Big Data: Hbase

- O que é Hbase
O Hbase é um banco de dados NoSQL distribuído e extensível que suporta armazenamento massivo de dados, estrutura física de armazenamento (KV).
- Se não houver Hbase
Como retornar centenas de milhões de dados em segundos em um cenário de big data. (Condicional: dados únicos, dados de intervalo)
1 estrutura Hbase e tipo de dados
- Estrutura lógica
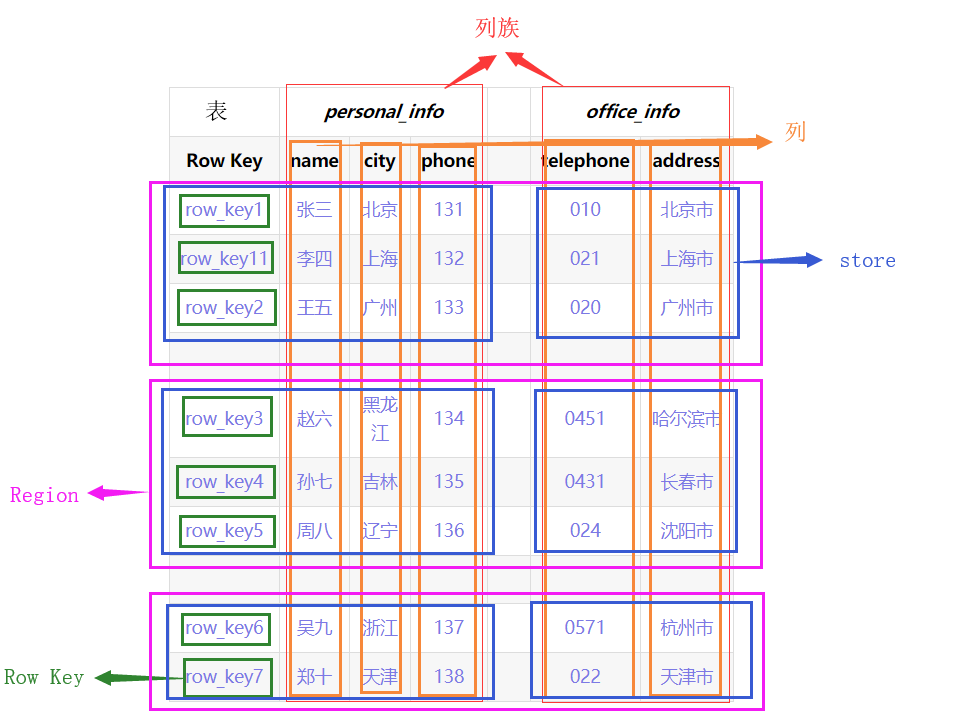
- Estrutura física
O relógio inteiro será cortado de acordo com a Chave da linha (região) na direção horizontal. Em seguida, pressione ColumnFamily para cortar (Store) na direção vertical,
-
Espaço de nome: espaço de nome
- Semelhante ao conceito de banco de dados em um banco de dados relacional, várias tabelas podem ser colocadas em cada espaço para nome e, por padrão, existem dois espaços para nome: hbase e padrão.O Hbase armazena as tabelas internas do Hbase.A tabela padrão é o espaço de nome padrão usado pelos usuários. (Por exemplo, o teste do espaço para nome é atribuído à tabela de pedidos, que pode ser escrita como teste: order)
-
Linha: Linha
- Cada linha de dados no Hbase consiste em uma RowKey e várias colunas.
-
Coluna: Coluna
- Cada coluna no Hbase é qualificada por ColumnFamily (família de colunas) e ColumnQualifier (qualificador de coluna) (por exemplo: personal_info: name, personal_info: city)
-
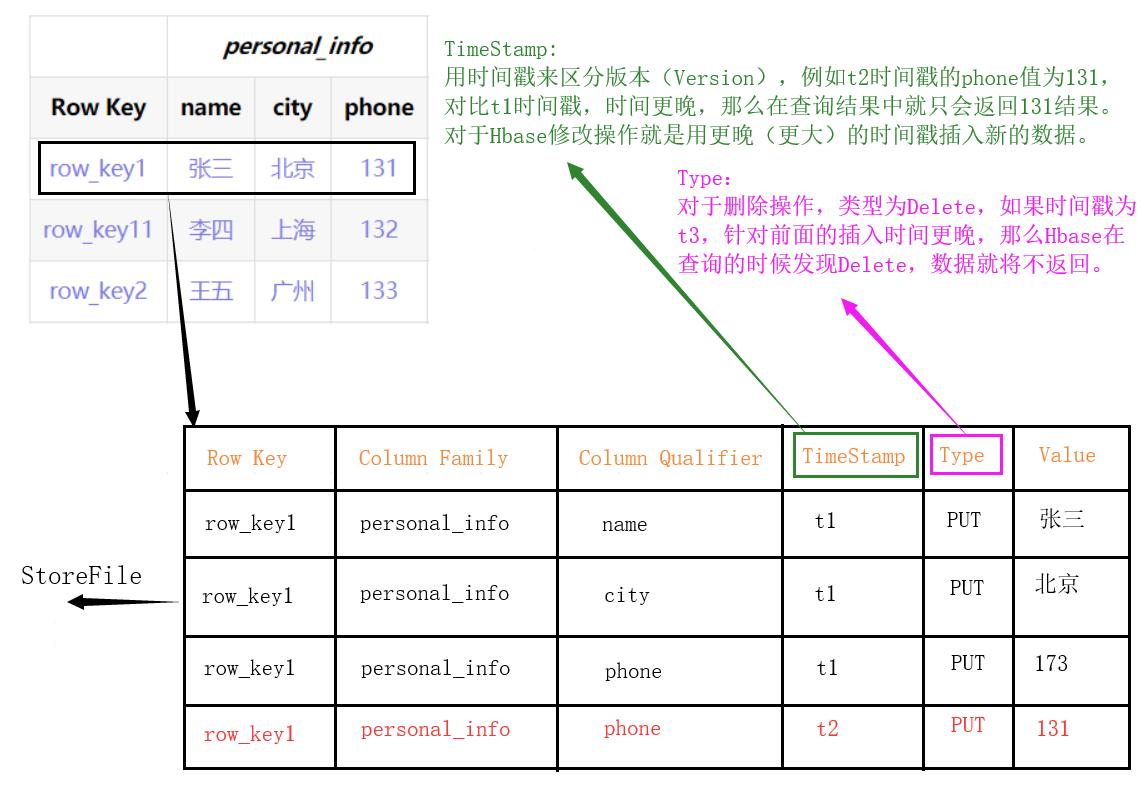
Cell: cell
- A unidade determinada exclusivamente por {RowKey, ColumnFamily, ColumnQualifier, TimeStamp}, os dados na célula não são digitados e todos são armazenados no código de bytes.
-
Chave de linha: Chave de linha
