1. Cientista de dados
Desde o surgimento do big data , o conceito de ciência de dados também se tornou um tópico quente de discussão no campo de dados. "Cientista de dados" se tornou um cargo e aparece em várias ofertas de emprego. Então, o que exatamente é ciência de dados? Qual é a relação entre Big Data e Data Science? Qual é o papel do big data na ciência de dados? Este artigo tem como objetivo principal desempenhar um papel na ciência popular, para que amigos que estão prestes a ou estão envolvidos no trabalho de dados tenham uma compreensão abrangente do trabalho de ciência de dados e também façam amigos que têm ideias para entrar no campo de big data tenham uma compreensão da situação do setor antes de realmente se envolverem no trabalho de big data. Conhecido. A ciência de dados é uma interdisciplinaridade mista (conforme mostrado na figura abaixo). Para se tornar um cientista de dados completo, você precisa ter bons conhecimentos de matemática e informática , bem como conhecimento em um determinado campo profissional . O trabalho feito gira em torno de dados. Depois que a quantidade de dados explodiu, o big data é considerado um ramo da ciência de dados.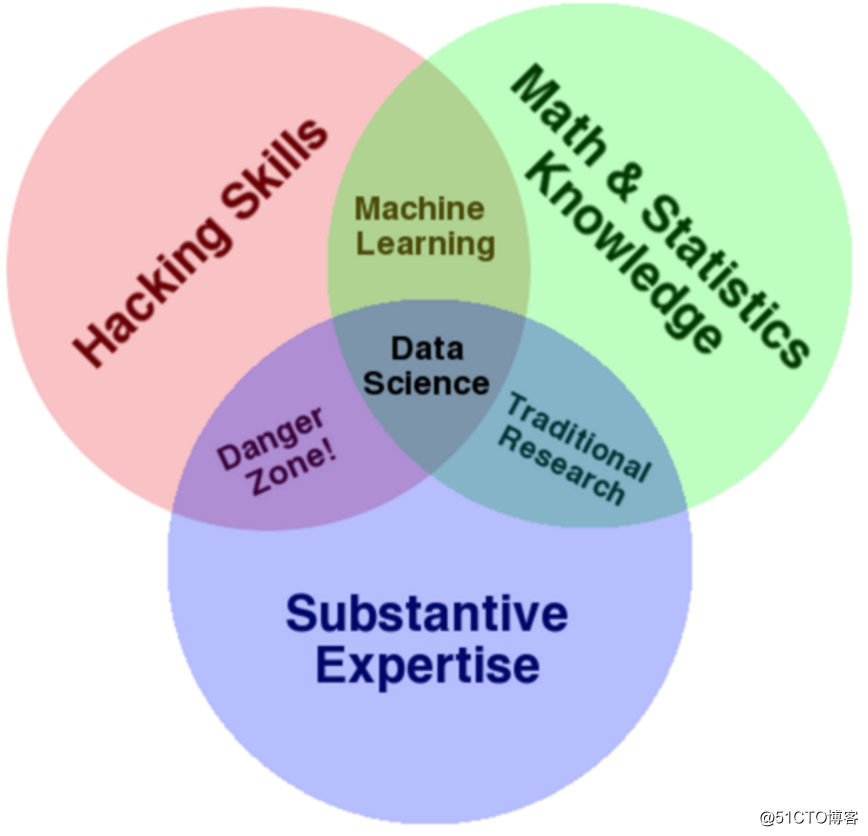
2. Sistema de Big Data
O Big Data já existe há muitos anos, mas com sensores e pontos de armazenamento de dados onipresentes, a aquisição de dados se tornou mais fácil, maior e mais diversa. Como resultado, o campo de dados tradicional original teve que pensar em mudar para uma nova plataforma que pudesse manipular e usar a quantidade crescente de dados. Use os dois pontos a seguir para elaborar mais:
- Um ponto levantado pelo Dr. Wu Jun: Indústria existente + nova tecnologia = nova indústria, big data também está em conformidade com este princípio, mas o que é gerado não é apenas uma nova indústria, mas uma cadeia industrial completa: campo de dados original + novo Tecnologia de big data = cadeia da indústria de big data;
-
O escopo do uso de dados, o aplicativo de dados original é principalmente para amostrar os dados nos dados existentes e, em seguida, fazer mineração e análise de dados para descobrir as regras em potencial nos dados para previsão ou tomada de decisão. No entanto, a amostragem sempre descartará parte dos dados. Ou seja, algumas regras e valores potenciais serão perdidos. À medida que a quantidade de dados e conteúdo continua a se acumular, as empresas estão prestando cada vez mais atenção ao uso de dados completos em aplicativos de dados, cobrindo todas as regras potenciais tanto quanto possível para descobrir o que pode ou nunca pensar o valor de.
