編集者のメモ
で、「機械翻訳(上)を作る方法」の記事では、我々は、機械翻訳の開発の歴史を見直します。この記事では、我々は作る方法を正確に説明するために、実用的な理論アルゴリズムと機械翻訳システム、機械翻訳神経の技術を共有することになります。この記事を読んだ後、あなたが学びます。
- どのように神経機械翻訳モデルが待望のTransformerモデルを作るためにNLPの研究者へと進化して開発されました。
- ベースTransformerモデル、どのように我々は、神経系の工業用グレードの機械翻訳を構築します。
大規模なワードが埋め込まれた提案、Googleの脳Mikolovは、技術word2vecは、RNN、CNNや他のネットワークが使用さ深さになるようになったため、2013〜2014ぬるい自然言語処理(NLP)フィールドは、施さ大きな変化を持っていますNLPタスクは、世界中のNLPの研究者は、NLP所属の新時代を開く、フラット期間に苦しむ原因に別れを告げる準備ができて、熱心に喜びました。
過去2年間で機械翻訳の分野で発生したにも「ビッグバン」です。2013オックスフォード大学は、NAL Kalchbrennerとフィル・Blunsom神経エンドの機械翻訳(エンコーダ・デコーダモデル)、エンコーダ・デコーダモデルに導入される2014 GoogleのイリヤSutskerver LSTMを、提案しました。機械翻訳の基礎としてニューラルネットワークをマークし2つのイベントが、我々は統計モデルに基づく統計的機械翻訳(SMT)を超え、かつ迅速に主流の標準オンライン翻訳システムになることを始めていました。2016年、Googleの展開神経質機械翻訳システム(GNMT)した後、その後、インターネットが広く言って循環した:「翻訳者として、このニュースを見て、私は心配を理解し、蒸気機関を参照してください18世紀の繊維労働者の間に恐れています。 "
情報エンコーダ・デコーダモデルを容易にするために2015注意のメカニズムとメモリベースのニューラルネットワークニューラルネットワークは、古典的な機械翻訳のキーフレーズベース機械翻訳に優れている、ボトルネックを表します。2017グーグルアシシュVaswaniら参照注意メカニズムは、自己注目のメカニズムに基づいてTransformerのモデルを提案し、変圧器ファミリは、NLPの仕事で最高の結果を推移しています。 - デコーダモデル(エンコーダ・デコーダ)、注意機構モデル、Transformerモデルの一般的なエンコーダ:NMTは、主に3つの段階を経て、最後の十年の発展をまとめました。
以下は、NMTの徐々に深さの分析は、これらの3つの段階はあなたが読み取り処理に非常に激しい感じ、それが直接、パート4を読み取るために、あなたを喜ば場合、紙数式や概念少量の定義は、「機械的センス」のいっぱいである可能性があり、自分自身を構築する方法のポイントを理解します工業用グレードのNMTシステム。
01新しい夜明け:エンコーダ・デコーダモデル
