1 Visão geral

2 Classificando idéias
Um dia, Yichen realizou pôquer e jogou lá sozinho, e foi visto apenas pelo mestre.

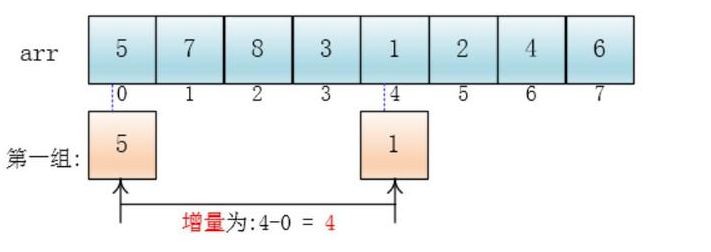
Primeiro, ele divide o conjunto de dados maior em vários grupos (agrupados logicamente) e, em seguida, insere e classifica cada grupo separadamente.Neste momento, a quantidade de dados inseridos e classificados é relativamente pequena (cada grupo) e a eficiência da inserção Relativamente alto


Pode-se ver que ele é um grupo com os subscritos separados por uma distância de 4 pontos, ou seja, os subscritos com diferença de 4. são divididos em um grupo.Por exemplo, neste exemplo a [0] e a [4] são um grupo 1] e a [5] são um grupo ..., onde a diferença (distância) é chamada de incremento
Depois que cada grupo é inserido e classificado, cada grupo é ordenado (o todo não é necessariamente ordenado)
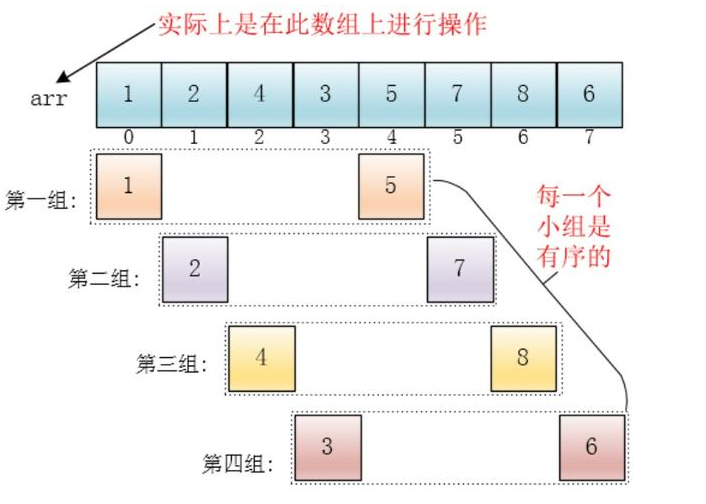
Nesse ponto, toda a matriz fica parcialmente ordenada (o grau de pedido pode não ser muito alto)
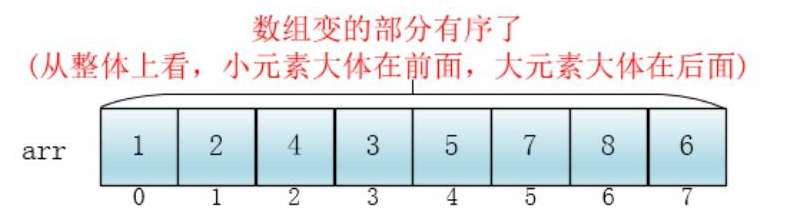
Em seguida, reduza o incremento para a metade do incremento anterior: 2, continue a dividir o agrupamento. Nesse momento, o número de elementos em cada agrupamento é maior, mas a parte da matriz é ordenada e a eficiência da classificação de inserção também é maior

Da mesma forma, classifique cada grupo (insira a classificação) para fazer cada pedido de grupo separadamente
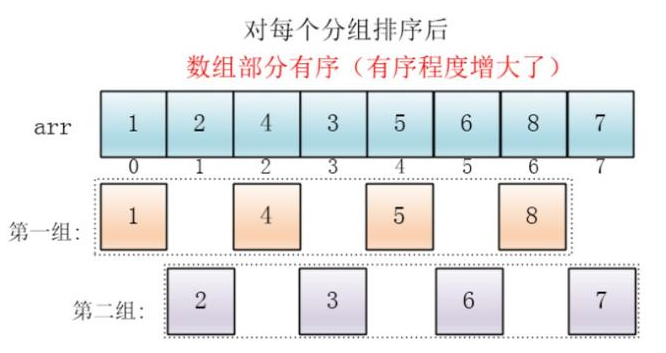
Por fim, defina o incremento para a metade do incremento anterior: 1, toda a matriz é dividida em um grupo; nesse momento, toda a matriz está próxima da ordem, a eficiência da ordenação por inserção é alta

Da mesma forma, classifique o único conjunto de dados, a classificação será concluída

