셀레늄을 사용하여 채용 데이터 얻기
GCC 학생들은 표절할 필요가 없습니다!
배경
。。。
페이지 가져오기:
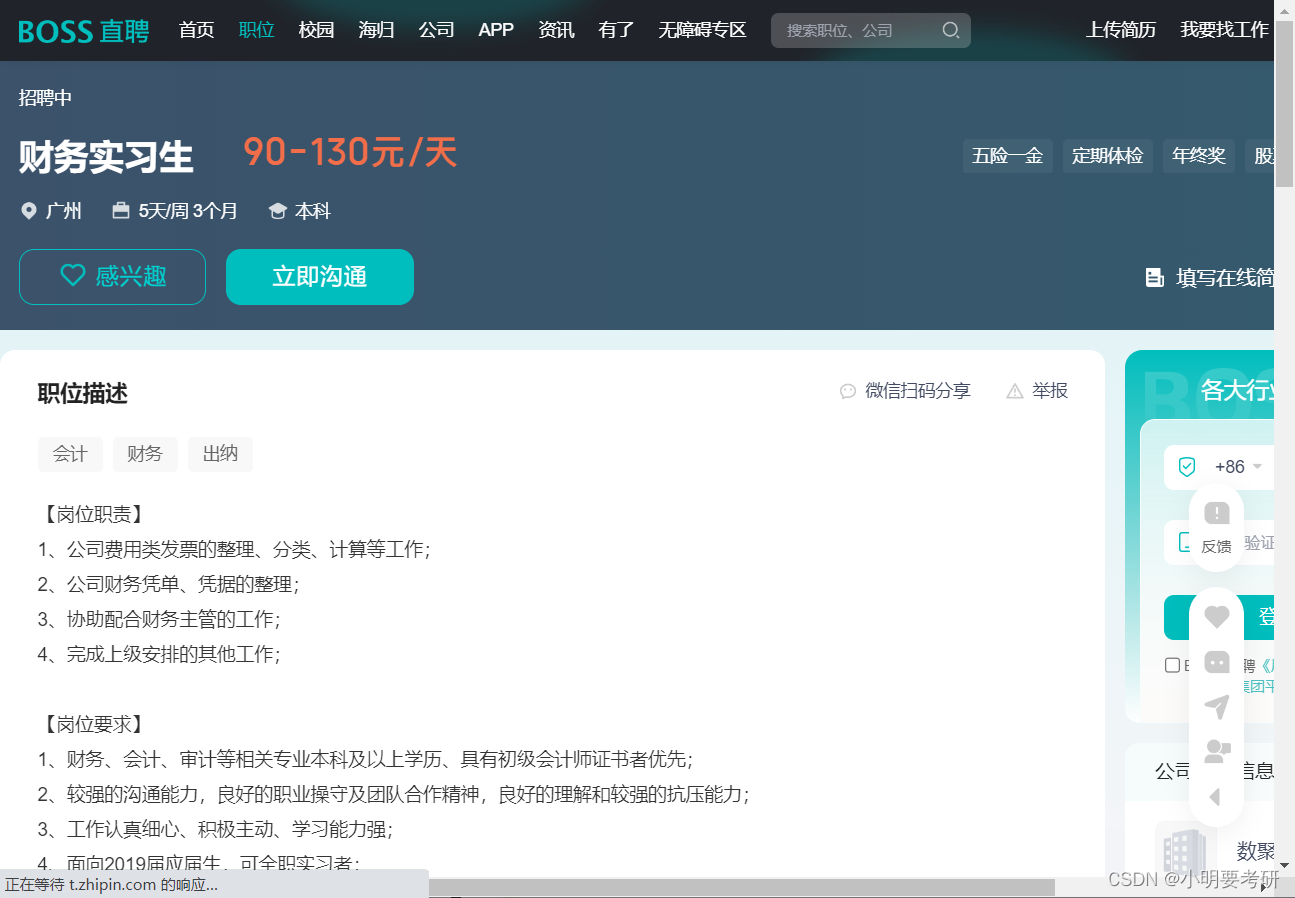
크롤링 효과 다이어그램: 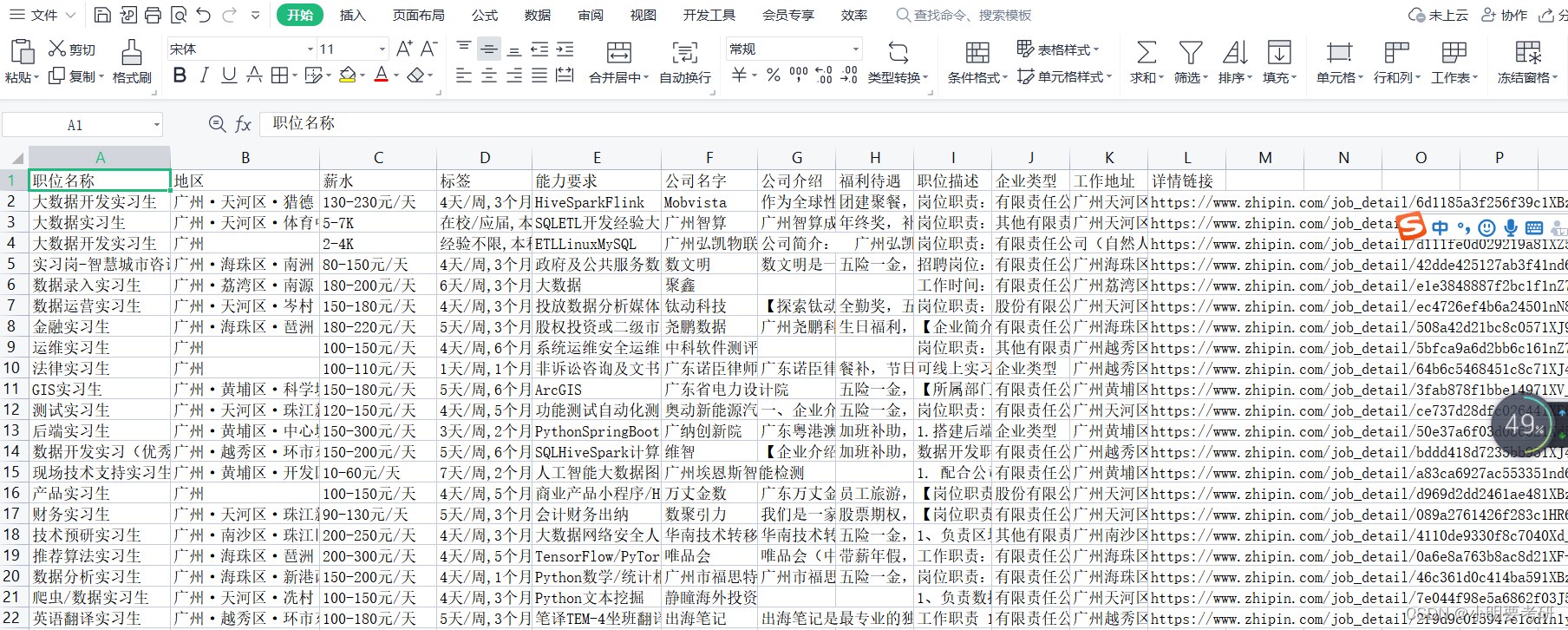
드라이버 버전과 Google 크롬이 일치해야 한다는 점에 유의해야 합니다.
암호:
import requests
from lxml import etree
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from time import sleep
from selenium.common import exceptions
import csv
from soupsieve.css_types import Selector
##### selenium.webdriver: 用于实现Web自动化测试,模拟浏览器的行为。
##### selenium.webdriver.Chrome: webdriver模块下的Chrome浏览器驱动程序。
##### selenium.webdriver.ChromeOptions: 用于定制Chrome浏览器实例的选项,例如:设置代理、设置头文件、设置窗口大小等设置项。
##### selenium.webdriver.common.by: 定义了一组按照元素查询条件查找的方法,常用的有class_name、css_selector、id、link_text、name、tag_name和xpath。
##### time.sleep: Python内置模块之一,表示让当前线程休眠指定时间,单位是秒。
##### selenium.common.exceptions: 该模块提供了各种异常类,用于处理在selenium操作过程中可能发生的异常情况。
##### csv: 用于读写CSV文件,可以方便地将数据导入到excel等工具中进行处理和分析等。
##### 创建保存文件
f = open('BOSS直聘.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=["职位名称","地区","薪水","标签","能力要求","公司名字","公司介绍","福利待遇","职位描述","企业类型",
"工作地址",
"详情链接"])
csv_writer.writeheader() # 写入表头
options = ChromeOptions()
##### 反检测
options.add_experimental_option("excludeSwitches", ["enable-automation"])
#调用其中的add_experimental_option方法,将一个字典作为参数传递给该方法。该字典只有一个键值对,键名为"excludeSwitches",键值为一个列表["enable-automation"]。这个选项可以关闭自动化测试软件的标志。
driver = Chrome(options=options) #实例化,通过传入不同选项来配置启动被控制的浏览器的环境和行为。
##### driver = webdriver.Chrome()
### 设置隐性等待时间为10s
driver.implicitly_wait(10)
driver.get('https://www.zhipin.com/web/geek/job?query=%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AE%9E%E4%B9%A0&city=101280100')
