1. Camada da fonte de dados: incluindo bancos de dados tradicionais, armazéns de dados, bancos de dados distribuídos, bancos de dados NOSQL, dados semiestruturados, dados não estruturados, rastreadores, sistemas de log etc., é o mecanismo de geração de dados da plataforma de big data.
2. Camada de classificação de dados: incluindo limpeza de dados, conversão de dados, processamento de dados, associação de dados, anotação de dados, pré-processamento de dados, carregamento de dados, extração de dados etc. A função dessa camada é processar dados brutos nos dados do produto.
3. Camada de armazenamento de dados (datacenter): armazena dados limpos que podem ser usados em sistemas de produção, como metadados, bancos de dados de negócios, bancos de dados de modelos, etc. Essa camada está diretamente voltada para o sistema de aplicativos e requer alta confiabilidade, alta simultaneidade e alta Precisão.
4. Camada de modelagem e mineração de dados: Esta camada implementa o processamento profundo de dados.De acordo com as necessidades do negócio, estabelece um modelo de análise estatística adequado para os negócios, estabelece uma plataforma de operação e processamento de big data e utiliza análise de dados, mineração de dados, aprendizado profundo e outros algoritmos para Os dados de produção extraem o valor intrínseco dos dados para fornecer dados e suporte a decisões para sistemas de negócios.
5. Camada de aplicação do setor: análise aprofundada das características dos dados do setor, combatendo as necessidades dos produtos de dados do setor e estabelecendo produtos de aplicativos de dados adequados para diferentes setores.
6. Visualização de dados: forneça serviços de exibição e compartilhamento de dados de várias maneiras, como relatórios inteligentes, relatórios especiais, exibições de BI, interfaces de plataforma etc.


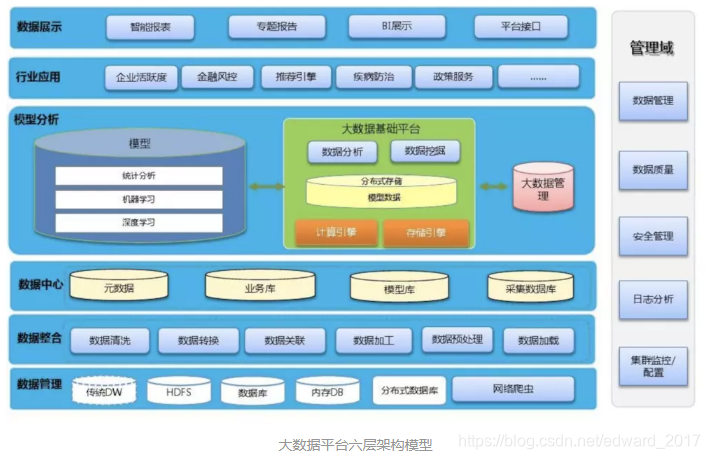

Não existe um padrão para a divisão hierárquica da arquitetura da plataforma de big data.No passado, eu fiz um planejamento de aplicativos de big data, que também é muito entrelaçado, porque a classificação do aplicativo também é vertical e horizontal, e ainda sinto que reflete um princípio "utilizável", claro e fácil de entender Pode orientar a construção, aqui a plataforma de big data é dividida em "cinco horizontais e uma vertical".
Para obter detalhes, consulte o exemplo abaixo: Esta imagem é mais clássica e é resultado de um comprometimento, podendo ser mapeada para muitos diagramas de arquitetura de big data na Internet.

De acordo com o fluxo de dados, ele é dividido em cinco camadas, de baixo para cima. Na verdade, é muito semelhante ao armazém de dados tradicional. Os sistemas de dados estão conceitualmente conectados. Eles são a camada de aquisição de dados, camada de processamento de dados, camada de análise de dados, camada de acesso a dados e aplicativos. Camada.
Ao mesmo tempo, a arquitetura da plataforma de big data é diferente do data warehouse tradicional no mesmo nível.Para atender a diferentes cenários, mais componentes técnicos serão adotados para refletir as características do florescimento das flores.
Camada de coleta de dados: inclui coleta offline tradicional de ETL, coleta em tempo real, análise de rastreador da Internet e assim por diante.
