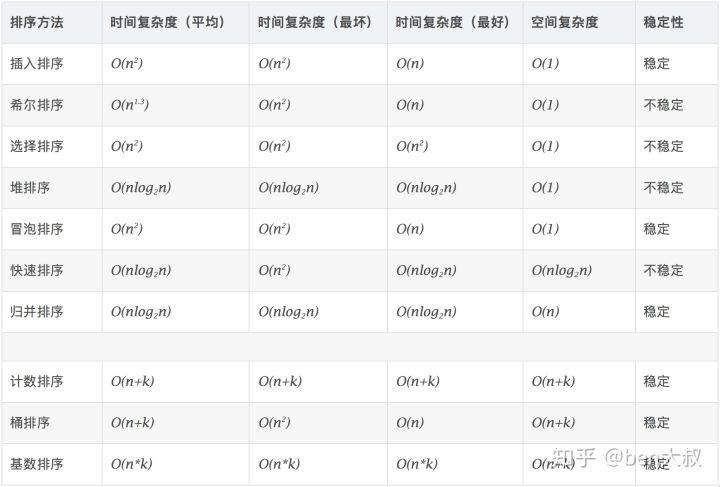
Classificação de algoritmo
Dez algoritmos de classificação comuns podem ser divididos em duas categorias:
- Classificação comparativa : a ordem relativa dos elementos é determinada por comparação. Como sua complexidade de tempo não pode exceder O (nlogn), também é chamada de classificação de comparação de tempo não linear.
- Classificação não comparativa : a ordem relativa dos elementos não é determinada por comparação. Ela pode romper o limite inferior de tempo com base na classificação comparativa e executar no tempo linear, por isso também é chamada de classificação não comparativa no tempo linear.

Complexidade do algoritmo
Conceitos relacionados
- Estável : Se a estiver originalmente na frente de b e a = b, a ainda estará na frente de b após a classificação.
- Instável : se a estiver originalmente na frente de b e a = b, a pode aparecer atrás de b após a classificação.
- Complexidade de tempo : o número total de operações em dados classificados. Reflete a lei do número de operações quando n muda.
- Complexidade do espaço: refere-se ao algoritmo no computador
Uma medida do espaço de armazenamento necessário para execução interna, que também é uma função do tamanho dos dados n.
1. Classificação por bolha (classificação por bolha)
A classificação por bolha é um algoritmo de classificação simples. Ele visitou repetidamente a sequência a ser classificada, comparando dois elementos por vez e trocando-os se estivessem na ordem errada. O trabalho de visitar a sequência é repetido até que não sejam necessárias mais trocas, o que significa que a sequência foi classificada. A origem do nome desse algoritmo é porque quanto menor o elemento irá lentamente "flutuar" para o topo da sequência através da troca.
1.1 Descrição do algoritmo
- Compare os elementos adjacentes. Se o primeiro for maior que o segundo, troque os dois;
- Faça o mesmo trabalho para cada par de elementos adjacentes, do primeiro par no início ao último par no final, de modo que o último elemento seja o maior número;
- Repita as etapas acima para todos os elementos, exceto o último;
- Repita as etapas 1 ~ 3 até que a classificação seja concluída.
1.2 Demonstração de animação

1.3 implementação de código
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
const int maxn = 100;
int arr[maxn], length;
//设置随机数组
void setRandArray(int a[]) {
srand((unsigned)time(NULL));
for (int i = 0; i < length; i++) {
int j = rand() % 100;
a[i] = j;
}
}
//输出数组
void showArray(int* a) {
cout << "数组元素内容:";
for (int i = 0; i < length; i++) {
cout << a[i] << " ";
}
cout << endl;
}
//冒泡排序
void bubbleSort(int *arr) {
for (int i = 0; i < length - 1; i++) {
for (int j = 0; j < length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
}
}
}
}
int main()
{
cout << "输入元素个数:";
cin >> length;
setRandArray(arr);
showArray(arr);
bubbleSort(arr);
cout << "冒泡排序后的数组:" << endl;
showArray(arr);
return 0;
}
2. Classificação por Seleção (Classificação por Seleção)
Seleção-ordenação (Seleção-ordenação) é um algoritmo de ordenação simples e intuitivo. Seu princípio de funcionamento: primeiro encontre o menor (grande) elemento na sequência não classificada, armazene-o no início da sequência classificada e, em seguida, continue a encontrar o menor (grande) elemento dos elementos não classificados restantes e, em seguida, coloque-o no seqüência ordenada No final. E assim por diante, até que todos os elementos sejam classificados.
