
Synchronized, AtomicLong ou LongAdder para contagem?
A função de contagem é usada em muitos sistemas, então qual dentre sincronizado, AtomicLong, LongAdder devemos usar para a contagem? Vamos dar um exemplo
public class CountTest {
private int count = 0;
@Test
public void startCompare() {
compareDetail(1, 100 * 10000);
compareDetail(20, 100 * 10000);
compareDetail(30, 100 * 10000);
compareDetail(40, 100 * 10000);
}
/**
* @param threadCount 线程数
* @param times 每个线程增加的次数
*/
public void compareDetail(int threadCount, int times) {
try {
System.out.println(String.format("threadCount: %s, times: %s", threadCount, times));
long start = System.currentTimeMillis();
testSynchronized(threadCount, times);
System.out.println("testSynchronized cost: " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
testAtomicLong(threadCount, times);
System.out.println("testAtomicLong cost: " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
testLongAdder(threadCount, times);
System.out.println("testLongAdder cost: " + (System.currentTimeMillis() - start));
System.out.println();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testSynchronized(int threadCount, int times) throws InterruptedException {
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
add();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
public synchronized void add() {
count++;
}
public void testAtomicLong(int threadCount, int times) throws InterruptedException {
AtomicLong count = new AtomicLong();
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
count.incrementAndGet();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
public void testLongAdder(int threadCount, int times) throws InterruptedException {
LongAdder count = new LongAdder();
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
count.increment();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
}
threadCount: 1, times: 1000000
testSynchronized cost: 187
testAtomicLong cost: 13
testLongAdder cost: 15
threadCount: 20, times: 1000000
testSynchronized cost: 829
testAtomicLong cost: 242
testLongAdder cost: 187
threadCount: 30, times: 1000000
