# 大 数据 之 电 商 推荐 系统 #
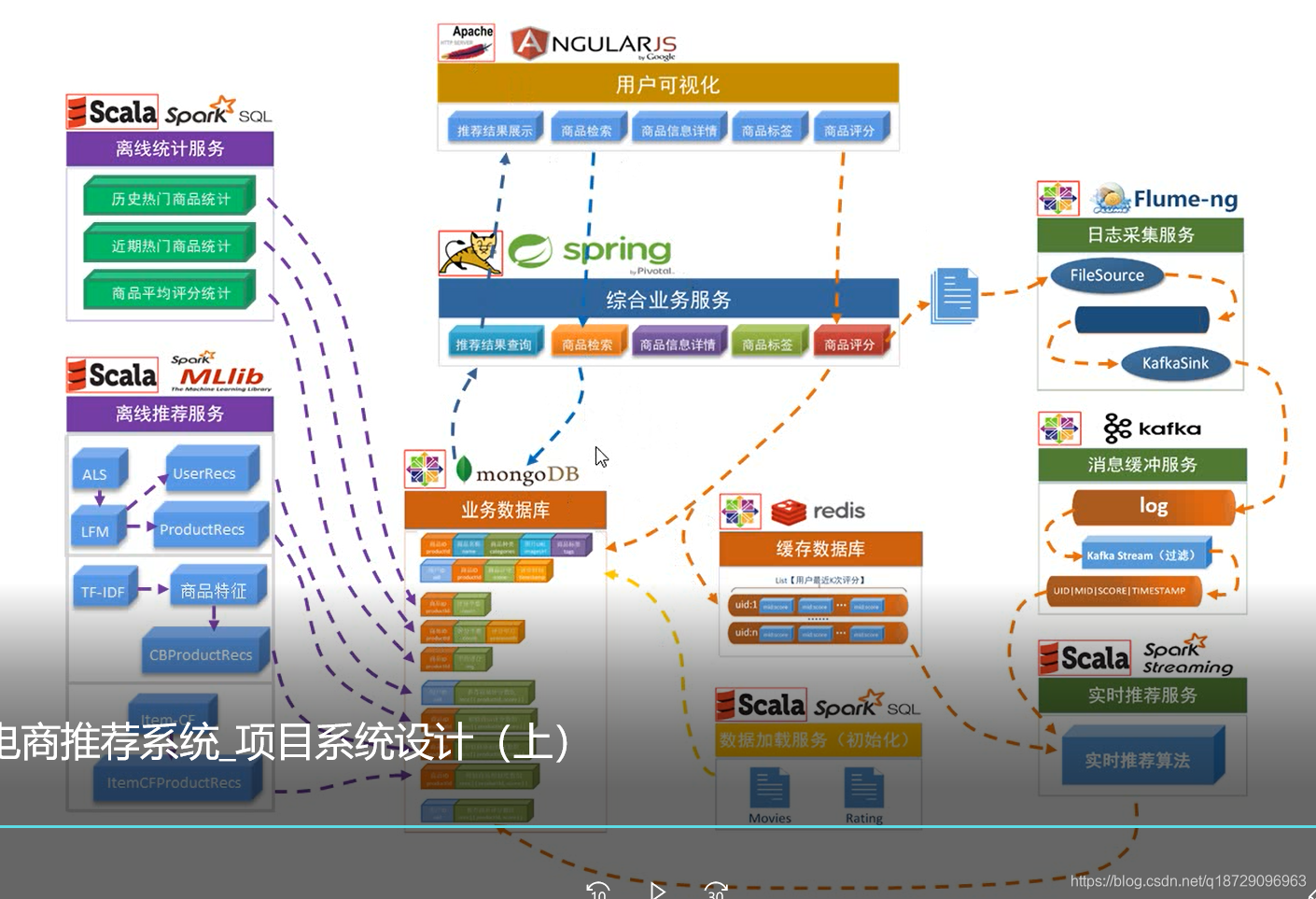
Arquitetura do sistema de projeto

Coleta de dados
- Dados de commodities
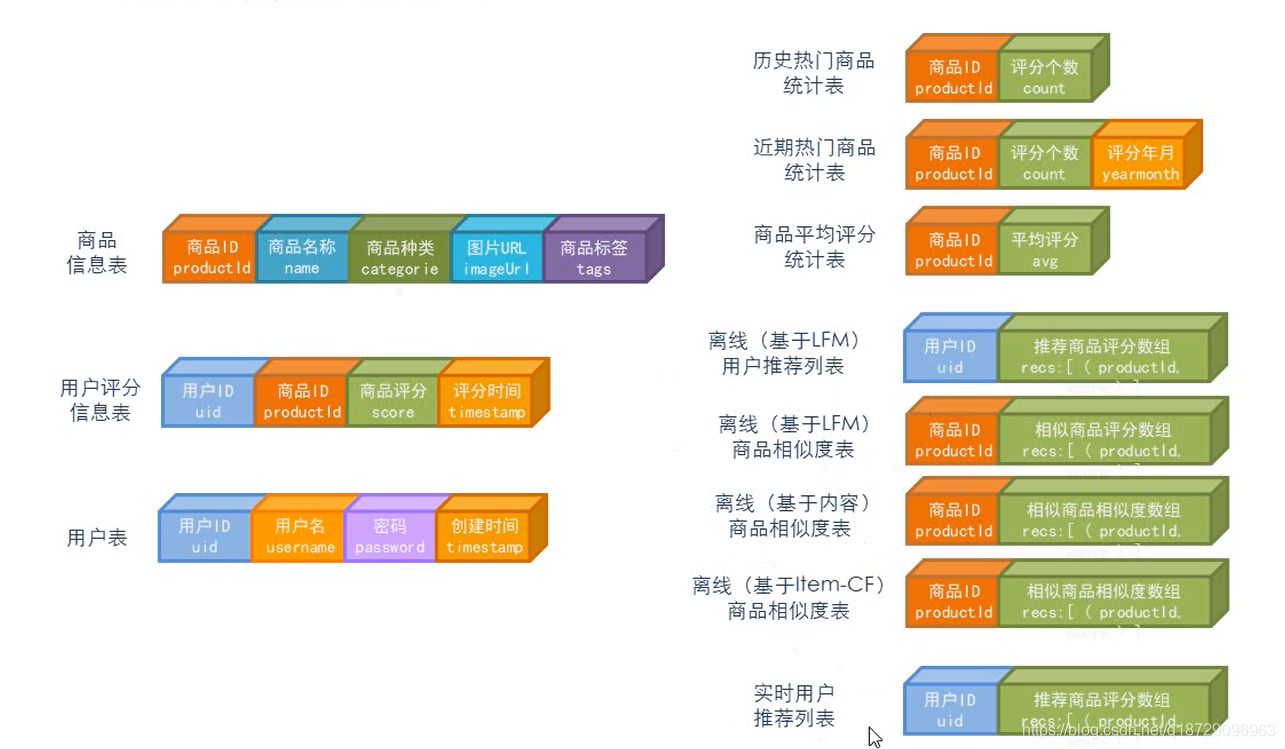
| ID da mercadoria | Nome do Produto | Tipos de bens | URL da imagem do produto | Etiqueta de mercadoria |
|---|---|---|---|---|
| ID do produto | nome | categorias | imagem URL | Tag |
- Dados de pontuação
| ID do usuário | ID da mercadoria | Classificação da mercadoria | Tempo de pontuação |
|---|---|---|---|
| uid | ID do produto | pontuação | carimbo de data / hora |
Design da estrutura da mesa
Análise estatística offline
-
Recomendações históricas de produtos importantes - o produto com mais classificações históricas
SQL: select product_id, count(product_id) as count from ratings group by product_id order by count desc 存储表:rate_more_product 字段:product_id rate_count -