すでに述べたように、このエンド・ツー・マシン翻訳モデルに言及した2013年に提案しました。自然言語文を時系列データ、類似LSTMとみなすことができ、GRUは循環ニューラルネットワークがプロセス時系列データ配列に適合される比較します。私たちは、ソースとターゲット言語が別の時系列データとして扱われていることを前提とした場合、機械翻訳は、タスクのシーケンスを生成することで、どのようにそれを生成するためのタスクシーケンスを達成するには?一般リカレントニューラルネットワーク・ベースのコーダ - デコーダモデルフレーム(また配列に対する配列と呼ばれる、Seq2Seqをいう)配列の生成を行う、Seq2Seqモデルは、2つのサブモデルから構成:エンコーダとデコーダ、エンコーダ、デコーダ、ニューラルネットワークの一の周期とは無関係に、所与のソース言語文のモデル、連続的な、密ベクトルをマッピングする第1エンコーダを使用して、ターゲット言語に復号した後、ベクターを使用しています文。
エンコーダエンコーダ入力ソース言語文は、非線形変換によってコードされる中間体Cのセマンティクスに変換表現。
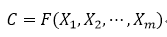
一度I、およびCは、デコーダデコーダ以前に生成された履歴情報y₁を表し、y₂、......、yᵢ-₁エンコーダの中間出力のセマンティクスに従ってターゲット言語文に次のワードを生成します。
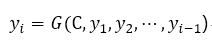
各yᵢはseq2seqモデルは、入力ソース言語文に従って文の目的言語翻訳のモデルを生成するように、順次生成されます。ソース言語文と目的言語の言語、単語の順序が同じではなく、同じセマンティクスで、エンコーダは、濃縮された埋め込み空間ベクトルCにソース言語文の後、デコーダは、再をベクターに暗黙意味情報を使用することができるものの同じ意味を持つ対象言語文を生成します。すべてのすべてで、Seq2Seq神経翻訳モデルは、人間の翻訳者の二つの主要なプロセスをシミュレートすることができます。
- ソーステキストのエンコーダエンコーダコンテキスト解釈。
- ターゲット言語にコンテキストを再コンパイルデコーダデコーダ。
02画期的な飛躍:注意機構モデル
2.1制限Seq2Seqモデル。
重要な仮定は、すべてが固定次元意味ベクトルに圧縮、デコーダは、ベクトルを再生成するためにこの情報を使用することができ、入力文の意味をモデル化することができるSeq2Seqエンコーダであるのと同じ意味が異なる言語文を持っています。固定された中間セマンティックベクトルの次元に入力コーデック文の長さなどの性能向上の急激な減少エンコーダ出力は詳細の多くを失い、長いサイクルニューラルネットワークの入力文を処理することは困難であろうように、一般的な情報モデルSeq2Seqがあるのでボトルネックが表現しました。
ソース・ステートメントは、ターゲット文で別々に処理されている一般的なSeq2Seqモデルは、ソースが直接ターゲット文を使用すると、文の間の関係をモデル化することはできません。だから、どのようにこの制限にそれを解決するには?メカニズムに注意を払うに初めて発表され2015 BahdanauらはSeq2Seqのボトルネックの問題を解決するために、共同翻訳とアライメント単語に適用されます。注意メカニズムは、ターゲット単語と単語の間に各ソースの関係を計算することができるので、ダイレクトモデリングソース・ステートメントと目標文の間の関係。アーティファクトの注意メカニズムは、NMTの名声が戦争機械翻訳のコンテストで優勝ことができます何ですか?
2.2一般原則注意のメカニズム
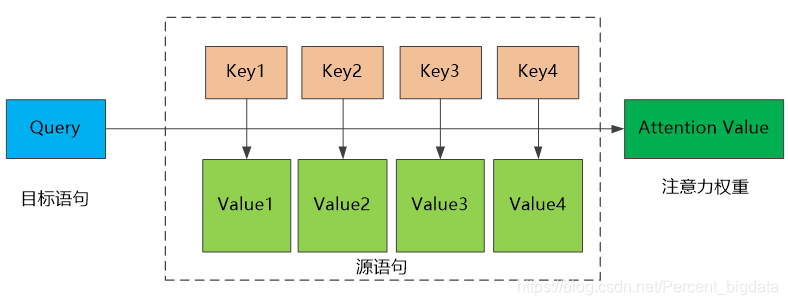