- A chave de linha deve ser exclusiva na tabela e deve existir.
- As chaves de linha são organizadas em ordem de acordo com a ordem lexicográfica (um valor é maior que nenhum valor). Por exemplo, row_key11 é organizado entre row_key1 e row_ley2.
- Todo o acesso à tabela deve passar pela Chave da Linha. (Acesso único ao RowKey ou acesso ao intervalo do RowKey ou verificação completa da tabela)
-
ColumnFamily: família de colunas
- Ao criar uma tabela Hbase, você só precisa especificar o CF. Ao inserir dados, as colunas (campos) podem ser aumentadas dinamicamente conforme necessário.
- Cada CF pode ter um ou mais membros da coluna (ColumnQualifier).
- Diferentes famílias de colunas são armazenadas em pastas diferentes em hdfs.
-
TimeStamp: timestamp
- Usado para identificar versões diferentes de dados.Se você não especificar um carimbo de data / hora, o Hbase adicionará automaticamente o carimbo de data / hora do sistema atual a esse valor de campo ao gravar dados.
Arquitetura 2 Hbase
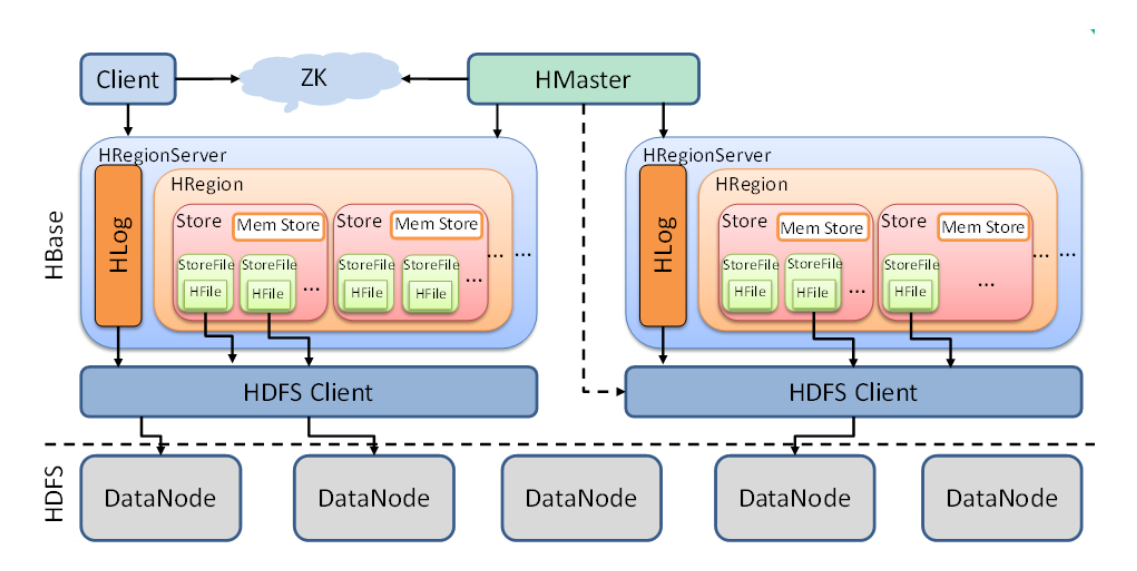
A seguir, são explicadas as funções dos componentes no diagrama acima, de pequenas a grandes.
-
StoreFile
- StoreFile é o arquivo que o HBase realmente armazena e, finalmente, armazenado no DataNode através do cliente HDFS. (Ou seja, no disco linux)
-
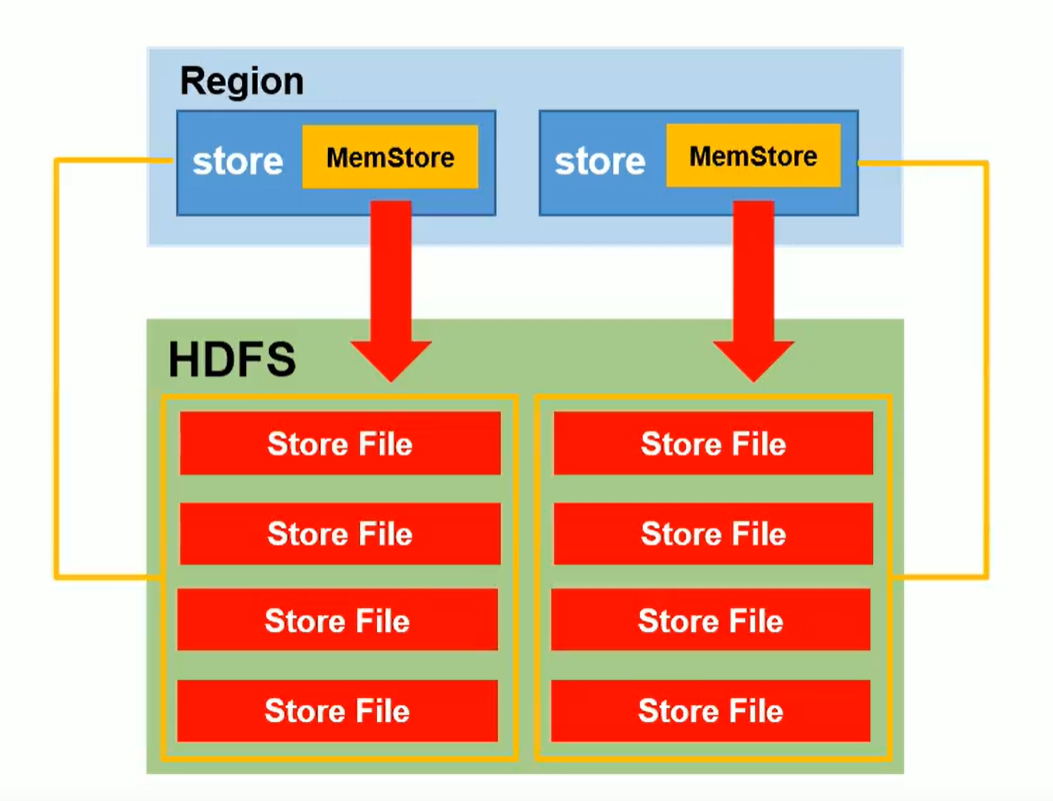
Loja
- Pode ser entendido como um conjunto de famílias de colunas em uma região fatiada. (Como mostrado acima, existem várias lojas em uma região)
- Store contém Mem Store (armazenamento de memória), StoreFile (dados piscaram na memória, mais serão mesclados e dados maiores serão divididos)
-
Região
- A região pode ser entendida como uma fatia de uma tabela.A região é dividida de acordo com o limite de tamanho dos dados e a chave de linha.
- O HBase divide automaticamente a tabela horizontalmente (por linha) em várias regiões (regiões), e cada região armazena dados contínuos em uma tabela.
- No início de cada tabela, existe apenas uma região. Com a inserção contínua de dados, a região continua a aumentar. Quando atingir um limite, a região será dividida em duas novas regiões, de acordo com a tecla Row, e assim por diante.
- À medida que o número de linhas na tabela aumenta, haverá mais e mais regiões e os dados de uma tabela serão salvos em várias regiões.
-
Amor
- O registro de pré-gravação do Hbase evita a perda de dados em circunstâncias especiais.
-
RegionServer
- Operações de dados (DML): obter, colocar, excluir
- Região de gerenciamento: SplitRegion (split), CompactRegion (mesclado)
-
mestre
- Operações no nível da tabela (DDL): criar, excluir, alterar
- Gerenciar RegionServer: monitore o status do RegionServer e atribua o RegionServer ao RegionServer (se houver máquinas rs1, rs2, rs3, os dados serão gravados na região em rs1, rs2, r3 estarão ociosos ---> então o rs1 será gravado muitos dados para atingir o limite superior da região, Depois que o rs1 dividir a região igualmente, ele notificará o mestre para enviar um deles para o rs3 para gerenciamento.)
3 Operação da linha de comando
3.1 Link hbase
- Link hbase
hbase shell
- Exibir comandos de ajuda ou usar comandos em detalhes
help
help '命令'
3.2 Operações de namespace
3.2.1 Consultar o espaço para nome
list_namespace