#
#https://www.zhipin.com/web/geek/job?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&city=101280100
#https://www.zhipin.com/web/geek/job?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&city=101280100
#https://www.zhipin.com/web/geek/job?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&city=101010100&page=1
a = 0
for page in range(1, 50): # 爬取3页
k = 0 # 用来设置每页爬取的数量,每页有30条数据,因全部爬取用selenium较慢
sleep(2)
### 滚动条滚到底部
driver.execute_script('document.documentElement.scrollTop = document.documentElement.scrollHeight')
li_lists = driver.find_elements(By.CSS_SELECTOR, '.job-card-wrapper')
print(len(li_lists))
for li in li_lists:
job_name = li.find_element(By.CLASS_NAME, 'job-name').text
job_area = li.find_element(By.CLASS_NAME, 'job-area').text
salary = li.find_element(By.CLASS_NAME, 'salary').text
job_tag = li.find_element(By.CSS_SELECTOR, '.job-card-wrapper .job-card-left .tag-list').text.replace('\n', ',')
job_ability = li.find_element(By.XPATH, './div[2]/ul').text
company_name = li.find_element(By.CLASS_NAME, 'company-name').text
welfare = li.find_element(By.CLASS_NAME, 'info-desc').text
link = li.find_element(By.CLASS_NAME, 'job-card-left').get_attribute('href')
# 点击详情页
clic = li.find_element(By.CSS_SELECTOR, '.job-card-left')
driver.execute_script('arguments[0].click()', clic)
# 窗口切换到最新打开的页面
driver.switch_to.window(driver.window_handles[-1])
sleep(2)
job_des = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/div/div[2]/div[1]/div[2]').text.replace('\n',
