Depois de configurar o ambiente do pacote NILMTK, quero encontrar dados para testá-lo. Na API Docs do site oficial NILMTK, descobri que o módulo dataset_converters tem uma função de processamento de conjunto de dados integrada, conforme mostrado na figura:
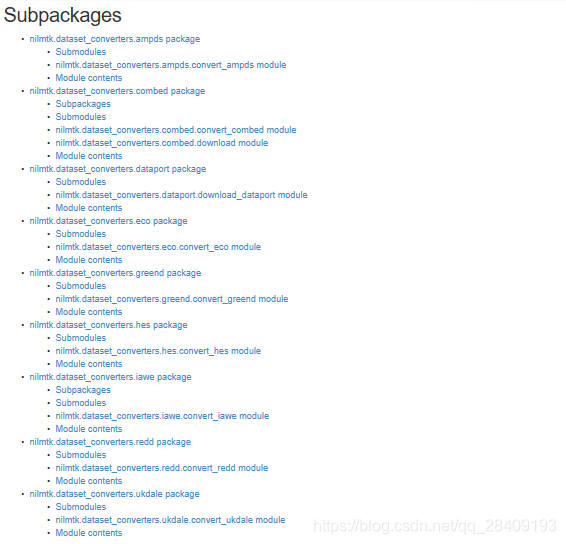
Converta os dados em arquivos HDF. Esses dados são relativamente bons. Entre eles, os conjuntos de dados comumente usados são REDD e UK_DALE.
1. Conjunto de dados REDD
O endereço de download da versão atual é: http://redd.csail.mit.edu , você precisa enviar um e-mail ao autor para obter o nome de usuário e senha para fazer o download!
论文 为 : J. Zico Kolter e Matthew J. Johnson. REDD: Um conjunto de dados públicos para pesquisa de desagregação de energia. Nos anais do workshop SustKDD sobre Aplicações de Mineração de Dados em Sustentabilidade, 2011. [ pdf ]
Os arquivos do conjunto de dados são:

O arquivo contém principalmente dados de energia de baixa frequência e voltagem de alta frequência e dados atuais
low_freq: dados de potência de 1 Hz
alta_freq: dados de forma de onda de tensão e corrente após calibração e agrupamento
high_freq_row: tensão bruta e dados da forma de onda atual
(1) Diretório de arquivo de low_freq

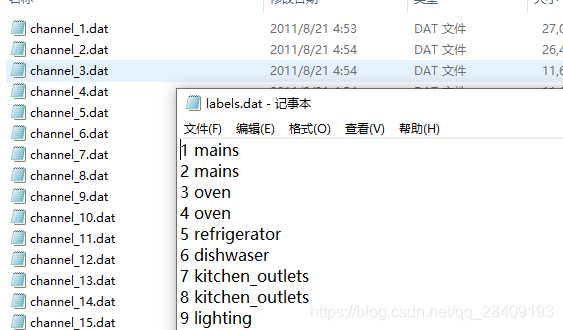
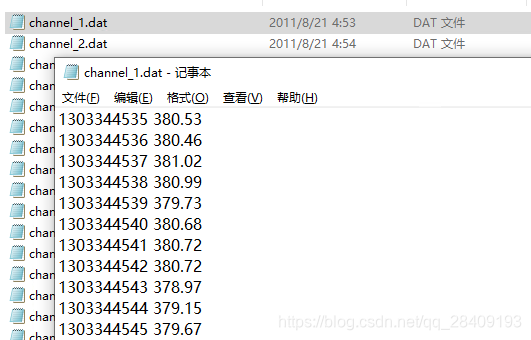
São coletados um total de 6 dados domésticos.Os rótulos registram o tipo de dispositivo de cada canal, e o canal registra os dados de potência do carimbo de data / hora UTC de cada canal.
rótulos:
canal (um ponto por segundo):
(2) Diretório de arquivo de alta_freq