3.2.2 Consultar a tabela sob o namespace
list_namespace_tables '命名空间名'

3.2.3 Criar espaço para nome
create_namespace '命名空间名'

3.2.4 Excluir espaço para nome (requer que o espaço esteja vazio)
drop_namespace '命名空间名'
3.3 operação DDL
3.3.1 Consultar todas as tabelas de usuários
list
3.3.2 Criar tabela
create '命名空间:表', '列族1', '列族2', '列族3','列族4'... 
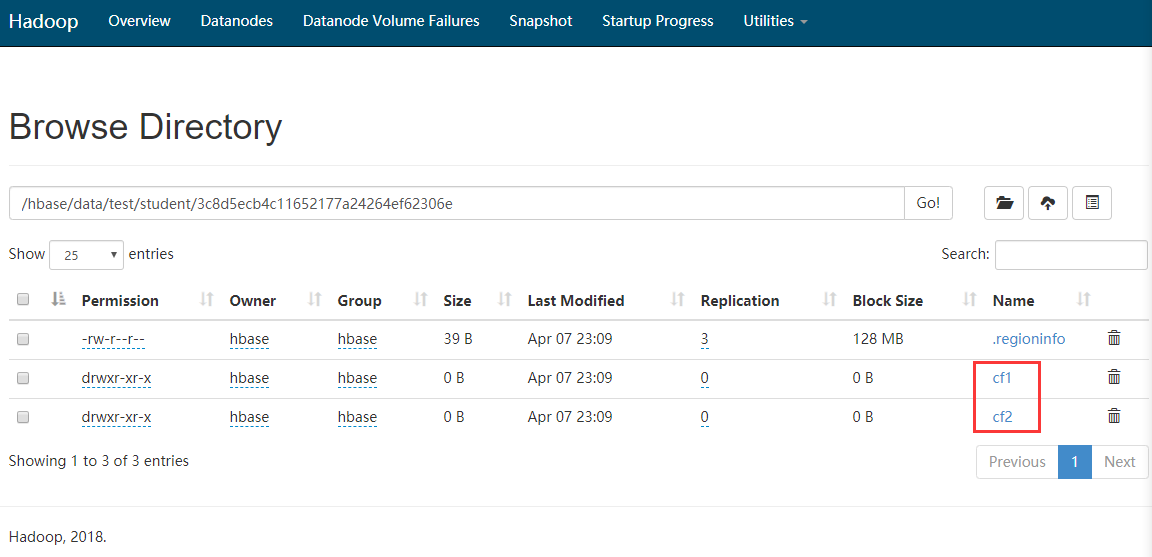
Como mostra a figura, há uma série de pastas fora de ordem.Esta série de pastas fora de ordem representa o número da região

