1. Escreva no início
O serviço de nuvem vivo fornece aos usuários a capacidade de fazer backup de dados como contatos, mensagens de texto, notas e marcadores em seus telefones celulares.O armazenamento subjacente usa banco de dados MySQL para armazenamento de dados.
Com o desenvolvimento do negócio de serviços em nuvem da vivo, o número de usuários de serviços em nuvem cresceu rapidamente e a quantidade de dados armazenados na nuvem aumentou. Dados massivos trouxeram enormes desafios para o armazenamento de back-end. O maior ponto problemático do negócio de serviços em nuvem nos últimos anos é como resolver o problema de armazenamento de dados massivos dos usuários.
2. Enfrentando desafios
De 2017 a 2018, os principais indicadores de produtos de serviço em nuvem se concentraram em aumentar o número de usuários. O serviço em nuvem fez grandes ajustes na estratégia do produto. Depois que os usuários fazem login na conta da vivo, o interruptor de sincronização de dados do serviço em nuvem é ativado por padrão.
Essa estratégia de produto trouxe um crescimento explosivo para o número de usuários de serviços em nuvem. O número de usuários saltou diretamente de um milhão para dezenas de milhões, e a quantidade de dados de armazenamento de back-end também saltou de dezenas de bilhões para centenas de bilhões.
Para resolver o problema de armazenamento massivo de dados, o serviço de nuvem implementou as quatro estratégias de subtabela de sub-banco de dados: subtabela horizontal, subtabela vertical, sub-banco de dados horizontal e sub-banco de dados vertical.
1. Tabela de pontuação de nível
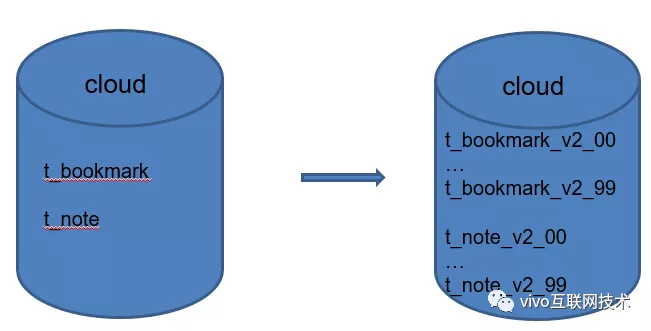
Path of Thorns 1: O que devo fazer se a quantidade de dados em uma única tabela for superior a 100 milhões nos favoritos do navegador, biblioteca de lista de memorandos e tabela única?
Acredito que os irmãos que entendem do sistema de conhecimento de sub-banco de dados e subtabela em breve saberão responder: Se a quantidade de dados em uma única tabela for muito grande, a tabela será dividida. Fizemos o mesmo, dividimos a única tabela de favoritos do navegador e módulos de memorando em 100 tabelas.
Migre o volume de dados de nível de bilhão de marcadores de navegador e folhas de anotações para 100 subtabelas, cada uma com um volume de dados de 1000W .
Este é o primeiro ataque com o qual todos estão familiarizados: a tabela de pontuação de nível .
