1. Compreenda os três elementos do aprendizado de máquina
- Aprendizado de máquina = modelo + estratégia (verifique se o modelo é bom ou ruim) + algoritmo
Modelo: lei y = ax +
estratégia b : que tipo de modelo é um bom modelo?
Algoritmo da função de perda : como encontrar com eficiência os parâmetros ideais, os parâmetros a e b no modelo
1.1 Modelo
-
No aprendizado de máquina, devemos primeiro considerar que tipo de modelo aprender. No aprendizado supervisionado, o modelo y = kx + b é o que precisamos aprender.
-
Classificação do modelo
- Função de decisão: fornecer apenas valores pertencentes a uma árvore de decisão de categoria
- Função de distribuição de probabilidade condicional: não apenas fornece o valor da categoria, mas também fornece a probabilidade - algoritmo LR

1.2 Estratégia
Para avaliar a qualidade do modelo, use a função de perda para medir a diferença entre o valor dado pelo modelo e o valor real.
A função de perda mede a qualidade da previsão de um modelo. As funções de perda comumente usadas são:
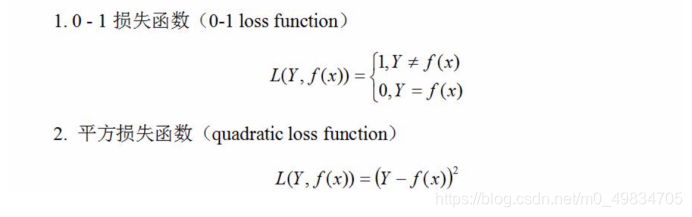

