図1に示すように、環境を準備するために、探査データ
インポートnumpyのAS NP から keras.modelsはインポートシーケンシャル から keras.layers インポート高密度 インポートASのPLTのmatplotlib.pyplot #は、データセット作成 RNG = np.random.RandomState(27 ) X- = np.linspace(-3 ,. 5、300 ) RNGを(X-).shuffle #セット無作為 。Y = 0.5 * X- + + np.random.normal 1(0、0.05、300) #は実際のモデルがあると仮定する:Y = 0.5X + 1 #描画データセット plt.scatter (X、Y、S = 0.5 ) plt.show()
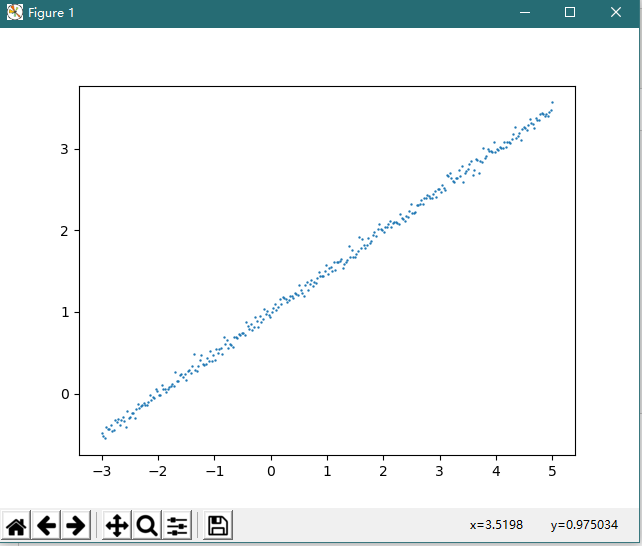
2、データ準備トレーニングモデル
#セットトレーニングセットとテストを分割 X-y_train =、X_trainを[400]、Y [400 ] X_test、android.permission.FACTOR。 = X - [ - 100:]、Y [-100 :] #の定義モデル モデルシーケンシャル()= 位Kerasとシーケンシャルモデル(シーケンシャルに)定義のモデルに基づいて、単一入力単一出力を model.add(高密度は(output_dim = 1、input_dim = 1)) #add()メソッドの一つ、高密度完全接続層は、第一の層を定義します入力 #セットモデルパラメータは、 (損失= model.compile 「MSE 」、オプティマイザ= 「SGD 」) #損失関数(コンパイルすることによって選択するように()メソッドを平均二乗誤差)とオプティマイザ(確率的勾配降下法) #は、訓練開始した 印刷("トレーニング========== ' ) のための工程における範囲(301 :) コスト = model.train_on_batch(X_train、y_train) #Keras的train_on_batch()函数训练模型 であれば、ステップ100%== 0: プリント(「電車費用:」、コスト)
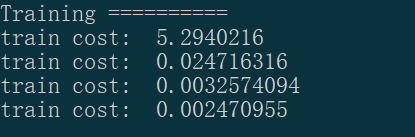
3、訓練されたモデルをテスト
印刷(' \ nTesting ========== ' ) コスト = model.evaluate(X_test、android.permission.FACTOR、BATCH_SIZE = 40。 ) プリント(' テストコスト:' 、コスト) Wであり、B = model.layers [0 ] .get_weights() #は、訓練されたネットワークパラメータが表示
印刷(「重み= 」、Wが、である「\ = nbiases 」、B) #を、ネットワークが一層のみを有しているので、入力と出力トレーニングのそれぞれ一つだけのノード最初に1訓練されたY = WX + Bモデル、前記W、訓練されたパラメータとしてB

最終テストのコストは、次のとおりです。0.0026768923737108706
4、視覚検査結果
y_pred = model.predict(X_test) # 用测试集进行预测 plt.scatter(X_test, y_test, s=4) # 绘制测试点图 plt.plot(X_test, y_pred, lw=0.7) # 绘制回归直线 plt.show()

。。。