Prefácio
Neste capítulo, explicaremos a fila na solução de alta simultaneidade. A fila de mensagens gradualmente se tornou o principal meio de comunicação interna nos sistemas de TI corporativos. Ele possui uma série de funções como baixo acoplamento, entrega confiável, transmissão, controle de fluxo e consistência final, e se tornou um dos principais meios de RPC assíncrono.
Resumo do Assunto
- Introdução básica da fila de mensagens simultânea alta
- Recursos da fila de mensagens
Conteúdo principal
1. Introdução básica da fila de mensagens de alta simultaneidade
1. Exemplos
Depois de fazer um pedido no shopping, espero que o comprador possa receber uma notificação por SMS ou e-mail. Existe uma maneira de ligar para a API para enviar SMS após a lógica de fazer um pedido.Se o servidor demorar a responder, o cliente SMS terá problemas e outros motivos, o comprador não poderá receber o SMS normalmente. E o envio? Não importa qual você escolher, a implementação ficará complicada.
Como é resolvida a fila de mensagens? Pode-se dizer que o processo de envio de mensagens curtas é encapsulado em uma mensagem e enviado para a fila de mensagens. A fila de mensagens processa as mensagens na fila em uma determinada ordem e, em um determinado momento, a mensagem enviada pela mensagem curta será processada. A fila de mensagens notificará um serviço para enviar a mensagem curta.Se for bem-sucedida, a mensagem será processada assim que for colocada na fila. Se algo der errado, você poderá colocar a mensagem na fila de mensagens novamente e aguardar o processamento. Se você usar a fila de mensagens no exemplo acima, a vantagem é desacoplar o processo de envio de mensagens de texto de outras funções. Ao enviar mensagens de texto, você só precisa garantir que essa mensagem seja enviada para a fila de mensagens e, em seguida, poderá lidar com outras coisas depois de enviar a mensagem de texto. Em segundo lugar, o design do sistema tornou-se simples, sem ter que pensar muito em enviar mensagens curtas no cenário de fazer um pedido, mas entregue à fila de mensagens para tratar desse assunto. E pode garantir que a mensagem será enviada, desde que não seja enviada com êxito, ela continuará sendo adicionada à fila de mensagens. Se houver um problema com o serviço SMS, aguarde até que o serviço seja restaurado e a fila de mensagens possa ser enviada, mas não é tão oportuno.
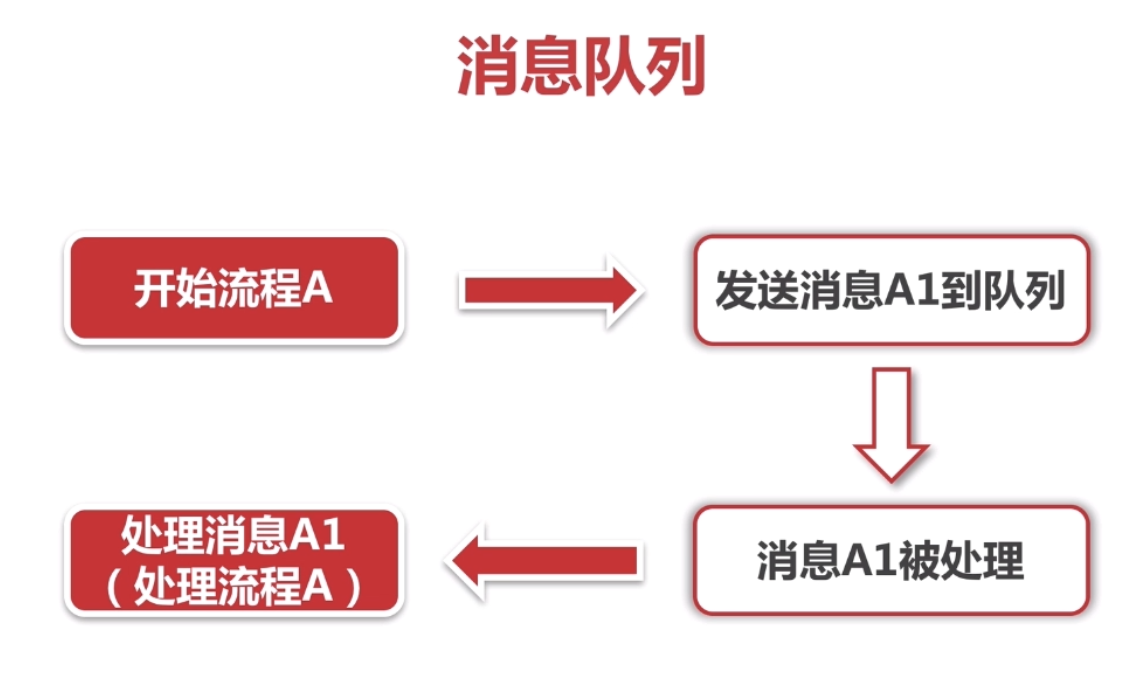
