Prefácio:
Com relação ao paradigma de banco de dados, já ouvi falar muitas vezes, mas nunca o entendi em detalhes. Livros gerais de banco de dados ou cursos de banco de dados apresentarão conteúdo relacionado a paradigmas, e os paradigmas freqüentemente aparecem em questões de exames de banco de dados. Não está claro se você tem uma compreensão mais clara do paradigma? Neste artigo, vamos aprender o paradigma do banco de dados juntos.
1. Introdução ao paradigma de banco de dados
Para construir um banco de dados com menos redundância e uma estrutura razoável, certas regras devem ser seguidas ao projetar o banco de dados. Em bancos de dados relacionais, essas regras são chamadas de paradigmas. Um paradigma é um resumo que atende a um determinado requisito de design. Para projetar um banco de dados relacional com uma estrutura razoável, um certo paradigma deve ser satisfeito.
O nome em inglês do paradigma é Normal Form, ou NF para breve. Ele foi resumido depois que o EFCodd britânico propôs o modelo de banco de dados relacional na década de 1970. O paradigma é a base da teoria do banco de dados relacional e também as regras e métodos de orientação que devemos seguir no processo de projeto da estrutura do banco de dados.
Existem atualmente seis paradigmas comuns para bancos de dados relacionais: Primeira Forma Normal (1NF), Segunda Forma Normal (2NF), Terceira Forma Normal (3NF), Forma Normal de Cordão de Banho (BCNF), Quarta Forma Normal (4NF) e Quinta Forma Normal Paradigma (5NF, também conhecido como paradigma perfeito). O paradigma que atende aos requisitos mínimos é a primeira forma normal (1NF). Com base na primeira forma normal, aquela que mais satisfaz mais especificações é chamada de segunda forma normal (2NF), e o resto da forma normal pode ser deduzido por analogia.
2. Explicação detalhada de paradigmas comuns
Ao projetar um banco de dados, ele se referirá aos requisitos do paradigma, mas não significa que quanto mais alto o nível do paradigma, melhor. Embora o paradigma seja muito alto, embora tenha melhores restrições no relacionamento de dados, ele também levará a mais relacionamentos entre as tabelas. É complicado, resultando em mais tabelas por operação e menor desempenho do banco de dados. Geralmente, no design de banco de dados relacional, o mais alto é BCNF, que geralmente é 3NF. Ou seja, em circunstâncias normais, usamos os três primeiros paradigmas é o suficiente. Vamos examinar mais de perto os três primeiros paradigmas comumente usados.
Primeira forma normal (1NF)