2. Sub-biblioteca horizontal
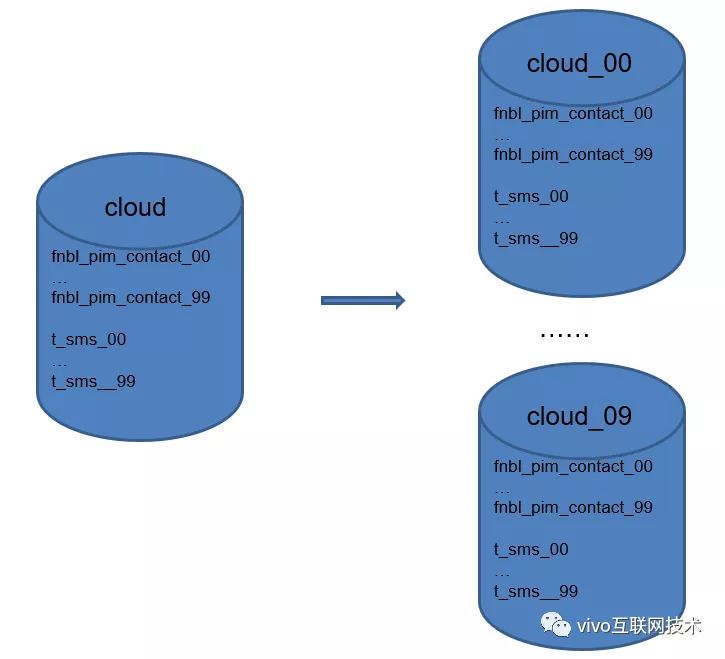
Caminho de Thorns 2: Os dados de contato e SMS foram divididos em tabelas, mas inicialmente apenas 50 tabelas foram divididas, e nenhum banco de dados foi dividido. Após o crescimento explosivo do número de usuários, a quantidade total de dados de contato em um único banco de dados atingiu vários bilhões, e a quantidade de dados em uma única tabela atingiu 5.000 W. O crescimento contínuo afetará seriamente o desempenho do mysql. O que devo fazer?
O segundo truque é dividir a biblioteca horizontalmente : se uma biblioteca não puder suportá-la, divida -a em várias outras bibliotecas. Nós dividir o banco de dados único original em 10 bases de dados , e expandiu o banco de dados único original de 50 mesas de contatos e mensagens de texto para 100 mesas. Durante o mesmo período, a migração e reencaminhamento de bilhões de dados armazenados foi muito doloroso.
3. Sub-biblioteca vertical, subtabela vertical
Path of Thorns 3: Inicialmente, o armazenamento de dados de cada módulo do serviço em nuvem são todos misturados.
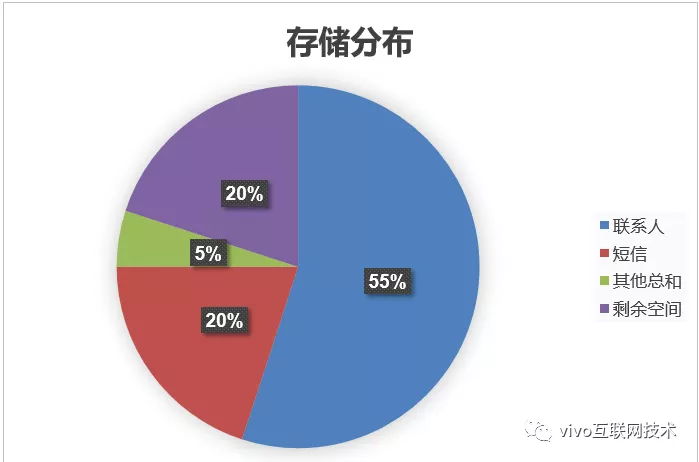
Quando há um gargalo no espaço, analisamos a distribuição do espaço de armazenamento dos dados de cada módulo, e a situação é a seguinte:
A capacidade do disco da biblioteca única é 5T , os dados de contato ocupam 2,75T (55%) de espaço de armazenamento , os dados SMS ocupam 1T (20%) de espaço de armazenamento , todos os outros dados do módulo ocupam um total de 500G (5%) de espaço de armazenamento e o espaço livre restante é 1T . Dados de pessoas e SMS ocupam 75% do espaço total .
O 1T restante de capacidade de espaço não pode suportar o crescimento contínuo de dados do usuário e a situação não é otimista. Se não houver espaço suficiente, todos os módulos ficarão indisponíveis devido a problemas de espaço. O que devo fazer?