Camada de processamento de dados: de acordo com diferentes cenários de processamento de dados, ele pode ser dividido em HADOOP, MPP, processamento de fluxo, etc.
Camada de análise de dados: contém principalmente mecanismos de análise, como mineração de dados, aprendizado de máquina, aprendizado profundo, etc.
Camada de acesso a dados: trata-se principalmente de realizar a separação da leitura e gravação e remover os recursos de consulta orientados a aplicativos e de computação, incluindo consultas em tempo real, consultas multidimensionais, consultas convencionais e outros cenários de aplicativos.
Camada de aplicação de dados: de acordo com as características da empresa, diferentes tipos de aplicação são divididos: por exemplo, para os operadores, há marketing de precisão, reclamações de atendimento ao cliente, análise de estação base etc., fluxo de passageiros com base na localização, aplicativos de publicidade com base em etiquetas etc.
Gerenciamento de dados: este é um método vertical, principalmente para obter gerenciamento de dados, operação e manutenção, e abrange várias camadas para obter gerenciamento unificado.
1. Camada de coleta de dados
A coleta de lotes offline usa o HADOOP, que se tornou o principal mecanismo da coleta de linhas de fluxo atual.Com base nessa plataforma, aplicativos ou ferramentas de coleta de dados precisam ser implementados.
Por exemplo, o BAT é um produto desenvolvido por ela mesma. As empresas em geral podem usar a versão comercial. Agora, existem muitas opções para esse tipo, como Huawei BDI, etc. Muitas empresas têm forças técnicas, mas quando iniciam, geralmente têm um entendimento fraco dos cenários de aplicativos e trabalham com detalhes. Muito ruim, o que dificulta o atendimento dos requisitos dos produtos fabricados, como a falta de funções estatísticas, que é muito diferente da MTD.As empresas tradicionais devem ser cautelosas ao comprar esses produtos.
Ser capaz de criar e fabricar produtos é uma questão de duas esferas: é claro que as pequenas empresas de Internet também podem criar ferramentas de coleta úteis para si mesmas, mas é difícil abstrair e criar um produto real. Vantagem.
A aquisição em tempo real agora é padrão em plataformas de big data. Estima-se que o mainstream seja FLUME + KAFKA e, em seguida, combinado com processamento de fluxo + banco de dados em memória.Esta tecnologia é certamente confiável, mas essas coisas de código aberto são boas, mas quando ocorrem problemas O ciclo de resolução geralmente é mais longo.
Além de usar o FLUME, para obter a coleta em tempo real da tabela do banco de dados ORACLE, você também pode usar o OGG / DSG e outras tecnologias para obter a coleta de logs em tempo real, o que pode resolver o problema de carga do armazém de dados tradicional para desenhar em escala completa.
Os rastreadores gradualmente se tornaram o padrão para muitas empresas coletarem, porque os novos dados na Internet dependem principalmente deles, você pode obter muitas informações on-line através da análise da página da web, qual análise de opinião pública, classificação do site etc. É recomendável que toda empresa estabeleça um nível empresarial Se não estiver no planejamento da sua plataforma de big data, você pode pensar nisso: se não conseguir os dados, não há nada a dizer.
A construção de um centro de rastreamento de nível empresarial é bastante difícil, porque não apenas o rastreador é necessário, mas também o estabelecimento de URLs e bases de conhecimento de aplicativos, a necessidade de segmentação de palavras em chinês, classificação reversa e mineração de texto com base no texto da página da Web. Este conjunto é muito desafiador. Atualmente, existem muitos componentes de código aberto, como solr, lucent, Nutch, ES, etc., mas para usá-lo bem, o caminho é longo.
Outra coisa é, se possível, o autor recomenda atualizar a plataforma de coleta de dados para uma plataforma de troca de dados, porque, de fato, há muitos dados fluindo na empresa, não apenas a coleta de dados unidirecional, mas também muita troca de dados, como a necessidade do ORACLE Coloque dados no GBASE, no HBASE e no ASTER etc. Para o aplicativo, esse valor é ótimo.
Como a coleta de dados e a troca de dados têm muitas funções muito semelhantes, por que não integrá-lo também é conveniente para o gerenciamento unificado, sinto que muitas trocas de dados corporativos são orientadas por aplicativos, o gerenciamento de interface é confuso, essa também é minha sugestão.
Em geral, é muito difícil criar uma plataforma de coleta de grandes volumes de dados.Na perspectiva de um cliente, pelo menos os três requisitos a seguir devem ser atendidos:
Recursos diversificados de coleta de dados: suporte a coleta incremental de dados em tempo real (usando canal, fila de mensagens, OGG e outras tecnologias) e recursos de coleta distribuída de dados em lote (SQOOP, FTP VOER HDFS) para vários dados, como tabelas, arquivos, mensagens, etc. Há uma melhoria de ordem de magnitude no desempenho em relação ao ETL tradicional, o que é fundamental.
Capacidade de configuração rápida visual: fornece uma interface gráfica de desenvolvimento e manutenção, suporta o desenvolvimento de arrastar e soltar, livre de gravação de código e reduz a dificuldade de coleta.Cada interface de dados de configuração demora um pouco para reduzir os custos de mão-de-obra.
Recursos unificados de gerenciamento e controle de agendamento: para obter agendamento unificado de tarefas de coleta, ele pode oferecer suporte a vários componentes técnicos do Hadoop (como MapReduce, Spark, HIVE), procedimentos armazenados de banco de dados relacional, shell scripts, etc. e suporta várias estratégias de agendamento (notificação por tempo / interface / Manual).
2. Camada de processamento de dados
O HIVE do Hadoop é uma alternativa distribuída aos data warehouses tradicionais. Cenários como limpeza de dados, filtragem, conversão e resumo direto usados no ETL tradicional são adequados: quanto maior a quantidade de dados, maior o desempenho dos custos. Mas até agora, os cenários de análise de dados suportados também são limitados. A análise e o cálculo massivos offline simples são os melhores. Correspondentemente, a velocidade das operações complexas de correlação cruzada é muito lenta.
Até certo ponto, por exemplo, a tabela ampla de visão unificada dos clientes corporativos é relativamente ineficiente com o HIVE, porque envolve a integração de dados de várias partes, mas não é impossível fazê-lo.O mais lento, no máximo, ainda precisa ser equilibrado.
O Hadoop não suportava a escala dos clusters X000. Atualmente, o volume de dados de muitas empresas deve exceder esse valor. Além de empresas como Ali e seus próprios recursos de P&D (como ODPS), eles também devem migrar os clusters Hadoop de acordo com os negócios? Estradas como a Zhejiang Mobile dividiram vários clusters de hadoop, como rede fixa, rede móvel e inovação.
O Hadoop SPARK é muito adequado para a iteração do aprendizado de máquina, mas se pode ser aplicado à análise de correlação de dados em larga escala e se pode substituir o MPP até certo ponto, ainda é necessário praticar.
O MPP deve ser considerado a melhor alternativa aos data warehouses tradicionais, usando uma arquitetura distribuída, afinal, na verdade, é um banco de dados relacional de uma variedade, fornece suporte completo para SQL. Após a análise de conversão do HIVE, a fusão de data warehouses A modelagem é mais do que suficiente para usá-la para desempenho e seu desempenho em custo é melhor que o DB2 tradicional.Por exemplo, após o uso prático, os clusters Gbase30-40 podem exceder 2 IBM 780 montados na parte superior.
O MPP agora tem muitos produtos, é difícil julgar os méritos e os deméritos, mas alguns resultados práticos podem ser considerados: o GBASE é bom, muitos dos sistemas da empresa foram executados nele, principalmente serviços domésticos, garantia de serviço técnico é relativamente confiável, o ASTER ainda tem que esperar e ver, pois Trazer algumas bibliotecas de algoritmos tem algumas vantagens: o GreenPlum e o Vertica nunca foram usados, por isso é difícil dizer.
Dizem agora que o MPP será substituído pelo framework Hadoop. Afinal, como o SPARK e outros, gradualmente estáveis e maduros, mas, a curto prazo, acho que ainda é muito confiável. Se o data warehouse adotar um método de evolução progressiva , MPP é realmente uma boa escolha.
Agora, muitas empresas como a China Mobile e o eBAY estão adotando esse tipo de estrutura de mashup para se adaptar a diferentes cenários de aplicativos, o que é obviamente uma escolha natural.