O primeiro paradigma é o paradigma mais básico. Se todos os valores de campo na tabela do banco de dados forem valores atômicos não decomponíveis, isso significa que a tabela do banco de dados satisfaz a primeira forma normal. Simplesmente falando, o primeiro paradigma é que os dados em cada linha são indivisíveis e não pode haver vários valores na mesma coluna.Se houver atributos duplicados, uma nova entidade precisa ser definida.
Exemplo: suponha que uma empresa deseja armazenar os nomes e detalhes de contato de seus funcionários. Ele cria uma tabela da seguinte maneira:
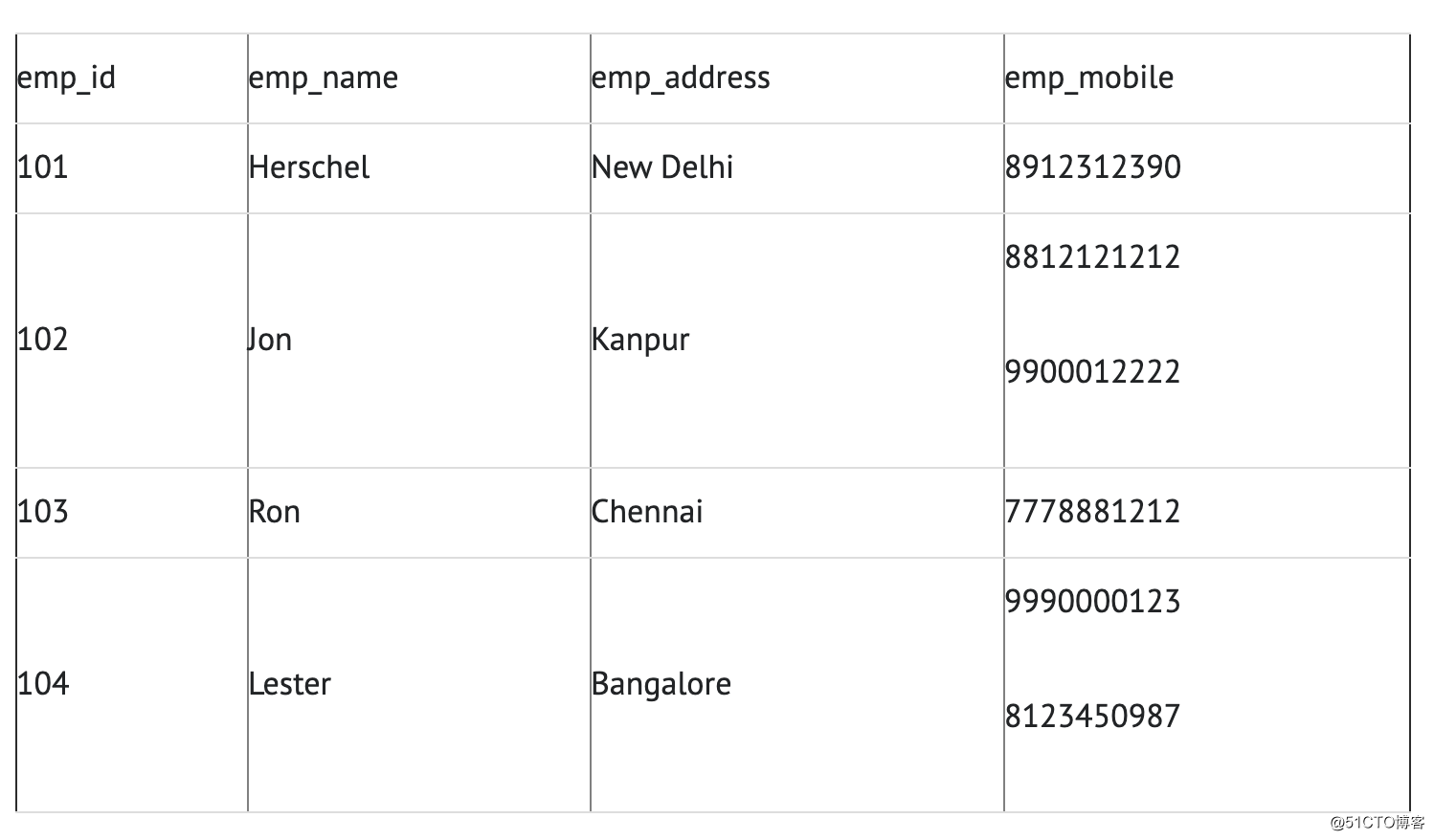
Dois funcionários (Jon & Lester) possuem dois números de telefone celular, portanto a empresa os armazena na mesma tabela, conforme mostrado na tabela acima. Então, a tabela não está em conformidade com 1NF porque a regra diz "cada atributo da tabela deve ter um valor atômico (único)", e o valor emp_mobile dos funcionários Jon & Lester viola essa regra. Para que a tabela esteja em conformidade com 1NF, devemos ter os seguintes dados de tabela:
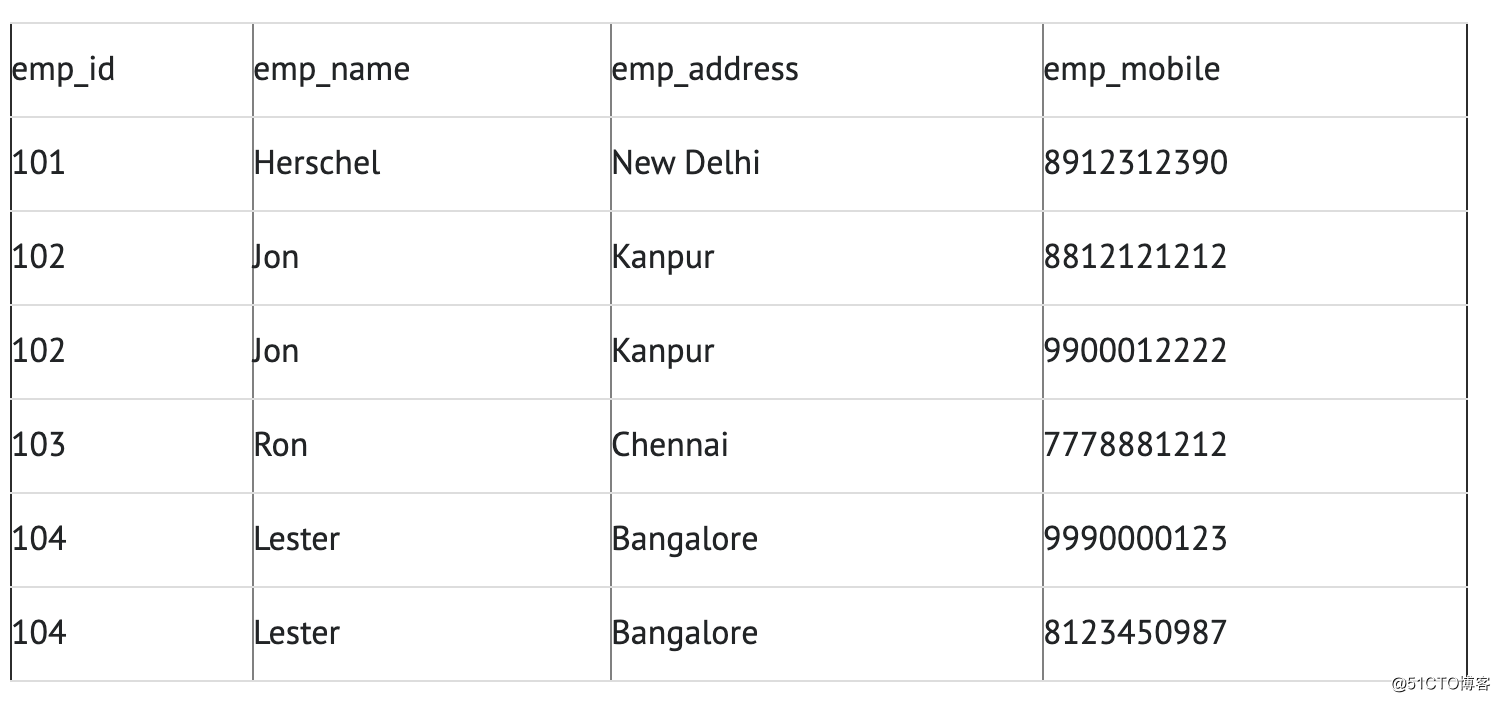
Segunda forma normal (2NF)
O segundo paradigma é um passo além do primeiro paradigma. O segundo paradigma precisa garantir que cada coluna na tabela do banco de dados esteja relacionada à chave primária, e não apenas relacionada a uma determinada parte da chave primária (principalmente para a chave primária combinada). Ou seja, em uma tabela de banco de dados, apenas um tipo de dados pode ser armazenado em uma tabela, e vários tipos de dados não podem ser armazenados na mesma tabela de banco de dados.
+----------+-------------+-------+
| employee | department | head |
+----------+-------------+-------+
| Jones | Accountint | Jones |
| Smith | Engineering | Smith |
| Brown | Accounting | Jones |
| Green | Engineering | Smith |
+----------+-------------+-------+A tabela acima descreve a relação entre o trabalhador, o departamento de trabalho e o líder. Tornamos os dados que podem representar exclusivamente uma linha da tabela no banco de dados como a chave primária desta tabela. A coluna do cabeçalho na tabela não está relacionada à chave primária. Portanto, a tabela não está em conformidade com a segunda forma normal. Para que a tabela acima esteja em conformidade com a segunda forma normal, ela deve ser dividida em duas tabelas:
-- employee 为主键
+----------+-------------+
| employee | department |
+----------+-------------+
| Brown | Accounting |
| Green | Engineering |
| Jones | Accounting |