(A figura abaixo mostra a distribuição do espaço de armazenamento de dados para serviços em nuvem naquele momento)
O terceiro e quarto eixos, sub-banco de dados vertical e subtabela vertical: Nós armazenamos e desacoplamos dados de contato, dados de SMS e outros dados de módulo. Separe dados de contato e dados de SMS em bibliotecas.
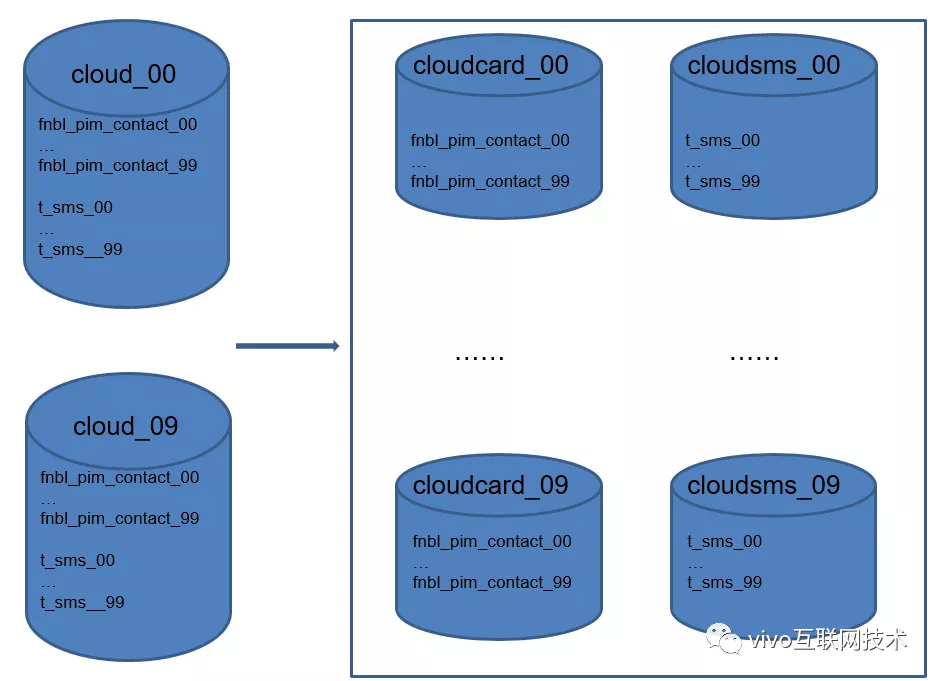
Neste ponto, o serviço em nuvem praticou todos os quatro truques do sub-banco de dados e subtabelas. Os dados devem ser divididos e os pontos devem ser divididos.
4. Esquema de expansão dinâmica com base na tabela de roteamento
Path of Thorns 4: A partir da descrição acima, sabe-se que o banco de dados de contato dividido adota uma estratégia fixa de sub-banco de dados de 10 bancos de dados. A avaliação preliminar de 10 bancos de dados * 100 tabelas pode atender às necessidades de crescimento de dados de negócios. Achei que poderia sentar e relaxar, mas A taxa de crescimento dos dados de contato superou as expectativas.
Nove meses depois que o banco de dados de contatos foi dividido separadamente , o espaço de armazenamento de um único banco de dados aumentou de 35% para 65% . De acordo com essa taxa de crescimento, após mais 6 meses de suporte, o banco de dados de contatos dividido de forma independente enfrentará novamente o problema de espaço insuficiente.
Como resolver? A expansão contínua é afirmativa, e o ponto central é a estratégia de expansão adotada. Se adotarmos o plano de expansão convencional, enfrentaremos o problema de migração e redirecionamento de dados de estoque massivos, que são muito caros.
Após a comunicação e discussão pelo grupo técnico, combinado com as características do negócio de contato de serviço em nuvem (o número de contatos para usuários antigos é basicamente estável e um grande número de contatos não é adicionado com frequência e a taxa de crescimento de dados de contato para usuários antigos é controlável), Finalmente, adotamos um esquema de expansão dinâmica baseado na tabela de roteamento.
O seguinte descreve os recursos deste programa:
- Adicione uma tabela de roteamento de usuário para registrar para qual banco de dados e tabela os dados de contato do usuário são roteados;
- Os dados de contato do novo usuário serão roteados para o banco de dados recém-expandido, o que não causará pressão de armazenamento de dados no antigo banco de dados original.
- Os dados do usuário antigo não serão movidos e ainda são armazenados no banco de dados original.
- O recurso dessa solução é garantir que o antigo banco de dados original precise apenas garantir o crescimento dos dados de usuários antigos e todos os novos usuários sejam transportados pelo banco de dados recém-expandido.
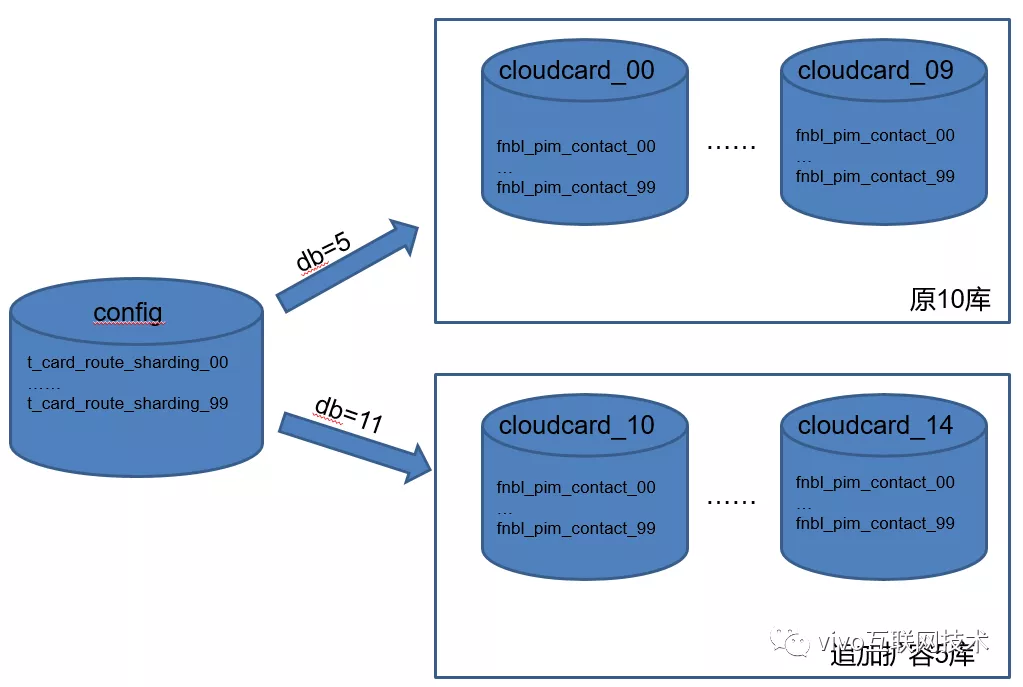
Embora a taxa de crescimento de contatos de usuários antigos seja controlável, esperamos que a biblioteca original possa reservar 60% do espaço de armazenamento para suportar o crescimento de dados de usuários antigos. Atualmente, restam apenas 35% do espaço disponível na antiga biblioteca, o que não atende aos nossos requisitos.
Para reduzir o espaço de armazenamento ocupado por dados de bancos de dados antigos, pensamos naturalmente em começar pelo nível de compactação de dados .
3. Pré-pesquisa sobre esquema de compressão
O serviço em nuvem realizou uma pré-pesquisa nas 3 soluções a seguir para compactação de dados de banco de dados:
Esquema 1: o programa implementa a compactação de dados por si só e os salva no banco de dados após a compactação
Vantagem:
Não há necessidade de modificar o banco de dados, a modificação é totalmente convergente pelo próprio programa e os campos que precisam ser compactados podem ser controlados livremente.
Desvantagens:
Os dados existentes precisam desenvolver tarefas de compactação adicionais para compactação de dados e a quantidade de dados existentes é muito grande, e a compactação de dados por programas é demorada e incontrolável.
Depois que os dados são compactados e armazenados no banco de dados, o conteúdo do campo de consulta selecionado que precisa ser executado diretamente a partir da plataforma db não é mais legível, o que aumenta a dificuldade de problemas de localização subsequentes.
Opção 2: banco de dados MySQL InnoDB vem com recursos de compressão de dados
Vantagem:
Use os recursos existentes do InnoDB para compactação de dados, sem nenhuma modificação no programa de nível superior, e não afeta as consultas de dados selecionadas subsequentes.
Desvantagens:
É adequado para cenários de negócios com uma grande quantidade de dados e menos leituras e gravações, e não é adequado para negócios que exigem alto desempenho de consulta.
Solução 3: mude o mecanismo de armazenamento InnoDB para TokuDB e use os recursos naturais de compressão de dados do mecanismo TokuDB
Vantagem:
O TokuDB suporta naturalmente a compactação de dados e vários algoritmos de compactação, oferece suporte a cenários de gravação de dados frequentes e tem vantagens naturais para grande armazenamento de dados.
Desvantagens:
O MySQL precisa instalar plug-ins adicionais para suportar o mecanismo TokuDB, e a empresa atualmente não tem negócios com experiência em TokuDB madura, o risco após o acesso é desconhecido e a manutenção subsequente do DBA também é um desafio.
Após uma consideração abrangente, finalmente decidimos adotar o segundo esquema de compactação: os próprios recursos de compactação do InnoDB .
Os principais motivos são os seguintes:
- Operação simples: altere o formato do arquivo da tabela de dados innodb existente por dba para compactar os dados;
- Velocidade de compressão controlável: após o teste, uma tabela de dados de 2.000 W pode ser usada para comprimir a tabela inteira em 1-2 dias;
- Baixo custo de transformação: todo o processo de transformação requer apenas dba para executar o SQL relacionado, alterar o formato do arquivo da tabela de dados e não precisar fazer nenhuma alteração no código do programa superior;
- Mais adequado para cenários de negócios de serviço em nuvem: o backup e a recuperação de dados do usuário não são cenários de negócios de alto desempenho e QPS alto, e as tabelas de dados de serviço em nuvem estão em conformidade com as características de um grande número de campos de string, que são muito adequados para compactação de dados.
Quarto, a verificação do esquema de compressão
1. Introdução aos recursos de compressão InnoDB
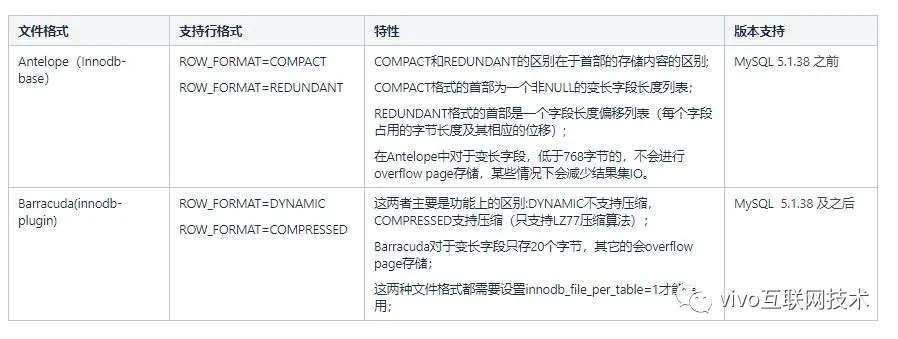
Antes da versão 5.1.38 do MySQL, havia apenas o mecanismo de armazenamento de base innodb. O formato de arquivo padrão é Antelope. Este formato de arquivo suporta dois formatos de linha (ROW_FORMAT): COMPACT e REDUNDANT, nenhum dos quais são formatos de linha do tipo de compactação de dados.
Após o MySQL 5.1.38, o innodb-plugin foi introduzido e o formato de arquivo do tipo Barracude também foi introduzido. Barracude é totalmente compatível com o formato de arquivo do Antelope e suporta os outros dois formatos de linha DYNAMIC e COMPRESSED (suporta compressão de dados).
2. Preparação do ambiente de compressão
Modifique a configuração do banco de dados: mude o formato do arquivo do banco de dados, o padrão é Antelope, modificado para Barracuda
SET GLOBAL innodb_file_format = Barracuda;
SET GLOBAL innodb_file_format_max = Barracuda;
SET GLOBAL innodb_file_per_table = 1
Nota: innodb_file_per_table deve ser definido como 1. O motivo é que o espaço de tabela do sistema InnoDB não pode ser compactado. O espaço de tabela do sistema não contém apenas dados do usuário, mas também contém informações internas do sistema do InnoDB, que nunca podem ser compactadas, portanto, diferentes espaços de tabela para tabelas diferentes precisam ser configurados para suportar compactação.
Depois de definir OK, você pode executar SHOW GLOBAL VARIABLES LIKE '% file_format%' e SHOW GLOBAL VARIABLES LIKE '% file_per%' para confirmar se a modificação tem efeito.
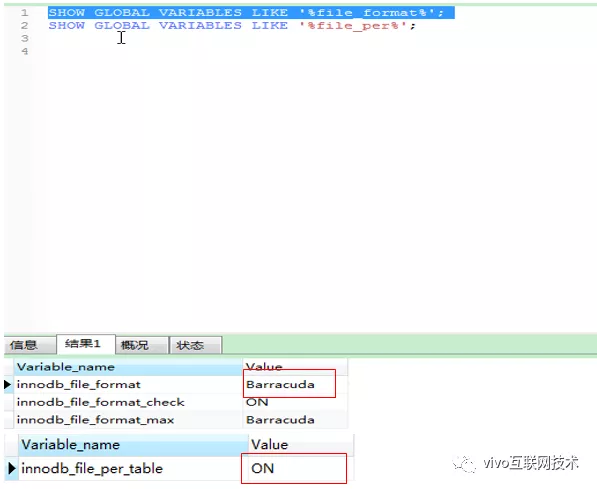
(Esta configuração só é efetiva para a sessão atual e se tornará inválida depois que a instância do mysql for reiniciada. Se você precisar entrar em vigor permanentemente, configure-o no arquivo de configuração global do mysql)
3. Teste de verificação do efeito de compressão
Prepare uma tabela de dados que suporte o formato de compactação e uma tabela de dados que não suporte a compactação. Os formatos dos campos são todos iguais.
Tabela de compressão:

Descrição: row_format = compressed, o formato de linha especificado é compactado. Key_block_size recomendado = 8. O padrão de key_block_size é 16. Os valores opcionais 16, 8, 4 representam o tamanho da página de dados InnoDB.Quanto menor o valor, maior a compactação. Com base na consideração abrangente da CPU e da taxa de compactação, a configuração online recomendada é 8.