Um total de 6 dados domésticos são coletados, current_1 registra os dados atuais da primeira fonte de energia, current_1 registra os dados atuais da segunda fonte de energia e a tensão registra os dados de tensão.
tem que estar ciente é:
a. O carimbo de data / hora UTC decimal está no mesmo formato que o carimbo de data / hora UTC de baixa frequência, mas isso permite partes fracionárias.
b. Contagem de ciclos. Embora seja expressa como precisão dupla no arquivo, na verdade é um número inteiro que indica quantos ciclos de CA estão reservados para esta forma de onda específica.
c. No período igualmente espaçado, 275 valores decimais representam o valor da forma de onda
Depois de baixar o conjunto de dados, os dados podem ser alterados para o formato HDF por meio da função de dataset_converters:
from nilmtk.dataset_converters import convert_redd
convert_redd(r'C:\Users\admin\Anaconda3\nilm_metadata\low_freq',r'C:\Users\admin\Anaconda3\nilm_metadata\low_freq\redd_low_new.h5')2. Uso do conjunto de dados REDD
a, algoritmo de decomposição de carga
Por meio da API do site oficial do NILMTK, sabemos que os algoritmos para pacotes de decomposição de carga incluem Otimização Combinatória, Fator Hidden Markov (FHMM), Hart 1985 (algoritmo Hart 1985) e CO e FHMM são comumente usados.