| Smith | Engineering |
+----------+-------------+
-- department 为主键
+-------------+-------+
| department | head |
+-------------+-------+
| Accounting | Jones |
| Engineering | Smith |
+-------------+-------+Terceira forma normal (3NF)
Sob a premissa de satisfazer 2NF, todos os campos, exceto a chave primária, devem ser independentes uns dos outros, ou seja, é necessário garantir que cada coluna de dados na tabela de dados esteja diretamente relacionada à chave primária, mas não indiretamente relacionada.
Resumindo, a terceira forma normal (3NF) requer que um relacionamento não contenha informações de chave não primária que já estão contidas em outros relacionamentos. Por exemplo, há uma tabela de informações do departamento, onde cada departamento tem informações como número do departamento (dept_id), nome do departamento e perfil do departamento. Então, depois que o número do departamento for listado na tabela de informações do funcionário, as informações relacionadas ao departamento, como nome do departamento e perfil do departamento, não podem ser adicionadas à tabela de informações do funcionário. Se não houver tabela de informações do departamento, ela deve ser construída de acordo com a terceira forma normal (3NF), caso contrário haverá muita redundância de dados.
3. Sobre o antiparadigma
As vantagens do paradigma são óbvias: ele evita muita redundância de dados, economiza espaço de armazenamento e mantém a consistência dos dados. As tabelas normalizadas são geralmente menores e podem ser melhor colocadas na memória, de modo que as operações serão realizadas mais rapidamente. Então, desde que todas as tabelas sejam padronizadas como 3NF, o design do banco de dados é ideal? Isto não é necessariamente verdade. Quanto mais alto o paradigma, mais precisa a divisão das tabelas, mais tabelas são necessárias em um banco de dados e o usuário precisa dividir os dados originalmente associados entre várias tabelas. Uma instrução de consulta um pouco mais complexa pode exigir pelo menos uma associação em um banco de dados que esteja em conformidade com o paradigma, e talvez mais.Isso não só é caro, mas também pode invalidar algumas estratégias de indexação.
Portanto, quando projetamos o banco de dados, não seguiremos completamente os requisitos do paradigma e, às vezes, também conduziremos o projeto antiparadigma. Melhore o desempenho de leitura do banco de dados adicionando dados redundantes ou repetidos e reduza o número de tabelas de junção durante as consultas relacionadas.
referência: