Kanban 1: Acesso a tópicos de consulta - coleção incremental
ponto importante:
-
No sistema de negócios, o sufixo da tabela de dados é
年_月, o que indica que o sufixo da tabela coletada muda dinamicamente com o tempo.Nosso script deve fazer isso também
-
Esta função deve ser transformada em um script automatizado, que pode ser executado regularmente todos os dias
Coleta incremental, executada uma vez por dia
Colete os dados de ontem no mesmo dia
Simulador de dados
No sistema Linux, é necessário executar o simulador de dados, para verificar se o script incremental está funcionando corretamente no futuro
Endereço do emulador: [email protected]: javacaoyu / edu-data-gen.git
Instale Python3 no Linux
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make zlib zlib-devel libffi-devel -y
wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz
解压安装包,并cd进去
# 编译并安装
./configure --enable-optimizations --prefix=/usr/local/python3.7.4
make && make install
# 将Python执行程序放入/usr/bin/中
ln -s /usr/local/python3.7.4/bin/python3.7 /usr/bin/python3
# 安装代码依赖的第三方库
# 更新pip
python3 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装依赖的库
python3 -m pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
Execute o simulador
Executar simulador incremental
realizado:
python3 current_visit_consult_data_gen.py
Exemplo de configuração de uma tarefa agendada:
* * * * * /usr/bin/python3 /root/current_visit_consult_data_gen.py >> /root/py_gen.log 2>&1
Execute o gerador de dados completo
realizado:
python3 visit_consult_data_gen.py
O padrão no simulador é gerado de 07 2019 a 2020 de dezembro
Se você deseja modificar, apenas modifique o conteúdo do objeto year_month_list no arquivo python.
Banco de dados de negócios -> Processo ODS
- No sistema de negócios, o sufixo da tabela de dados é
年_月, o que indica que o sufixo da tabela coletada muda dinamicamente com o tempo. - Nossa coleção incremental é baseada no dia, e os dados coletados podem ser filtrados por dia.
Execute o script:
#!/bin/bash
# 需求:能够手动传入参数指定采集的日期。 如果不传入参数要求能够自动的识别前一天的日期
if [ $# -eq 0 ]
then
DATESTR=`date -d "-1 day" +%Y-%m-%d`
else
DATESTR=$1
fi
# Define var
SQOOP_HOME=/usr/bin/sqoop
JDBCSTR="jdbc:mysql://192.168.52.150:3306/nev"
MYSQL_USERNAME=root
MYSQL_PASSWORD=123456
YEARSTR=`date -d "-1 day" +%Y`
MONTHSTR=`date -d "-1 day" +%m`
HIVE_DB=itcast_ods
MAP_NUMBER=3
echo "执行采集web_chat_ems_${YEARSTR}_${MONTHSTR}的任务......"
$SQOOP_HOME import \
--connect $JDBCSTR \
--username $MYSQL_USERNAME --password $MYSQL_PASSWORD \
--query "SELECT
id,create_date_time,session_id,sid,create_time,
seo_source,seo_keywords,ip,area,country,province,
city,origin_channel,user AS user_match,manual_time,
begin_time,end_time,last_customer_msg_time_stamp,
last_agent_msg_time_stamp,reply_msg_count,msg_count,
browser_name,os_info, CURRENT_DATE() AS start_time
FROM web_chat_ems_${YEARSTR}_${MONTHSTR}
WHERE create_time >= '${DATESTR} 00:00:00' AND create_time <= '${DATESTR} 23:59:59' and \$CONDITIONS" \
--fields-terminated-by '\t' \
--hcatalog-database $HIVE_DB \
--hcatalog-table web_chat_ems \
-m $MAP_NUMBER \
--split-by id
wait
echo "执行采集web_chat_text_ems_${YEARSTR}_${MONTHSTR}的任务......"
