Índice
A forma como o modelo PyTorch é definido
Comparação e Cenários Aplicáveis dos Três Métodos
Use nuggets de modelo para construir rapidamente redes complexas
Modelo de modificação do PyTorch
A forma como o modelo PyTorch é definido
conhecimento básico
- A classe Module é uma classe de construção de modelo (nn.Module) fornecida no módulo arch.nn.É a classe base de todos os módulos de rede neural e pode ser herdada para definir o modelo;
- A definição do modelo PyTorch deve incluir: inicialização de cada parte (__init__); definição do fluxo de dados (avançar)
Com base em nn.Module, os modelos PyTorch podem ser definidos de três maneiras: Sequential, ModuleList e ModuleDict.
Sequencial
O módulo correspondente é nn.Sequential(). Quando o cálculo forward do modelo é o cálculo de simplesmente concatenar cada camada, a classe Sequential pode definir o modelo de forma mais simples. Ele pode aceitar um dicionário ordenado de submódulos (OrderedDict) ou uma série de submódulos como parâmetros para adicionar instâncias de Módulos uma a uma, e o cálculo direto do modelo é calcular essas instâncias uma a uma na ordem de adição.
class MySequential(nn.Module):
from collections import OrderedDict
def __init__(self, *args):
super(MySequential, self).__init__()
if len(args)==1 and isinstance(args[0], OrderedDict):
#如果传入的是一个OrderedDict
for key, module in args[0].items():
self.add_module(key, module)
# add_module方法会将module添加进self._modules(一个OrderedDict)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def forward(self, input):
# self._modules返回一个OrderedDict,保证会按照成员添加顺序遍历成
for module in self._modules.values():
input = module(input)
return inputUsando Sequential para definir um modelo só precisa organizar as camadas do modelo em ordem. De acordo com os diferentes nomes de camada, existem duas maneiras de organizar:
#直接排列
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)
#使用OrderedDict
import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)A vantagem de usar o Sequential para definir o modelo é que ele é simples e fácil de ler, não sendo necessário escrever adiante, pois a sequência já está definida. Porém, usar o Sequencial fará com que a definição do modelo perca flexibilidade, por exemplo, quando uma entrada externa precisa ser adicionada no meio do modelo, não é adequado implementá-lo no modo Sequencial.
ModuleList
O módulo correspondente é nn.ModuleList(). ModuleList aceita uma lista de submódulos como entrada e também pode anexar e estender operações. Ao mesmo tempo, os pesos dos submódulos ou camadas são adicionados automaticamente à rede.
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net.append(nn.Linear(256, 10))
print(net[-1])
print(net)nn.ModuleList não define a rede, mas armazena diferentes módulos juntos.
A ordem dos elementos na ModuleList não representa sua real ordem de posição na rede, e a definição do modelo só é concluída após a especificação da ordem de cada camada através da função forward. A implementação específica pode ser concluída com um loop for
class model(nn.Module):
def __init__(self, ...):
super().__init__()
self.modulelist = ...
...
def forward(self, x):
for layer in self.modulelist:
x = layer(x)
return xModuleDict
O módulo correspondente é nn.ModuleDict(), que facilita a adição de nomes às camadas da rede neural.
net = nn.ModuleDict({
'linear':nn.Linear(784, 256),
'act':nn.ReLU(),
})
net['output'] = nn.Linear(256, 10)
print(net['linear'])
print(net.output)
print(net)Comparação e Cenários Aplicáveis dos Três Métodos
Sequencial é adequado para resultados de verificação rápida, sem escrever __init__ e encaminhar ao mesmo tempo;
ModuleList e ModuleDict podem ser "uma linha no máximo" quando uma determinada camada idêntica precisa ser repetida várias vezes;
Quando as informações da camada anterior são necessárias, como o cálculo residual em ResNets, os resultados da camada atual precisam ser fundidos com os resultados da camada anterior, geralmente usando ModuleList/ModuleDict.
