índice
concat (), concat_ws (), group_concat ()
concat () : concatena várias strings em uma string e retorna o resultado como a string gerada pelos parâmetros de conexão. Se algum parâmetro for nulo, o valor de retorno será nulo.
SELECT CONCAT(1,',',2,',',3,',',4) result;
Resultado da operação: 1, 2, 3, 4
SELECT CONCAT(1,',',NULL,',',3,',',4) result;
Resultado da operação: NULL
concat_ws () : (concat com separador) O mesmo que concat (), concatena várias strings em uma string, mas você pode especificar o separador de uma vez. Se o separador for nulo, o resultado será totalmente nulo. Se o parâmetro após o separador for nulo, então nulo será ignorado.
SELECT CONCAT_WS(',',1,2,3,4) result;
Resultado da operação: 1, 2, 3, 4
SELECT CONCAT_WS(',',1,NULL,3,4) result;
Resultado da operação: 1,3,4
SELECT CONCAT_WS(',',1,2,3,4) result;
Resultado da operação: NULL
group_concat () : Na instrução group by query, concatene várias linhas de dados no mesmo grupo em uma única string.
Sintaxe : group_concat ([distinto] o campo a ser conectado [ordenar pelo campo de ordenação asc / desc] [separador'separador '])
Descrição : Valores duplicados podem ser excluídos usando distinto; se você quiser ordenar os valores no resultado, você pode usar A cláusula order by; separator é um valor de string, o padrão é uma vírgula.

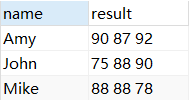
Use group_concat () para listar as notas de cada pessoa com um espaço como separador
SELECT `name`,GROUP_CONCAT(mark SEPARATOR ' ') result
FROM score1 GROUP BY `name`;
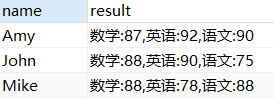
Use group_concat () para listar as notas de todos na forma de pares de valores-chave
SELECT `name`,GROUP_CONCAT(`subject`,':',mark ORDER BY `subject`) result
FROM score1 GROUP BY `name`;
Nota para group_concat () :
- Depois de usar group_concat, se limit for usado no select, não funcionará
- Há um limite de comprimento ao conectar campos com group_concat. Use a variável de sistema group_concat_max_len para definir o comprimento máximo permitido. SET [SESSION | GLOBAL] group_concat_max_len = val;
- O separador padrão do sistema é a vírgula
COALESCE () , IFNULL ()
COALESCE () é usado principalmente para processamento de valor nulo, seu formato de parâmetro: COALESCE (expressão, valor1, valor2 ……, valor)
A primeira expressão de parâmetro da função COALESCE () é a expressão a ser testada, e os seguintes parâmetros são O número é incerto.
A função COALESCE () retornará a primeira expressão não vazia em todos os parâmetros, incluindo a expressão.
Se a expressão não for um valor nulo, retorne a expressão; caso contrário, determine se o valor1 é um valor nulo,
se o valor1 não é um valor nulo, retorne o valor1; caso contrário, determine se o valor2 é um valor nulo,
se o valor2 não é um valor nulo, retorne o valor2;
se todas as expressões Se a fórmula for nula, NULL será retornado.
SELECT COALESCE(1,2,3) result1,
COALESCE(NULL,2,3) result2,
COALESCE(NULL,NULL,3) result3;
Resultado da operação: 1, 2, 3
A função COALESCE () pode ser usada para completar quase todo o processamento de valor nulo, mas uma versão simplificada dela é fornecida em muitos sistemas de banco de dados. Essas versões simplificadas aceitam apenas duas variáveis, como IFNULL ()
SELECT IFNULL(NULL,666) result;
Resultado de corrida: 666
SUM () calcula várias colunas
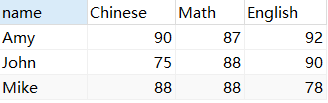
SELECT *,SUM( Chinese + Math + English ) sum
FROM score2 GROUP BY `name`
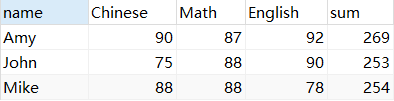
Coluna a linha e linha a coluna
Coluna a linha, coluna a linha
SELECT `name`,
MAX(IF(`subject`='语文',mark,0)) Chinese,
MAX(IF(`subject`='数学',`mark`,0)) Math,
MAX(IF(`subject`='英语',`mark`,0)) English
FROM score1
GROUP BY `name`;
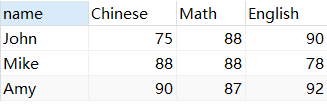
Linha a coluna, linha a coluna
SELECT `name`,'语文' `subject`,Chinese mark FROM score2
UNION
SELECT `name`,'数学' `subject`,Math mark FROM score2
UNION
SELECT `name`,'英语' `subject`,English mark FROM score2
ORDER BY `name`;
Conversão DISTINCT e GROUP BY
Existem tabelas como a seguir, id é o id do registro, user_id é o id do usuário e conta o número de registros e usuários.
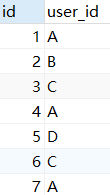
Abordagem do DISTINCT
SELECT COUNT(id) sum_id,COUNT(DISTINCT user_id) sum_user FROM t1;
A prática do GROUP BY
SELECT sum(sum) sum_id,COUNT(user_id) sum_user FROM (
SELECT user_id,COUNT(1) sum FROM t1 GROUP BY user_id ) temp;

O nome da subconsulta
O nome da subconsulta deve ser definido, se não for definido, um erro será relatado.
Subconsulta associada e subconsulta existente
SELECT product_type, product_name, sale_price
FROM product t1 WHERE sale_price > (
SELECT avg(sale_price) FROM product t2
WHERE t1.product_type = t2.product_type);
A lógica de execução é a seguinte:
(1) Execute o loop externo primeiro, depois pegue o primeiro valor da coluna product _type, entre na subconsulta, julgue as condições da cláusula where e, se corresponder, calcule o valor médio e retorne o resultado.
(2) Repita a operação acima até que todos os registros na coluna product _type da tabela Product na consulta principal sejam recuperados.
Descubra os dados na tabela do artigo, mas o uid deve existir na tabela do usuário. A instrução SQL é a seguinte:
SELECT * FROM article WHERE EXISTS (
SELECT * FROM user WHERE article.uid = user.uid);
Coloque os dados da consulta principal na subconsulta para verificação condicional e determine se o resultado dos dados da consulta principal pode ser retido de acordo com o resultado da verificação (VERDADEIRO ou FALSO, portanto, a seleção pode ser arbitrária).
like corresponde a caracteres especiais
escape pode especificar qual é o caractere de escape usado em like, e o caractere após o caractere de escape será considerado como o caractere original
select * from table where name like '1\_%' escape '\'
select * from table where name like '%\%%' escape '\'