Autor: chen_h
Micro Signal & QQ: 862251340
micro-channel número público: coderpai
Com Numpy ou Torch?
tocha alegando Numpy comunidade de rede neural, porque ele pode tocha tensor gerados na GPU acelerada computação (desde que você tem a GPU direita), como uma matriz Numpy na CPU irá acelerar as operações. Portanto, se a rede neural naturalmente, é a forma de um tensor de dados tocha de preferência ligeiramente. tensor Tensorflow como entre os mesmos.
Claro, nós ainda amamos o Numpy, porque estamos tão acostumados a formar uma numpy mas ver a nossa tocha favorito, a tocha que ele fez bem e compatibilidade numpy. Por exemplo, para que possa livremente converter variedade numpy e tocha tensor de:
import torch
import numpy as np
np_data = np.arange(6).reshape((2, 3))
torch_data = torch.from_numpy(np_data)
tensor2array = torch_data.numpy()
print(
'\nnumpy array:', np_data, # [[0 1 2], [3 4 5]]
'\ntorch tensor:', torch_data, # 0 1 2 \n 3 4 5 [torch.LongTensor of size 2x3]
'\ntensor to array:', tensor2array, # [[0 1 2], [3 4 5]]
)
Em matemática Torch
Na verdade, as operações de tensores e matriz numpy de exatamente a mesma tocha, estamos em forma de ponto de vista comparativo. Se você quer aprender tocha mais útil em outros operadores,
# abs 绝对值计算
data = [-1, -2, 1, 2]
tensor = torch.FloatTensor(data) # 转换成32位浮点 tensor
print(
'\nabs',
'\nnumpy: ', np.abs(data), # [1 2 1 2]
'\ntorch: ', torch.abs(tensor) # [1 2 1 2]
)
# sin 三角函数 sin
print(
'\nsin',
'\nnumpy: ', np.sin(data), # [-0.84147098 -0.90929743 0.84147098 0.90929743]
'\ntorch: ', torch.sin(tensor) # [-0.8415 -0.9093 0.8415 0.9093]
)
# mean 均值
print(
'\nmean',
'\nnumpy: ', np.mean(data), # 0.0
'\ntorch: ', torch.mean(tensor) # 0.0
)
variável
Variável no Torch é um local de armazenamento irá alterar o valor. O valor dentro mudando constantemente, assim como uma cesta carregada de ovos, número de ovos continuará a mudança. Quem é que os ovos dentro dela, então naturalmente é tocha da Tensor ligeiramente. Se um cálculo da variável, que é o retorno do mesmo tipo de uma variável.
Nós definimos uma variável:
import torch
from torch.autograd import Variable # torch 中 Variable 模块
# 先生鸡蛋
tensor = torch.FloatTensor([[1,2],[3,4]])
# 把鸡蛋放到篮子里, requires_grad是参不参与误差反向传播, 要不要计算梯度
variable = Variable(tensor, requires_grad=True)
print(tensor)
"""
1 2
3 4
[torch.FloatTensor of size 2x2]
"""
print(variable)
"""
Variable containing:
1 2
3 4
[torch.FloatTensor of size 2x2]
"""
Cálculo gradiente variável
Nós, então, comparar tensor cálculo e cálculo da variável.
t_out = torch.mean(tensor*tensor) # x^2
v_out = torch.mean(variable*variable) # x^2
print(t_out)
print(v_out) # 7.5
Até o momento, não vemos nada de diferente, mas lembre-se sempre, quando o cálculo variável, criou o sistema em um grande pano de fundo para trás um passo a passo em silêncio, o chamado gráfico computação, gráfico computacional. Este valor é usado para fazer o? originalmente toda a etapa de cálculo de tempo (nodos) estão ligados entre si, e finalmente a transmissão de erro inverso, que ao mesmo tempo todas as mudanças de amplitude variáveis (gradientes) são calculados, e o tensor que não têm essa capacidade.
