Hadoopのビッグデータ技術が判明したとして、開発の年後に、Hadoopのは、特定の技術ではなく、完全なビッグデータのエコロジーを参照していません。
単一のマシンが完了大きいデータ記憶できないので、Hadoopのは、これらのデータを操作し、データを別のマシンに別々に格納する必要があり、アクセスするように単一のマシンのアクセス画像データにユーザーを可能にするので、処理、システムの分散性質であります。HDFSとMapReduceの:このタスクを達成するために、Hadoopの年には、前方に二つの概念を入れました。
HDFS
すなわち、Aデータ記憶方式を分散、その役割は、データの格納部に、複数のマシンから成るクラスタ内の各マシンに大量のデータを格納することです。
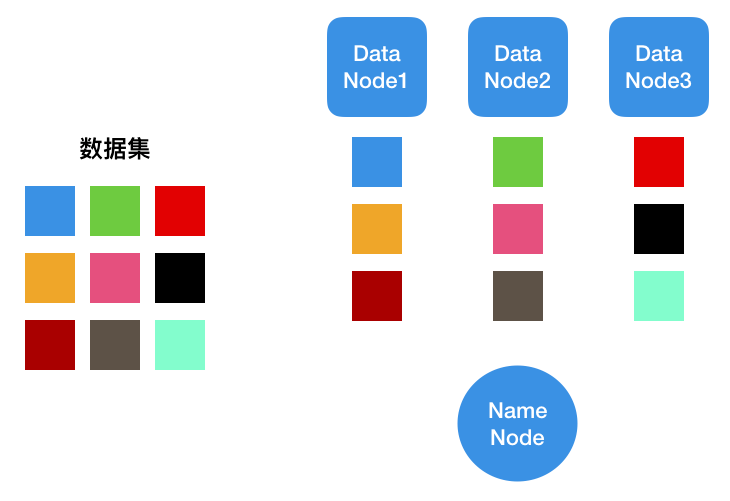
我々は、すなわち、データNode1,2,3右、及び、HDFSクラスタストレージノードを含む、格納されたデータセットを残すことにしたいと仮定名ノードは、各データブロックの位置を記憶するために配置されています。たとえば、私たちは今、次のステップに分けたアクセスデータ・ブロック、青と緑のブロックを、する必要があります。
-
クライアントは、データ・ブロックの青と緑のデータブロックの位置を取得し、名前ノードへの要求を行います
-
データノード2の名前ノードデータノード1のリターンアドレス
-
クライアントアクセスデータNode1およびNode2のデータ
私たちは、クラスタ内のデータを増やしたい場合は、次の手順に従います。
-
クライアントが名前ノードへの書き込み要求を送信します
-
名前ノード確認要求し、データノードのアドレスを返します。
-
スタートは、宛先アドレスにデータを書き込むと、対応するマシンが正常に書き込まれ正常に書き込まれ時に確認メッセージを返します。
-
クライアントは、名前ノードに確認メッセージを送信します
図から分かるように、最も重要なは、ファイルシステム全体の情報を管理するクラスタ全体のノード名ノード、及び対応するスケジュールファイル操作です。もちろん、クラスタは必ずしもないだけ名前ノードは、のみ、名前ノードならば、それは全体のクラスタが動作を停止していますサービスを提供することはできません。
ちょうど新しいデータが書き込まれるクラスタは、データのバックアップを必要とするなど、最も簡単な場合、より複雑な実際の状況、などの上述したデータ・ストレージ・アクセス操作の概念は、書き込みバックアップデータも複雑なプロセスです。
MapReduceの
MapReduceのプログラミングモデルは、地図2で、削減操作を処理する分散データを簡素化するであろう、抽象的です。MapReduceのが表示される前に、我々はタスクを完了したい場合、多くのサブタスクにタスクを打破するための最初の必要性は、その後、あなたは異なるサブにこれらのタスクを割り当てるため、データの分散クラスタ処理は非常に分散し、複雑なクラスタです機械の結果、最終的にサブの作業を完了は、サブタスクは、合併、集計などの操作によって生成される必要があります。
このプロセスのMapReduceの抽象化は、それはマシンは、2つのカテゴリ、すなわち、マスターと労働者に分けられます。マスターは、スケジューリング作業を担当して、労働者のマシンは、実際にタスクを実行します。労働者は、2つのタイプ、マッパーとリデューサーに分けることができます。個々のマッパーの結果の概要の実行を担当するサブタスクマッパー、リデューサーの実装の主な原因。
私たちは、プロセスを説明するために簡単な例を使用することができ、たとえば、今、私たちは数字からトランプのA杭の数を必要とする、我々はいくつかのトランプに分割されます、カードの数のシェアで皆(マッパー)うちの数は、少数の個人デッキ1があり、デッキ2は、個人番号を持っています。最後に、それぞれの数は結果が要約され、完成された(リデュース)まで、カードのスタック全体は、Aさんの数です。
もちろん、本当の課題は、より多くのこれらの二つの操作よりも、すなわちデータをカット、スプリットなどが、シャッフルは、すなわち、データおよびその他の操作を分類しています。これらの操作のデザインは特に繊細で、設計されていない場合は、システム全体のパフォーマンスに影響を与える可能性があります。