Como ponto final, vamos supor que após o envio do SMS, o email será enviado. Com a fila de mensagens, não precisamos esperar de forma síncrona. Podemos processar diretamente em paralelo. O processo principal de fazer um pedido pode ser concluído mais rapidamente. Isso pode aumentar a capacidade de processamento assíncrono do aplicativo, reduzir ou até mesmo impossível aparecer e encontrar o fenômeno. Lembre-se de que, quando inserimos o número do celular para enviar o código de verificação no site, não podemos receber a mensagem de texto por um longo tempo e o tempo da interface do SMS expirou. Ocorreu um erro quando o SMS foi enviado ou a rede do servidor abriu uma pequena lacuna e pode haver muitas mensagens na fila de mensagens por um certo período de tempo para serem processadas.
2. Benefícios
1. Concluiu com êxito um processo de dissociação assíncrona . Ao enviar um SMS, apenas coloque-o na fila de mensagens e faça o seguinte. Uma transação se preocupa apenas com o processo essencial e precisa depender de outras coisas, mas quando não é tão importante, pode ser notificada sem aguardar o resultado. Cada membro não precisa ser influenciado por outros membros, mas pode ser mais independente e só pode ser contatado por meio de um contêiner simples.
Para o nosso sistema de pedidos, após o pagamento final do pedido ser bem-sucedido, talvez seja necessário enviar pontos SMS para o usuário, mas esse não é o processo principal do nosso sistema. Se a velocidade do sistema externo for lenta (por exemplo, a velocidade do gateway SMS não for boa), o tempo do processo principal será muito maior.O usuário certamente não deseja clicar para pagar por alguns minutos antes de ver o resultado. Depois, precisamos apenas informar ao sistema SMS que "pagamos com sucesso" e não precisamos esperar que ele termine o processamento.
3. Cenários de aplicação
Existem muitos cenários em que as filas de mensagens podem ser usadas
O principal recurso é o processamento assíncrono e o principal objetivo é reduzir o tempo de resposta à solicitação e a dissociação. Portanto, o cenário de uso principal é colocar operações demoradas e que não exigem resultados de retorno imediatos (síncronos) como mensagens na fila de mensagens.
No cenário de uso, por exemplo:
suponha que o usuário se registre no seu software e o servidor faça essas operações após receber a solicitação de registro do usuário:
- Verifique o nome do usuário e outras informações, se nenhum problema adicionar um registro do usuário no banco de dados
- Se você se registrar por e-mail, um e-mail de registro bem-sucedido será enviado a você e o registro do telefone móvel enviará um SMS
- Analise as informações pessoais do usuário para recomendar algumas pessoas afins para ele no futuro ou recomende-o para essas pessoas
- Enviar aos usuários uma notificação do sistema com instruções
Espera ...