$SQOOP_HOME import \
--connect $JDBCSTR \
--username $MYSQL_USERNAME --password $MYSQL_PASSWORD \
--query "SELECT
id,referrer,from_url,landing_page_url,
url_title,platform_description,
other_params,history, CURRENT_DATE() AS start_time
FROM web_chat_text_ems_${YEARSTR}_${MONTHSTR}
WHERE 1=1 AND \$CONDITIONS" \
--fields-terminated-by '\t' \
--hcatalog-database $HIVE_DB \
--hcatalog-table web_chat_text_ems \
-m $MAP_NUMBER \
--split-by id
Configure as tarefas cronometradas do Oozie
O Oozie é lançado pela Cloudera. Integre-se perfeitamente com o cluster CM. O Oozie pode ser configurado diretamente em Hue, o que é mais conveniente
Azakaban: lançado por Linked
Oozie: É também uma estrutura de agendamento de tarefas, que é basicamente igual ao Azkaban. Em termos de funcionalidade, o Azkaban é realmente melhor.
Existem 2 pontos para escolher Oozie no projeto:
- Na aprendizagem, use mais uma estrutura
- Entre as empresas reais, a maioria das empresas que escolhem CM escolherá Oozie
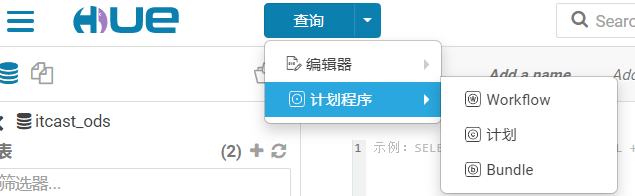
Conforme mostrado na figura, a posição de Oozie em Hue
WorkFlow: representa uma única tarefa
Plano: o plano executado na configuração de WorkFlow configurada, como uma regra regular
Pacote: faça um plano geral para vários planos
Configure o WorkFlow do Oozie
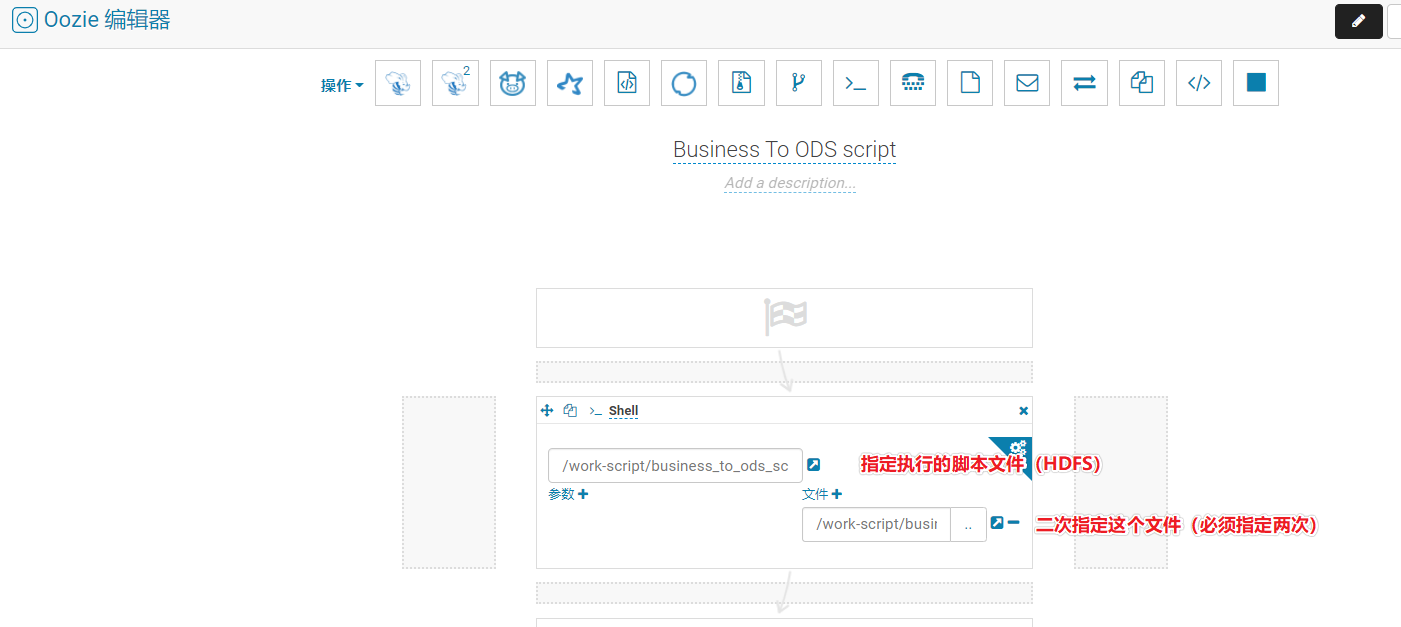
Plano para configurar o Oozie
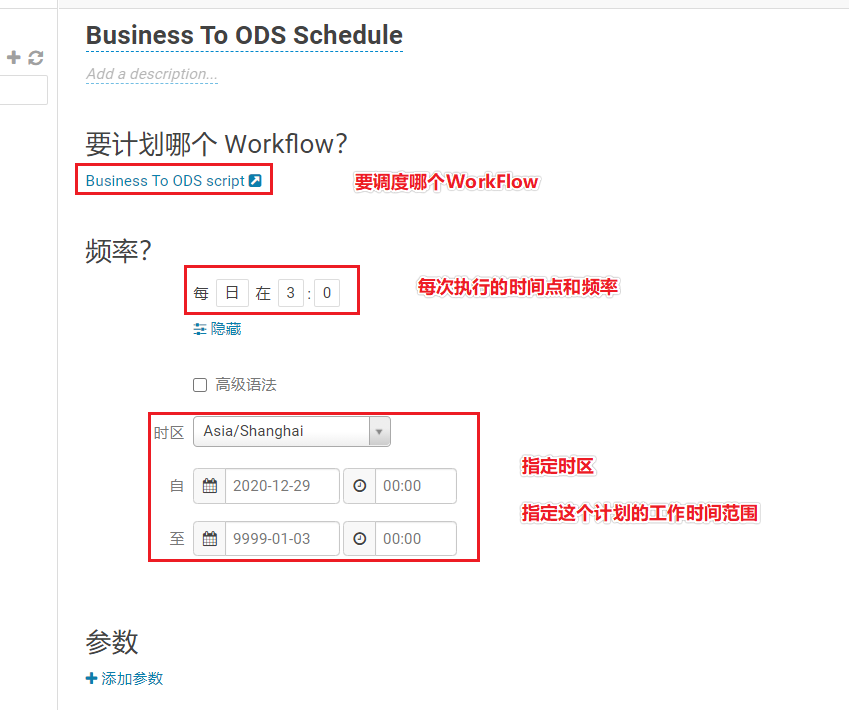
Configurar ODS -> processo DWD
# 配置从ODS层到DWD层的脚本
# 需求:能够手动传入参数指定采集的日期。 如果不传入参数要求能够自动的识别前一天的日期
if [ $# -eq 0 ]
then
DATESTR=`date -d "-1 day" +%Y-%m-%d`
else
DATESTR=$1
fi
HIVE_HOME="/usr/bin/hive"
YEARSTR=`date -d "${DATESTR}" +%Y`
MONTHSTR=`date -d "${DATESTR}" +%m`
DAYSTR=`date -d "${DATESTR}" +%d`
# 计算季度
if [ ${MONTHSTR} -ge 1 ] && [ ${MONTHSTR} -le 3 ]
then
QUARTERSTR=1
elif [ ${MONTHSTR} -ge 4 ] && [ ${MONTHSTR} -le 6 ]
then
QUARTERSTR=2
elif [ ${MONTHSTR} -ge 7 ] && [ ${MONTHSTR} -le 9 ]
then
QUARTERSTR=3
else
QUARTERSTR=4
fi
echo "即将执行:${DATESTR} 这一天的ODS -> DWD的过程......"