Tabela não comprimida:
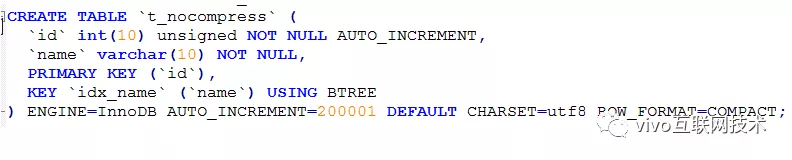
Prepare os dados: Use um procedimento armazenado para inserir pedaços de 10 W dos mesmos dados na tabela t_nocompress e na tabela t_compress ao mesmo tempo. O espaço ocupado pelas 2 mesas é o seguinte:
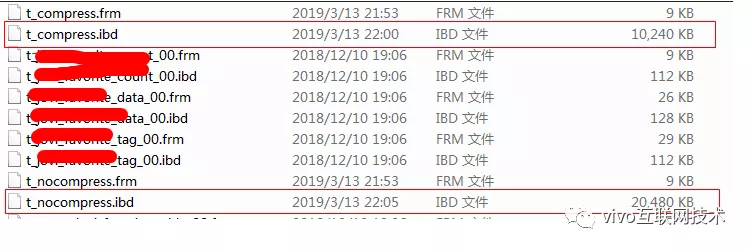
Os dados da tabela t_compress ocupam 10M, os dados da tabela t_nocompress ocupam 20M e a taxa de compressão é de 50%.
Observação: o efeito de compactação depende do tipo de campo da tabela. Os dados típicos geralmente têm valores repetidos, portanto, podem ser compactados com eficácia. CHAR, VARCHAR, TEXT, BLOB, etc.
Os dados da string geralmente podem ser bem compactados. No entanto, dados binários (números inteiros ou de ponto flutuante) e dados compactados (imagens JPEG ou PNG) geralmente não conseguem compactação.
Cinco, prática online
A partir da verificação do teste acima, se a taxa de compressão pode chegar a 50%, o espaço ocupado pelo banco de dados de contatos será comprimido de 65% a 33%, e 60% do espaço restante pode ser alcançado.
Mas precisamos estar atentos aos dados online. Antes da prática online, precisamos verificar o plano offline. Ao mesmo tempo, também precisamos considerar as seguintes questões:
1. A compactação e descompactação de dados afetam o desempenho do servidor db?
Usamos o teste de estresse de desempenho para avaliar o impacto na CPU do servidor de banco de dados antes e depois da compactação. A seguir está o gráfico de comparação da CPU do servidor db antes e depois da compressão:
Sob a premissa de que o volume de dados da lista de contatos já é de 2.000 W, os dados são inseridos nesta tabela.
Antes da compressão: Insira 50 contatos por vez, com 200 simultâneos, 10 minutos, TPS 150, CPU 33%
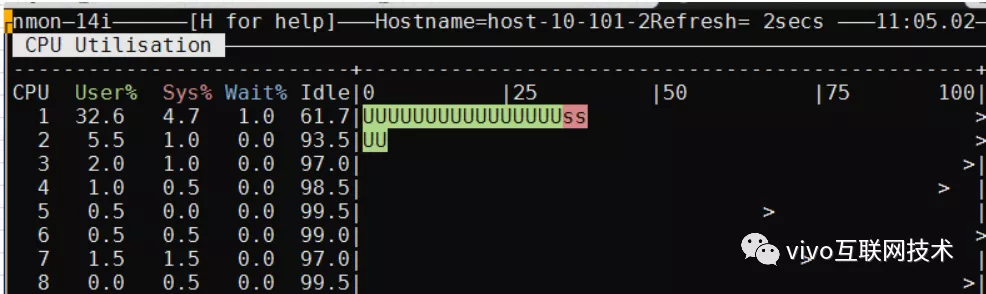
Após a compressão: insira 50 contatos por vez, com 200 simultâneos, 10 minutos, TPS 140, CPU 43%
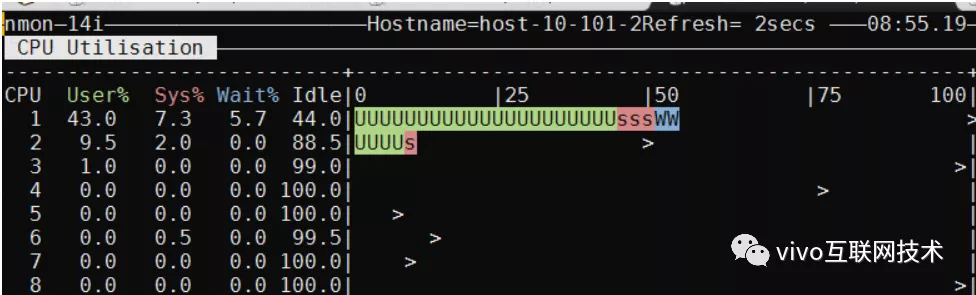
Depois que a tabela de dados é compactada, a CPU da inserção frequente de dados no banco de dados realmente aumenta, mas o TPS não é muito afetado. Após repetidos testes de estresse, a CPU do servidor de banco de dados fica basicamente estável em cerca de 40%, o que é aceitável para os negócios.