b. Realização da decomposição de carga
O exemplo a seguir é calculado por CO e FHMM, e o arquivo é obtido em:
FHMM : O arquivo fhmm_exact no arquivo nilmtk.legacy.disaggregate.
- recuperar dados:
from __future__ import print_function, division
import pandas as pd
import numpy as np
from nilmtk.dataset import DataSet
#from nilmtk.metergroup import MeterGroup
#from nilmtk.datastore import HDFDataStore
#from nilmtk.timeframe import TimeFrame
from nilmtk.disaggregate.combinatorial_optimisation import CombinatorialOptimisation
from nilmtk.legacy.disaggregate.fhmm_exact import FHMM
train = DataSet('C:/Users/admin/PycharmProjects/nilmtktest/low_freq/redd_low.h5') # 读取数据集
test = DataSet('C:/Users/admin/PycharmProjects/nilmtktest/low_freq/redd_low.h5') # 读取数据集
building = 1 ## 选择家庭house
train.set_window(end="30-4-2011") ## 划分数据集,2011年4月20号之前的作为训练集
test.set_window(start="30-4-2011") ## 四月40号之后的作为测试集
## elec包含了这个家庭中的所有的电器信息和总功率信息,building=1-6个家庭
train_elec = train.buildings[1].elec
test_elec = test.buildings[1].elec
top_5_train_elec = train_elec.submeters().select_top_k(k=5) ## 选择用电量排在前5的来进行训练和测试
O primeiro domicílio é selecionado e o consumo de eletricidade está entre os 5 principais dados de aparelhos elétricos para teste.
- Cálculo:
def predict(clf, test_elec, sample_period, timezone): ## 定义预测的方法
pred = {}
gt= {}
#获取总的负荷数据
for i, chunk in enumerate(test_elec.mains().load(sample_period=sample_period)):
chunk_drop_na = chunk.dropna() ### 丢到缺省值
pred[i] = clf.disaggregate_chunk(chunk_drop_na) #### 分解,disaggregate_chunk #通过调用这个方法实现分解,这部分代码在下面可以见到
gt[i]={} ## 这是groudtruth,即真实的单个电器的消耗功率
for meter in test_elec.submeters().meters:
# Only use the meters that we trained on (this saves time!)
gt[i][meter] = next(meter.load(sample_period=sample_period))
gt[i] = pd.DataFrame({k:v.squeeze() for k,v in gt[i].items()}, index=next(iter(gt[i].values())).index).dropna() #### 上面这一块主要是为了得到pandas格式的gt数据
# If everything can fit in memory
gt_overall = pd.concat(gt)
gt_overall.index = gt_overall.index.droplevel()
pred_overall = pd.concat(pred)
pred_overall.index = pred_overall.index.droplevel()
# Having the same order of columns
gt_overall = gt_overall[pred_overall.columns]
#Intersection of index
gt_index_utc = gt_overall.index.tz_convert("UTC")
pred_index_utc = pred_overall.index.tz_convert("UTC")
common_index_utc = gt_index_utc.intersection(pred_index_utc)
common_index_local = common_index_utc.tz_convert(timezone)
gt_overall = gt_overall.ix[common_index_local]
pred_overall = pred_overall.ix[common_index_local]
appliance_labels = [m.label() for m in gt_overall.columns.values]
gt_overall.columns = appliance_labels
pred_overall.columns = appliance_labels
return gt_overall, pred_overall
classifiers = { 'CO':CombinatorialOptimisation(),'FHMM':FHMM()} ### 设置了两种算法,一种是CO,一种是FHMM
predictions = {}
sample_period = 120 ## 采样周期是两分钟
for clf_name, clf in classifiers.items():
print("*"*20)
print(clf_name)
print("*" *20)
clf.train(top_5_train_elec, sample_period=sample_period) ### 训练部分
gt, predictions[clf_name] = predict(clf, test_elec, 120, train.metadata['timezone'])Primeiro, use clf.train para treinar as leis características desses 5 tipos de aparelhos elétricos e, em seguida, use os dados de potência total para decompor as características de vários aparelhos elétricos. gt registra os dados de potência de cada aparelho elétrico, e o período de amostragem é de um ponto em dois minutos. Então, de acordo com os tipos de aparelhos elétricos previstos, cinco aparelhos elétricos com as classificações de consumo de energia mais altas são selecionados.
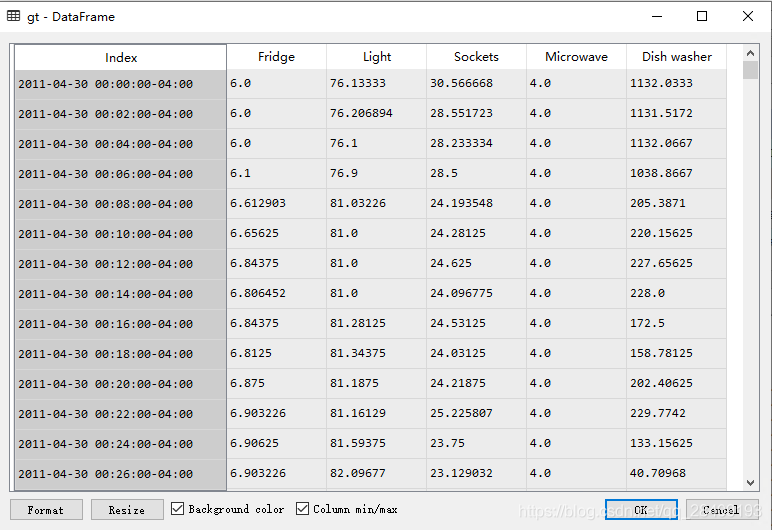
A variável de predições registra os resultados do cálculo dos dois algoritmos:

- Avaliação:
def compute_rmse(gt, pred): ### 评估指标 rmse
from sklearn.metrics import mean_squared_error
rms_error = {}
for appliance in gt.columns:
rms_error[appliance] = np.sqrt(mean_squared_error(gt[appliance], pred[appliance])) ## 评价指标的定义很简单,就是均方根误差
return pd.Series(rms_error)
rmse = {}
for clf_name in classifiers.keys():
rmse[clf_name] = compute_rmse(gt, predictions[clf_name])
rmse = pd.DataFrame(rmse)O resultado do cálculo é:

Blog de referência: https://blog.csdn.net/baidu_36161077/article/details/81144037