Porém, para o usuário, a função de registro realmente precisa apenas da primeira etapa, desde que o servidor armazene as informações de sua conta no banco de dados, ele poderá efetuar login para fazer o que deseja. Quanto a outras coisas, tenho que concluir todas elas nesta solicitação? Vale a pena perder tempo esperando que você lide com essas coisas que não são importantes para ele? Portanto, após a conclusão da primeira etapa, o servidor pode colocar outras operações na fila de mensagens correspondente e retornar imediatamente os resultados do usuário, e a fila de mensagens executa essas operações de forma assíncrona.
Ou existe um caso em que há um grande número de usuários registrando seu software ao mesmo tempo, não importa quão alta seja a simultaneidade, a solicitação de registro começa a ter alguns problemas, como a interface de correio não suporta, ou a grande quantidade de cálculos ao analisar as informações torna o cpu cheio, o que aparecerá Embora os registros de dados do usuário tenham sido adicionados rapidamente ao banco de dados, ele ficou bloqueado ao enviar e-mails ou analisar informações, resultando em um aumento significativo no tempo de resposta da solicitação e até em um tempo limite, que era um pouco antieconômico. Diante dessa situação, essas operações geralmente são colocadas na fila de mensagens (modelo de consumidor do produtor), a fila de mensagens é processada lentamente e a solicitação de registro pode ser concluída rapidamente, sem afetar o uso de outras funções pelo usuário.
Segundo, as características da fila de mensagens
1. Quatro características
- Não relacionado aos negócios: apenas distribuir mensagens
- FIFO (primeiro a entrar, primeiro a sair): primeira entrega, primeira chegada
- Tolerância a desastres: adição e exclusão dinâmicas de nós e persistência de mensagens
- Desempenho: maior produtividade e maior eficiência na comunicação interna do sistema
2. Por que você precisa de uma fila de mensagens?
- A velocidade ou estabilidade de [produção] e [consumo] são inconsistentes.
3. Benefícios do serviço de enfileiramento de mensagens
-
Desacoplamento de negócios : é o problema mais essencial resolvido pela fila de mensagens. O chamado desacoplamento é um processo que se preocupa com o núcleo de uma coisa e precisa confiar em outros sistemas, mas não é tão importante. Pode ser notificado sem aguardar o resultado. Em outras palavras, o modelo baseado em mensagem se preocupa mais com a notificação do que com o processamento. Por exemplo, existe um centro de produtos dentro de uma plataforma de viagens. O centro de produtos está conectado a várias fontes de dados, como estação principal, plano de fundo móvel e cadeia de suprimentos de turismo. O downstream é conectado ao sistema de exibição, como o sistema de recomendação e o sistema API. Quando os dados upstream são alterados, No momento, se você não usar filas de mensagens, inevitavelmente precisará chamar a interface para atualizar os dados, o que depende da estabilidade e do poder de processamento da interface do centro de produtos.No entanto, como um centro de produtos para turismo, talvez apenas para o suprimento de turismo construído por ele mesmo O sucesso da atualização do centro de produtos da cadeia é sua preocupação. Para sistemas externos, como compras em grupo, o sucesso da atualização do centro de produtos não é responsabilidade de falha. Eles só precisam garantir que sejam notificados quando as informações forem alteradas. Para o downstream, pode haver uma série de requisitos, como atualizar o índice e atualizar o cache.Para o centro de produtos, essas não são as responsabilidades. Para ser franco, se eles extraem dados regularmente, eles também podem garantir que os dados sejam atualizados, mas o tempo real não é tão forte, mas se o método de interface for usado para atualizar os dados, é obviamente muito pesado para o centro de produtos e apenas um precisa ser liberado neste momento. A notificação da alteração do ID do produto é mais razoável para ser processada pelo sistema downstream. Vamos dar outro exemplo: para o sistema de pedidos, após o pagamento final do pedido ser bem-sucedido, talvez seja necessário enviar uma notificação de mensagem de texto ao usuário, mas esse não é mais o processo principal do sistema.Se a velocidade do sistema externo for lenta, como a velocidade do gateway SMS, não é boa. , Então o tempo do processo principal será muito mais longo, o usuário certamente não deseja clicar para ver o resultado depois de alguns minutos; então, precisamos notificar o sistema de SMS que pagamos com sucesso, basta enviar uma notificação por SMS, não precisa ser necessário. Aguarde o término do processamento antes de terminar.
