Escreva na frente
O código ou pseudo-código do artigo é um trecho online e meu código é privado!
hw2
1. Detecção de canto de Harris
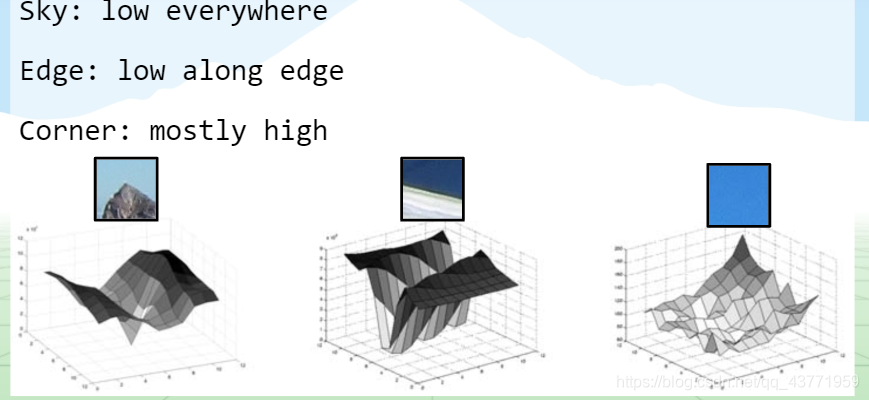
Cálculo de ponto de recurso

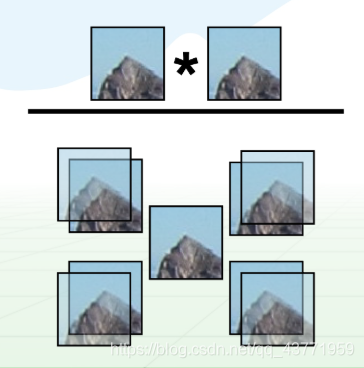
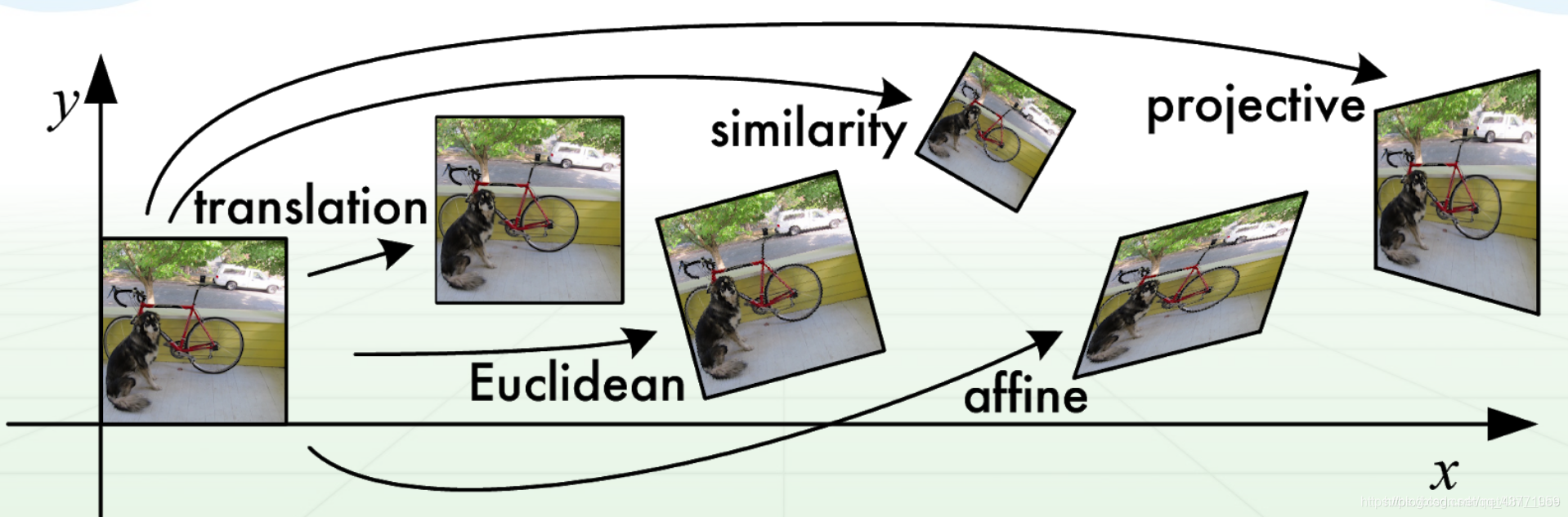
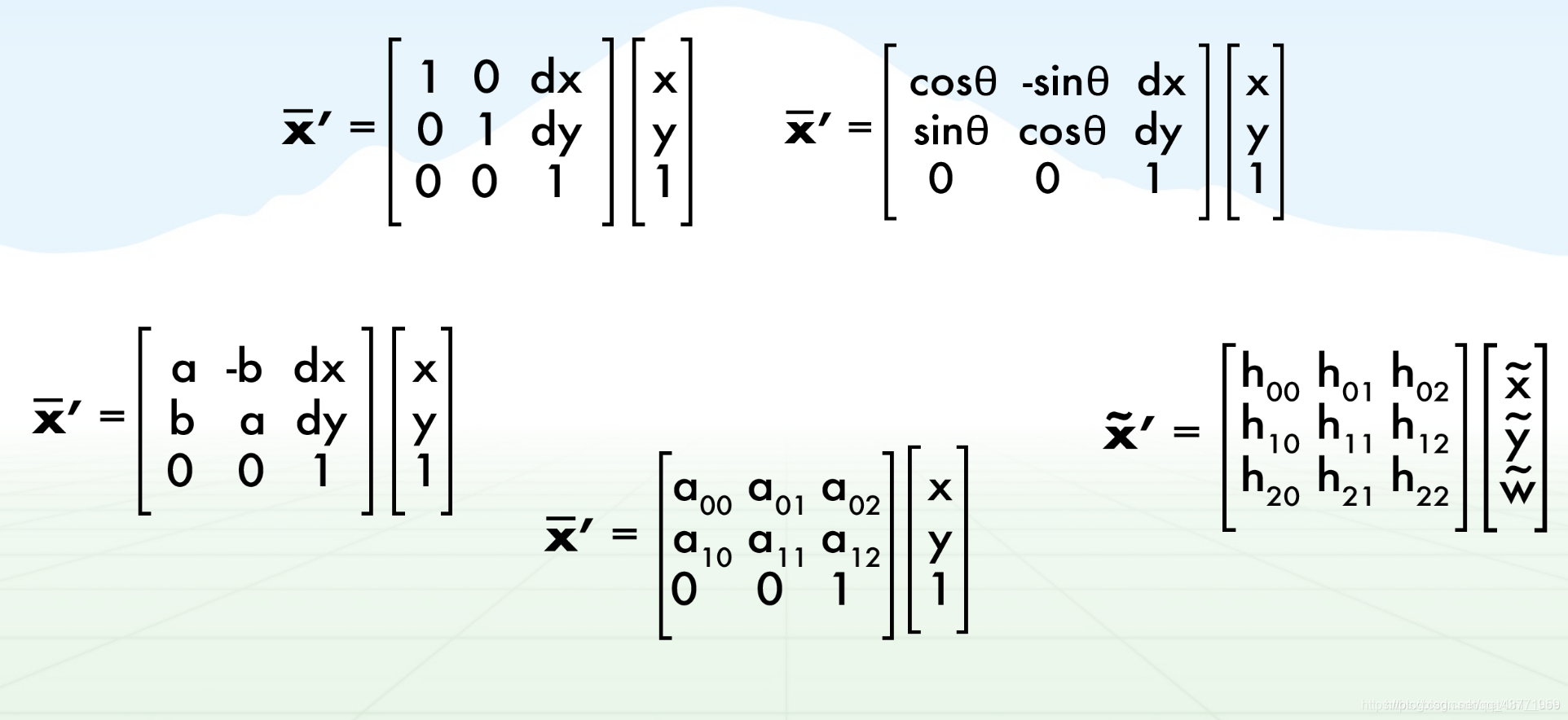
Afim: (transformação essencial de coordenadas)

supressão não máxima (NMS)
Ao executar a detecção de destino, geralmente é adotado um método de deslizamento de janela para gerar muitos quadros candidatos na imagem e, em seguida, esses quadros candidatos são submetidos à extração de recursos e depois enviados ao classificador.Geralmente, é obtida uma pontuação, como detecção de rosto , Haverá pontuações em muitas caixas e todas essas pontuações serão classificadas. Selecione a caixa com a pontuação mais alta e calcule o grau de sobreposição (iou) das outras caixas com a caixa atual.Se o grau de coincidência for maior que um determinado limite, exclua-o, porque pode haver várias caixas com pontuações altas na mesma face. É um rosto humano, mas não precisa ser emoldurado. Só precisamos de um.