2.1 Descrição do algoritmo
A seleção direta e a classificação de n registros podem ser diretamente selecionadas e classificadas n-1 vezes para obter um resultado ordenado. O algoritmo específico é descrito a seguir:
- Estado inicial: a área desordenada é R [1..n], e a área ordenada está vazia;
- No início da i-ésima classificação (i = 1,2,3 ... n-1), a área ordenada atual e a área desordenada são R [1..i-1] e R (i..n) respectivamente. Esta viagem de classificação seleciona o registro R [k] com a menor chave da área desordenada atual, e o troca com o primeiro registro R da área desordenada para fazer R [1..i] e R [i + 1 ..n ) Torne-se uma nova área ordenada com o número de registros aumentado em um e uma nova área desordenada com o número de registros diminuído em um;
- No final da passagem n-1, a matriz é ordenada.
2.2 Demonstração de imagens em movimento
2.3 Implementação do código
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
const int maxn = 100;
int arr[maxn], length;
//设置随机数组
void setRandArray(int a[]) {
srand((unsigned)time(NULL));
for (int i = 0; i < length; i++) {
int j = rand() % 100;
a[i] = j;
}
}
//输出数组
void showArray(int* a) {
cout << "数组元素内容:";
for (int i = 0; i < length; i++) {
cout << a[i] << " ";
}
cout << endl;
}
//选择排序
void selectionSort(int arr[]) {
int minIndex, temp;
for (int i = 0; i < length - 1; i++) {
minIndex = i;
for (int j = i + 1; j < length; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
int main()
{
cout << "输入元素个数:";
cin >> length;
setRandArray(arr);
showArray(arr);
selectionSort(arr);
showArray(arr);
return 0;
}
3. Classificação por inserção (classificação por inserção)
A descrição do algoritmo de Insertion-Sort é um algoritmo de classificação simples e intuitivo. Seu princípio de funcionamento é construir uma sequência ordenada. Para dados não classificados, faça a varredura de trás para a frente na sequência classificada, encontre a posição correspondente e insira.
3.1 Descrição do algoritmo
De um modo geral, a classificação por inserção é implementada na matriz usando no local. O algoritmo específico é descrito a seguir:
- A partir do primeiro elemento, pode-se considerar que o elemento foi classificado;
- Retire o próximo elemento e faça a varredura de trás para a frente na sequência ordenada de elementos;
- Se o elemento (classificado) for maior que o novo elemento, mova o elemento para a próxima posição;
- Repita a etapa 3 até encontrar a posição onde o elemento classificado é menor ou igual ao novo elemento;
- Após inserir o novo elemento nesta posição;
- Repita as etapas 2 ~ 5.
3.2 Demonstração de imagens em movimento

3.2 Implementação do código
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
const int maxn = 100;
//设置随机数组
void setRandArray(int a[], int length) {
srand((unsigned)time(NULL));
for (int i = 0; i < length; i++) {
int j = rand() % 100;
a[i] = j;
}
}
//输出数组
void showArray(int* a, int length) {
cout << "数组元素内容:";
for (int i = 0; i < length; i++) {
cout << a[i] << " ";
}
cout << endl;
}
//插入排序
void insertionSort(int *arr,int len){
int preIndex,current;
for(int i = 1; i < len; i++){
preIndex = i - 1;
current = arr[i];
while(preIndex >= 0 && arr[preIndex] > current){
arr[preIndex + 1] = arr[preIndex];
preIndex--;
}
arr[preIndex + 1] = current;
}
}
int main()
{
int arr[maxn], length;
cout << "数组元素个数:";
cin >> length;
setRandArray(arr,length);
showArray(arr,length);
insertionSort(arr,length);
showArray(arr,length);
return 0;
}
4. Classificação Hill (Classificação Shell)
Shell inventou em 1959, o primeiro algoritmo de classificação a quebrar O (n2), que é uma versão aprimorada da classificação por inserção simples. A diferença entre ele e a classificação por inserção é que ele comparará os elementos mais distantes primeiro. A classificação em colina também é chamada de classificação incremental reduzida .