Use nuggets de modelo para construir rapidamente redes complexas
Quando a profundidade do modelo é muito grande, usar Sequential para definir a estrutura do modelo requer adicionar centenas de linhas de código a ele, o que não é muito conveniente de usar. Para a maioria das estruturas de modelo, embora o modelo tenha muitas camadas, existem muitas estruturas recorrentes nele. Considerando que cada camada possui uma entrada e uma saída, um módulo composto por várias camadas em série também possui sua entrada e saída. Se essas camadas recorrentes forem definidas como um "módulo", cada vez que você só precisa adicionar o módulo correspondente à rede para construir o modelo, isso facilitará muito o processo de construção do modelo.
Esta seção usa o U-Net como um exemplo para introduzir como construir blocos de modelo e como usar blocos de modelo para construir rapidamente modelos complexos.
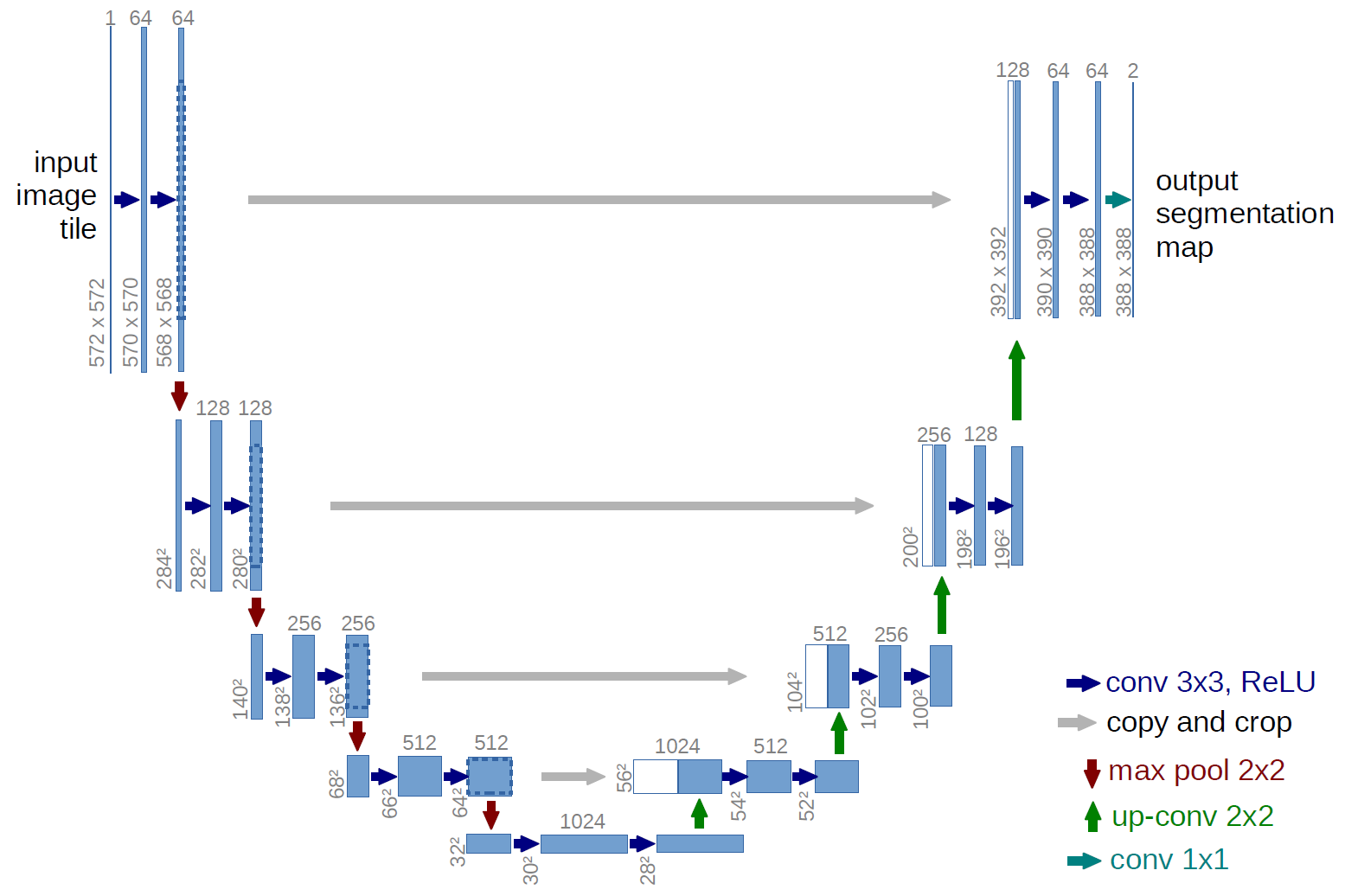
U-Net é uma obra-prima do modelo de segmentação, que resolve o problema de regressão no aprendizado do modelo por meio da estrutura de conexão residual, para que a profundidade da rede neural possa ser continuamente expandida.
