まず、どのようにクエリを最適化するには?以下の回答の質問の詳細な分析
いないすべてのテーブルを最適化する必要があり、それは一般的に指導を行うために、1つまたは2人と建築家によって最適化され、毎週行われる系統的な指導を開きます。
- 最適化データアクセス
- 、不要なデータかどうかを確認するために、データベースへの要求:例えば、記録を必要としない、必ずしもすべての列を削除し、マルチテーブルに関連付けられているすべての列を返すは、同じデータがクエリを繰り返します。
- B、追加のスキャンレコードかどうかを確認してください。例えば、走査線の数と返される行の数は、広く変化し、(最適化は、以下を参照方法)を最適化することができます。
- インデックスを使用して、C、
- クエリの再構築
- 、セグメンテーションクエリ:大きなクエリは、このような古いデータの多くを削除するために使用することができるようにいくつかの小さなアイデアクエリ、に分けることができます。
- B、分解リレーショナルクエリ:スプリット関連のデータベースクエリ、各テーブルのための単一のテーブルのクエリ、関連コード、多くの利点があります(どのような利点は、以下を参照してください)
- いくつかのミドルウェアを使用します
- 、MyCat別個のリードおよびライトのような、サブサブテーブルライブラリプラグイン(著者が記事を読み続け参照します)。
- B、
第二に、スロークエリの基礎:最適化データアクセス
最も基本的な理由は、データにアクセスするには、あまりにも多くのクエリのパフォーマンスのハイテクですが、次の2つのステップの分析により、非効率的なクエリことができます。
- それは、データベースに不要なデータを要求した場合、手段はあまりまたは列の、あまりにも多くの行にアクセスします。
- かどうかはMySQLの走査線をはるかに超えるスキャンの追加レコードを必要としていました。
2.1、不要なデータベースにデータを要求した場合
(1)クエリ不要なレコードを
間違えMySQLの戻り必要なデータのみが、実際には、MySQLは結果セット全体が算出される返すことです。最も効果的な方法はしている、SELECTステートメントを使用して、インスタンスのために多数の結果を照会し、(のみ1000年10ページを表示し、そのようなデータを照会として)その後、N行の結果セットの前に下車バックプラスLIMITを問い合わせます。
(2)は、マルチテーブルに関連付けられているすべての列を返します

(3)常にすべての列を削除します
SELECT *、オプティマイザがしますこのような最適化をカバーするスキャンインデックスを完了していない、それはまた、追加のパフォーマンス・オーバーヘッドをもたらすでしょう。
(4)同じデータがクエリを繰り返します
同じクエリを繰り返して、まったく同じデータ毎時間を返します。例:ローカルユーザーではコメントはURLアバターユーザーを照会する必要があり、ユーザが繰り返しコメントするとき、繰り返しデータを照会することがあり、このURL;決意は:データへの最初のクエリがキャッシュされたときに、必要なときに、その後、キャッシュから取ります。
2.2、MySQLのかどうか、追加のスキャンレコード
データのみが必要なクエリが返すには、それは次の3つの指標のクエリコストで測定した結果は、多くのデータを返されたクエリを、スキャンするかどうかを検討している、これらの3つの指標は、MySQLの遅い、遅いのでログのチェックが見つけることです、ログに記録されます走査線の数が過剰に良い方法を問い合わせます。
- 応答時間。
- 走査線の数。
- 行の数が返されます。
(1)応答時間
サービス時間とキューイング時間:応答時間は二つの部分との合計を指します。サービス時間 - データベースクエリは、本当に多くの時間を費やし処理、時間をキューイング - 実際のクエリのいくつかの実行時間を待たずにサーバリソースので、(I / O操作などのような、このような行ロックとして、完了です...)が、一般的には、それぞれ一緒になって、両方の決定された応答時間であるかどうかを決定することは困難です。
スキャン返さ線(2)数
理想的な条件と返される行数の下でスキャンラインの数は同じでなければなりませんが、実際には非常に困難に近い最高にそれらを得るために。
アクセスタイプ:
MySQLのいくつかを見つけるための方法および戻りライン結果から、スピードがあり、低速、高速に:フルテーブルスキャン、インデックス・スキャン、スキャン範囲、インデックスのみのクエリ、一定の屈折率。最良の方法は、あなたが適切なインデックスを見つけることができない、適切なアクセスタイプ、追加する場合にはスキャンラインの最も効率的でMySQLと少なくとも数は、レコードへの道を見つける必要があるようにインデックスを。
あなたは、クエリのニーズは、大量のデータが、返された行のほんの数をスキャンすることが判明した場合、それを最適化することができます。
、索引スキャン被覆使用:ストレージエンジンは、行が結果を返すことができ、対応するテーブルに戻って取得する必要がないので、インデックス内のすべての列を使用する必要性を、
B、データベーステーブルの構造を変更する:例えば、別々の要約を使用して、
C、複雑なクエリでは、これを書き換える: MySQLのオプティマイザは、より最適な方法でクエリを実行してみましょう。
第三に、クエリの再構築
3.1、より複雑なクエリまたは単純なクエリを選択してください
3.2、セグメンテーションクエリ(DLETE)
時には大きなクエリの小さなクエリに切断することができ、各クエリ機能とまったく同じ、ごく一部だけ、戻りクエリ結果までの時間のごく一部を完了しました。
例:データを削除するために0に古いデータ、または虚偽のフラグを削除します。
ビッグタイム文はワンタイムロックに大量のデータを完了するために必要とされる場合、それは、システムリソースをトランザクションログ全体を占有し、小さいながらも重要なクエリの数をブロックし、そのような月に実行する必要のような大きなDELETEセグメンテーション、次の文に一度:

データは、各後に削除された場合、時間の非常に長い期間に分散したワンタイム圧力を削除するには、元のサーバーを削除することができ、あなたが削除のロック時間を短縮することができます休みます。
3.3、クエリに関連した分解
各テーブルには、単一テーブルのクエリを行い、その後、アプリケーション・コードの結果を相関することです。例えば:
(これらのテーブルが大きいと仮定すると、全体的に非常に遅い理にかなっています)

クエリに関連した分解の利点:
ので、高いキャッシュ効率その:MySQLのクエリキャッシュテーブル内の関連する変更された場合、クエリキャッシュを使用することはできません。クエリテーブルに基づいて、テーブルまれ変更は、繰り返すことができる分割後の場合クエリキャッシュを使用した結果、(例えば、上記の例では:タグが既にキャッシュされている場合、アプリケーションは、最初のクエリをスキップすることができます)
B、ロック競合削減する:クエリ分解した後、ロック競合を減らすことができ、単一のクエリを実行します。
Cは、改善されたスケーラビリティ:相関的コード層、データベースを分割することが容易です。
Dは、クエリ自体の効率を改善する:上記の例で使用する代わりに、リレーショナルクエリ)INを(ランダムアソシエーションより、より効率的なクエリID順序MySQLを可能にします。
E、冗長レコードの問い合わせを減らすことができます:コードの層を数回しかチェックに関連するいくつかのレコードを行う可能性がありますデータベース層を照会する必要が関連付けられている特定のレコードを行うには、
第四に、基本的なクエリの実行
クエリのMySQLの実行:

(1)プロトコル:クライアントがサーバにクエリを送信します。
(2)の状態を確認してください:キャッシュがヒットした場合、その後、サーバーのキャッシュをチェックし、すぐにキャッシュに保存された結果を返します。そうでなければ、次の段階に進みます。
(3)クエリキャッシュ:解析SQLサーバ側、前処理、およびオプティマイザによって生成された対応する実行計画。
(4)优化器:MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
(5)将结果返回给客户端
4.1、客户端/服务端通信协议
4.2、查询状态
等待、查询、锁定、排序
4.3、查询缓存
解析一个查询语句之前,如果查询缓存打开则优先检查是否命中缓存,这个检查是通过一个对大小写敏感的哈希查找实现的。
4.4、优化查询处理
(1)语法解析器和预处理
MySQL通过关键字将SQL语句进行解析,并生成一颗对应的“解析树”。
(2)查询优化器
下面是MySQL能够处理的优化类型:
- 重新定义关联表的顺序;
- 将外连接转化为内连接;
- 使用等价变换规则;
- 优化COUNT()、MIN()、MAX();
- 预估转化为常数表达式;
- 覆盖索引扫描;
- 子查询优化;
- 提前终止查询;
- 等值转播;
- 列表IN()的比较。
4.5、查询执行引擎
4.6、将 结果返回给客户端
五、MySQL查询优化器的局限性
5.1、关联子查询
虽然IN()通常能提高效率,但是最糟糕的一类子查询却是WHERE条件中包含IN()的子查询。
子查询可能会提高性能也可能影响性能。
5.2、UNION的局限性
使用UNION无法将限制条件从外层“下推“”到内层,这使得原本能够限制部分返回结果的条件无法应用到内层查询优化上。
比如希望UNION的各个字句能够根据LIMIT只取部分结果集,或者先排序好再合并结果集,则每个UNION的表数据都放在临时表空间然后再取出条件的数据,但是从临时表空间取出来的数据是无序的,所以在外层还需要加一个ORDER BY和LIMIT操作。
5.3、索引合并优化
WHERE字句包含多个复杂条件的时候,MySQL能够访问单个表的多个索引以合并和交叉过滤的方式来定位需要查找的行。
5.4、等值传递
5.5、并行执行
MySQL没有并行执行查询的功能
5.6、哈希关联
5.7、松散索引扫描
5.8、最大值和最小值优化
5.9、在同一个表上查询和更新
MySQL不允许同时在一张报表进行更新和查询
六、优化特定类型的查询
6.1、优化COUNT()查询
(1)COUNT ()聚合函数的作用
作用1:可以统计某个列值的函数
作用2:也可以统计行数
(2)简单的优化:

假设上面那个查询会扫描5000行数据,由于在MyISAM中COUNT()函数非常快,前提是没有任何WHERE条件的COUNT(*)才非常快,需要优化成只需要扫描5行数据:
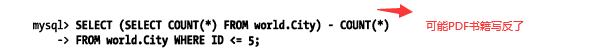
(3)复杂的优化:
通常使用COUNT需要扫描大量的行,除了上面的简单优化,还可以使用索引覆盖扫描。
6.2、优化关联查询
(1)确保ON子句的列上有索引
创建索引时就要考虑关联的顺序,当表A和表B用c列关联的时候,如果优化器的关联顺序是B、A,那么就不需要在B表的c列上创建索引了,没有用到的索引会带来额外的负担。总的来说只需要在关联顺序中的第二个表的相应列创建索引。
(2)确保任何的GROUP BY 和ORDER BY中的表达式只涉及到一个表中的列,这样MySQL才能使用索引来优化这个过程;
6.3、优化GROUP BY
当无法使用索引时,GROUP BY使用两种策略来完成:使用临时表或者文件排序来做分组
优化GROUP BY WITH ROLLUP:
这是分组的一种变种——对返回的分组结果再做一次超级聚合,最好不要使用它,可以把它实现的功能放在代码中实现。
6.4、优化LIMIT分页
分页可以使用LIMIT+偏移量实现(LIMIT 偏移量,返回页数),同时加上合适的ORDER BY,如果有索引效率还可以没有则需要做大量文件排序操作。
但是当偏移量非常大时要优化:
(比如LIMIT 1000,20,则需要查询10020条记录但是只返回最后20条,前面10000条记录都被抛弃掉)
(1)使用索引覆盖扫描,而不是查询所有的列,然后根据需要做一次关联操作再返回所需的列

可改成:

6.5、优化UNION查询
MySQL总是通过创建并填充临时表的方式来执行UNION,上面也有提到过,所以很多优化策略在UNION都没得使用,经常需要手工地将WHERE、LIMIT、ORDER BY等子句“下推”到UNION的各个子查询中,以便里边优化器能更充分利用这些条件进行优化。
如何优化:
除非明确需要消除重复的行,否则一定要使用UNION ALL,如果没有ALL关键字,MySQL会给临时表加上DISTINCT选项,这会导致对整个临时表的数据做唯一性检查,很费时。
七、查询优化案例学习
7.1、使用MySQL构建一个队列表
(1)背景:一个表包含多种类型的记录,高流量高并发情况下的,比如未处理、已处理、正在处理等,当多线程在表中查找未处理记录时,然后生成正在处理,在处理完后再将记录更新程已处理状态。比如邮件发送、多命令处理、评论修改等功能。
(2)这种表设计不合理的两个原因
a、随着队列越来越大、索引深度正价,找到未处理记录的速度会随之变慢。(可以通过将队列表分为两部分解决,将已处理记录归档或者存放到历史表,这样可以保证队列很小);
b、一般的处理分为两步,是先找到未处理的记录、然后加锁,找到服务会增加服务器压力,而加锁会让各个消费者进程增加竞争;
(3)要解决的问题
如何让消费者标记正在处理的记录,而不至于让多个消费者重复处理一个记录
上一篇:https://blog.csdn.net/RuiKe1400360107/article/details/103783635
下一篇:https://blog.csdn.net/RuiKe1400360107/article/details/103963493
参考资料:《高性能MySQL 第三版》
### 若对你有帮助的话,欢迎点赞!评论!+关注!