3.3.3 Exibir detalhes da tabela
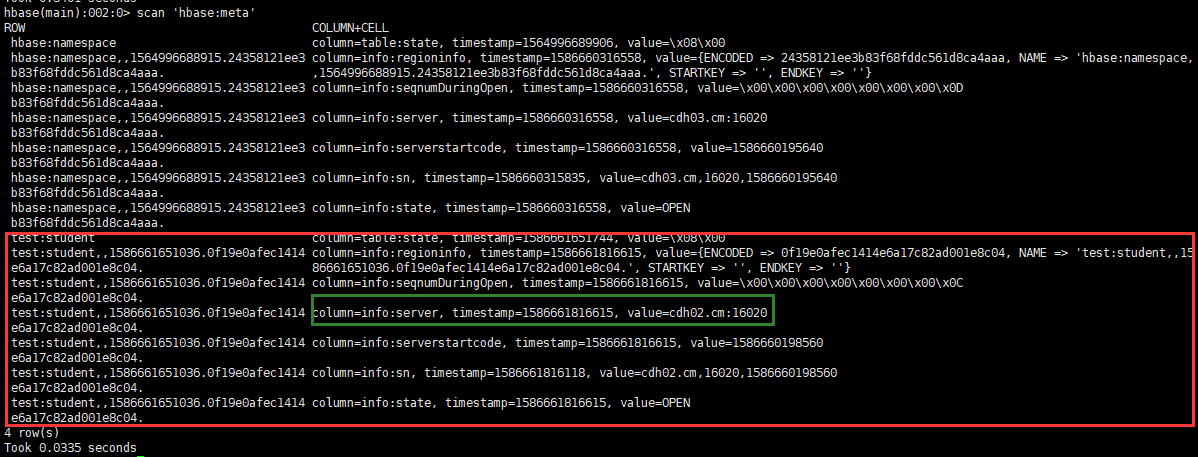
describe '命名空间:表'

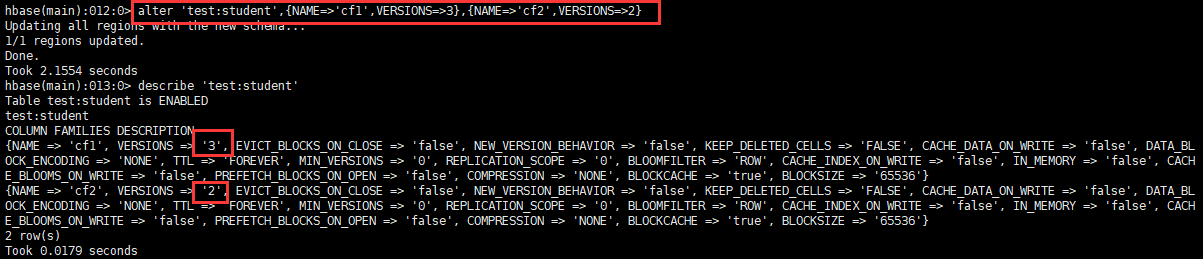
Pode-se observar que VERSIONS é 1, o que significa que esta tabela pode armazenar apenas uma versão dos dados.
3.3.4 Alterar informações da tabela
Ele é usado principalmente para modificar as informações de salvamento de versão da tabela e também pode ser especificado quando a tabela é criada, mas o comando shell é complicado, portanto o comando change geralmente é usado.
alter '命名空间:表',{NAME=>'列族名',VERSIONS=>3}

3.3.5 Modifique o status da tabela (a tabela deve ser inválida antes da exclusão)
- Tabela de falhas
disable '表'
- Ativar tabela
enable '表'
3.3.6 Excluir tabela
delete '表'
3.4 Operação DML
3.4.1 Inserindo dados
put '命名空间:表','RowKey','列族:列','值'
put '命名空间:表','RowKey','列族:列','值',时间戳(版本控制) 