4.1 Descrição do algoritmo
Primeiro divida toda a sequência de registros a serem classificados em várias subseqüências para classificação por inserção direta, a descrição do algoritmo específico:
- Escolha uma sequência incremental t1, t2, ..., tk, onde ti> tj, tk = 1;
- Ordene a sequência k vezes de acordo com o número de sequências de incremento k;
- Em cada passagem de classificação, de acordo com o incremento correspondente ti, a seqüência a ser classificada é dividida em várias subseqüências de comprimento m, e cada subtabela é inserida e classificada diretamente. Quando apenas o fator de incremento é 1, toda a sequência é tratada como uma tabela, e o comprimento da tabela é o comprimento de toda a sequência.
Primeiro, ele divide o conjunto de dados maior em vários grupos (agrupados logicamente) e, em seguida, insere e classifica cada grupo separadamente. Nesse momento, a quantidade de dados usada pela classificação por inserção é relativamente pequena (cada grupo) e a eficiência de inserção relativamente alta
Pode-se ver que ele é um grupo cujos subscritos estão separados por 4 pontos, o que significa que os subscritos diferem por 4 em um grupo. Por exemplo, neste exemplo, a [0] e a [4] são um grupo, um [1] e a [5] são um grupo ..., aqui a diferença (distância) é chamada de incremento
Após inserir a classificação de cada grupo, cada grupo fica ordenado (o todo não é necessariamente ordenado)
Neste ponto, toda a matriz torna-se parcialmente ordenada (o grau de ordem pode não ser muito alto)
Em seguida, reduza o incremento para metade do incremento anterior: 2, continue dividindo o agrupamento, neste momento, o número de elementos em cada agrupamento é maior, mas a parte da matriz torna-se ordenada e a eficiência de classificação de inserção também é maior .
Da mesma forma, cada grupo é classificado (classificação por inserção), de modo que cada grupo seja ordenado individualmente
Por fim, defina o incremento para a metade do incremento anterior: 1, então toda a matriz é dividida em um grupo. Nesse momento, toda a matriz está próxima da ordem e a eficiência de classificação por inserção é alta
Da mesma forma, classifique o único conjunto de dados e a classificação estará completa
4.2 Demonstração de animação
![[imagem de saída video-to-gif]](https://img-blog.csdnimg.cn/img_convert/176a4ad488af4badccccad813ef2f882.gif)
4.3 Implementação do código
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
const int maxn = 100;
//设置随机数组
void setRandArray(int a[], int length) {
srand((unsigned)time(NULL));
for (int i = 0; i < length; i++) {
int j = rand() % 100;
a[i] = j;
}
}
//输出数组
void showArray(int* a, int length) {
cout << "数组元素内容:";
for (int i = 0; i < length; i++) {
cout << a[i] << " ";
}
cout << endl;
}
void insertI(int arr[], int gap, int i){
int inserted = arr[i];
int j;
//插入的时候按组进行插入(组内元素两两相隔gap)
for(j = i - gap; j >= 0 && inserted < arr[j]; j -= gap){
arr[j + gap] = arr[j];
}
arr[j + gap] = inserted;
}
void shellSort(int arr[], int len){
//进行分组,最开始时的增量(gap)为数组长度的一半
for(int gap = len / 2; gap > 0; gap /= 2){
//对各个分组进行插入排序
for(int i = gap; i < len; i++){
//将arr[i]插入到所在分组的正确位置上
insertI(arr,gap,i);
}
}
}
int main()
{
int arr[maxn], length;
cout << "数组元素个数:";
cin >> length;
setRandArray(arr,length);
showArray(arr,length);
shellSort(arr,length);
showArray(arr,length);
return 0;
}
function shellSort(arr) {
var len = arr.length;
for (var gap = Math.floor(len / 2); gap > 0; gap = Math.floor(gap / 2)) {
// 注意:这里和动图演示的不一样,动图是分组执行,实际操作是多个分组交替执行
for (var i = gap; i < len; i++) {
var j = i;
var current = arr[i];
while (j - gap >= 0 && current < arr[j - gap]) {
arr[j] = arr[j - gap];
j = j - gap;
}
arr[j] = current;
}
}
return arr;
}5. Merge Sort (Merge Sort)
A classificação de mesclagem é um algoritmo de classificação eficaz baseado em operações de mesclagem. Este algoritmo é uma aplicação muito típica do Divide and Conquer. Combine as subsequências ordenadas existentes para obter uma sequência completamente ordenada; isto é, primeiro faça cada subsequência em ordem e, em seguida, faça as subsequências em ordem. Se duas listas ordenadas forem mescladas em uma lista ordenada, isso é chamado de mesclagem bidirecional.