-
Consistência final : consistência final refere-se ao estado dos dois sistemas que permanecem consistentes, com êxito ou com falha. É claro que há um limite de tempo, quanto mais rápido, melhor na teoria, mas, de fato, sob várias condições anormais, pode haver um certo atraso para atingir o estado consistente final, mas o estado dos dois últimos sistemas é o mesmo.
Existem algumas filas de mensagens no setor para "consistência máxima", como Notify (Ali) e QMQ (Para onde ir) etc. A intenção original do design é receber notificações altamente confiáveis no sistema de transações.
Para entender a consistência final com o processo de transferência de um banco, a necessidade de transferência é simples: se o sistema A deduz dinheiro com êxito, o sistema B deve adicionar dinheiro com sucesso. Caso contrário, recue como se nada tivesse acontecido.
No entanto, existem muitos acidentes possíveis nesse processo:(1) A deduz dinheiro com êxito e falha ao chamar a interface B plus money.
(2) Um dinheiro deduzido com êxito Embora a chamada para a interface B plus money tenha sido bem-sucedida, a exceção de rede causou um tempo limite ao obter o resultado final.
(3) A deduz dinheiro com sucesso, B falha em adicionar dinheiro, A deseja reverter o dinheiro deduzido, mas A máquina está inoperante.
Pode-se ver que realmente não é tão fácil realmente fazer essa coisa aparentemente simples. Do ponto de vista técnico, todos os problemas comuns de consistência entre JVM são:
(1) Forte consistência, transações distribuídas, mas o desembarque é muito difícil e o custo é muito alto, não é mais uma introdução específica aqui, quero conhecer o Baidu.
(2) A consistência final é principalmente por meio de "registro" e "compensação". Antes de fazer todas as coisas incertas, primeiro registre-as e depois faça-as.O resultado pode ser: sucesso, falha ou incerteza. "Incerto" (como tempo limite) pode ser equivalente a falha . Se for bem-sucedido, você pode limpar as coisas gravadas.Para falhas e incertezas, você pode contar com tarefas programadas e outros métodos para reativar todas as coisas com falha até obter sucesso.
Voltando ao exemplo anterior, quando o sistema deduz dinheiro com êxito de A, o sistema registra a "notificação" para B na biblioteca (para garantir a mais alta confiabilidade, o sistema pode notificar o sistema B para adicionar dinheiro e deduzir dinheiro com êxito. As coisas são mantidas em uma transação local.) Se a notificação for bem-sucedida, o registro será excluído.Se a notificação falhar ou for incerta, dependemos de uma tarefa agendada para nos informar de forma compensatória até atualizar o status para a correta. Deve-se observar que o design de filas de mensagens , como Kafka, tem a possibilidade de perder mensagens no nível do design. Por exemplo, piscar regularmente pode causar a perda de mensagens. Mesmo se perder apenas um milésimo da mensagem, a empresa usa outros Os meios também devem garantir que os resultados estejam corretos. -
Difusão : uma das funções básicas da fila de mensagens é a difusão. Se não houver fila de mensagens, sempre que uma nova parte comercial acessar, precisamos depurar em conjunto a nova interface. Com a fila de mensagens, precisamos apenas nos preocupar se a mensagem será entregue à fila.Quanto a quem deseja se inscrever, é uma questão a jusante, que sem dúvida reduz bastante a carga de trabalho de desenvolvimento e depuração conjunta.