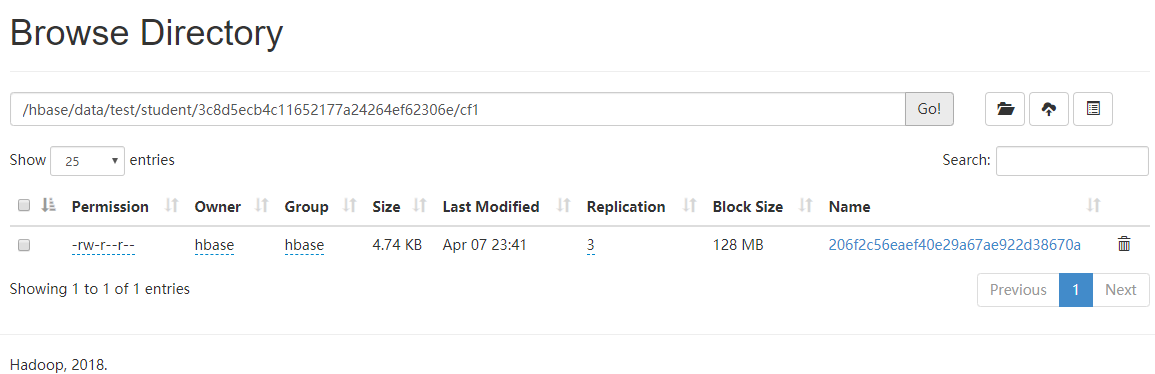
Conforme mostrado na figura, nenhum arquivo de dados é gerado, porque os dados estão na memória, você precisa liberar a 'tabela' e, em seguida, pode ver o desembarque dos dados. (Liberar é gerar um StoreFile uma vez)
3.4.2 Tabela de digitalização
#全表扫描
scan '命名空间:表'
#范围扫描(左闭右开)
scan '命名空间:表',{STARTROW => 'RowKey',STOPROW=>'RowKey'} #扫描N个版本的数据 scan '命名空间:表',{RAW=>true,VERSIONS=>10} 3.4.3 Flush
flush '命名空间:表'
- Mecanismo de retenção de versão de dados
Pelo exposto, sabe-se que liberar é gerar um StoreFile uma vez; os dados armazenarão os dados mais recentes de acordo com o número de versões da reserva da tabela.
Por exemplo: se o número de versões reservadas for 2, se você inserir três dados v1, v2, v3, após a liberação, restarão apenas dois dados v2, v3 e, em seguida, insira três dados v4, v5, v6, após a liberação, permanecendo Os dados a seguir são quatro versões das v2, v3, v5 e v6 (nesse caso, dois arquivos StoreFile) Se ocorrer uma mesclagem ou divisão de uma região, o arquivo StoreFile será mesclado e colocado na região correspondente. Ele será excluído de acordo com o número de versões reservadas e v2, v3, v5, v6 se tornará v5, v6. (Se não houver liberação manual ou o tempo de liberação automática definido, os dados não serão excluídos de acordo com o número de versões) (Por padrão, mais de 3 arquivos do StoreFile serão mesclados)
- Uma família de colunas corresponde a um MemStore
- Cada MemStore gera um StoreFile independente ao piscar no HDFS
- Horário de atualização global do RegionServer MemStore: hbase.regionserver.global.memstore.size
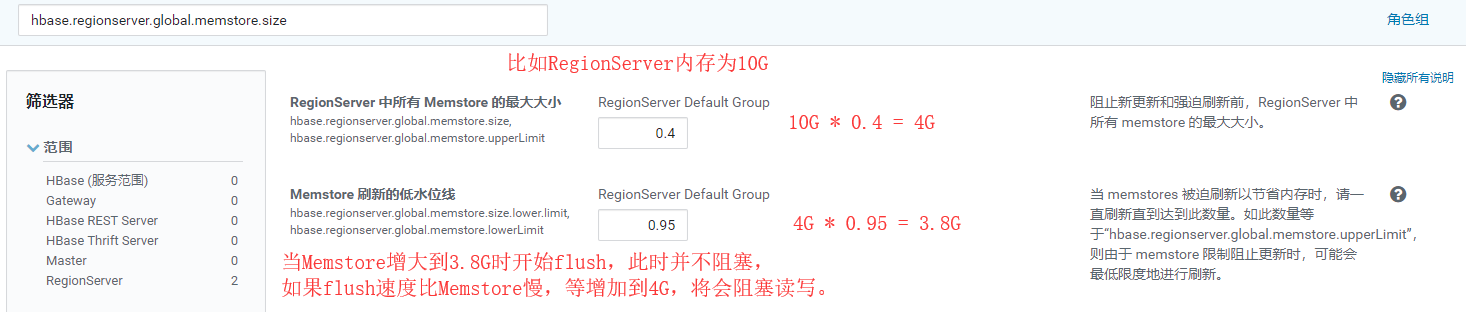
- Tempo de atualização do Memstore Único: hbase.hregion.memstore.flush.size

3.4.3 Dados da consulta
get '命名空间:表','RowKey'
get '命名空间:表','RowKey','列族' get '命名空间:表','RowKey','列族:列' #获取N个版本的数据 get '命名空间:表','RowKey',{COLUMN=>'列族:列',VERSIONS=>10} 
3.4.4 Esvazie a mesa
truncate '命名空间:表'
3.4.5 Excluir dados
#delete '命名空间:表','RowKey','列族'(此命令行删除有问题,但是API可以)
delete '命名空间:表','RowKey','列族:列'
deleteall '命名空间:表','RowKey' 4 Processo de leitura e escrita
4.1 Processo de escrita
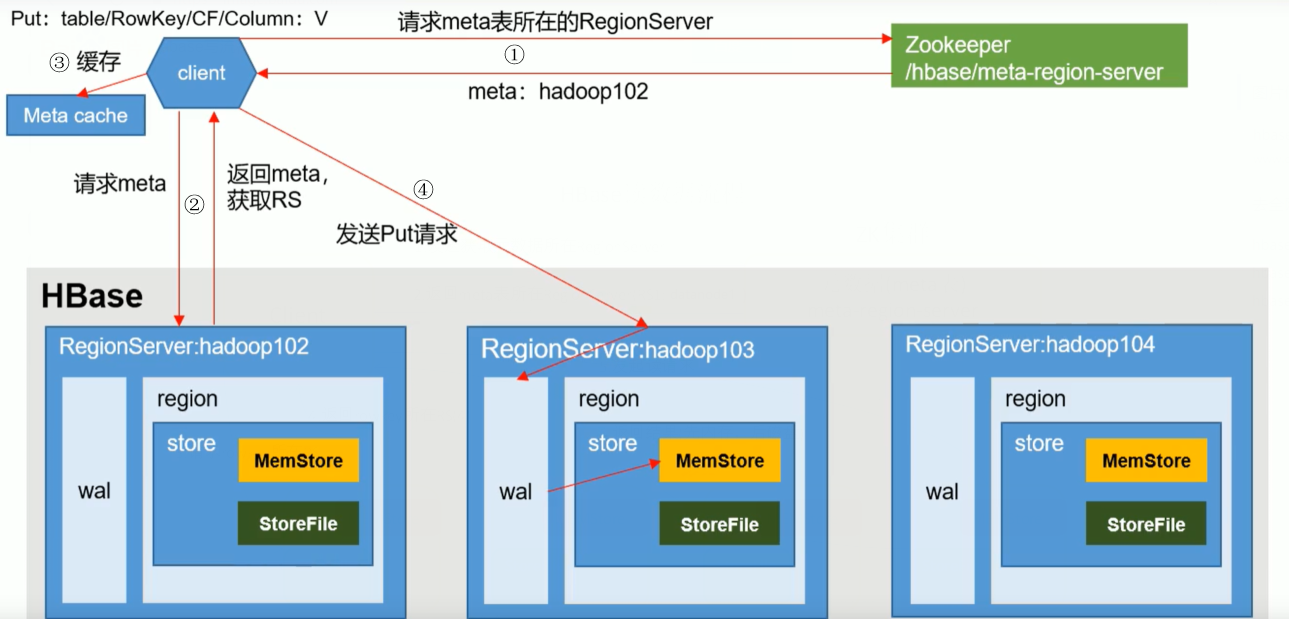
- O cliente consulta o local do RegionServer onde a tabela de armazenamento de metadados está localizada através do ZK e retorna