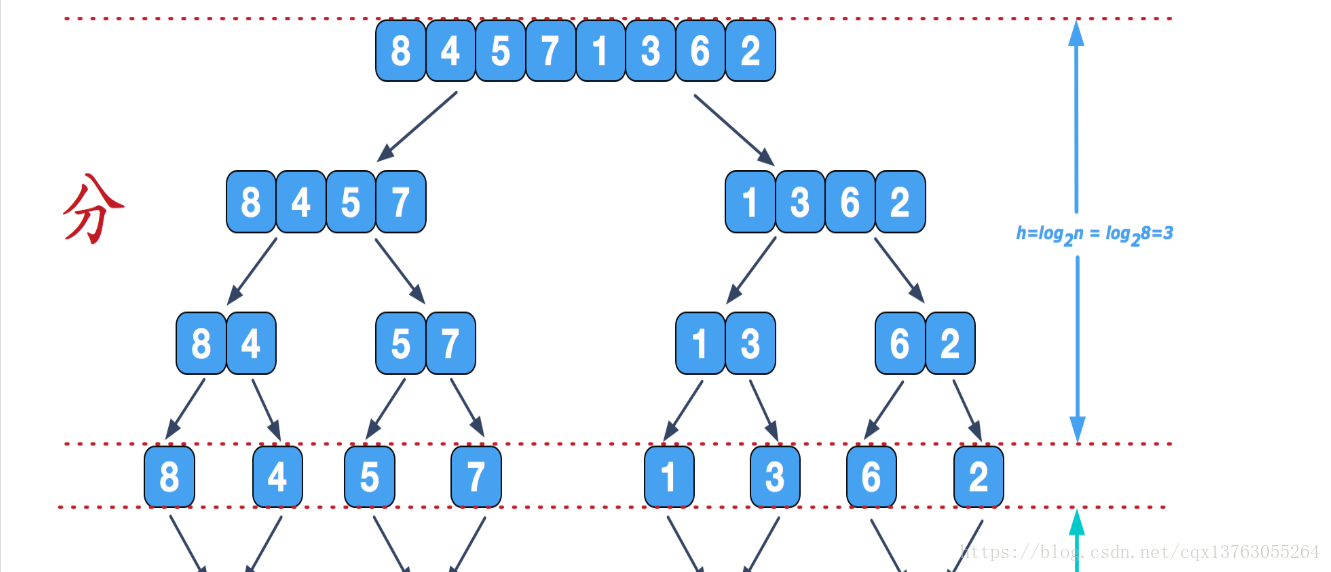
A ideia principal da classificação por mesclagem é dividir e conquistar . O processo principal é:
- Corte n elementos do meio e divida-os em duas partes. (Pode haver mais 1 número à esquerda do que à direita)
- Divida a etapa 1 em duas partes e execute a decomposição recursiva. Até que o número de elementos em todas as partes seja 1.