$HIVE_HOME -e "
-- 动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
-- hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
-- 写入时ORC压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
INSERT INTO TABLE itcast_dwd.visit_consult_dwd partition(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
w1.session_id,
w1.sid,
UNIX_TIMESTAMP(w1.create_time, 'yyyy-MM-dd HH:mm:ss') AS create_time,
w1.seo_source,
w1.ip,
w1.area,
w1.country,
w1.province,
w1.city,
CAST(IF (w1.msg_count IS NULL, 0, w1.msg_count) AS INT) AS msg_count,
w1.origin_channel,
w2.referrer,
w2.from_url,
w2.landing_page_url,
w2.url_title,
w2.platform_description,
w2.other_params,
w2.history,
SUBSTRING(w1.create_time, 12, 2) AS hourinfo,
SUBSTRING(w1.create_time, 1, 4) AS yearinfo,
QUARTER(w1.create_time) AS quarterinfo,
SUBSTRING(w1.create_time, 6, 2) AS monthinfo,
SUBSTRING(w1.create_time, 9, 2) AS dayinfo
FROM (SELECT * FROM itcast_ods.web_chat_ems WHERE start_time='${DATESTR}') AS w1 INNER JOIN itcast_ods.web_chat_text_ems AS w2
ON w1.id = w2.id;"
DWD -> processo DWS
problema
Nosso DWS contém os dados de resultado de dimensões como ano, trimestre, mês, etc.
Devido à adição de dados de um dia, os dados de resultado do ano atual, trimestre atual e mês atual são inválidos
Precisa recalcular
A questão é: como lidar com os dados inválidos usados na tabela DWS.
Método de resolução de problemas
Caminho 1
Excluir dados expirados
vantagem:
- Amigável para BI, não há confusão de dados históricos, basta pegar o mais recente
- Os dados da tabela são claros
Desvantagens:
- Execução complexa
- Quebrou o princípio de não excluir o máximo possível no design do data warehouse
Caminho 2:
Adicionar nova coluna, nome da tabela, hora de cálculo dos dados atuais
Ao usá-lo, use o tempo mais recente
vantagem:
- As alterações nos resultados históricos são armazenadas na tabela
- Não executará a exclusão, não destruirá o princípio do data warehouse
Desvantagens:
- Para análise de BI, você precisa filtrar os dados mais recentes primeiro (um pouco hostil)
- Modifique a estrutura da tabela (todas as operações devem ser repetidas)
Caminho 3:
Adicionar nova mesa
Uma tabela é gerada para os resultados de cada dia (uma tabela por dia)
vantagem:
- Cada tabela é clara e aponta para os resultados de um dia específico
- Mudanças nos resultados históricos registrados por meio de várias tabelas
Desvantagens:
- Muita redundância de dados (contanto que o negócio precise, redundância não é um problema)
- Não é amigável para o BI (mudar um dia, mudar uma tabela, se o BI não suportar a configuração de regras dinâmicas para alterar automaticamente a tabela, você deve alterá-la manualmente)
Nessas três maneiras, não há bem ou mal absoluto
Sob a demanda certa, basta escolher o caminho certo.