3 Complexidade temporal
4 Derivação de classificação de colinas
// Derivação de classificação de colina public static void main (String [] args) { int [] arr = {5,7,8,3,1,2,4,6 }; shellSort (arr); } // use passo a passo Método de derivação public static void shellSort ( int [] arr) { // Hill classifica a primeira rodada de int temp; // Devido à primeira rodada de classificação, 8 dados são divididos em 4 grupos // a extensão é 4 para ( int i = 4; i <comprimento da matriz; i ++ ) { // percorre todos os elementos de uma variedade (um total de 5 grupos, 2 elementos em cada grupo) tamanho do passo 5 para ( int j = i-4; j> = 0; j - = 4) { // Se o elemento atual for maior que aquele após o tamanho da etapa, significa troca se (arr [j]> arr [j + 4 ]) { temp = arr [j]; arr [j] = arr [j + 4 ] ; ARR [J + 4.] = TEMP; } } } System.out.println ( "funcionamento 1 Ordenar resultados:" ); System.out.println (de Arrays.toString (RRA)); // Colina triagem 2 rodadas // Por causa da primeira rodada de classificação, 8 dados são divididos em 4/2 = 2 grupos // o intervalo é 2 para ( int i = 2; i <comprimento do arrimo; i ++) { // Atravessa todos os elementos em todos (um total de 2 grupos) Etapa 2 para ( int j = i-2; j> = 0; j- = 2 ) { // Se o elemento atual for maior que o passo Esse elemento explica a troca se (arr [j]> arr [j + 2 ]) { temp = arr [j]; arr [j] = arr [j + 2 ]; arr [j + 2] = temp; } } } System.out.println ( "O segundo resultado da classificação é:" ); System.out.println (Arrays.toString (arr)); // Classificação da colina rodada 3 //Devido à primeira rodada de classificação, os 10 dados são divididos em 2/2 = 1 grupos para ( int i = 1; i <comprimento da matriz; i ++ ) { // Atravessa todos os elementos em uma variedade (um total de 5 grupos, cada grupo 2 elementos) Tamanho da etapa 5 para ( int j = i-1; j> = 0; j- = 1 ) { // Se o elemento atual for maior que o elemento após o tamanho da etapa, troque se (arr [j]> arr [j + 1 ]) { temp = arr [j]; arr [j] = arr [j + 1 ]; arr [j + 1] = temp; } } } System.out.println ( "O terceiro resultado da classificação Para: " ); System.out.println (Arrays.toString (arr)); }
Resultados de derivação:

5 Método de troca para obter a classificação de Hill (o código é fácil de entender e lento)
// ********************** Exchange Method ************************** ******** // a análise anterior passo a passo, utilizando o ciclo de processamento do público estático vazio shellSort2 ( int [] RRA) { int temp; para ( int GAP = arr.Length / 2; GAP> 0; GAP / = 2 ) { for ( int i = gap; i <comprimento da arroba; i ++ ) { // percorre todos os elementos de uma variedade (total de 5 grupos, 2 elementos em cada grupo) etapa 5 para ( int j = i- gap; j> = 0; j- = gap) { // Se o elemento atual for maior que o elemento após o tamanho da etapa, isso significa troca se (arr [j]> arr [j + gap]) { temp = arr [j]; arr [j] = arr [j + gap]; arr [j + gap] = temp; } } } } }
Método 6 Shift para obter a classificação de Hill (o código é difícil de entender e rápido)
// ********************** Shift method ************************* ************* público estático vazio shellSort3 ( int [] RRA) { // incremento por um seu lacuna, onde os grupos de inserção de ordenação directos para ( int lacuna = arr.Length / 2; gap> 0; gap / = 2 ) { // A partir do elemento gap, insira e classifique os grupos um por um para ( int i = gap; i <comprimento da arroba; i ++ ) { int j = i; int temp = arr [j]; if (arr [j] <arr [j- gap]) { enquanto(j-gap> = 0 && temp <arr [j-gap ]) { // Move arr [j] = arr [j- gap]; j- = gap; } // Ao sair desse loop, dê temp Encontre a posição de inserção arr [j] = temp; } } } }
Teste de velocidade de classificação de 7 Hill
public static void main (String [] args) { // ********************* Teste de velocidade do método de troca de array em Hill ********* ********************** 888 int [] arr2 = novo int [8000000 ]; for ( int i = 0; i <arr2.length; i ++ ) { arr2 [i] = ( int ) (Math.random () * 800000 ); } // Exibe a matriz antes de classificar // System.out.println ("Selecione a matriz de teste de classificação:" + Arrays.toString (arr2)); SimpleDateFormat simpleDateFormat = new SimpleDateFormat ("aaaa-MM-dd HH: mm: ss" ); Date date1 = new Date (); String time1 = simpleDateFormat.format (date1); System.out.println ( "O tempo antes da classificação é:" + time1); // Método de troca de classificação Hill shellSort2 (arr2); // Método de mudança de ordenação em shell shellSort3 (arr2); Data date2 = new Date (); String time2 = simpleDateFormat.format (date2); System.out.println ( "O tempo após a classificação é:" + time2); }
Método de troca ----- resultado do teste de velocidade:
80.000 resultados de classificação de dados (método de troca) levam cerca de 10 segundos:
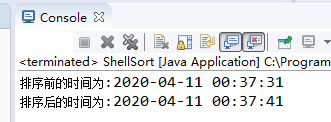
800.000 resultados de classificação de dados (método de troca) levam cerca de incontáveis segundos: (mal pode esperar pelos resultados)
Método de mudança ----- resultado do teste de velocidade:
80.000 resultados de classificação de dados (método shift) levam menos de 1 segundo:
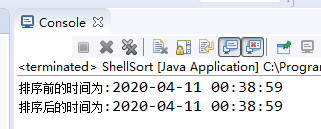
800.000 resultados de classificação de dados (método shift) levam menos de 1 segundo:
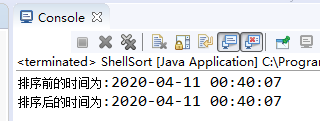
O resultado da classificação de 8 milhões de dados (método shift) leva menos de 3 segundos:
