pythonのヒープソートアルゴリズム
注:この記事のノードと区別せずに使用するノード
ヒープの概念:
- ヒープは完全2分木であります
- 各非リーフノードの値は、ヒープビッグトップと呼ばれているよりも大きいか、左と右の子ノードに等しくなければなりません。
- 各非リーフノードの値が小さいスタックトップと呼ばれる左右の子ノード以下であることが
- ルートノードは、最大スタック大きな上部にする必要があり、スタックの最上部は、小さい最小でなければならない
スタック完全なバイナリツリーのノードの値は、特性点を有する、実際のノードからの観測値であります
ヒープタイプ
ヒープの特徴によれば、我々は二つのカテゴリーに積み重ねることができます
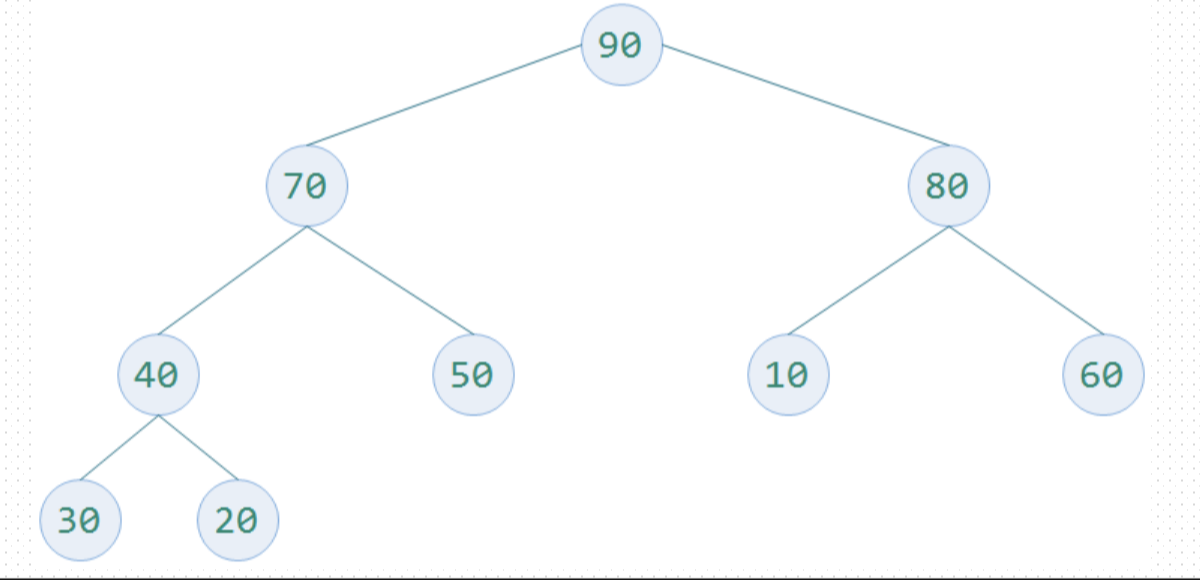
大スタックトップ
よりも大きいか、左右の子ノードの値に等しいバイナリツリーの各非リーフノードの、ルートノードは、スタックトップ、最大の値である必要があり、図1
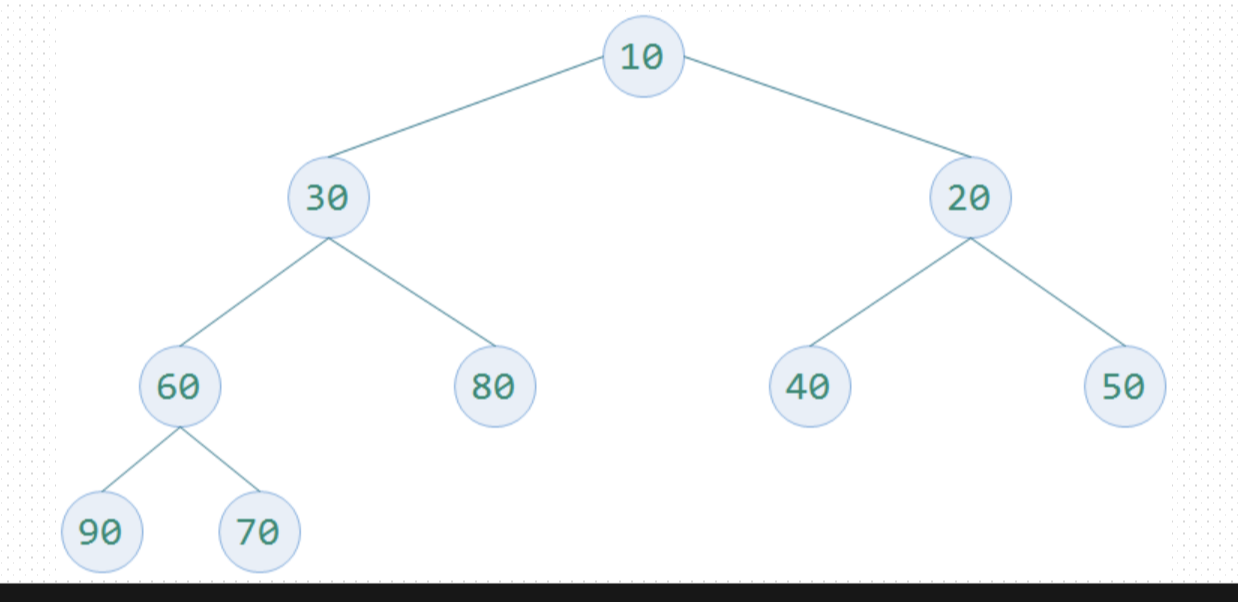
小さなトップは、スタック
、最小値は、大きいルートスタックのトップでなければならない左右の子ノードの値以下になるように各非リーフノードを図2に示すように
ヒープソートのステップ
完全なバイナリツリーの構築
オリジナルデータ:30,20,80,40,50,10,60,70,90
構造自然と要素5つの完全進数に応じて、データを保存するために、完全なバイナリツリー、:リストにデータ構造のシーケンスが設定されています【0,30,20,80,40,50,10,60,70,90】図のように、(0のノードと完全なバイナリ数字が一致する配列のインデックスに、挿入されています)。

大きなパイルトップの構築
スタックの先頭(または小さなヒープ上)よりも大きくなるようにキューを構築する方法、ヒープソートアルゴリズムはの中核である
分析
ノードの度合いの1 A 2、彼の左と右の子ノードの最大値は、その最大値よりも大きい場合ノードおよび為替の値
2.彼は左の子の場合はノード1度はその値は、スイッチよりも大きい
3ノード新しい位置に切り替えられた場合(この場合はノードA、すでに持っていたことをA子ノードは、しっかりと確保するかどうかを、子どもたちは)自分の接合点の比較を必要とする新しい位置する必要があるが、他の子ノード、および上記のプロセスを繰り返します
大トップスタックの1建設-開始ノードを選択する
ノードの数がnである場合、すなわち、親ノードが最終的に層の右端のリーフノードは、開始され、最後の完全なバイナリツリーノードの開始の親ノードから、各比較プロセスが、すべての数字を与えることができるようにすることを確実にする最初のノード2 // n個、比較的である(スタックは開始位置である9 @ 2 = 4)