Produtos populares recentes - conte os produtos que foram avaliados com mais frequência pelos usuários no último mês
原则: 先创建一个UDF 将评分时间转换为yyyyMM形式的 SimpleDateFormat 时间格式化 然后对时间进行分组统计 存储表:rate_more_recently_product 字段:product_id rate_count yearmonth -
Estatísticas de classificação média de commodities
select product_id,avg(score) as avg_score from ratings group by product_idorder by avg_score desc 存储表:rate_avg_product 字段: product_id avg_score
ALS de recomendação personalizada offline
1. 使用ALS模型对评分数据进行训练
val model = ALS.train(data, rank, iterations, lambda)
搞出最优模型
2. 用户userRDD 与 商品productRDD 做笛卡尔积 求出 userId,productId的RDD
3. model.predict() 预测出一个评分矩阵
4. 以userId groupByKey 以 score 排序后 取TopN
注: 此处附加求出 商品的相似度矩阵
1. model.productFeatures 求出商品的特征向量矩阵
2. 笛卡儿积求出II矩阵 求余玄相似度
3. 过滤出相似度大于0.6的 进行groupByKey
Recomendação em tempo real
特点:
1. 计算速度快
2. 预测结果可以不是特别精确
3. 预先算出商品相似度,有预先准备好的预测模型
原理:
1. 用户最近一段时间的口味应该是相似的
误区:
1. 评分了一个物品 即做相似推荐 --- 单个物品不能反映该用户的喜好
2. 做了差评 --- 推荐毫无意义
正确姿势:
拿出最近一段时间的用户评分数据 综合考虑评分分值和相似度
projeto de algoritmo:
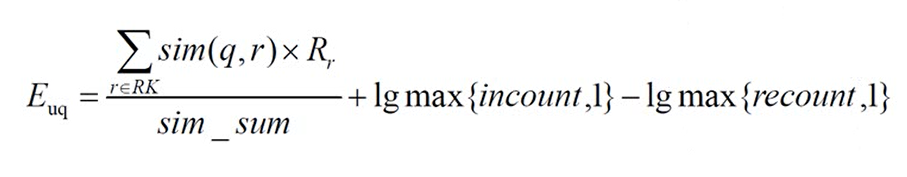
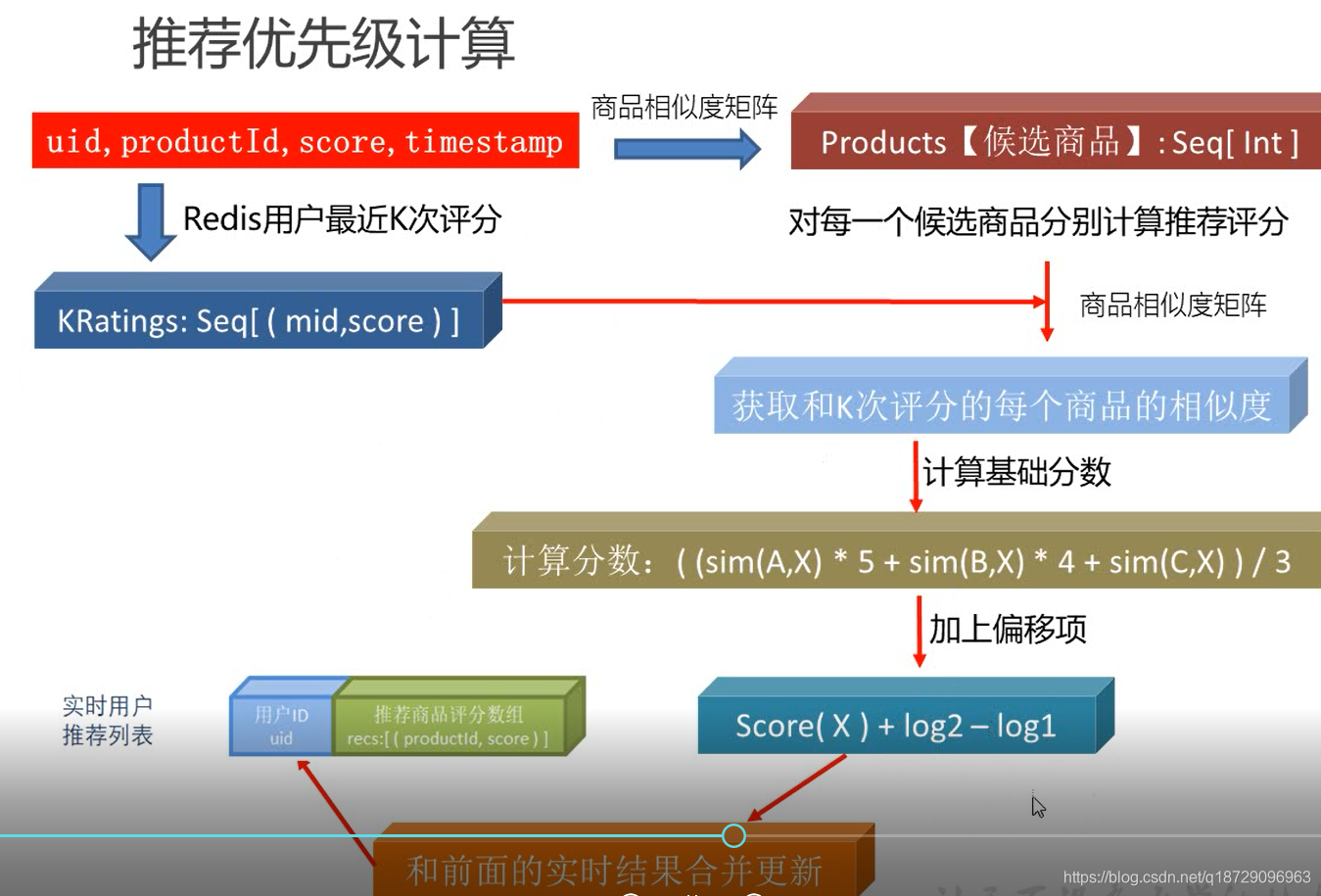
举例:用户最近的K次评分数据为
| ID do usuário | ID da mercadoria | pontuação |
|---|---|---|
| u1 | UMA | 5 |
| u1 | B | 4 |
| u1 | C | 4 |
| u1 | D | 2 |
对于商品X的推荐优先级得分公式:
最终得分 = (sim(X,A) * 5 + sim(X,B) * 4 + sim(X,C) * 4 + sim(X,D) * 2) / 4 + lgmax{incount,1} - lgmax{recount,1}
其中,incount为K次评分中大于3分的次数
recount为K次评分中小于3分的次数
注:此处即为 高分多 加奖励 低分多 做惩罚
Outras formas de recomendação offline
1. 内容推荐 TF-IDF
商品Tags 分词得到特征向量 进行相似度 求解
注: 喜欢了该物品的用户 应该也喜欢 下面这些
您有可能也喜欢下面这些物品
注: 一般在 商品详情页 商品购买页 做推荐
2. 被相似的人喜欢的物品推荐
即 喜欢的人重合度越高 相似度越高
“同现相似度”
同时购买了 两个物品的 的人 的个数
除以
购买两个物品的总人数的