-
Aceleração : suponha que ainda precisamos enviar e-mail. Com a fila de mensagens, não precisamos esperar de forma síncrona. Podemos processar diretamente em paralelo e as tarefas principais podem ser concluídas mais rapidamente. Aprimore a capacidade de processamento assíncrono do sistema de negócios. É quase impossível aparecer e descobrir elefantes.
-
Controle de pico de corte e fluxo : para solicitações que não requerem processamento em tempo real, quando a quantidade de simultaneidade é particularmente grande, você pode primeiro armazenar em cache na fila de mensagens e enviá-las ao serviço correspondente para processamento. Imagine que a montante e a jusante tenham recursos de processamento diferentes para as coisas. Por exemplo, não é uma coisa mágica para o front-end da Web suportar dezenas de milhões de solicitações por segundo, basta adicionar um pouco mais de máquinas e criar alguns equipamentos de balanceamento de carga LVS e Nginx. No entanto, o poder de processamento do banco de dados é muito limitado, mesmo com o uso de SSD mais sub-banco de dados e sub-tabela, o poder de processamento de uma única máquina ainda está em 10.000 níveis. Devido a considerações de custo, não podemos esperar que o número de máquinas de banco de dados acompanhe o front end. Esse problema também existe entre o sistema e o sistema.Por exemplo, devido ao efeito da placa curta, a velocidade do sistema de mensagens curtas fica presa no gateway (centenas de solicitações por segundo) e a simultaneidade com o front end não é uma ordem de magnitude. No entanto, se o usuário receber a mensagem de texto cerca de meio minuto à noite, geralmente não haverá problema. Se não houver fila de mensagens, esquemas complexos como negociação e janelas deslizantes entre os dois sistemas não são impossíveis. No entanto, o crescimento exponencial da complexidade do sistema inevitavelmente o armazenará a montante ou a jusante e lidará com uma série de problemas, como tempo e congestionamento. E sempre que houver uma lacuna no poder de processamento, um conjunto separado de lógica precisará ser desenvolvido para manter esse conjunto de lógica. Portanto, é uma maneira relativamente comum de usar o sistema intermediário para despejar o conteúdo de comunicação dos dois sistemas e processar essas mensagens quando o sistema downstream tiver a capacidade de processar essas mensagens. Em suma, a fila de mensagens não é uma panacéia. Para aqueles que exigem fortes garantias de transação e são sensíveis a atrasos, o RPC é superior às filas de mensagens. Para coisas irrelevantes ou muito importantes para os outros, mas não tão preocupadas com você, você pode usar a fila de mensagens para fazer isso. As filas de mensagens que suportam consistência eventual podem ser usadas para lidar com cenários de "transação distribuída" onde a latência não é tão sensível e pode ser uma maneira melhor de processar do que transações distribuídas em massa. Quando houver uma lacuna nos recursos de processamento dos sistemas upstream e downstream, use as filas de mensagens como um "funil" geral. Quando o downstream for capaz de processar, distribua-o novamente. Se houver muitos sistemas downstream preocupados com as notificações enviadas pelo seu sistema, use a fila de mensagens decisivamente.
4. Exemplo de fila de mensagens
(1) Aqui, segmentamos apenas Kafka e RabbitMQ como exemplos
- Kafka
- RabbitMQ
...
(2) Kafka é um projeto Apache, um sistema de fila de mensagens de publicação e assinatura de alto desempenho, em vários idiomas, distribuído.