我々は電気の供給業者のサイトを持っている、大規模な購入記録のユーザーを保存する場合たとえば、私たちはデータを処理したい場合、どのようにこのデータを断片化?私たちは、断片化の指標としてユーザの年齢に言うならば、それはユーザーの20〜30歳のグループの数であってもよいユーザー70+年齢層の数よりもはるかに大きいです。50歳+のユーザーデータ等の処理が完了すると、まだプロセス内のユーザデータ20〜30歳のグループ。これは、各ワーカーのための処理時間に変化をもたらしたタスクの完了の進行を遅らせました。また、MapReduceは複雑なタスクのためにこの抽象は、大規模なロジックの量、および依存関係に、シンプルを達成することは非常に困難です。要するに、MapReduceはこのモデルは、業界の後で、実際に次のような問題が発生しました:
- その後、全体のプロセスが大幅に遅れることになる合理的なセグメンテーションデータが存在しない場合は地図の完了後、必要性を削減
- マップや複雑なロジックに対処する上で、やや非力削減
- 性能瓶颈,因为MapReduce处理的中间结果需要存放在HDFS上,所以写入写出时间大大影响了性能
- 每次任务的延时巨大,只适合批量数据的处理,不太能处理实时数据
Spark
Spark的出现一定程度上解决了上述的问题,可以作为MapReduce的替代品。其速度远远超过Hadoop的MapReduce,
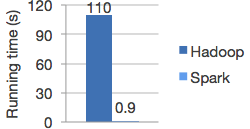
为了完成这个一步到位,不需要硬盘多次读写的任务,Spark提出了新的思想,即RDD,基于分布式内存的数据抽象。
RDD的全称叫做Resilient Distributed Datasets,即弹性分布式数据集,基于RDD,Spark定义了很多数据操作,比起MapReduce,大大提高了逻辑的表示能力。
当然,RDD这个概念十分难以理解,它并不是一个实际存在的东西,而是一个逻辑上的概念,在实际的物理存储中,真实的数据仍然是存放在不同的节点中。它具有以下几个特性:
- 分区
- 不可变
- 能并行操作
分区
分区的意思是,同一个RDD中的数据存储在集群不同的节点中,正是这个特性,才能保证它能够被并行处理。前面提到,RDD是一个逻辑上的概念,它只是一种数据的组织形式,我们可以用下图来说明这个组织结构:

不可变
各RDDは読み取り専用です、パーティション情報に含まれるが、変更することはできません。既存のRDDを変更することはできませんので、データのすべての操作ので、結果として新しいRDDを生成します。新しいRDDは毎回生成し、我々はそれを記録する必要が新旧RDDの依存ので、RDDが来操作によって変換され、このことの利点は何もありませんことを生成し、格納されたデータのすべての段階で、ステップの場合失敗した、それだけですべての操作を繰り返す必要がなく、再び作動する前のステップのRDDにロールバックする必要があります。具体的な内容は、その後の記事にあっ専念され、より複雑なロジックを実現するために頼ってここに記載されていません。
並列運転
前述のデータは、それが並列に処理できることを保証するために、この特徴で、同じRDD異なるクラスタ・ノードに格納されています。異なるノードからのデータを別々に処理することができるので、
さまざまな人々の手の中に私たちは、このような最初の小平郭などの皮、のタイプの順序に従って、これらの果物を与える場合たとえば、今、人々のグループの手に全てカット梨後、桃、最終的なカットが、確かに果物で、いくつかの果物を保持していることができます並列タスクを完了しました。人とリンゴ、ナシの手で人の手ならば、その人は継続して完全にカットするために別の人を待つことができます。
概要
MapReduceのに比べて、スパークは、実質的に改善された性能を得るために、いくつかの改良を行いました。
- 代わりに、読み取りおよび書き込み速度を大幅に向上させることができ、ハードディスクのデータメモリに点火操作
- 各ステップにおけるスパークタスクの結果は、ディスクに書き込ま生成するために必要な、だけので、耐障害性を向上、操作間の依存関係を記録し、大幅に回復作業のコストを削減されていません
- データを並列に処理することを可能にする使用ゾーニング、
著者:水のカエル
リンクします。https://juejin.im/post/5dc29951f265da4cef190de6
出典:ナゲッツの
著者によって予約の著作権。著者は認可商業転載してください接触、非商用の転載は、ソースを明記してください。