quanto menor o valor da função de perda, melhor é o modelo.
1.3 Algoritmo
O algoritmo de aprendizado de máquina é um algoritmo para resolver problemas de otimização
2. Como construir um sistema de aprendizado de máquina
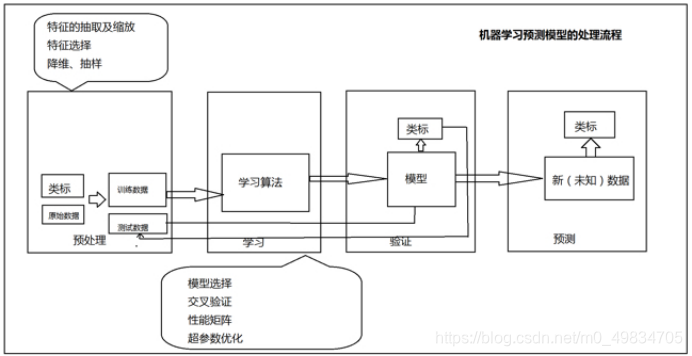
- 1- preparar dados
- 2- engenharia de recursos
- 1- Processe os dados
- Amostragem de dados de amostra - linha
- 2- Processar os recursos
- Seleção de recursos
- Redução da dimensionalidade do recurso
- Amostragem de recursos
- 1- Processe os dados
- 3- modelo de treinamento
- Algoritmo de aprendizagem de dados + máquina
- Parâmetros: o que o aprendizado de máquina aprende é um modelo, e o que ele aprende são essencialmente os parâmetros correspondentes no modelo
- Hiperparâmetros: os parâmetros especificados com antecedência antes do treinamento do modelo de aprendizado de máquina são chamados de hiperparâmetros, como o número de iterações alfa
- y = kx + b especifica o número de iterações alfa = 20 k = 5, b = 3 y = 5x + 3 y = 4x + 6
- 4- escolha o melhor modelo
- O modelo não é apenas bom para o conjunto de treinamento, mas também bom para o teste ==> bom desempenho de generalização do modelo
- 5- fazer previsões sobre novos dados
- O modelo foi treinado e pode atender aos requisitos
3. Seleção de modelo
- Conceitos básicos
1) Generalização: O modelo tem boa capacidade de generalização significa que o modelo não só tem um bom desempenho no conjunto de dados de treinamento, mas também tem um bom efeito na adaptabilidade a novos dados.
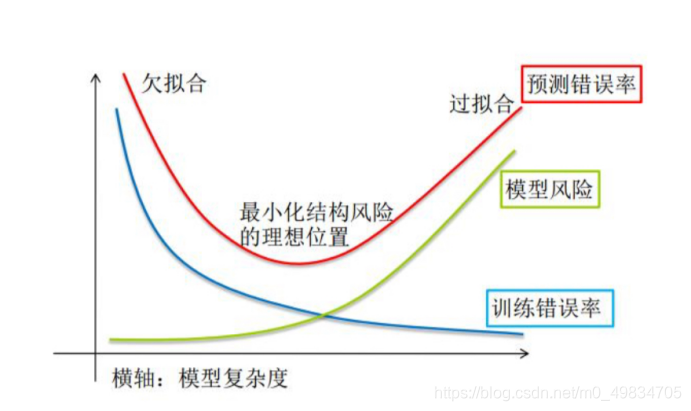
Quando discutimos a capacidade de aprendizado e a capacidade de generalização de um modelo de aprendizado de máquina, geralmente usamos os conceitos de overfitting e underfitting. Overfitting e underfitting também são as duas principais razões para o baixo desempenho dos algoritmos de aprendizado de máquina.
2) Overfitting : O modelo tem um bom desempenho em dados de treinamento, mas um desempenho ruim em dados desconhecidos ou conjunto de teste.
3) Underfitting : baixo desempenho nos dados de treinamento e dados desconhecidos.
Exemplo: qual curva se ajusta melhor? A
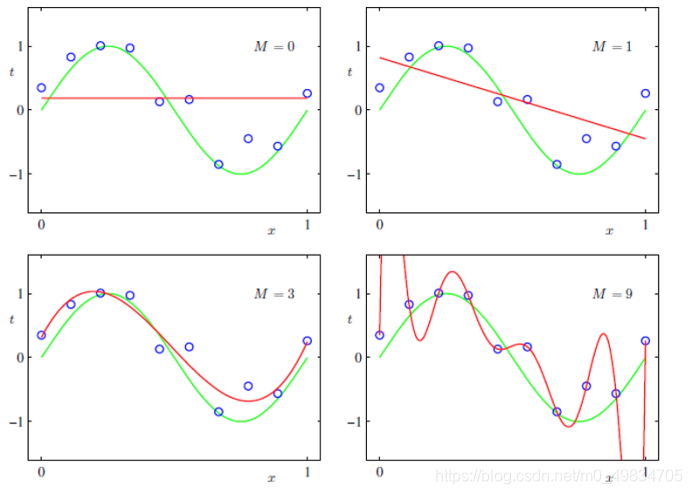
primeira imagem e a segunda são imagens mal ajustadas
- Underfitting
- O modelo tem um desempenho ruim no conjunto de dados de treinamento e no conjunto de dados de teste
- Momento de ocorrência do subajuste:
- Estágio inicial de treinamento do modelo
- O motivo da falta de ajuste?
- O modelo é muito simples
- y = t ou y = -2x + 3
- O modelo é muito simples
- Como resolver o problema de underfitting?
- Adicionar recursos polinomiais
- Prever preços de moradias - área, aumentar localização + número de moradias, etc.
- y = k1x1 + b ===》 y = k1xk2x2 + b1
- Aumenta o grau do termo polinomial
- y = k1x1 + b ==》 y = k1 * x1 ** 2 + k2 * xb
- Reduzir penalidades regulares
- Adicionar recursos polinomiais
A quarta imagem é uma imagem super ajustada
- Sobreajuste
- O modelo funciona bem no conjunto de treinamento, mas funciona mal em novos dados ou dados de teste
- O período de overfitting:
- Treinamento de modelo intermediário e tardio
- Razões para overfitting:
- O modelo é muito complexo + poucos dados de treinamento + dados impuros
- Solução de sobreajuste:
- 1- Aumente a penalidade regular ===> o modelo é muito complicado
- 2- Reamostrar dados de treinamento
- 3- Limpe novamente os dados
- 4-método de abandono - descartar aleatoriamente alguns dados de amostra
A escolha de um bom modelo requer um bom desempenho de generalização para evitar underfitting e overfitting.
Siga o princípio da navalha de Occam : Com base em ter a mesma capacidade de generalização ou semelhante, prefira um modelo mais simples. A essência é: evitar que o modelo super ajuste
3.1 Experiência de risco e risco estrutural
A perda média do modelo f (x) no conjunto de dados de treinamento é chamada de risco empírico ou perda empírica, que é registrada como
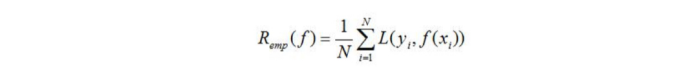
as duas estratégias básicas de aprendizagem supervisionada R (emp) : minimização do risco empírico e risco estrutural Minimize .
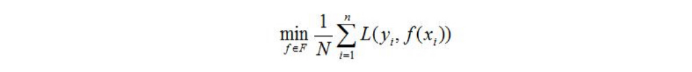
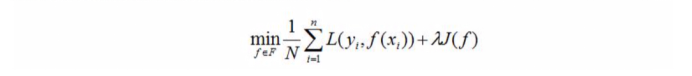
3.2 Avaliação e seleção do modelo
Quando a função de perda é fornecida, o erro de treinamento do modelo baseado na função de perda e o erro de teste do modelo naturalmente se tornarão o padrão para a avaliação do método de aprendizagem .