A troika da plataforma de big data é indispensável para o processamento de fluxo.
Para muitas empresas, é obviamente uma existência semelhante a uma arma nuclear, e um grande número de cenários de aplicativos exige, por isso deve ser construída.Por exemplo, os cenários de data warehouse em tempo real e quase em tempo inimaginável na era IOE tornaram-se muito importantes no processamento de fluxo. É simples: costumava ser doloroso contar um indicador em tempo real antes.No momento, como um sistema antifraude em tempo real, o sistema é aplicado para implantação em um dia.
Eu tentei apenas o STORM e o IBM STREAM. Recomendo o IBM STREAM. Embora seja uma versão comercial, sua capacidade de processamento não é um pouco mais do que o STORM. Dizem que o STORM não é basicamente atualizado, mas, na verdade, a quantidade de dados não é grande. Tudo pode ser usado. De uma perspectiva, uma versão comercial como a IBM é uma boa escolha, mais do que suficiente para suportar vários cenários de aplicativos em tempo real.
Os clusters de processamento de fluxo usam a tecnologia de processamento de fluxo combinada com os bancos de dados na memória para processamento de dados em tempo real e quase em tempo real.Os clusters de processamento de fluxo IBM Streams realizam os negócios da empresa em tempo real:

3. Camada de análise de dados
Vamos falar primeiro da linguagem. R e Python são um par de amigos atuais no campo de código aberto da mineração de dados. Se eu quiser fazer uma escolha, não posso dizer. Sinto que o Python está mais inclinado à engenharia. Por exemplo, há suporte direto para segmentação de palavras e desenho de R. A capacidade é excepcionalmente poderosa. Mas eles costumavam se concentrar em estatísticas de amostra, portanto, o suporte a dados em larga escala é limitado.
O SPARK é uma opção.Recomenda-se usar o SPARK + scala.Afinal, o SPARK é escrito em scala e pode suportar rapidamente muitos recursos nativos.
O banco de dados MPP da TD, ASTER, também possui muitos algoritmos incorporados. Deve ser otimizado com base em uma arquitetura paralela. Parece ser uma opção. Eu fiz alguns graus de comunicação no passado. A velocidade é realmente muito rápida, mas o uso de dados é raro. Suporte.
Depois que as ferramentas tradicionais de mineração de dados não estão disponíveis, o SPSS agora possui o IBM SPSS Analytic Server, que fortalece o suporte ao big data hadoop, e a equipe de negócios usa feedback bom.
Talvez o aprendizado de máquina futuro também forme uma mistura de usuários altos e baixos, high-end que usam spark, usuários low-end usam SPSS, mas também para se adaptar a diferentes cenários de aplicativos.
De qualquer forma, a ferramenta é apenas uma ferramenta e, em última análise, depende da capacidade do engenheiro de modelagem de controlar.
4. Camada aberta de dados
Alguns engenheiros produzem diretamente o HIVE como uma consulta. Embora não seja razoável, também mostra que o cálculo e a consulta exigem recursos técnicos completamente diferentes. Mesmo no campo da consulta, diferentes tecnologias precisam ser selecionadas de acordo com diferentes cenários.
O HBASE é muito fácil de usar, com base no armazenamento de colunas, a velocidade da consulta está na faixa de milissegundos e também é uma alavanca para as consultas gerais de dezenas de bilhões de registros. Possui uma certa alta disponibilidade. A consulta detalhada da lista e a consulta da biblioteca de índices em nossa produção são muito boas. Cenários de aplicação. Mas a leitura de dados suporta apenas a leitura por chave ou intervalo de teclas, portanto, a chave de linha deve ser projetada.
O Redis é um banco de dados KV, e a velocidade de leitura e gravação é mais rápida que o HBASE.Na maioria das vezes, o HBASE pode fazer, o Redis também pode fazer, mas o Redis é baseado na memória, usada principalmente no cache de memória de valor-chave, existe a possibilidade de perda de dados, o atual Ele será usado para consultas em tempo real de tags.A maioria das empresas de Internet ou de publicidade que colaboraram no uso da tecnologia, mas se os dados estiverem aumentando, o HBASE é a única opção.
Além disso, aplicativos de consulta on-line em tempo real baseados em logs da Internet fornecidos pela IMPALA também estão sendo usados para implementar a análise de correlação SQL baseada em memória distribuída na plataforma de marketing usando SQLFire e GemFire.Embora a velocidade possa ser, mas existem muitos BUGs, o custo de introdução e transformação é relativamente grande .
Atualmente, o Kylin é uma ferramenta matadora, baseada na análise multidimensional do hadoop / SPARK.Há muitos cenários de aplicativos, e espero ter a oportunidade de usá-lo.
5. Camada de aplicação de dados
Cada empresa deve planejar seu próprio aplicativo de acordo com sua situação real. De fato, é difícil desenvolver um blueprint de aplicativo. Quanto maior a camada superior da arquitetura de big data, mais instável é porque a mudança é muito rápida. A seguir, é apresentado um plano de aplicativo geralmente usado pelos operadores no estágio atual. Figura para referência:

6. Gerenciamento de dados
O gerenciamento da plataforma de big data é dividido em gerenciamento de aplicativos e gerenciamento de sistemas. Do ponto de vista do aplicativo, por exemplo, estabelecemos a plataforma de gerenciamento visual do DACP, que pode se adaptar a 11 componentes da tecnologia de big data e obter transparência para vários componentes técnicos. Recursos de acesso, ao mesmo tempo através da plataforma, para alcançar todo o gerenciamento do ciclo de vida, desde o design, desenvolvimento até a destruição de dados, e os padrões, regras de qualidade e estratégias de segurança são solidificados na plataforma, para obter pré-gerenciamento, controle em processo e auditoria pós-auditoria, auditoria Gerenciamento abrangente de qualidade e gerenciamento de segurança.
Outros, como gerenciamento de agendamento, gerenciamento de metadados e gerenciamento da qualidade, é claro, nem é preciso dizer que, como a fonte do desenvolvimento é controlada, a complexidade do gerenciamento de dados será bastante reduzida.
Da perspectiva do gerenciamento de sistemas, a empresa incorpora a plataforma de big data em um gerenciamento unificado de plataforma de gerenciamento de nuvem (nuvem privada) .A plataforma de gerenciamento de nuvem inclui ferramentas visuais de operação e manutenção que oferecem suporte à implantação com um clique e implantação incremental, além de um sistema de controle e gerenciamento de recursos de computação orientado para vários inquilinos. (Gerenciamento multilocatário, gerenciamento de segurança, gerenciamento de recursos, gerenciamento de carga, gerenciamento de cotas e gerenciamento de medição) e um sistema abrangente de gerenciamento de direitos do usuário fornecem suporte à capacidade de operação da plataforma de big data em nível corporativo e gerenciamento de manutenção. Obviamente, esses objetivos ambiciosos devem ser alcançados. Um dia de trabalho.
Resuma alguns valores revolucionários da plataforma de big data.
Na era do big data, a arquitetura da maioria das empresas será inevitavelmente distribuída, escalável e diversificada.A chamada separação a longo prazo não é mais uma tecnologia que pode dominar o mundo.Isso afeta o modelo tradicional de terceirização de tecnologia das empresas centralizadas. Enorme.

Na era do big data e da computação em nuvem, existem tantos componentes de tecnologia e uma nova tecnologia deve ser adotada.Existem oportunidades e riscos:
Para a versão comercial da plataforma de big data, a empresa é confrontada com os serviços dos parceiros não pode acompanhar, porque o desenvolvimento é muito rápido, para a versão de código aberto, a empresa enfrenta o desafio de suas próprias capacidades de operação e manutenção e capacidades técnicas, requisitos mais práticos para capacidades autônomas Alto.
Atualmente, empresas como a BAT, a Huawei e a nova Internet estão varrendo os talentos.O desafio para talentos como operadores é enorme, mas também contém oportunidades.De fato, para aqueles que estão comprometidos com o big data Também é uma boa opção para se envolver com operadores e outras empresas, porque, por um lado, as empresas estão se transformando, por outro lado, o volume de dados é grande o suficiente e há mais oportunidades para o domínio da tecnologia.