の主キーを照会することができます個々のレコードにアクセスする際に一意に個々のレコードの値を識別し、一般的な使用の主キーのキーのためのデータベースで解釈人気の、キークエリ検索とクエリ照合とどこ削除しますデータ値。それぞれ、データの断片として仮想的な<キー、値>ストレージに従ってデータ、すべての主キーのキーマッチング度クエリ1つのクエリを計算して、重み値:アイデアは、アドレッシング、ソフトのコンセプトです注意のメカニズムに似ています加重値がやると、クエリの結果として、その結果が注目されます。したがって、一般的な原理注意機構(上記参照):まず、ソース文を構成する要素は、ターゲット文をクエリー配列の要素で構成されている<キー、値>コンフィギュレーションデータの系列として想像してから教えます要素クエリ文は、ターゲットが与えられ、各問合せキーまたは相関の類似度を算出することにより、各キー値に対応する重み係数を取得するために、最終的には、注目の最終値を得るために、すなわち、値に重み付けすることができます。これにより、フォーカス機構は、本質的にソース・ステートメントの値は、要素の加重和である、およびクエリーキー値に対応する重み係数を計算するために使用されます。一般式は次のとおりです。
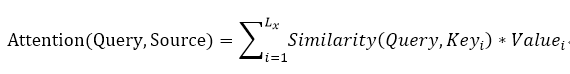
機械翻訳モデルSeq2SeqにRNNのような一般LSTM / GRU複数の積層。2016年9月GoogleはSeq2Seq +モデルフレームワーク注意機構、エンコーダのネットワークを使用して、神経機械翻訳システムGNMTを解放し、デコーダネットワークは、8層の層を隠さLSTM復号に注意機構の入力の加重平均によるエンコーダの出力を有していますLSTM各隠された層デバイス、および接続ごとに各単語ソフトマックス層の出力ターゲット言語辞書の最後に確率。
GNMTは、それがパフォーマンスの向上の注目を計算にする方法?:次に、ターゲット文ペア - (X、Y)ソース・ステートメントのいずれかのセットに並列コーパスを想定
長さMのストリングのソース・ステートメント:
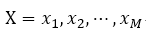
長さNのターゲット文の文字列:
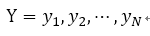
Hをコードするd次元ベクトルとしてエンコーダ出力:
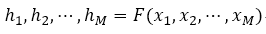
ベイズの定理の使用、文の条件付き確率:
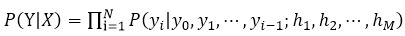
コードの前にエンコーダの出力に応じてデコーダによってデコードされ、時点iにおけるI-1の出力をデコーダとき、P(Y | X)を最大化するターゲット単語を得ることができます。
GNMT注意のメカニズム、実際の計算手順:
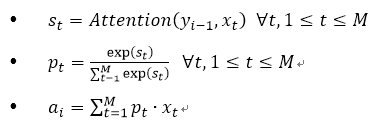
ここで読んで、あなたも理解不能さておき、この記事を唱え、フル疲れを始めることができます。これまでにエキサイティングな時間が始まったので、読むために忍耐を教えてください:記事トランス(変圧器)の主人公を学生が果たしました!
03ハイライト瞬間:自己の注目メカニズムに基づいてTransformerモデル