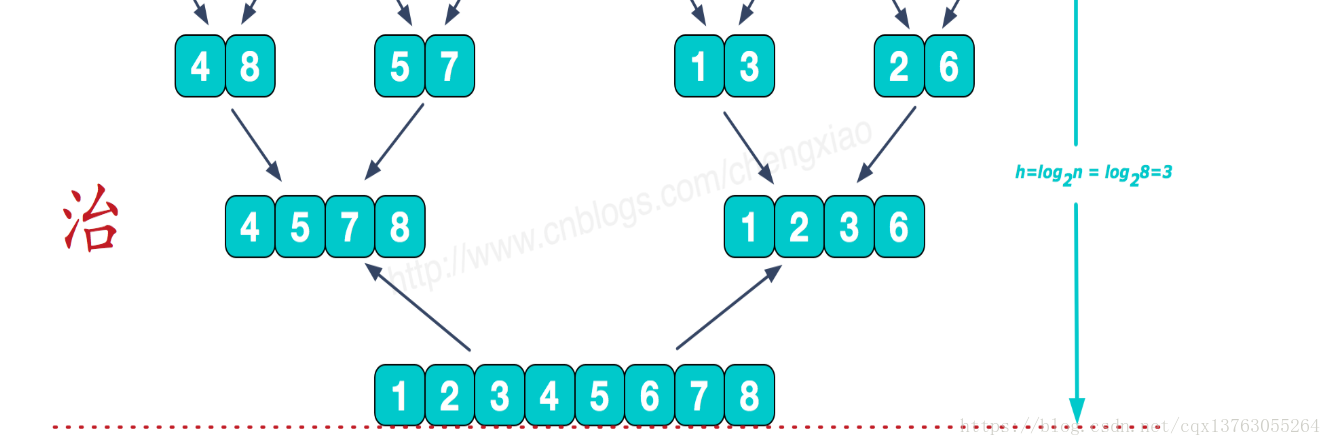
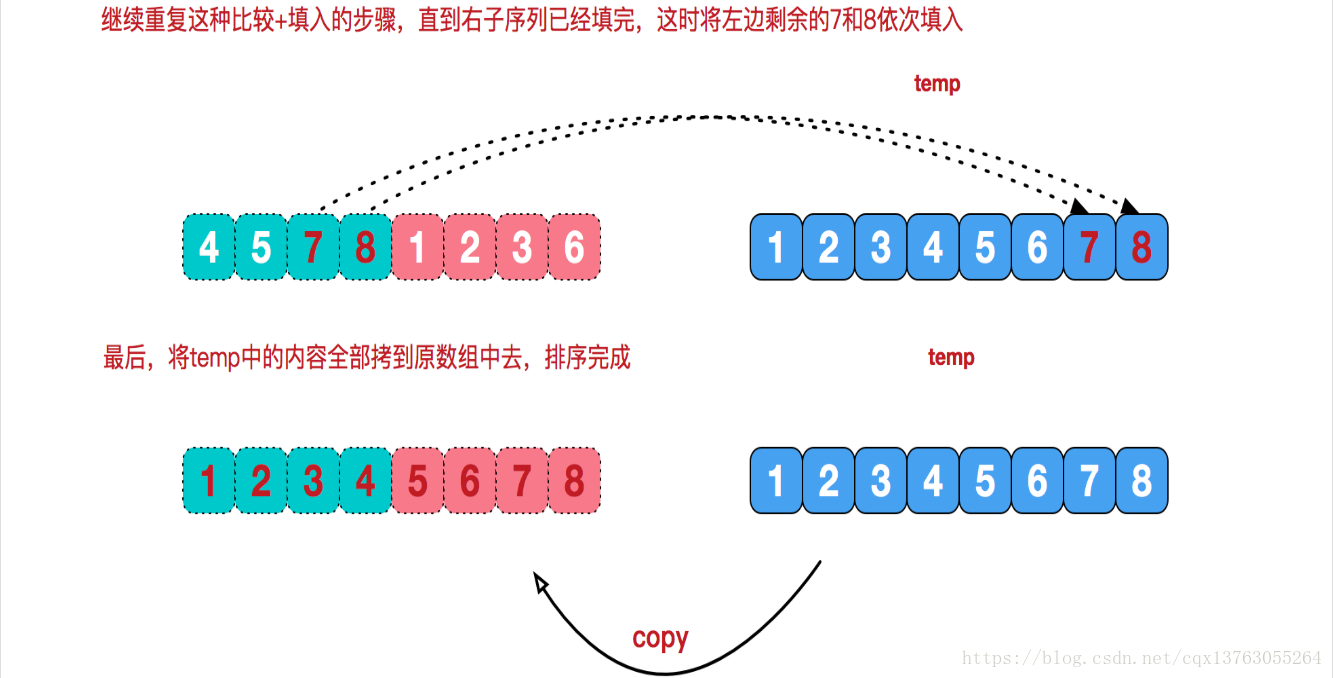
- Começando na camada inferior, mescle gradualmente os dois números sequenciados.