Análise do modelo: O modelo é dividido em várias camadas de cima para baixo, cada camada é composta por dois blocos modelo à esquerda e à direita, e há conexões entre os blocos modelo de cada lado e os blocos modelo superior e inferior; os modelos nos lados esquerdo e direito da mesma camada ao mesmo tempo. Também existem conexões entre os blocos, chamadas de 'conexões de salto'. Existem também outros componentes, como processamento de entrada e saída.
Os blocos do modelo que compõem o U-Net incluem principalmente a dupla convolução (Double Convolution) dentro de cada sub-bloco, a conexão de downsampling entre os blocos do modelo esquerdo, ou seja, Maxpooling, e o uplink entre os blocos do modelo direito. -sampling) e processamento da camada de saída. Além dos blocos do modelo, existem cálculos como a conexão horizontal entre os blocos do modelo, a conexão entre a entrada e a parte inferior da U-Net, e essas operações individuais podem ser realizadas por meio da função de encaminhamento.
Código:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
# (convolution => [BN] => ReLU) * 2
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mie_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
# Downscaling with maxpool then double conv
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
# Upscaling then double conv
def __init__(self, in_channels, out_channels, bilinear=False):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels//2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX//2, diffX-diffX//2, diffY//2, diffY-diffY//2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024//factor)
self.up1 = Up(1024, 512//factor, bilinear)
self.up2 = Up(512, 256//factor, bilinear)
self.up3 = Up(256, 128//facotr, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logins
Modelo de modificação do PyTorch
modificar camada de modelo
Tomando como exemplo o modelo pré-definido ResNet50 da biblioteca de visão oficial da Pytroch, Torchvision, explore como modificar uma determinada camada ou várias camadas do modelo.
import torch vision.models as models
net = models.resnet50()
print(net)ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
..............
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)A estrutura do modelo aqui é para se adaptar ao peso do pré-treinamento do ImageNet, de modo que o nó de saída da última camada totalmente conectada (fc) seja 1000. Suponha que você queira usar resnet para fazer 10 classificações, você deve modificar a camada fc do modelo e substituir o número de nós de saída por 10. Além disso, é necessária uma camada adicional totalmente conectada.
from collections import OrderedDict
classifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(2048, 128)),
('relu1', nn.ReLU()),
('dropout1', nn.Dropout(0.5)),
('fc2', nn.Linear(128, 10)),
('output', nn.Softmax(dim=1))
]))
net.fc = classifierA operação final equivale a substituir a última camada do modelo (rede) denominada 'fc' por uma estrutura denominada 'classificador'. O modelo modificado pode executar 10 tarefas de classificação.
Adicionar entrada externa
No treinamento do modelo, além da entrada do modelo existente, informações adicionais precisam ser inseridas. A ideia básica é: pegue a parte do modelo original antes de adicionar a posição de entrada como um todo e, ao mesmo tempo, defina a relação de conexão entre a parte inalterada do modelo original, a entrada adicionada e a camada subsequente na frente, para completar a modificação do modelo.
Com base no modelo resnet50 do archvision, a tarefa ainda é classificada em 10; a diferença é que, usando a estrutura do modelo existente, uma variável de entrada adicional add_variable é adicionada à penúltima camada para auxiliar na previsão.
class Model(nn.Module):
def __init__(self, net):
super(Model, self).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc_add = nn.Linear(1001, 10, bias=True)
self.output = nn.Softmax(dim=1)
def forward(self, x, add_variable):
x = self.net(x)
x = torch.cat((self.dropout(self.relu(x)), add_variable.unsqueeze(1)),1)
x = self.fc_add(x)
x = self.output(x)
return xO ponto principal da implementação é realizar a emenda do tensor por meio do arch.cat.