testSynchronized cost: 232
testAtomicLong cost: 413
testLongAdder cost: 111
threadCount: 40, times: 1000000
testSynchronized cost: 314
testAtomicLong cost: 629
testLongAdder cost: 162
Quando a quantidade de simultaneidade é relativamente baixa, a vantagem do AtomicLong é mais óbvia , porque a camada inferior do AtomicLong é um bloqueio otimista e não há necessidade de bloquear o encadeamento, apenas mantenha o cas. No entanto , é vantajoso usar o synchronized quando a simultaneidade é relativamente alta , porque um grande número de threads continua a cas, o que fará com que a CPU continue a subir, o que reduzirá a eficiência.
LongAdder tem vantagens óbvias, independentemente do nível de simultaneidade. E quanto maior a quantidade de simultaneidade, mais óbvia será a vantagem
O "Manual de Desenvolvimento Java" do Alibaba também tem as seguintes sugestões:

Como o LongAdder consegue alta simultaneidade?
Como LongAdder consegue alta simultaneidade?
A ideia básica
O segredo da alta simultaneidade de LongAdder é usar o espaço para o tempo. A operação cas em um valor torna-se a operação cas em vários valores. Quando a quantidade é obtida, os vários valores podem ser somados.
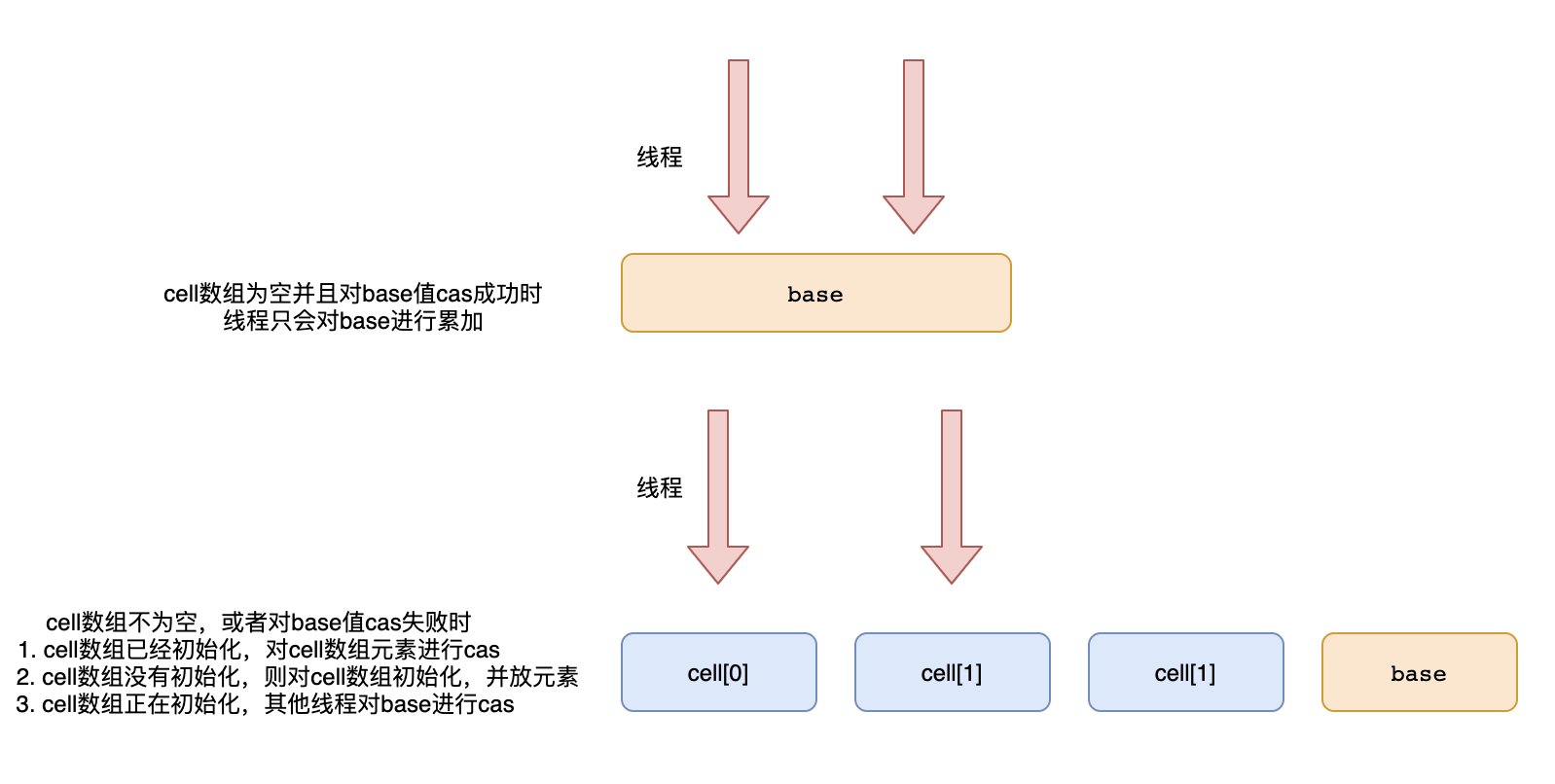
Específico para o código-fonte é
- Execute a operação cas na variável base primeiro e retorne depois que o cas for bem-sucedido
- Obtenha um valor hash para o thread (chame getProbe), o valor hash modula o comprimento da matriz, localiza o elemento na matriz de células e executa o cas nos elementos da matriz
Aumente o número de
public void increment() {
add(1L);
}
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// 数组为空则先对base进行一波cas,成功则直接退出
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
Quando a matriz não está vazia, e o elemento localizado em um subscrito da matriz não está vazio de acordo com o valor de hash da thread, cas retornará diretamente a este elemento se for bem-sucedido, caso contrário, insira o método longAccumulate
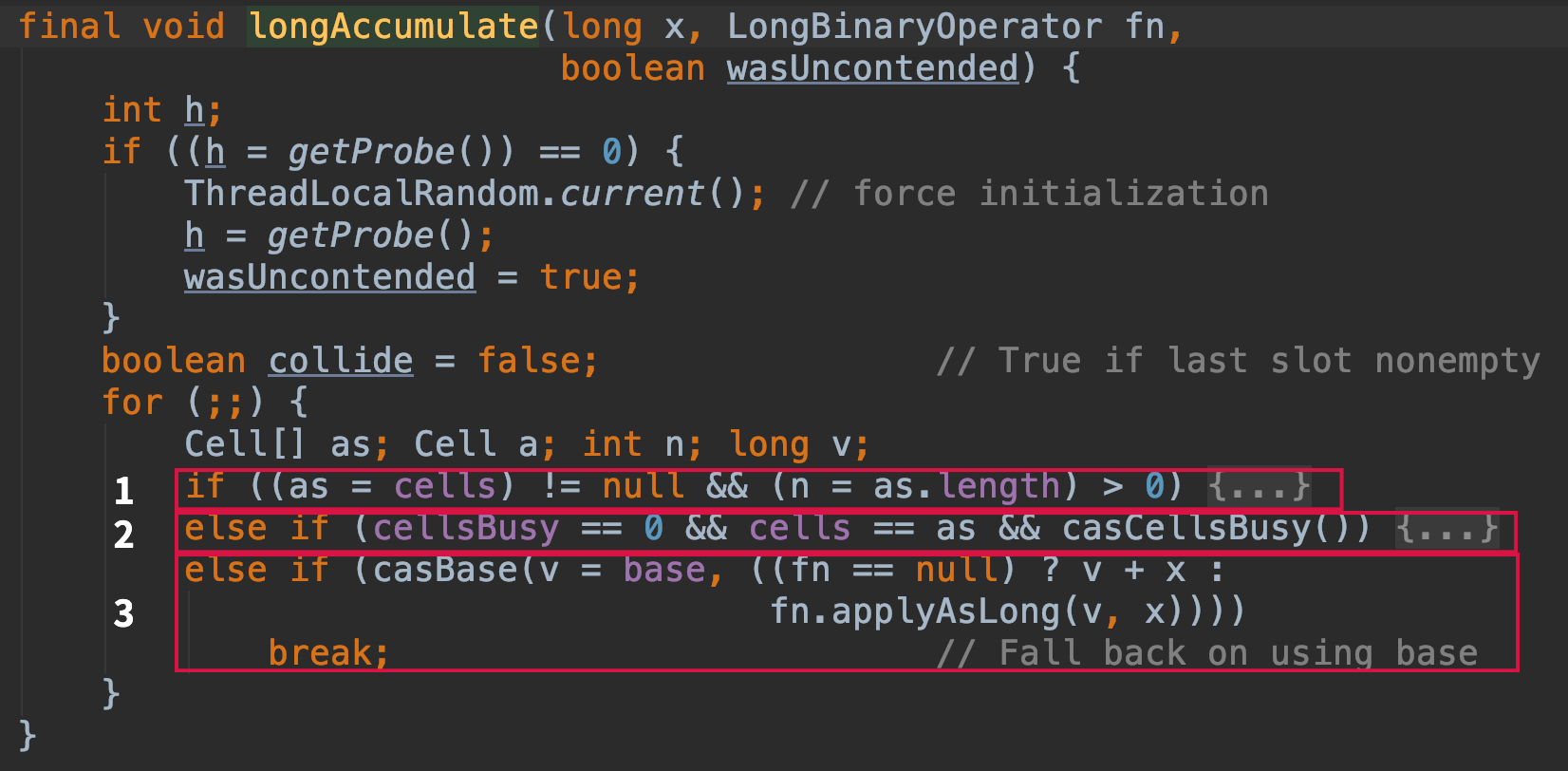
- A matriz de células foi inicializada, principalmente para colocar elementos na matriz de células e realizar operações como a expansão da matriz de células