Scripting
Exclusão de dados expirados
# 删除过期年的数据
ALTER TABLE itcast_dws.visit_dws DROP PARTITION(yearinfo='当前年', quarterinfo='-1', monthinfo='-1', dayinfo='-1');
# 删除过期季度的数据
ALTER TABLE itcast_dws.visit_dws DROP PARTITION(yearinfo='当前年', quarterinfo='当前季度', monthinfo='-1', dayinfo='-1');
# 删除过期月的数据
ALTER TABLE itcast_dws.visit_dws DROP PARTITION(yearinfo='当前年', quarterinfo='当前季度', monthinfo='当前月', dayinfo='-1');
Instruções de script
O script pode usar o script completo, as coisas que precisam ser alteradas são:
Traga para o ano:
WHERE yearinfo = '${YEARSTR}'
Trazendo para o trimestre:
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}'
Traga para o mês:
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}'
Traz dias e horas:
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}' AND dayinfo = '${DAYSTR}'
Independentemente da quantidade de visitas ou consultas, ambos precisam trazer a filtragem de condição WHERE acima
Não se esqueça de apagar os dados expirados primeiro
Script de amostra
# DWD层数据聚合到DWS层的操作脚本(增量)
# 需求:能够手动传入参数指定采集的日期。 如果不传入参数要求能够自动的识别前一天的日期
if [ $# -eq 0 ]
then
DATESTR=`date -d "-1 day" +%Y-%m-%d`
else
DATESTR=$1
fi
HIVE_HOME="/usr/bin/hive"
YEARSTR=`date -d "${DATESTR}" +%Y`
MONTHSTR=`date -d "${DATESTR}" +%m`
DAYSTR=`date -d "${DATESTR}" +%d`
# 计算季度
if [ ${MONTHSTR} -ge 1 ] && [ ${MONTHSTR} -le 3 ]
then
QUARTERSTR=1
elif [ ${MONTHSTR} -ge 4 ] && [ ${MONTHSTR} -le 6 ]
then
QUARTERSTR=2
elif [ ${MONTHSTR} -ge 7 ] && [ ${MONTHSTR} -le 9 ]
then
QUARTERSTR=3
else
QUARTERSTR=4
fi
echo "先删除过期的${YEARSTR}年, ${QUARTERSTR}季度, ${MONTHSTR}月数据"
$HIVE_HOME -e "
# 删除过期年的数据
ALTER TABLE itcast_dws.visit_dws DROP PARTITION(yearinfo='${YEARSTR}', quarterinfo='-1', monthinfo='-1', dayinfo='-1');
# 删除过期季度的数据
ALTER TABLE itcast_dws.visit_dws DROP PARTITION(yearinfo='${YEARSTR}', quarterinfo='${QUARTERSTR}', monthinfo='-1', dayinfo='-1');
# 删除过期月的数据
ALTER TABLE itcast_dws.visit_dws DROP PARTITION(yearinfo='${YEARSTR}', quarterinfo='${QUARTERSTR}', monthinfo='${MONTHSTR}', dayinfo='-1');"
echo "执行新数据的计算,计算的日期是:${DATESTR}"
$HIVE_HOME -e "
/*
指标:访问量
维度:时间(年、季度、月、天、小时)、来源渠道、受访页面、搜索渠道、区域维度
*/
-- 时间维度表开发
-- 动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
-- hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
-- 写入时ORC压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 统计某年的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
'-1' AS country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
yearinfo AS time_str,
'-1' AS from_url,
'5' AS groupType,
'5' AS time_type,
yearinfo,
'-1' AS quarterinfo,
'-1' AS monthinfo,
'-1' AS dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}'
GROUP BY yearinfo;
-- 统计某年某季度的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
'-1' AS country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
CONCAT(yearinfo, '-Q', quarterinfo) AS time_str,
'-1' AS from_url,
'5' AS groupType,
'4' AS time_type,
yearinfo,
quarterinfo,
'-1' AS monthinfo,
'-1' AS dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}'
GROUP BY yearinfo, quarterinfo;
-- 统计某年某季度某月的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
'-1' AS country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
CONCAT(yearinfo, '-', monthinfo) AS time_str,
'-1' AS from_url,
'5' AS groupType,
