Webサイトのトラフィックログ解析システムノート(Hadoopのビッグデータ技術の原理と応用)
その他
2020-01-30 18:43:52
訪問数: null
まず、システムアーキテクチャ設計
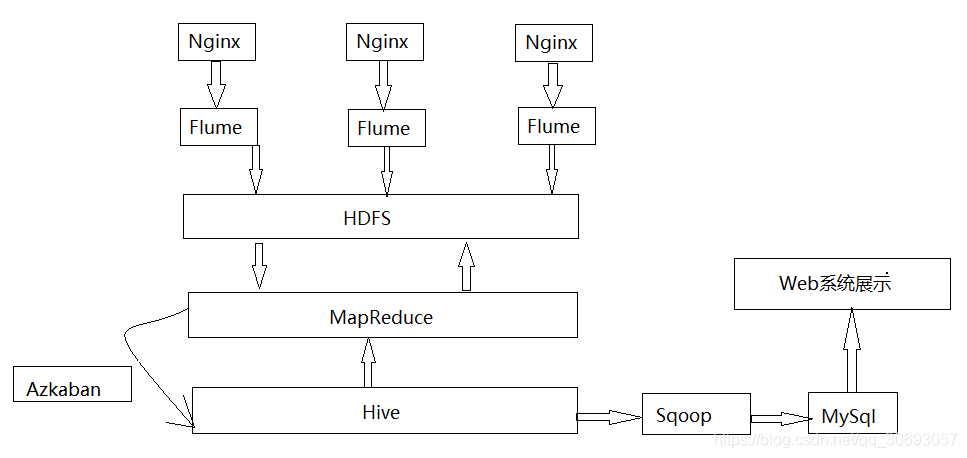
- まず、ログ・ファイルは、nginxのは、HDFSザ・水路によって収集サーバによって生成されます。
- 第二に、元のログファイルとデータ形式カスタム開発のMapReduceプログラムの規定に従って処理するデータの開発;
- その後、ハイブによって最も重要なデータ分析;
- ここでも、sqoopツールによって、リレーショナルデータベースのMySQLへの輸出のデメリット分析。
- 最後に、Webシステム、最も重要なデータ解析
第二に、システムの概要
- 仮想マシンでのログイン水路収集サイトは、仮想マシンがでHDFSに保存されています。
- Dウィンドウに記憶された仮想マシンのHDFSにログデータ、:/入力フォルダ
- Dへの洗浄に/入力ログデータ、及び出力する:DへのウィンドウのMapReduceプログラムにおける食の調製、IN /出力
- そして、D:クリーニング/ HDFS内の仮想マシンにアップロードされた出力データ
- 仮想マシン内のハイブ、データ・ウェアハウス・テーブルを作成し、ログおよびデータのデータに対応するフィールドは、テーブルにクリーニング後HDFSです。HQL文の(同様のSQL文)を書く、データは統計分析のために集約されます。ハイブは、HDFS内のテーブルに格納されているため、メタ解析後のデータはHDFSです。
- MySQLへハイブ統計分析の後sqoopデータをインポートすることによって。
- SSMフレームは、データは、MySQL視覚表示であった、Echartsによって調製しました
第三に、結果の最終的な表示

公開された43元の記事
・
ウォン称賛13
・
ビュー4907
転載: blog.csdn.net/qq_30693057/article/details/96052930