- Consulte metadados e retorne o RegionServer que precisa da tabela

-
O cliente armazena em cache as informações para facilitar o uso na próxima vez
-
Envie uma solicitação PUT ao RegionServer, escreva o log de operações (WAL) e, em seguida, escreva na memória, depois sincronize o wal com o HDFS e, em seguida, termine. (Nesta etapa, a transação é revertida para garantir que os logs e a memória sejam gravados com êxito)
4.2 Processo de leitura

Ao ler os dados, o MemStore e o StoreFile são lidos juntos, coloque os dados no StoreFile no BlockCache, mescle os dados da memória e o carimbo de data e hora do BlockCache e busque os dados mais recentes e retorne.
5 Mesclando e dividindo
- Compactação
Como o Memstore irá gerar um novo HFile toda vez que ele piscar, e diferentes versões e tipos diferentes do mesmo campo podem ser distribuídos em diferentes HFiles, portanto, é necessário percorrer todos os HFiles durante a consulta. Para reduzir o número de HFiles e limpar os dados expirados e excluídos, a mesclagem do StoreFile será realizada.
Compactação é dividida em Compactação Menor e Compactação Principal.
Compactação secundária mesclará vários HFiles menores adjacentes em um HFile maior, mas não limpará os dados expirados e excluídos.
A Compactação Principal mesclará todos os HFiles em um Armazenamento em um HFile grande e limpará os dados expirados e excluídos.
Configuração de parâmetro:
hbase.hregion.majorcompaction = 0
hbase.hregion.majorcompaction.jitter = 0
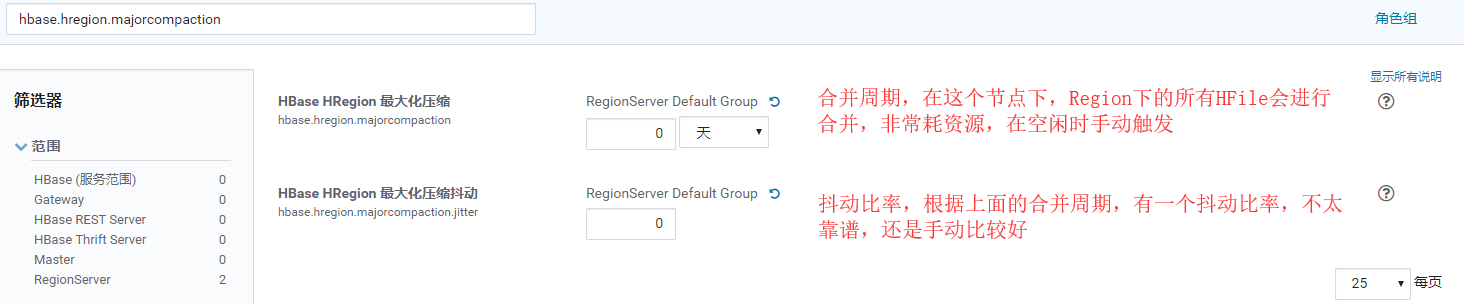
hbase.hstore.compactionThreshold = 3

- Split
Por padrão, existe apenas uma região no início de cada tabela. À medida que os dados continuam sendo gravados, a região será dividida automaticamente. Quando divididas, as duas sub-regiões estão localizadas no servidor de região atual, mas por considerações sobre o balanceamento de carga, o HMaster Uma região pode ser transferida para outro servidor de região.
Configuração de parâmetro:
hbase.hregion.max.filesize = 5G (Max1 na fórmula a seguir) (esse valor pode ser reduzido para aumentar a simultaneidade)
hbase.hregion.memstore.flush.size = 258M (Max2 na fórmula a seguir)
Cada divisão comparará o valor de Max1 e Max2, o que for menor. [min (Max1, Max2 * Número de regiões * 2)], onde o número de regiões é o número de regiões da tabela no atual servidor de região.
Como a segmentação automática não pode evitar pontos de acesso, geralmente usamos o pré-particionamento e o design do RowKey para evitar pontos de acesso na produção.