Big data é uma cadeia ou pipeline com base no fluxo de dados. De onde vêm os dados e para onde vão não é apenas uma questão filosófica, mas também pode ser considerada durante o trabalho de dados. Conforme mostrado na figura abaixo, o campo de big data pode ser dividido nas seguintes direções principais, e essas direções podem corresponder a alguns cargos:
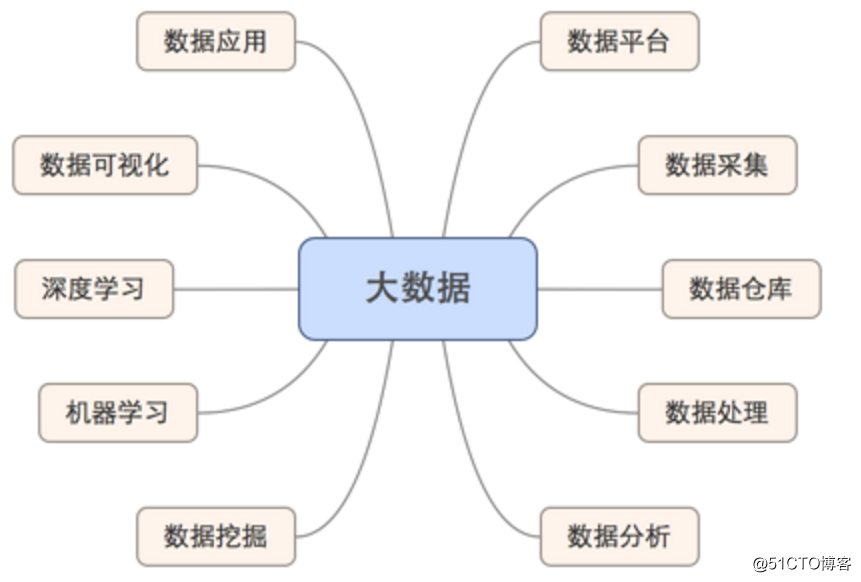
1. Plataforma de dados
Plataforma de dados , construir e manter uma plataforma de big data estável e segura, projetar arquitetura de big data sob demanda, pesquisar e selecionar produtos e soluções de tecnologia de big data, implementar implantação e ficar online. Para a maioria das tecnologias envolvidas no campo de big data, é necessário ter uma compreensão de algumas partes e ter o pensamento e a habilidade de sistemas distribuídos.
Cargos correspondentes: arquiteto de big data, engenheiro de plataforma de dados
2. Coleta de dados
Coleta de dados , obtém dados de canais como Web / Sensor / RDBMS e fornece fontes de dados para plataformas de big data.
Cargos correspondentes: engenheiro rastreador, engenheiro de aquisição de dados
3. Data warehouse
O data warehouse é um pouco semelhante ao conteúdo de trabalho do data warehouse tradicional: projetar a estrutura hierárquica do data warehouse, ETL e modelagem de dados, mas com base em plataformas diferentes. Na era do big data, a maioria dos data warehouses é implementada com base na tecnologia de big data, como o Hive Data warehouse baseado em Hadoop.
Cargos correspondentes: engenheiro ETL, engenheiro de data warehouse
4. Processamento de dados
O processamento de dados , para concluir o processamento ou limpeza de dados em alguns requisitos específicos, é combinado com o data warehouse em uma pequena equipe. No passado, o ETL pode ser usado para configurar e processar diretamente alguns itens de filtro com ferramentas, e a parte do código será menor. Hoje em dia, o processamento de dados na plataforma de big data pode usar mais métodos de código para fazer um processamento mais diversificado e as tecnologias necessárias são Hive, Hadoop, Spark, etc. Não subestime o processamento de dados. A análise de dados subsequente e a mineração de dados são baseadas na qualidade do processamento de dados. Pode-se dizer que o processamento de dados tem uma posição particularmente importante em todo o processo.
Cargos correspondentes: engenheiro Hadoop, engenheiro Spark
5. Análise de dados
Análise de dados , com base em métodos de análise estatística para análise de dados: como análise de regressão, análise de variância, análise de correlação, etc. As tecnologias de análise de big data, como análise interativa Ad-Hoc e SQL no Hadoop, incluem: Hive, Impala, Presto, Spark SQL e tecnologias que oferecem suporte a OLAP: Kylin.
Posição correspondente: analista de dados
6. Mineração de dados
Data Mining é um conceito relativamente amplo, que pode ser entendido diretamente como a localização de informações úteis em uma grande quantidade de dados. A mineração de dados em big data é principalmente para projetar e implementar algoritmos de mineração de dados em plataformas de big data: algoritmos de classificação, algoritmos de agrupamento, análise de associação, etc.
Posição correspondente: engenheiro de mineração de dados
7. Aprendizado de máquina
O aprendizado de máquina e a mineração de dados costumam ser discutidos juntos e até considerados a mesma coisa. O aprendizado de máquina é um assunto interdisciplinar de computação e estatística. O objetivo básico é aprender uma função (mapeamento) de x-> y para classificação ou regressão. A razão pela qual muitas vezes é combinada com mineração de dados é porque muito trabalho de mineração de dados agora é realizado por meio de ferramentas de algoritmo fornecidas pelo aprendizado de máquina, como recomendação personalizada, que analisa várias compras na plataforma por meio de alguns algoritmos de aprendizado de máquina, navegar E o log de coleta, obtenha um modelo de recomendação para prever os produtos que você gosta.
Cargo correspondente: engenheiro de algoritmo, pesquisador
8. Aprendizagem profunda
Aprendizado profundo é um tópico (tópico muito popular) em aprendizado de máquina. A partir do conteúdo do aprendizado profundo, é um derivado de algoritmos de rede neural. Alcançou resultados muito bons na classificação e reconhecimento de imagens, fala, linguagem natural, etc. Efetivamente, a maior parte do trabalho está nos parâmetros de ajuste.
Cargo correspondente: engenheiro de algoritmo, pesquisador
9. Visualização de dados
Data Visualization , exibe os dados de alto valor após a análise e mineração de uma forma mais bonita e flexível na frente de chefes, clientes e usuários. É mais de algumas coisas de front-end. Talvez um certo conhecimento estético seja necessário. Combinando as preferências do usuário, apresente o valor dos dados da maneira mais adequada.
Cargos correspondentes: engenheiro de dados, engenheiro de BI
10. Aplicação de dados
Aplicativo de dados , aplicativos que podem ser derivados de cada um dos itens acima, como publicidade precisa, recomendações personalizadas, retratos de usuários, etc.
Cargo correspondente: engenheiro de dados