パート2は、我々は、平均的なモデルアーキテクチャseq2seqよりもデメリットはあるものの、この組み合わせを、より良い結果を達成しseq2seq +注意のメカニズムに言及しましたか?効果的に並列コンピューティングにできませんでしたが、すぐに研究者が福音をしたいと思います。実際にはそこリカレントニューラルネットワークの研究者が長年の問題に悩まされてきています。2017年6月Transformerモデルでは、Googleの出現を回し、注意のメカニズムを参考に、「注意されたすべてのあなたの必要性」に掲載された論文で提案されたメカニズム(自己注意)と、新たなニューラルネットワークアーキテクチャから注目されました - -transformer。モデルは次のような利点があります。
- 従来のモデルSeq2Seq RNN主に制限されたトレーニングGPU速度は、Transformerモデルは完全に注意をRNNとCNNの並列コンピューティングメカニズムなしモデルです。
- 変圧器は、最も急速な並列コンピューティングを実現するために、自己の注意機構による批判スロートレーニングRNNの欠点を改善し、変圧器は完全にモデルの精度を向上させるためにDNNモデルの特性を活用するために、非常に深い深さまで上昇させることができます。
洞察Transformerモデルのアーキテクチャをしてみましょう。
3.1。Transformerモデルアーキテクチャ
以下に示すように、変圧器モデルは、エンコーダ、デコーダ及び接続層を介し組成物によって、本質的にモデルSeq2Seqあります。原稿に記載された「トランス」エンコーダ:エンコーダエンコーダが同じNした6番目の符号化エンコーダ層=層の積層は、各層が2つの副層を有しています。第一のサブ層は、第2のサブ層は、単純な、フィードフォワードネットワークの完全に接続されたフィードフォワードネットワークロケーションで、マルチヘッドの注目の機構です。我々は次に、標準化層レイヤ正規化に続いて、各サブ層接続Residualconnection、の残差を使用します。各副層の出力は、サブレイヤ(x)は、サブ層自体によって実現される機能であるLayerNorm(X +サブレイヤ(X))、です。
「トランス」デコーダ:デコーダもデコーダ層の積層を復号同じN = 6番目の層からなるデコーダ。エンコーダの各々において同一層を有する2つのサブ層に加えて、デコーダは、さらに、第3のサブ層(エンコーダ・デコーダ注意層)に挿入し、層スタックエンコーダ出力実行マルチHeadAttention。エンコーダと同様、そして、我々は各副層との間に接続された残差を使用し、正規化層。
Transformerモデルは、3つの方法の注意を計算します。
- エンコーダから注目、各々がマルチヘッド注目エンコーダ層を有します。
- デコーダからの注目は、各デコーダは、マスクされたマルチヘッドの注目層を有しています。
- コーダ-注目のデコーダは、各デコーダエンコーダデコード注目されている、工程と同様の過去seq2seq +注意モデル。

3.2。注意のメカニズムので、
Transformerモデルは、あなたが計算するの異なる位置の入力配列の配列を表現する能力に注意を払うことができ、自己の注目メカニズム(自己注意)の核となるアイデアです。名前の間に注意メカニズムを示唆しているので注意機構のソースとターゲット文の文を参照していますが、内部要素間の文と注意のメカニズムはありません。通常、ベクトルvのすべての要素の値の間の鍵ベクトルkとしてクエリベクトルq、エンコーダの出力シーケンスとして計算モデルSeq2Seqデコーダ出力における焦点、素子の注意機構とターゲットセンテンス内のソース文。