- Se a matriz de células não for inicializada, inicialize a matriz
- A matriz de células está sendo inicializada e outros threads usam cas para acumular baseCount
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
// 往数组中放元素是否冲突
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
// 有线程在操作数组cellsBusy=1
// 没有线程在操作数组cellsBusy=0
if (cellsBusy == 0) {
// Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
// Recheck under lock
Cell[] rs; int m, j;
// // 和单例模式的双重检测一个道理
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
// 成功在数组中放置元素
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
// cas baseCount失败
// 并且往CounterCell数组放的时候已经有值了
// 才会重新更改wasUncontended为true
// 让线程重新生成hash值,重新找下标
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// cas数组的值
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// 其他线程把数组地址改了(有其他线程正在扣哦荣)
// 数组的数量>=CPU的核数
// 不会进行扩容
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
// collide = true(collide = true会进行扩容)的时候,才会进入这个else if
// 上面2个else if 是用来控制collide的
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
// Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
// Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
Quantidade adquirida
valor base + o valor na matriz de células
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
Deve-se observar que o número retornado pela chamada de sum () pode não ser o número atual, porque no processo de chamada do método sum (), pode haver outras matrizes que alteraram a variável base ou a matriz de células.
// AtomicLong
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
O método AtomicLong # getAndIncrement retornará o valor exato após o incremento, porque cas é uma operação atômica
Por fim, apresentarei um pequeno menu. Em jdk1.8, a ideia de ConcurrentHashMap de aumentar o número de elementos e operações estatísticas é exatamente a mesma de LongAdder. O código é basicamente o mesmo. Se você estiver interessado, você pode dar uma olhada.
Blog de referência
[1] https://www.cnblogs.com/thisiswhy/p/13176237.html