'3' AS time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' AS dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}'
GROUP BY yearinfo, quarterinfo, monthinfo;
-- 统计某年某季度某月某日的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
'-1' AS country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
CONCAT(yearinfo, '-', monthinfo, '-', dayinfo) AS time_str,
'-1' AS from_url,
'5' AS groupType,
'2' AS time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}' AND dayinfo = '${DAYSTR}'
GROUP BY yearinfo, quarterinfo, monthinfo, dayinfo;
-- 统计某年某季度某月某日某小时的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
'-1' AS country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
hourinfo,
CONCAT(yearinfo, '-', monthinfo, '-', dayinfo, ' ', hourinfo) AS time_str,
'-1' AS from_url,
'5' AS groupType,
'1' AS time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}' AND dayinfo = '${DAYSTR}'
GROUP BY yearinfo, quarterinfo, monthinfo, dayinfo, hourinfo;
-- 按照时间和其它维度汇合进行聚合
-- 按照时间和国家进行组合计算
-- 动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
-- hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
-- 写入时ORC压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 统计某年某国家的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
yearinfo AS time_str,
'-1' AS from_url,
'1' AS groupType,
'5' AS time_type,
yearinfo,
'-1' AS quarterinfo,
'-1' AS monthinfo,
'-1' AS dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}'
GROUP BY yearinfo,country;
-- 统计某年某季度某国家的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
CONCAT(yearinfo, '-Q', quarterinfo) AS time_str,
'-1' AS from_url,
'1' AS groupType,
'4' AS time_type,
yearinfo,
quarterinfo,
'-1' AS monthinfo,
'-1' AS dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}'
GROUP BY yearinfo, quarterinfo, country;
-- 统计某年某季度某月某国家的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
CONCAT(yearinfo, '-', monthinfo) AS time_str,
'-1' AS from_url,
'1' AS groupType,
'3' AS time_type,
yearinfo,
quarterinfo,
monthinfo,
'-1' AS dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}'
GROUP BY yearinfo, quarterinfo, monthinfo, country;
-- 统计某年某季度某月某天某国家的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
'-1' AS hourinfo,
CONCAT(yearinfo, '-', monthinfo, '-', dayinfo) AS time_str,
'-1' AS from_url,
'1' AS groupType,
'2' AS time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}' AND dayinfo = '${DAYSTR}'
GROUP BY yearinfo, quarterinfo, monthinfo, dayinfo, country;
-- 统计某年某季度某月某天某小时某国家的访问量
INSERT INTO TABLE itcast_dws.visit_dws PARTITION(yearinfo, quarterinfo, monthinfo, dayinfo)
SELECT
COUNT(DISTINCT sid) AS sid_total,
COUNT(DISTINCT session_id) AS sessionid_total,
COUNT(DISTINCT ip) AS ip_total,
country,
'-1' AS province,
'-1' AS city,
'-1' AS seo_source,
'-1' AS origin_channel,
hourinfo,
CONCAT(yearinfo, '-', monthinfo, '-', dayinfo, ' ', hourinfo) AS time_str,
'-1' AS from_url,
'1' AS groupType,
'1' AS time_type,
yearinfo,
quarterinfo,
monthinfo,
dayinfo
FROM itcast_dwd.visit_consult_dwd
WHERE yearinfo = '${YEARSTR}' AND quarterinfo = '${QUARTERSTR}' AND monthinfo = '${MONTHSTR}' AND dayinfo = '${DAYSTR}'
GROUP BY yearinfo, quarterinfo, monthinfo, dayinfo, hourinfo, country;
"
Configurar o tempo do Oozie
Isso também precisa ser executado uma vez por dia.