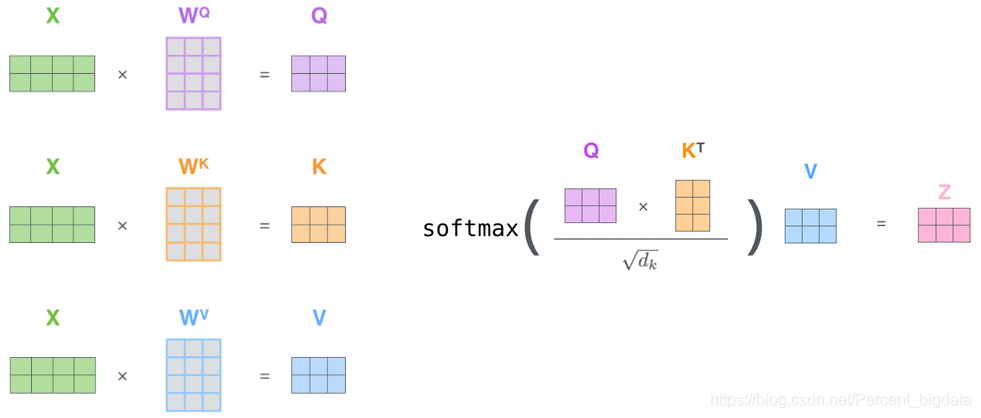
クエリベクトルq、鍵ベクトルk、ベクトルVの値、およびそれぞれの位置:計算機構からの注目は、それぞれ3つのベクトル、にエンコーダまたはデコーダ3つの線形変換することによって、各入力シーケンスの位置ベクトルであります他の位置kのシーケンスとマッチングを取る行うqが、0と1の間に獲得層ソフトマックス重み値の後に一致度を用いて計算し、従って各位置に対する重みvで加重平均し、最終的に取得されます位置出力ベクトルz。以下の計算方法は、自己注目を導入しました。
▶ズーム可能な注意内積
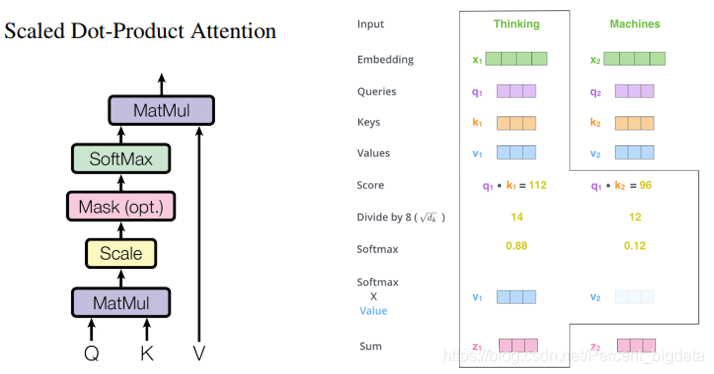
ご注意ズーム可能な、すなわち内積が注意ベクトルから計算方法、注意の4つのステップで計算されます。
- クエリベクトルq、鍵ベクトルk、ベクトルvの値は:3つの入力ベクトルエンコーダの各々からのベクトル(各単語のための単語ベクトル)で生成されます。重量、Wᴷによって三つの入力と3つのXコーデック重みベクトル行列Wᴼ̴における行列演算は、Wᵛが作成掛け。
- スコアを計算します。入力文「思考機械」の一例を示し、最初の単語の注目のベクトルから計算された「思考」、「思考」スコアの文中の各単語を入力する必要があります。スコアは、プロセスにコード化された単語「思考」に文の他の部分にどのように多くの注意を決定します。スコアリングワードスコア(単語全て入力文)と計算されたドット積と鍵ベクトルkの「思考」クエリベクトルqによって。例えば、第1のスコアはq₁とk₁、q₁及びk₂の第2のドット積の画分のドット積です。
- 加算スケーリング:画分は、より安定した勾配に(dₖdₖキーが= 64ベクトルの次元で)スケーリング係数1 /√dₖ乗じ、次いでソフトマックス結果に通します。ソフトマックスの役割は、すべての単語が正規化を得点することです、そして得られたスコアが正であり、1。ソフトマックススコアは、現在の位置(「思考」)をコードする各単語の寄与を決定します。
- 各値はベクトルvソフトマックススコアを乗じて、我々は、意味的に関連の単語に集中したい、と無関係な単語を弱めます。加重値ベクトルを加算し、その位置にフォーカスzᵢ層から出力を得ます。
したがって、注目ドット積は、次式で計算することができるスケーリングすることができます。
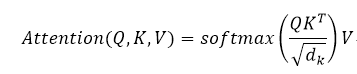
実際には、マトリックス状に注意の計算はより高速と見なされるために完了します。私たちは、行列演算することにより、自己の注目のメカニズムを実現する方法を見てしようとしていること。
最初の取得Aクエリベクトル行列Q、および鍵ベクトル行列ベクトル行列VのK値は、重み行列Wᴼ̴、Wᴷにより、Wᵛは、入力行列Xを乗じた、同一の任意の単語スコアは、そのベクトルキーkで得られ、ドット積を計算し、クエリベクトルqを持つすべての言葉は、私たちは一緒にクエリベクトル行列Qとして結合Kᵀ、すべての単語のクエリベクトルqの組み合わせを形成するために、ベクトル行列の鍵ベクトルk個の転置のすべての単語を置くことができ、その2つの行列注目スコアリング行列A =QKᵀを乗算してから、注目スコアリング行列Aソフトマックス正規化スコア行列A ^、左マトリクス出力ベクトル行列V Zを乗算した行列を取得しようとしています