2.大トップスタックの構築-次のノードを選択し、
開始点からヘッドから階層ノードとの接合部の左側及びその後右端ノードの層が根までつの検索だけ左にさらに開始するために、開始を見つけるために以下に示すようにノードは、順序は、4,3,2,1

3.大スタックトップ目標
値確実に接合約各ノード点以上の値
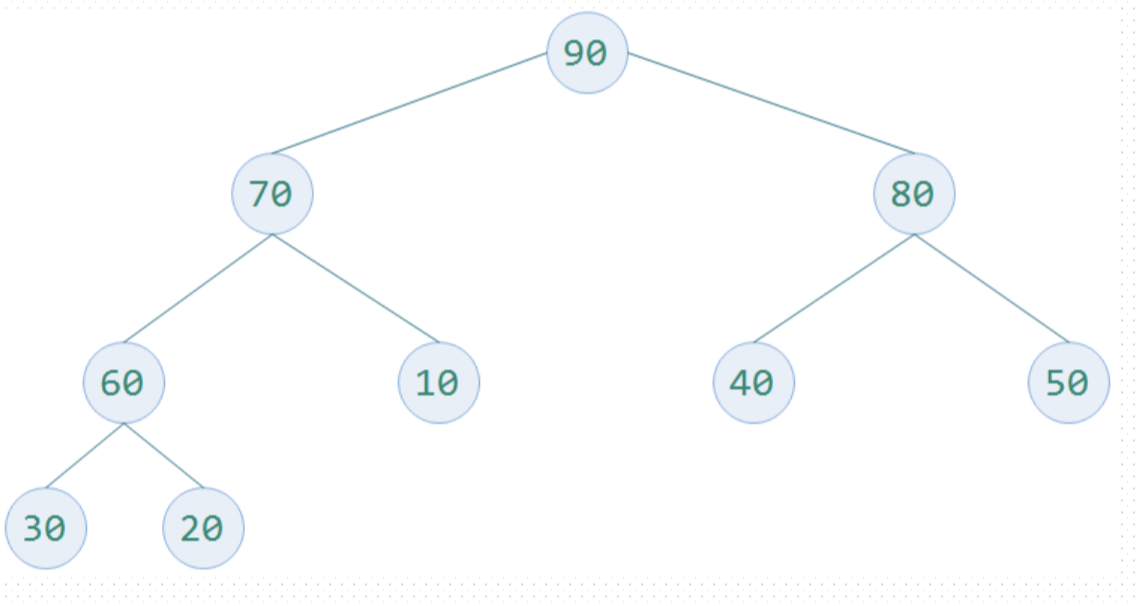
より多くの混沌は、図に見ることができます。

シーケンス
分析
1.最大ルート大トップスタックと最後のリーフノード交換、最後の点がリーフノードの最大値であり、このリーフノードは、ソートノードから除外すべき
ルートから2スタート(新しいルートノード)の後、大きなヒープの頂上に再調整し、前の手順を繰り返して
、ヒープと最後のノード交換の上部を発注し、そしてあなたが最後にそれを変更する理由、最後のノードを排除:依頼しますか?
A:データのヒープの上部には、これが最大(最小)値であり、その後、木に残って何もないことを確認し、必要に応じて、最後のリーフノード、良いマークの上に置きました。
概要
1.利用堆性质的一种选择排序,在堆顶选出最大值或者最小值(这也就是可以解决我们常见的TopN问题)
2.时间复杂度为O(nlogn)
3.空间复杂度:只是使用了一个交换用的空间,所以空间复杂度为O(1)
4.堆排序是一种不稳定的排序算法注:ヒープソート状態は、それが最善と最悪であるかどうか、元の録音の一種に敏感ではないので、時間計算量はO(nlogn)であります
コードの実装
#!/bin/env python
# -*- coding: utf-8 -*-
'''
__title__ = ''
__author__ = 'cxding'
__mtime__ = '2020/1/3'
# code is far away from bugs with the god
'''
import math
#居中打印 数量少的可以这么打印,多了就不行了
def print_tree(array,unit_width=2):
length = len(array)
depth = math.ceil(math.log2(length + 1))
index = 0
width = 2 ** depth -1 #行宽,最深的行 15个数
for i in range(depth):
for j in range(2 ** i):
#居中打印,后面追加一个空格
print('{:^{}}'.format(array[index],width * unit_width),end=' ' * unit_width)
index += 1
if index >= length:
break
width = width // 2 #居中打印宽度减半
print()
def sift(li:list,low:int,high:int):
'''
调整当前结点,这个时间复杂度最多是一棵树的高度,所以是logn
:param li: 列表
:param low: 堆的根结点位置
:param high: 堆的最后一个元素的位置
:return:
'''
i = low
j = 2 * i + 1 #j开始是左孩子
tmp = li[low] #把堆顶存起来
while j <= high: #只要j位置有数,没有超过堆的长度
if j + 1 <= high and li[j+1] > li[j]:
j = j + 1 # 如果有右孩子,并且他的值比左孩子大,将j指向右孩子
if li[j] > tmp:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
li[i] = tmp
break
else:
li[i] = tmp
#return li
li = [10,40,50,30,20,90,70,80,60]
def heap(li):
'''
实现堆排序,这里面的时间复杂度是nlogn,所以最终的时间复杂度就是nlogn,但是这个速度会比快排慢
:param li: 待排序的列表
:return:
'''
#构建大顶堆
n = len(li)
print("原始的序列为:")
print_tree(li)
for i in range(n//2 - 1,-1,-1):
print('-' * 30)
sift(li,i,n-1)#high为n-1,其实是取了极大值
print_tree(li)
print("准备出数了!")
#挨个出数
for i in range(n-1,-1,-1):
#将第一个元素和堆的最后一个元素交换
li[0],li[i] = li[i],li[0]
sift(li,0,i -1)#将最后一个元素排除在外,只需要调整堆顶的元素就是一个大顶堆了
print('-'*30)
print_tree(li)
heap(li)
さらに別の言葉遣い:
#!/bin/env python
# -*- coding: utf-8 -*-
'''
__title__ = ''
__author__ = 'cxding'
__mtime__ = '2020/1/13'
# code is far away from bugs with the god
'''
origin = [0,30,20,80,50,10,60,70,90]
total = len(origin) - 1
def heap_adjust(n,i,array:list):
'''