A saída resnet50 no archvision é um tensor de 1000 dimensões. Ao modificar a função de encaminhamento, primeiro passe o tensor de 1000 dimensões através da camada de função de ativação e da camada de abandono e, em seguida, una-o com a variável de entrada externa "add_variable" e, finalmente, mapeá-lo para a dimensão de saída especificada 10.
Além disso, a operação de descompressão da variável de entrada externa "add_variable" é para manter a mesma dimensão que a saída do tensor por rede. É frequentemente usada quando add_variable é um valor único (escalar). Neste momento, a dimensão de add_variable é (batch_size, ), que precisa estar na segunda dimensão Supplement dimension 1, para que a operação do arch.cat possa ser realizada com o tensor.
Em seguida, instanciar a estrutura do modelo modificado
import torchvision.models as models
net = models.resnet50()
model = Model(net).cuda()Durante o treinamento, duas entradas são necessárias ao inserir dados:
outputs = model(input, add_var)adicionar saída extra
No treinamento do modelo, além da saída final do modelo, é necessário produzir o resultado de uma certa camada intermediária do modelo, e supervisão adicional foi aplicada para obter melhores resultados da camada intermediária. A ideia básica é modificar a variável de retorno da função forward na definição do modelo.
class Model(nn.Module):
def __init__(self, net):
super(Model, self).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(1000, 10, bias=True)
self.output = nn.Softmax(dim=1)
def forward(self, x, add_variable):
x1000 = self.net(x)
x10 = self.dropout(self.relu(x1000))
x10 = self.fc1(x10)
x10 = self.output(x10)
return x10, x1000Depois de instanciar a estrutura do modelo modificado, ela pode ser usada
import torchvision.models as models
net = models.resnet50()
model = Model(net).cuda()Existem duas saídas após os dados de entrada no treinamento:
out10, out1000 = model(inputs, add_var)Salvamento e leitura do modelo PyTorch
Formato de armazenamento do modelo
Use principalmente pkl, pt, pth três formatos.
Conteúdo de armazenamento do modelo
Um modelo PyTorch consiste principalmente em duas partes: estrutura do modelo e peso, onde o modelo é uma classe herdada de nn.module, e a estrutura de dados do peso é um dicionário (a chave é o nome da camada, o valor é o vetor de peso). Existem dois tipos de armazenamento: armazenar todo o modelo e armazenar apenas os pesos do modelo.
import torchvision import models
model = models.resnet152(pretrained=True)
torch.save(model, save_dir)#保存整个模型
torch.save(model.state_dict, save_dir)#保存模型权重Para PyTorch, os três formatos de dados de pt, pth e pkl suportam o armazenamento do peso do modelo e de todo o modelo, portanto, não há diferença no uso.
A diferença entre o armazenamento de modelo de cartão único e multicartão
Há duas maneiras de colocar o modelo e os dados na GPU no PyTorch: .cuda() e .to(device). Se você usar o treinamento de vários cartões, precisará usar o arch.nn.DataParallel para o modelo.
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #如果是多卡改成类似0,1,2
model = model.cuda() #单卡
model = torch.nn.DataParallel(model).cuda() #多卡Discussão situacional
Devido às diferentes condições de hardware usadas para treinamento e teste, problemas como incompatibilidade de modelo podem ocorrer devido a diferenças em ambientes de GPU única e multi-GPU durante o salvamento e carregamento do modelo. Aqui, o problema de salvar e carregar modelos sob o cartão único/vários cartões sob a estrutura PyTorch é organizado e combinado. O modelo de amostra é o modelo pré-treinado resnet152 no Torchvision.
- Salvamento de cartão único e carregamento de cartão único
import os, torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0'#这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
#保存+读取整个模型
torch.save(model, save_dir)
loaded_model = torch.load(save_dir)
loaded_model.cuda()
#保存+读取模型权重
torch.save(model.state_dict(), save_dir)
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152()
loaded_model.state_dict = loaded_dict
loaded_model.cuda()
- Economia de cartão único + carregamento de vários cartões
import os, torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
model = models.resnet152(pretrained=True)
model.cuda()
#保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2'
loaded_model = torch.load(save_dir)
loaded_model = nn.DataParallel(loaded_model).cuda()
#保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2'# 替换成希望使用的GPU编号
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152()# 注意这里需要对模型结构有定义
loaded_model.state_dict = loaded_dict
loaded_model = nn.DataParallel(loaded_model).cuda()- Economia de vários cartões + carregamento de cartão único
O problema central é como remover o "módulo" no nome da chave do dicionário de pesos para garantir a unidade do modelo.