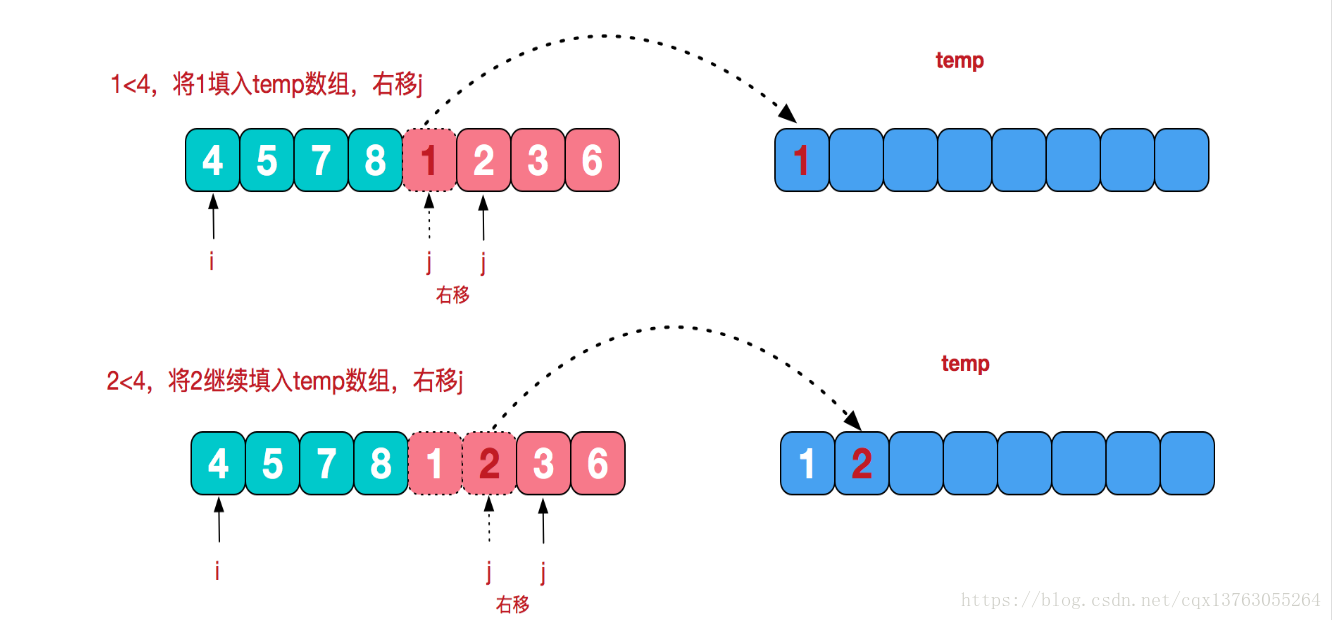
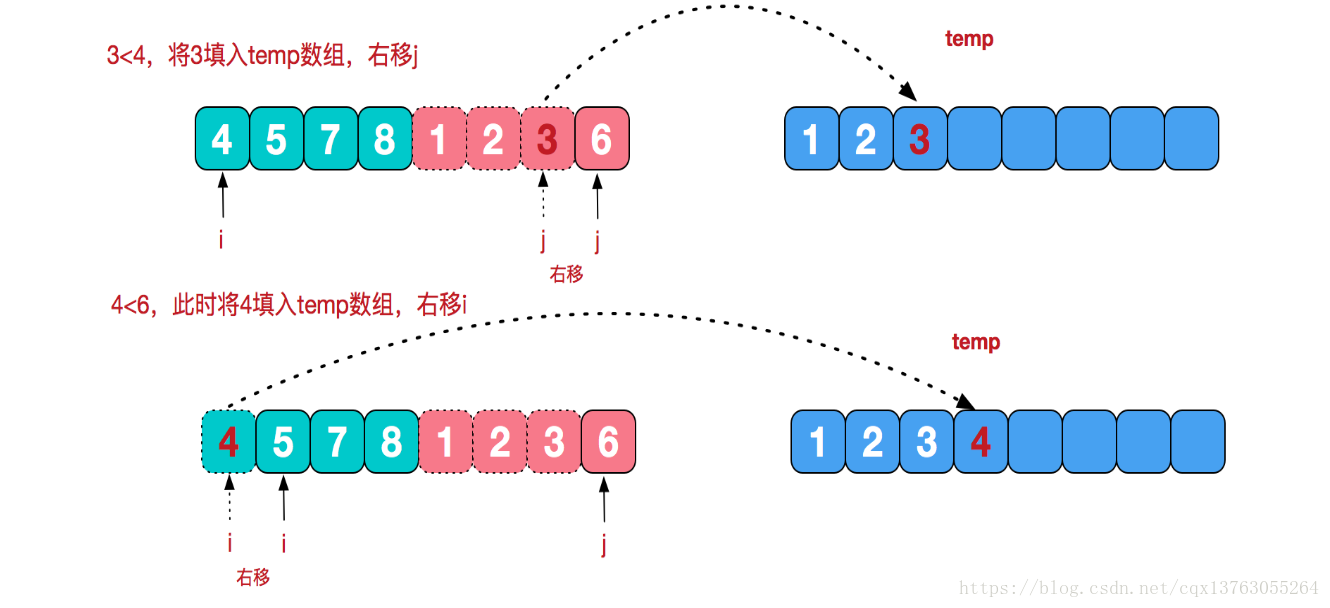
Considere um problema: como mesclar duas sequências de números ordinais em uma sequência de números ordinais?