2. A alteração do formato do arquivo da tabela de dados afetará a leitura e gravação do SQL de negócios e afetará as funções normais de negócios?
Fizemos principalmente verificação offline e verificação online :
Verificação offline: O ambiente de teste ajustou todas as tabelas de dados de contato para um formato compactado, organizado por um engenheiro de teste para auxiliar na verificação de todas as funções do contato, e as funções finais estavam todas normais.
O ambiente de pré-lançamento segue as etapas do ambiente de teste novamente e não há nenhuma anormalidade na verificação de função.
Verificação online: Selecione a tabela de dados do módulo de registro de chamadas que não é sensível aos usuários para compactar, opte por compactar 1 tabela em 1 biblioteca, preste atenção à situação de leitura e gravação de dados dessa tabela e preste atenção às reclamações dos usuários.
Após 1 semana de observação contínua, os dados de registro de chamadas deste relógio podem ser lidos e gravados normalmente, e nenhum feedback anormal de qualquer usuário foi recebido durante este período.
3. A quantidade de dados de contato online é enorme, como garantir a estabilidade do serviço durante a compressão?
Principalmente fazemos trocas de acordo com as seguintes idéias:
- Selecione uma tabela de dados de contato para compactar e avalie o tempo gasto em uma única tabela.
- Selecione um único banco de dados, execute a compactação simultânea de várias tabelas e observe o uso da CPU. O DBA pondera que o valor máximo da CPU não pode exceder 55% e ajusta gradualmente o número de compressões simultâneas com base neste padrão para garantir que a CPU esteja estável em cerca de 55% e, finalmente, obter o número máximo de tabelas suportadas por um único banco de dados para compactação ao mesmo tempo.
- Combinando a primeira e a segunda etapas, podemos calcular o tempo aproximado que leva para compactar todas as tabelas de dados de todas as bibliotecas.Após sincronizar com a equipe do projeto e responsáveis, siga as etapas para implementar o trabalho de compactação.
O efeito da compactação de dados no banco de dados de contatos online final é o seguinte:

Seis, escreva no final
Este artigo apresenta os desafios trazidos pelos serviços em nuvem com o desenvolvimento de negócios e armazenamento massivo de dados, bem como alguma experiência de serviços em nuvem em subtabela de banco de dados, compressão de dados de banco de dados, na esperança de fornecer referência.
A compactação de dados InnoDB é adequada para os seguintes cenários:
Empresas com grande quantidade de dados de negócios e pressão de espaço em discos de banco de dados;
É adequado para cenários de negócios que leem mais e gravam menos e não é adequado para empresas que têm altos requisitos de desempenho e QPS;
- É adequado para um grande número de dados do tipo string na estrutura da tabela de dados de negócios.Este tipo de tabela de dados pode geralmente ser compactado de forma eficaz.
Finalmente:
Ao selecionar bancos de dados e tabelas para negócios, é necessário estimar completamente o crescimento do volume de dados.O trabalho de migração de dados trazido pela expansão subsequente do banco de dados vai doer os ossos.
- Fique admirado com os dados online e a solução deve ser aplicada online apenas após repetidas verificações offline.
Autor: plataforma vivo para equipes de desenvolvimento de produtos