Para carregar o modelo inteiro, basta extrair o atributo do módulo do modelo diretamente
import os, torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir)
loaded_model = loaded_model.modulePara carregar os pesos do modelo, existem várias ideias:
É mais problemático remover o módulo no dicionário, mas é fácil adicionar o módulo ao modelo
import os, torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2'
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
#保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152()
loaded_model = nn.DataParallel(loaded_model).cuda()
loaded_model.state_dict = loaded_dictPercorra o dicionário para remover o módulo
from collections import OrderedDict
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
loaded_dict = torch.load(save_dir)
new_state_dict = OrderedDict()
for k, v in loaded_dict.items():
name = k[7:] # module字段在最前面,从第7个字符开始就可以去掉module
new_state_dict[name] = v # 新字典的key值对应的value一一对应
loaded_model = models.resnet152()
loaded_model.state_dict = new_state_dict
loaded_model = loaded_model.cuda()Use a operação de substituição para remover o módulo
loaded_model = models.resnet152()
loaded_dict = torch.load(save_dir)
loaded_model.load_state_dict({k.replace('module.',''): v for k, v in loaded_dict.items()})- Economia de vários cartões + carregamento de vários cartões
Uma vez que o cartão múltiplo é usado tanto para salvar quanto para carregar o modelo, não há problema de diferentes prefixos de nomes de camadas do modelo. No entanto, existe um problema de correspondência do dispositivo (GPU usado) no estado multi-card, ou seja, ao salvar o modelo inteiro , informações como o id da GPU usada serão salvas ao mesmo tempo. informações de GPU usadas atualmente durante a leitura, um erro pode ser relatado ou o programa não funciona conforme o esperado. Especificamente, os dois pontos a seguir:
Leia todo o modelo e use nn.DataParallel para configurações de treinamento distribuído
Essa situação provavelmente causa uma discrepância entre o ID da GPU no modelo salvo e o ID da GPU definido no ambiente de leitura, e o dispositivo onde os dados estão localizados é inconsistente com o dispositivo onde o modelo está localizado durante o treinamento, resultando em um erro.
Leia o modelo inteiro sem usar nn.DataParallel para configuração de treinamento distribuído
Neste caso, um erro pode não ser reportado. Durante o teste, foi constatado que o programa utilizará automaticamente as primeiras n GPUs do dispositivo para treinamento (n é a quantidade de GPUs utilizadas pelo modelo salvo). Neste momento, se o número de GPUs especificado for menor que n, um erro será relatado. Neste caso, somente se o id do dispositivo do ambiente ao salvar o modelo for igual ao id do dispositivo do ambiente ao ler o modelo, o programa executará o treinamento distribuído na GPU especificada conforme o esperado.
Por outro lado, ler os pesos do modelo e, em seguida, usar nn.DataParallel para uma configuração de treinamento distribuído não é problema. Portanto, no modo multicartão, é recomendável usar o método de peso para armazenar e ler o modelo :
import os, torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2'
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
#保存+读取模型权重,强烈建议!!
torch.save(model.state_dict(), save_dir)
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152()
loaded_model = nn.DataParallel(loaded_model).cuda()
loaded_model.state_dict = loaded_dictSe você tiver apenas o modelo inteiro salvo, também poderá criar um novo modelo extraindo pesos:
#读取整个模型
loaded_whole_model = torch.load(save_dir)
loaded_model = models.resnet152()
loaded_model.state_dict = loaded_whole_model.state_dict
loaded_model = nn.DataParallel(loaded_model).cuda()Além disso, todas as formas de modificar o dicionário de peso para o Load_model são realizadas por atribuição e também podem ser realizadas pela função "load_state_dict" no PyTorch:
loaded_model.load_state_dict(loaded_dict)Anexo: Ambiente de teste SO: Ubuntu 20.02 LTS GPU: GeForce RTX 2080 Ti(x3)