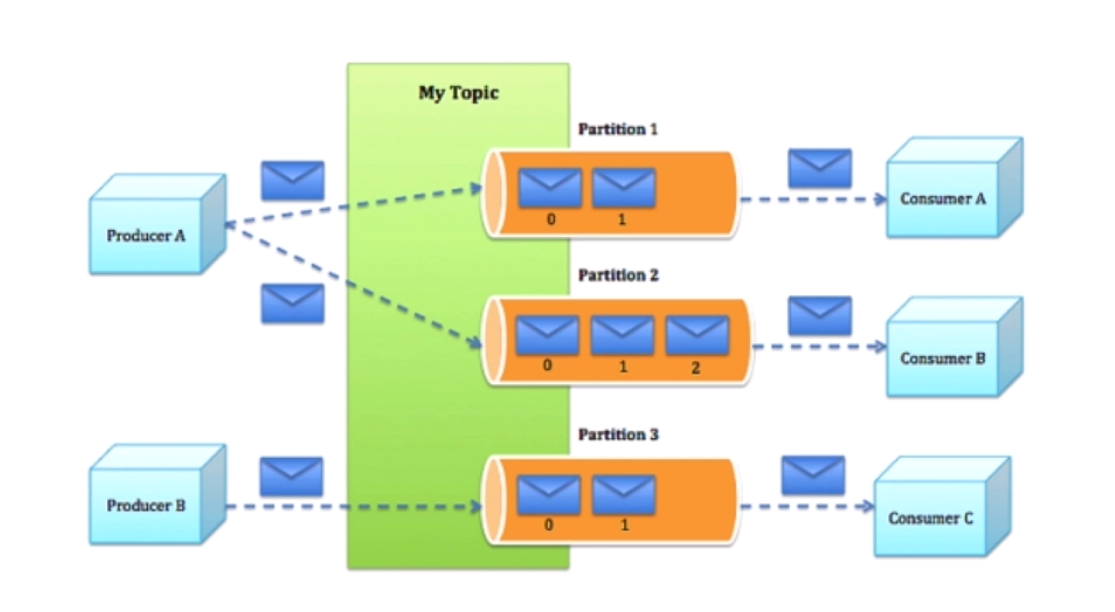
Diagrama de estrutura
Características
- Rápida duração. O recurso de persistência de mensagem é fornecido de uma maneira com uma complexidade de tempo de O (1), e o desempenho do acesso com complexidade de tempo constante pode ser garantido mesmo para dados acima do nível de terabytes.
- Alto rendimento. Mesmo em máquinas comerciais muito baratas, pode conseguir a transmissão de mais de 100 mil mensagens por segundo em uma única máquina. É um sistema completamente distribuído, seu Broker, Producer e Consumer (consulte a terminologia básica) são todos nativos, suportam automaticamente o balanceamento de carga distribuído e automático e suportam o carregamento paralelo de dados do Hadoop.
- Ofereça suporte ao particionamento de mensagens entre os servidores Kafka e ao consumo distribuído, garantindo a transmissão sequencial de mensagens dentro de cada partição.
- Ele também suporta processamento de dados offline e processamento de dados em tempo real.
- Expansão: suporte a expansão horizontal online.
Terminologia básica
- Broker: o cluster Kafka contém um ou mais servidores, chamados de brokers.
- Tópico: Toda mensagem publicada no cluster Kafka tem uma categoria, chamada Tópico. (Fisicamente, as mensagens de tópicos diferentes são armazenadas separadamente. Embora logicamente, as mensagens de um tópico sejam armazenadas em um ou mais intermediários, mas os usuários precisam especificar o tópico da mensagem para produzir ou consumir dados sem ter que se preocupar com a localização dos dados.
- Partição: Partição é um conceito físico, cada Tópico contém uma ou mais Partições.
- Produtor: responsável pela publicação de mensagens no corretor Kafka.
- Consumidor: um consumidor de mensagens, um cliente que lê mensagens do broker Kafka.
- Grupo de Consumidores: Cada Consumidor pertence a um Grupo de Consumidores específico (você pode especificar o nome do grupo para cada Consumidor, se você não especificar o nome do grupo, ele pertence ao grupo padrão).
(3) Em seguida, vamos dar uma olhada no RabbitMQ.