v_out = torch.mean(variable*variable) É um passo calculado para adicionar a figura no cálculo, erro de cálculo quando há uma passagem inversa um crédito para ele, nós vamos dar-lhe um exemplo:
v_out.backward() # 模拟 v_out 的误差反向传递
# 下面两步看不懂没关系, 只要知道 Variable 是计算图的一部分, 可以用来传递误差就好.
# v_out = 1/4 * sum(variable*variable) 这是计算图中的 v_out 计算步骤
# 针对于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2
print(variable.grad) # 初始 Variable 的梯度
'''
0.5000 1.0000
1.5000 2.0000
'''
dados variáveis adquirida na
Dirigir print(variable)únicas formas variável de saída de dados, em muitos casos não é tomar (por exemplo, quer desenhar com PLT), por isso temos de convertê-lo, torna-se uma forma tensor.
print(variable) # Variable 形式
"""
Variable containing:
1 2
3 4
[torch.FloatTensor of size 2x2]
"""
print(variable.data) # tensor 形式
"""
1 2
3 4
[torch.FloatTensor of size 2x2]
"""
print(variable.data.numpy()) # numpy 形式
"""
[[ 1. 2.]
[ 3. 4.]]
"""
Tocha a função de activação
Função da tocha tem um monte de motivação, mas geralmente usamos para apenas alguns. relu, sigmoid, tanh, softplus. Então vemos que eles se parecem com seus amigos.
import torch
import torch.nn.functional as F # 激励函数都在这
from torch.autograd import Variable
# 做一些假数据来观看图像
x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
x = Variable(x)
Próxima geração é fazer uma função diferente de dados de excitação:
x_np = x.data.numpy() # 换成 numpy array, 出图时用
# 几种常用的 激励函数
y_relu = F.relu(x).data.numpy()
y_sigmoid = F.sigmoid(x).data.numpy()
y_tanh = F.tanh(x).data.numpy()
y_softplus = F.softplus(x).data.numpy()
# y_softmax = F.softmax(x) softmax 比较特殊, 不能直接显示, 不过他是关于概率的, 用于分类
Em seguida, começar a desenhar, desenho de código são os seguintes:
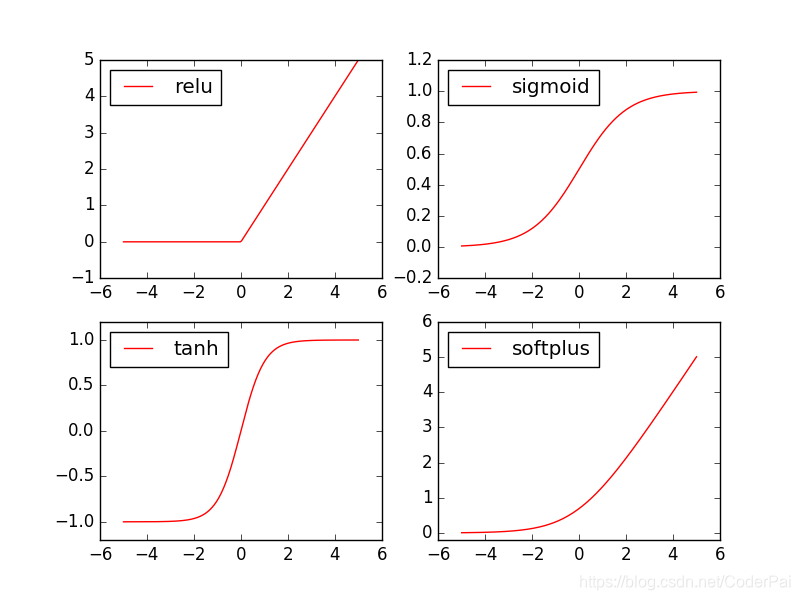
import matplotlib.pyplot as plt # python 的可视化模块, 我有教程 (https://morvanzhou.github.io/tutorials/data-manipulation/plt/)
plt.figure(1, figsize=(8, 6))
plt.subplot(221)
plt.plot(x_np, y_relu, c='red', label='relu')
plt.ylim((-1, 5))
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
plt.ylim((-0.2, 1.2))
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_np, y_tanh, c='red', label='tanh')
plt.ylim((-1.2, 1.2))
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_np, y_softplus, c='red', label='softplus')
plt.ylim((-0.2, 6))
plt.legend(loc='best')
plt.show()
link:
https://morvanzhou.github.io/tutorials/machine-learning/torch/
https://pytorch.org/docs/stable/torch.html
https://pytorch.org/docs/stable/torch.html