É muito simples. Como as duas séries já estão em ordem, precisamos apenas pegar o menor número da ordem inferior das duas séries para PK. O perdedor é um valor pequeno, coloque esse valor na série temporária e, em seguida, a parte perdedora continua a fornecer um valor para PK, até que uma parte não tenha elementos e todos os elementos da outra parte sejam seguidos pela sequência temporária. Neste momento, a sequência temporária é uma combinação ordenada de duas sequências. Merge in merge sort é usar essa ideia.
5.1 Descrição do algoritmo
- Divida a sequência de entrada de comprimento n em duas subsequências de comprimento n / 2;
- Mesclar e classificar essas duas subsequências respectivamente;
- As duas subsequências classificadas são mescladas em uma sequência final classificada.
5.2 Demonstração de filme

5.3 Implementação do código
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
const int maxn = 100;
//随机数组
int arr[maxn];
int length;
//设置随机数组
void setRandArray(int a[]) {
srand((unsigned)time(NULL));
for (int i = 0; i < length; i++) {
int j = rand() % 100;
a[i] = j;
}
}
//输出数组
void showArray(int *a) {
cout << "数组元素内容:";
for (int i = 0; i < length; i++) {
cout << a[i] << " ";
}
cout << endl;
}
//将数组a的[L1,R1]与[L2,R2]区间合并为有序区间,此处,L2即为L1 + 1
void merge(int a[], int L1, int R1, int L2, int R2) {
int i = L1; //i指向a[L1]
int j = L2; //j指向a[L2]
int temp[maxn]; //存放合并后的数组
int index = 0; //index为temp的下标
while (i <= R1 && j <= R2) {
if (a[i] <= a[j]) {
temp[index++] = a[i++];
}
else {
temp[index++] = a[j++];
}
}
while (i <= R1)
temp[index++] = a[i++];
while (j <= R2)
temp[index++] = a[j++];
//合并后,再赋回数组a
for (int i = 0; i < index; i++) {
a[L1 + i] = temp[i];
}
}
void mergeSort(int arr[], int left, int right) {
if (left < right) { //只要left小于right
int mid = (left + right) / 2; //取left和right中点
mergeSort(arr, left, mid); //递归,左区间归并
mergeSort(arr, mid + 1, right); //递归,右区间归并
merge(arr, left, mid, mid + 1, right); //左右区间合并
}
}
int main() {
cout << "输入数组元素个数:";
cin >> length;
setRandArray(arr);
showArray(arr);
mergeSort(arr, 0, length - 1);
cout << "归并排序后:" << endl;
showArray(arr);
return 0;
}
5.4 Análise de algoritmo
A classificação por mesclagem é um método de classificação estável . Como a ordenação por seleção, o desempenho da ordenação por mesclagem não é afetado pelos dados de entrada, mas tem um desempenho muito melhor do que a ordenação por seleção porque é sempre uma complexidade de tempo O (nlogn) . O preço é a necessidade de espaço de memória adicional.
6. Classificação rápida (classificação rápida)
7. Classificação Heap (Classificação Heap)
8. Classificação por contagem
9. Classificação de Balde (Classificação de Balde)
10. Radix Sort (Radix Sort)