6 Otimização
6.1 Tente não usar várias famílias de colunas
Para evitar a geração de vários arquivos pequenos durante a descarga.
6.2 Otimização de memória

A principal função é armazenar em cache os dados da tabela, mas o GC será usado na descarga, não muito grande, de acordo com os recursos do cluster, geralmente aloca 70% de toda a memória do cluster Hbase, 16-> 48G é suficiente
6.3 Permitir conteúdo adicional no HDFS
dfs.support.append = true (hdfs-site.xml 、 hbase-site.xml)
6.4 Optimize DataNode permite o número máximo de arquivos abertos
dfs.datanode.max.transfer.threads = 4096 (HDFS 配置)
Em uma operação de mesclagem no nível do Region Server, o Region Server não está disponível.Você pode ajustar esse valor de acordo com os recursos do cluster para aumentar a simultaneidade.
6.5 Aumentar o número de monitores RPC
hbase.regionserver.handler.count = 30
De acordo com a situação do cluster, esse valor pode ser aumentado adequadamente, a principal decisão é o número de solicitações do cliente.
6.6 Otimizar cache do cliente
hbase.client.write.buffer = 100M (buffer de gravação)
Aumentar esse valor pode reduzir o número de chamadas RPC; o singular consumirá mais memória, definido de acordo com a situação dos recursos do cluster.
6.7 Otimização de mesclagem e segmentação
Referência 5 mesclar e dividir
6.8 Pré-partição
- Adicione o parâmetro SPLITS ao criar a tabela
create '命名空间:表', '列族1', '列族2', '列族3','列族4'...,SPLITS=>['分区号','分区号','分区号','分区号'] 
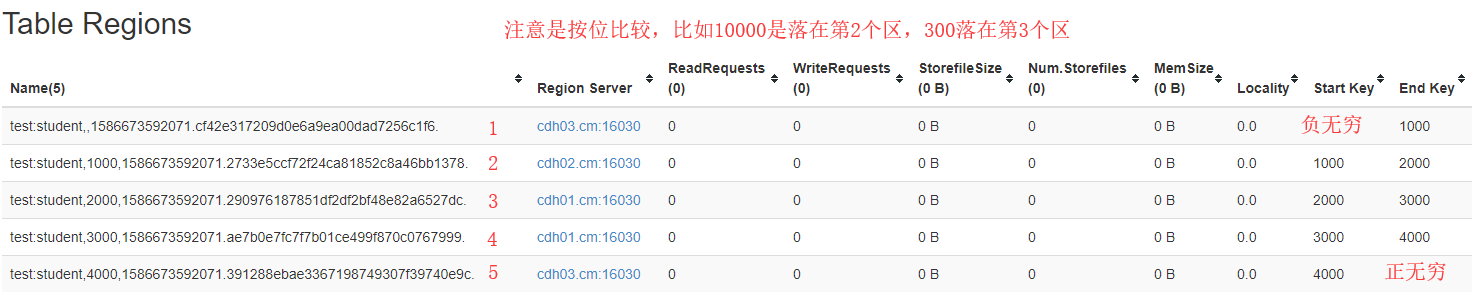
O número de pré-partições é selecionado com base na quantidade de dados estimada de meio ano a um ano e no valor máximo de Região.
6.9 RowKey
- Hashability: dividido uniformemente em diferentes regiões
- Exclusividade: não se repete
- Comprimento: 70-100
Opção 1: Números aleatórios, valores de hash, mas isso não pode ser consultado por intervalo e não há concentração de dados.
Opção 2: Inversão de string, por exemplo, a capacidade de hash é alcançada após o carimbo de data / hora ser invertido, mas a concentração é apenas melhor que a primeira na visualização.
- Plano de produção recomendado:
#设计预分区键(如比如200个区) | ASCLL码为124只有 } 和 ~ 比它大,那么不管以后的RowKey使用什么字符,都是小于这个字符的,所以可以有效的得到RowKey规律
000|
001|
......
199|
# 1 设计RowKey键_ASCLL码为95
000_
001_
......
199_
# 2 根据业务唯一标识(如用户ID,手机号,身份证)和时间维度(比如按月:202004)计算后根据分区数取余(13408657784^202004)%199=分区号
# 想以什么时间进行查询就把什么往前提,如下数据需要查1月数据范围就是 000_13408657784_2020-04 -> 000_13408657784_2020-04|
000_13408657784_2020-04-01 12:12:12
......
199_13408657784_2020-04-01 24:12:12