▶長い注意
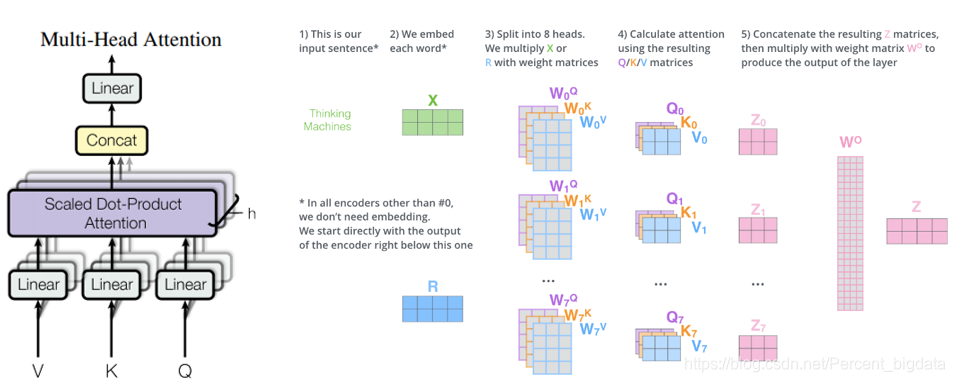
全ての情報入力文空間を捕捉することは困難でのみ計算された注目する場合は、モデルを最適化するために、原稿用紙は、新規なアプローチ--Multiヘッド注意を提案しています。マルチヘッド注意のみベクトルQの寸法K D(モデル)、V単一注意埋め込み行うが、空間線形K、Q、V hは寸法DQ、dₖ、dᵥに、それぞれ、異なる時間に投影されていませんその後、自分の注意を行います。
ここで、DQ =dₖ=dᵥ= D(モデル)/ H = 64時間ヘッド上に投影されます。マルチヘッド注意一つだけ注意ヘッドが存在する場合、その平均値がメッセージを弱体化する、異なる場所に共同注意部分空間情報の異なる表現するモデルを可能にします。
マルチヘッド注意ヘッドは、異なるクエリ/キー/値のマトリックス(Qᵢ、Kᵢ、Vᵢ)で得られた、各クエリ/キー/値の重み行列Wᴼ̴ᵢ、Wᴷᵢ、Wᵛᵢに別々のままです。Xは、クエリ/キー/値行列Qᵢ、Kᵢ、Vᵢを生成するWᴼ̴ᵢ、Wᴷᵢ、Wᵛᵢ行列を乗じました。上述した同一の注目から算出し、8つの異なるZᵢ行列を得るための唯一の8つの異なる重み行列計算、異なる暗黙のベクトル空間への入力テキストを表す各投影しました。最後に、この行列マトリクス出力に減少一緒に8個、重量Wᵒを乗じて重み行列、Z.
文の最後に各ヘッドマルチヘッド注意は何の情報も懸念しますか?頭はどこの関心の異なる焦点?「それは広すぎたので、動物が道路を横断していない」「それはあまりにも疲れていたので、動物がcrossthe通りませんでした」と何以下の2つの文では例えば、二つの文は「」を指し、それは?「それは」「ストリート」を指し、あるいは「動物」?我々は「それは」動物」という方法で、ある意味では「動物」と「ストリート」、単語のモデル式にそれのフォーカスを言葉「それ」をエンコードする場合それは「と」ストリート」の略ではなく、意味論では、より強く動物を指し、それの最初の文、それはより強く、通りを指し番目の文。
他の構造について3.3。Transformerモデル
▶正規化された残差に関連
残留接続と層の正規化(LN)、即ち、残留層が正規に接続されている:フィードフォワード層との間にサブ層にマルチHeadAttention出力:コーデックは、特殊な構造を有しています。残留接続は、小さな変化が方法は、コンピュータビジョンに使用したことに留意することができる、新たな残留構造、残留書き換えの入出力は、このようなトレーニングモデルを構築することです。
活性化関数にデータを正規化する前に、我々は飽和帯のデータを入力したくないので、活性化関数を落ちます。LNは、正則化深さ試験であり、一般的なバッチの正規化(BN)を比較しました。BNの主なアイデアは、正規化の各レイヤにおけるデータの各バッチで行われる、LNは、各試料中の平均及び分散を計算することである、LNの利点は、独立したコンピューティングおよび単一のサンプルに対して正規化ではなく、そのBNバッチ方向の平均と分散の一種。
▶フィードフォワードニューラルネットワークの前に
注目が完全に接続されたネットワークに出力コーデック層サブレイヤます:フィードフォワードネットワーク(FFN)を、そして線形変換は、2つのReLuを含む、紙は、それぞれ、それぞれの位置に応じて(文字入力文ごと)でありますFFN、FFNポイントワイズの名前の由来を行います。それは次のように計算されます。