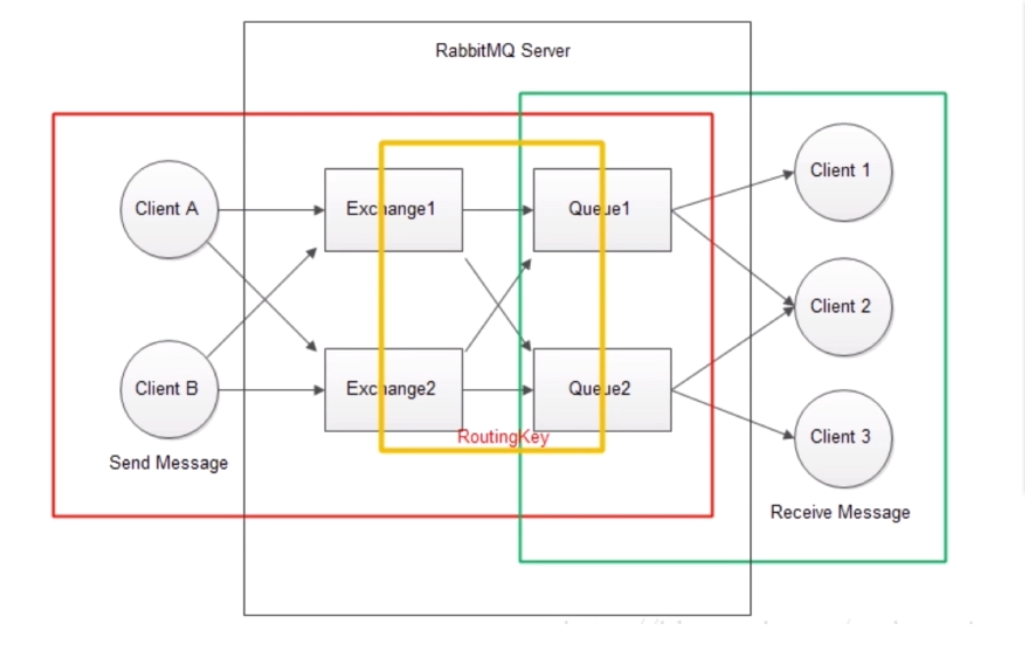
Diagrama de estrutura
Definição básica no RabbitMQ
RabbitMQ Server : Fornece um processamento de mensagens do Produtor para o Consumidor.
Troca : envie mensagens para a fila enquanto recebe mensagens do editor.
Os produtores só podem enviar mensagens para troca. A troca é responsável por enviar mensagens para filas. A mensagem do Procuder Publish entra no Exchange.O Exchange processa a mensagem recebida de acordo com a routingKey, determina se a mensagem deve ser enviada para a fila especificada ou para várias filas ou simplesmente ignora a mensagem. Essas regras são definidas pelo tipo de troca (tipo de troca) Os principais tipos são direto, tópico, cabeçalhos e fanout. Use tipos diferentes para diferentes cenários.
A fila também é vinculada pelas chaves de roteamento. O comutador corresponderá com precisão a chave de ligação e a chave de roteamento para determinar em qual fila a mensagem deve ser distribuída.
Fila : fila de mensagens. Receba a mensagem da central e retire-a pelo consumidor. O Exchange e a fila podem ser um para um ou um para muitos e seu relacionamento é vinculado pela routingKey.
Produtor : Cliente A & B, produtor, a fonte da mensagem, a mensagem deve ser enviada para a central. Em vez de diretamente para a fila
Consumidor : consumidor 1, 2, 3 consumidores, obtenha mensagens diretamente da fila para consumo, em vez de obter mensagens da central para consumo.
(4) Kafka e rabbitmq usam o springboot como exemplo.Para simplificar o conteúdo, os dois executam o teste ao mesmo tempo.