3.3 Regularização
O método típico de seleção de modelo é a regularização. A forma geral de regularização é a seguinte:

um modelo com menos risco empírico pode ser mais complicado e o valor do termo de regularização será maior neste momento. O papel da regularização é selecionar o risco empírico e a complexidade do modelo. Modelo pequeno.
O termo de regularização está de acordo com o princípio da navalha de Occam. Dentre todos os modelos possíveis, o melhor modelo é aquele que consegue analisar bem os dados conhecidos e é muito simples. Do ponto de vista da estimativa Bayesiana, regularização O termo corresponde à probabilidade anterior do modelo, pode-se supor que um modelo complexo tenha uma probabilidade anterior menor e um modelo simples tenha uma probabilidade anterior maior.
4. Expanda as bibliotecas de aprendizado de máquina comuns
Com a ajuda de muitas bibliotecas de código aberto poderosas desenvolvidas nos últimos anos, agora é a melhor hora para entrar no campo do aprendizado de máquina. Usando uma biblioteca de aprendizado de máquina madura para me ajudar a completar o algoritmo, só precisamos entender como ajustar os parâmetros de cada modelo para poder aplicar o modelo a cenários reais de negócios.
- Biblioteca Sklearn baseada em Python
- Ferramentas simples e eficientes de mineração e análise de dados
- Pode ser usado por todos, pode ser reutilizado em vários ambientes
- Construído em NumPy, SciPy e matplotlib
- Código aberto, disponível comercialmente - obtenha licença BSD

- O SparkMLLIB baseado em Scala
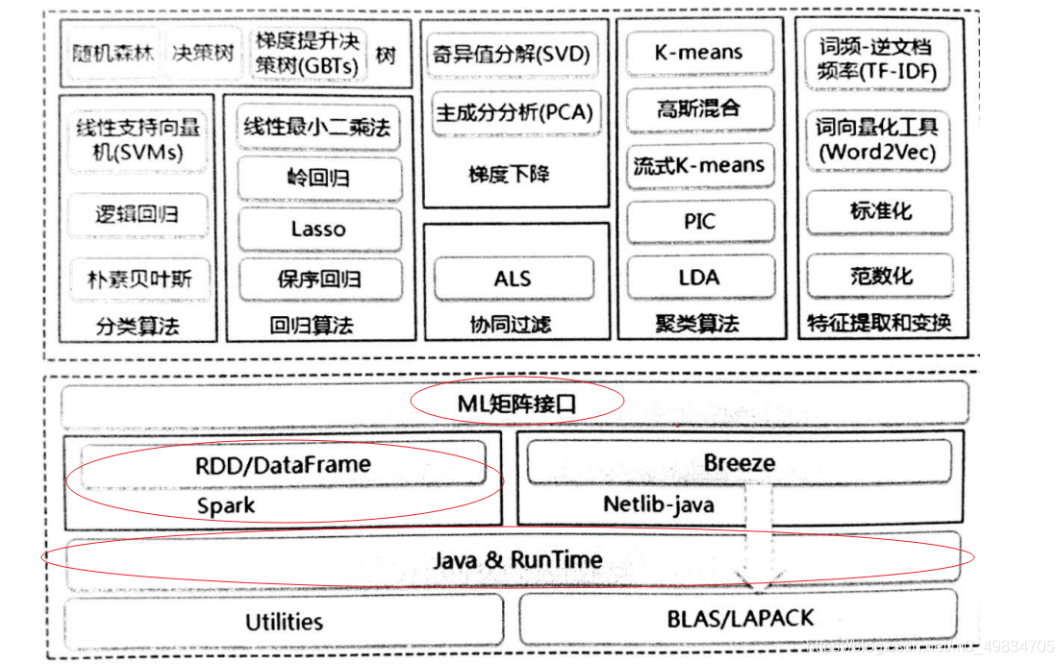
agora está aprendendo o aprendizado de máquina. Precisamos apenas usar a biblioteca de algoritmos existente e colocar mais experiência na cognição, processamento e integração de dados.