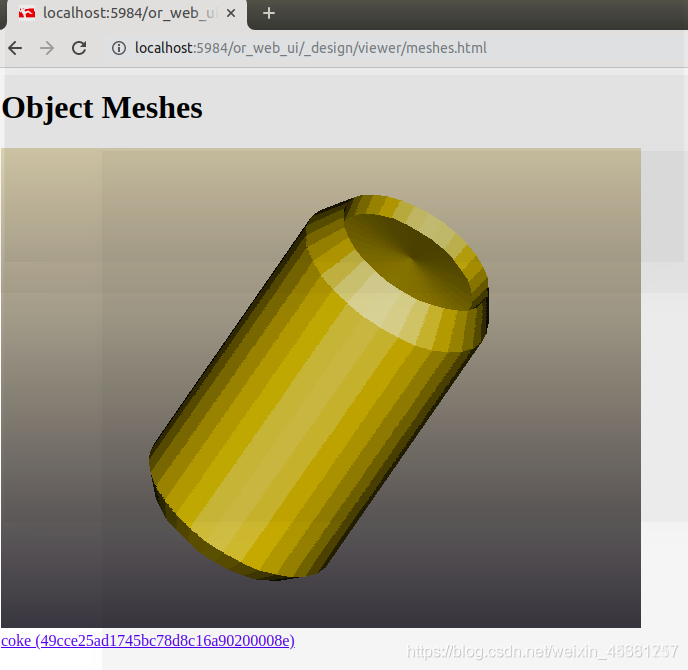
3. Treinamento de modelo
Existem muitos modelos carregados no banco de dados e precisamos treinar para gerar modelos correspondentes.
O comando é o seguinte:
sudo object_recognition_core training -c `rospack find object_recognition_linemod`/conf/training.ork
4. Reconhecimento tridimensional de objetos