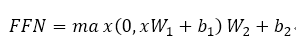
そして、線形変換層▶ソフトマックス
最後に、デコーダは、実数のベクトルを出力します。どのように浮動小数点ワードになるには?これは、それがソフトマックス層であり、行うべき作業の線形変換層です。デコーダベクターにより生成することができる単純な線形変換層を完全に接続ニューラルネットワークは、それよりもはるかに大きい上に投影され、 'S(logits)対数確率ベクトルと呼ばれます。
のは、トレーニングセットから百万異なる英単語(「出力語彙」我々のモデル)を学ぶために我々のモデルを想定してみましょう。したがって1万確率ベクトルの数は、細胞のベクトルの長さである - 単語の割合に各セルに対応します。次の層は、これらのスコアは、確率になるであろうソフトマックス(1.0の上限は、陽性です)。最も高い確率を有する細胞が選択され、そしてその対応するワードは、時間ステップとして出力されます。
▶位置エンコーダ
Seq2Seqモデルにのみ単語ベクトルを入力しますが、Transformerモデルと畳み込みサイクルを放棄し、不足している情報は、すべての単語をもたらすことができる場合にはシーケンス順序の情報系列の順序を抽出することができない権利ですが、意味のある文を形成することはできません。著者はこの問題を解決する方法ですか?シーケンスのモデル次数、注入すべき単語の相対的または絶対的な位置についての配列情報を利用します。論文では、定位置エンコードを導入:シーケンス内の単語の位置は、符号化されているようです。図は、単語512の寸法の視覚化に埋め込まれた20位置コードワードです。
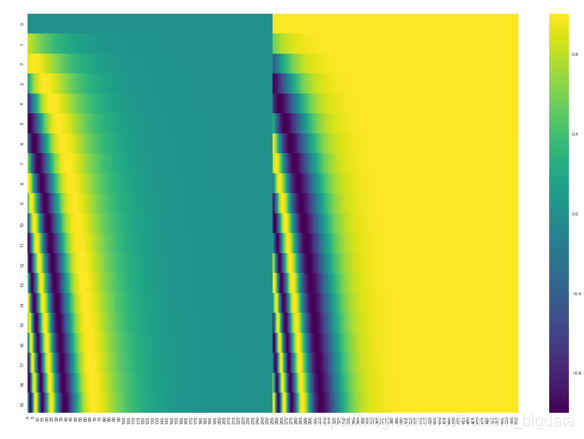
各センテンス「場所コード」の語は、エンコーダとデコーダの下部に追加された入力スタックに埋め込まれ、同じ寸法及び埋め込みワードdmodelをコードする位置には、タリア添加してもよいです。位置情報を得るために、異なる周波数の紙の使用正弦及び余弦関数:
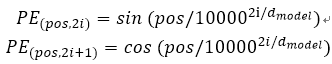
POSは、奇数位置の余弦エンコーダで使用され、iは符号化正弦も位置で、寸法となる位置です。各次元は、位置符号化正弦波に相当します。
参考文献:
- 最終KalchbrennerとフィルBlunsom。2013年再発連続翻訳モデル。EMNLP 2013の議事録
- イリヤSutskever、etc.2014。など2015 NIPS 2014 Dzmitry Bahdanauの神経Networks.In議事録と系列学習へのシーケンス。
- 共同Learningto揃えることにより、ニューラル機械翻訳と翻訳。ICLR 2015の議事録。
- アシシュVaswani、etc.Attentionisすべてのあなたの必要性。NIPS2017の議事録。
- ジェイAlammar TheIllustrated変圧器は、http://jalammar.github.io/illustrated-transformer/
- 張Junlin注意モデル(2017年版)の深さの調査、HTTPS://zhuanlan.zhihu.com/p/37601161