Basta configurá-lo por trás do processo Oozie original (todos são o mesmo WorkFlow)
DWS -> MySQL
Se o DWS usar o método 1, o MySQL também deve excluir o expirado
O script de exportação precisa ser excluído do MySQL antes da execução
Exemplo:
mysql -uroot -p123456 scrm_bi -e "
# 删除过期年
delete from itcast_visit WHERE yearinfo='${YEARSTR}' AND quarterinfo='-1' AND monthinfo='-1' AND dayinfo='-1';
# 删除过期季度
delete from itcast_visit WHERE yearinfo='${YEARSTR}' AND quarterinfo='${QUARTERSTR}' AND monthinfo='-1' AND dayinfo='-1';
# 删除过期月
delete from itcast_visit WHERE yearinfo='${YEARSTR}' AND quarterinfo='${QUARTERSTR}' AND monthinfo='${MONTHSTR}' AND dayinfo='-1';
"
sqoop export \
--connect "jdbc:mysql://192.168.52.150:3306/scrm_bi?useUnicode=true&characterEncoding=utf-8" \
--username root --password 123456 \
--table itcast_visit \
--hcatalog-database itcast_dws \
--hcatalog-table visit_dws \
--hcatalog-partition-keys yearinfo \
--hcatalog-partition-values ${YEARSTR} \
-m 1
O Oozie WorkFlow final
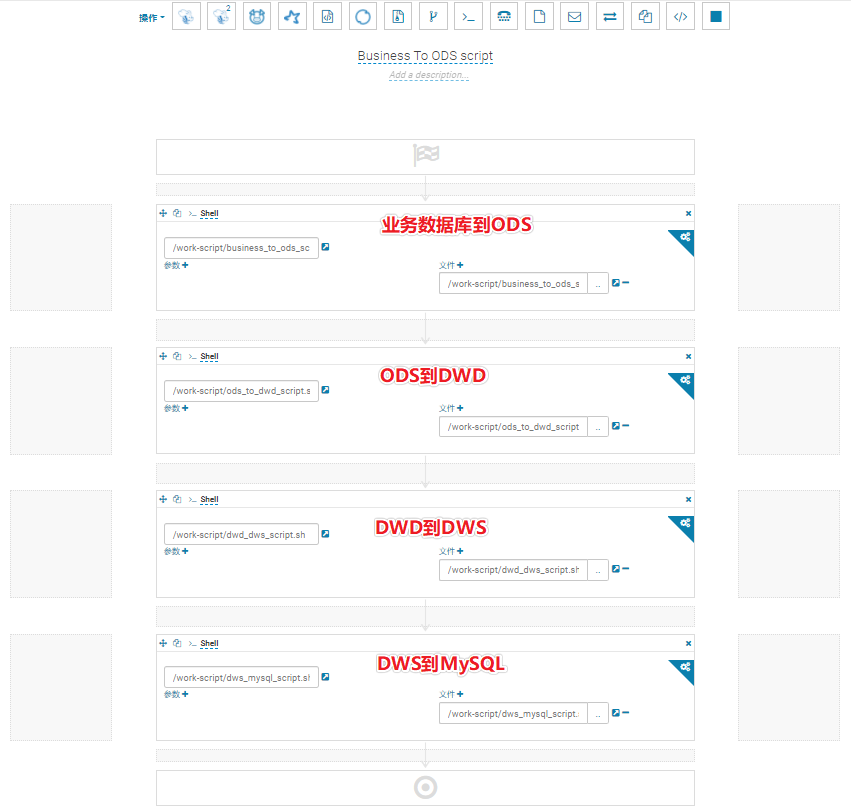
Kanban One Homework
responder
- Ser capaz de dizer a introdução do projeto, a indústria do projeto e o que fazer. Em que prestar atenção
- Posso dizer quais são os indicadores e dimensões do Kanban Um
- Capaz de dizer o pensamento e o processo de modelagem e análise
- Capacidade de analisar diferentes práticas e vantagens e desvantagens para dados incrementais
prática
-
Todo o processo pode ser concluído do início ao fim (do banco de dados de negócios -> ODS -> DWD -> DWS -> MySQL)
Muito SQL foi omitido na aula, então você não pode omitir quando você faz isso sozinho.
Envie-me o endereço do seu depósito.