' ')
try: # 有的公司没有公司介绍
company_info = driver.find_element(By.CSS_SELECTOR,
'.job-body-wrapper .company-info-box .fold-text').text.replace('\n', ' ')
except exceptions.NoSuchElementException:
company_info = ''
try:
company_type = driver.find_element(By.CLASS_NAME, 'company-type').text.replace('企业类型\n', '')
except exceptions.NoSuchElementException:
company_type = ''
address = driver.find_element(By.CLASS_NAME, 'location-address').text
dic = {
"职位名称": job_name,
"地区": job_area,
"薪水": salary,
"标签": job_tag,
"能力要求": job_ability,
"公司名字": company_name,
"公司介绍": company_info,
"福利待遇": welfare,
"职位描述": job_des,
"企业类型": company_type,
"工作地址": address,
"详情链接": link
}
# 写入数据
csv_writer.writerow(dic)
k += 1
print(dic)
driver.close()
# 窗口切换到第一个页面
driver.switch_to.window(driver.window_handles[0])
if k == 30: # 每页爬取5条数据
break
sleep(2)
# 点击下一页,这里下一页的按钮不好定位,用XPATH的话只对1-4页有用,第五页后面要改成a[11]
a+=1
if a<=4:
c = driver.find_element(By.XPATH, '//*[@class="options-pages"]/a[10]')
driver.execute_script('arguments[0].click()', c)
elif a<7:
c = driver.find_element(By.XPATH, '//*[@class="options-pages"]/a[11]')
driver.execute_script('arguments[0].click()', c)
else :
c = driver.find_element(By.XPATH, '//*[@class="options-pages"]/a[10]')
driver.execute_script('arguments[0].click()', c)
driver.close()
driver.quit() ##
#### driver.close()方法会关闭当前打开的窗口或标签页。
#### driver.quit()则会彻底退出WebDriver驱动程序并关闭所有关联的窗口和标签页,释放内存。
##### 如果只调用close()方法,则会使该窗口被关闭,但是浏览器进程仍然处于活动状态。如果你想要完全退出浏览器及其相关进程,则需要使用quit()方法。
##### 注意:在非常规情况下,在调用driver.quit()之前,可能需要将driver对象设置为None来释放与其相关的资源。