Percorra o restante das caixas, se a área de sobreposição (IOU) com a subestrutura mais alta atual for maior que um determinado limite, excluiremos a caixa
Código MATLAB encontrado online
%% NMS:non maximum suppression
function pick = nms(boxes,threshold,type)
% boxes: m x 5,表示有m个框,5列分别是[x1 y1 x2 y2 score]
% threshold: IOU阈值
% type:IOU阈值的定义类型
% 输入为空,则直接返回
if isempty(boxes)
pick = [];
return;
end
% 依次取出左上角和右下角坐标以及分类器得分(置信度)
x1 = boxes(:,1);
y1 = boxes(:,2);
x2 = boxes(:,3);
y2 = boxes(:,4);
s = boxes(:,5);
% 计算每一个框的面积
area = (x2-x1+1) .* (y2-y1+1);
%将得分升序排列
[vals, I] = sort(s);
%初始化
pick = s*0;
counter = 1;
% 循环直至所有框处理完成
while ~isempty(I)
last = length(I); %当前剩余框的数量
i = I(last);%选中最后一个,即得分最高的框
pick(counter) = i;
counter = counter + 1;
%计算相交面积
xx1 = max(x1(i), x1(I(1:last-1)));
yy1 = max(y1(i), y1(I(1:last-1)));
xx2 = min(x2(i), x2(I(1:last-1)));
yy2 = min(y2(i), y2(I(1:last-1)));
w = max(0.0, xx2-xx1+1);
h = max(0.0, yy2-yy1+1);
inter = w.*h;
%不同定义下的IOU
if strcmp(type,'Min')
%重叠面积与最小框面积的比值
o = inter ./ min(area(i),area(I(1:last-1)));
else
%交集/并集
o = inter ./ (area(i) + area(I(1:last-1)) - inter);
end
%保留所有重叠面积小于阈值的框,留作下次处理
I = I(find(o<=threshold));
end
pick = pick(1:(counter-1));
end
2. Correspondência de patches
Medição de distância:
Σx, y (I (x, y) -J (x, y)) 2

encontre a melhor correspondência
Algoritmo de consenso de amostra aleatória (RANSAC)
Estimar iterativamente os parâmetros do modelo matemático a partir de um conjunto de dados observados contendo valores extremos.
① Considere um modelo com um potencial mínimo de conjunto de amostragem de n (n é o número mínimo de amostras necessário para inicializar os parâmetros do modelo) e um conjunto de amostras P, o número de amostras no conjunto P # §> n, selecione aleatoriamente n amostras de P O subconjunto S de P inicializa o modelo M;
set O conjunto de amostras cujo erro no conjunto residual SC = P \ S é menor que um determinado limite do conjunto t e S constitui S *. S é considerado um conjunto de pontos interior, e eles constituem um conjunto consistente de S (Conjunto de Consenso);
#Se # (S ) ≥N, considera-se que os parâmetros corretos do modelo são obtidos e o método dos mínimos quadrados é usado usando o conjunto S * (inliers) Recalcule o novo modelo M *; extraia aleatoriamente um novo S e repita o processo acima.
④ Após a conclusão de um determinado número de amostragens, se o conjunto consistente não for encontrado, o algoritmo falhará, caso contrário, o maior conjunto consistente obtido após a amostragem será usado para julgar os pontos internos e externos, e o algoritmo será encerrado.
O algoritmo de pseudocódigo é o seguinte: (online)
输入:
Data 一组观测数据
Model 适应于数据的模型
n 适应于模型的最小数据个数
k 算法的迭代次数
t 用于决定数据是否适应于模型的阈值
d 判定模型是否适用于数据集的数据数目
参考链接:http://blog.csdn.net/pi9nc/article/details/26596519
Best_model 与数据最匹配的模型参数(没有返回null)
Best_consensus_set 估计出模型的数据点
Best_error 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
Algoritmo SIFT detalhado
https://blog.csdn.net/zddblog/article/details/7521424