Para a instalação do kafka no Windows, consulte: https://www.jianshu.com/p/d64798e81f3b
Arquitetura de pacotes

KafkaReceiver.java
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* 接收端
*/
@Component
@Slf4j
public class KafkaReceiver {
@KafkaListener(topics={TopicConstants.TEST})
public void receive(ConsumerRecord<?,?> record){
log.info("record:{}",record);
}
}
KafkaSender.java
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.practice.mq.Message;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Date;
/**
* 发送端
*/
@Component
@Slf4j
public class KafkaSender {
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
private Gson gson = new GsonBuilder().create();
public void send(String msg) {
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMsg(msg);
message.setSendTime(new Date());
log.info("send Message:{}",message);
kafkaTemplate.send(TopicConstants.TEST,gson.toJson(message));
}
}
TopicConstants.java
public interface TopicConstants {
//定义一下我们需要使用Topic的字符串
String TEST = "test";
String MESSAGE = "message";
}
QueuesContants.java
public interface QueuesConstants {
String TEST="test";
String MESSAGE="message";
}
RabbitMQClient.java
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
public class RabbitMQClient {
@Resource
private RabbitTemplate rabbitTemplate;
public void send(String message){
//发送到指定队列
rabbitTemplate.convertAndSend(QueuesConstants.TEST,message);
}
}
RabbitMQServer.java
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
@Bean
public Queue queue(){
//定义好要发送的队列
return new Queue(QueuesConstants.TEST);
}
}
Message.java
import lombok.Data;
import java.util.Date;
@Data
public class Message {
private Long id;
private String msg;
private Date sendTime;
}
MQController.java
import com.practice.mq.kafka.KafkaSender;
import com.practice.mq.rabbitmq.RabbitMQClient;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.annotation.Resource;
@Controller
@RequestMapping("/mq")
public class MQController {
@Resource
private RabbitMQClient rabbitMQClient;
@Resource
private KafkaSender kafkaSender;
@RequestMapping("/send")
@ResponseBody
public String send(){
String message = "message";
rabbitMQClient.send(message);
kafkaSender.send(message);
return "success";
}
}
Dependências do Maven usadas (aqui combinadas com o springboot)
<!--kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!--Gson-->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.7</version>
</dependency>
<!-- rabbitmq依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
configuração application.properties
#============== kafka ===================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=127.0.0.1:9092
spring.kafka.consumer.group-id=test
#=============== provider =======================
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
spring.kafka.producer.acks=1
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
O navegador executa o console "http://127.0.0.1:8090/mq/send"
para imprimir
rabbitmq:
...
2020-04-19 02:09:12.040 INFO 31676 --- [nio-8090-exec-1] com.practice.mq.kafka.KafkaSender : send Message:Message(id=1587233352040, msg=message, sendTime=Sun Apr 19 02:09:12 GMT+08:00 2020)
2020-04-19 02:09:12.048 INFO 31676 --- [cTaskExecutor-1] com.practice.mq.rabbitmq.RabbitMQServer : message:message
2020-04-19 02:09:12.054 INFO 31676 --- [nio-8090-exec-1] o.a.k.clients.producer.ProducerConfig : ProducerConfig values:
kafka:
...
2020-04-19 02:09:12.070 INFO 31676 --- [nio-8090-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version : 2.0.0
2020-04-19 02:09:12.070 INFO 31676 --- [nio-8090-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId : 3402a8361b734732
2020-04-19 02:09:12.076 INFO 31676 --- [ad | producer-1] org.apache.kafka.clients.Metadata : Cluster ID: i1-NXUmvQRyaT-E27LPozQ
2020-04-19 02:09:12.106 INFO 31676 --- [ntainer#0-0-C-1] com.practice.mq.kafka.KafkaReceiver : record:ConsumerRecord(topic = test, partition = 0, offset = 5, CreateTime = 1587233352082, serialized key size = -1, serialized value size = 73, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"id":1587233352040,"msg":"message","sendTime":"Apr 19, 2020 2:09:12 AM"})
OK, então o exemplo simples dessas duas filas acabou!