调整当前结点,主要是为了保证以i为堆顶的堆是一个大顶堆(或者小顶堆)
:param n: 待排序的序列的总长度
:param i: 当前结点,因为要是一个堆,所以他必须至少有一个子结点
:param array: 待排序的列表
:return:
'''
while 2 * i <= n:
lchild_index = 2 * i
if lchild_index < n and array[lchild_index] < array[lchild_index + 1]:#如果有右孩子,并且右孩子的值比左孩子大
#array[i],array[lchild_index + 1] = array[lchild_index + 1],array[i]
lchild_index += 1
if array[lchild_index] > array[i]:#接上面,已经得到了左右结点中最大结点的index,只要将其与当前结点比较,得到最大的直接就可以了,
# 如果当前结点就是最大的,就不用比较了,这棵子树就是大顶堆了,这是有前提的,前提是认定了,已经从len(li) // 2开始进行了一次次向上了
array[i],array[lchild_index] = array[lchild_index],array[i]
i = lchild_index
else:
break
#调整成大顶堆
for i in range(total//2,0,-1):
heap_adjust(total,i,origin)
'''
heap_adjust(total,4,origin)
print(origin)
heap_adjust(total,3,origin)
print(origin)
heap_adjust(total,2,origin)
print(origin)
heap_adjust(total,1,origin)
print(origin)
#[0, 90, 50, 80, 30, 10, 60, 70, 20]
'''
print(origin)
#[0, 90, 50, 80, 30, 10, 60, 70, 20]
def heap(max_heap:list):
length = len(max_heap) - 1
print("length ---> ",length)
print("origin--->",max_heap)
for i in range(length,1,-1):
print("i-->",i,"element--",max_heap[i])
max_heap[1],max_heap[i]= max_heap[i],max_heap[1]
heap_adjust(i-1,1,max_heap)
heap(origin)
print(origin)