ディレクトリ
著者は、問題を解決したいです
これは、一段階、正と負の、アンバランスの難しさのサンプル中の古典的な問題が残っています。そのため、アンカーの、POS:NEG> = 1:70。陰性サンプルのほとんどは、それはまた、困難なサンプルの問題を引き起こし、比較的簡単です。
フォーカル損失(CVPR2017)
フォーカル損失ソリューション
従来のクロスエントロピー損失関数:
\ [。L_ {CE} = - [P ^ *(ログ(P)+(1-P ^ *)ログ(1-P)] \]
\(P ^ * = \ {0 、1 \} \) 、実際のタグである)((0、1でP \)\ \ネットワークの予測確率を見ることができる、機能等しい正及び負のサンプルは、従来のクロスエントロピー損失を見ている。
焦点損失
\ [L = - [\アルファP ^ \
ガンマP ^ *ログ(P)+(1- \アルファ)(1-P)^ \ガンマ(1-P ^ *)ログ(1-P)] \] これらは参照フォーカル損失は、スーパーの2つのパラメータを導入(アルファ、\ガンマ\ \)\、\ (\アルファ\) 、正と負のサンプルのバランスをとるために(\ガンマ\)は\。サンプルのしやすさのバランスをとるために使用される単純な分析を、プラス左は、陽性試料の損失であり、右側は、異なる係数を乗算することにより、負のサンプルの損失である\(\アルファ1-(\アルファ)\) 、陽性および陰性試料のバランスをとるために単純なサンプルについて、その小さな損失確率は、近いラベルの真値になるように確率\(\ガンマ\)電源小さく、逆に、それは大きなサンプルが困難となり、損失が試料を増大させることは困難であり、サンプルがネットワークに焦点を当てることは困難です。
未満の焦点損失
この論文の焦点損失をある程度有するが、正および負のサンプルの不均衡の問題を解決するが、発表2つの超焦点損失パラメータ、パラメータ調整激しい、およびのみボックス分類に適用することができ、回帰の問題を解決できません。
デザインのアイデア
サンプルの勾配の間の関係
著者らは、勾配が(単純サンプル)が小さいときに困難サンプルの勾配の分布は以下の関係を見ることができるしていることが観察され、サンプルサイズは、勾配が緩やかである場合に、より少ないサンプル非常に大きいです。また、注目に値する1程度の勾配でのサンプル数またはロットということです。特に困難な異常であると考え、これらの試料の著者は、追加のサンプルに正確な割合原因サンプルを解決するために。
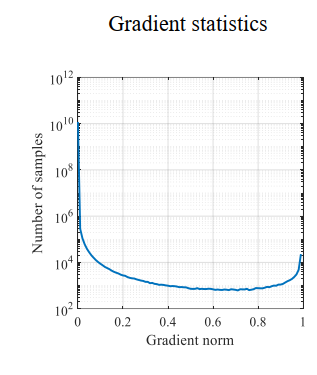
以上の知見のために困難サンプル不均衡の問題に対処するため、著者ら勾配分布(勾配近傍のサンプルの数)。考え方は単純な勾配小さなサンプルサイズが比較的大きい、次に小さい係数、少なくとも大係数を乗じの勾配大きいサンプルに乗るそれらを与えるあります。しかし、この要因は、自分の曲に依存するが、サンプルの勾配分布に基づいて決定されていません。
勾配プロファイル計算方法:0-1カットビンの勾配は、各ビン内に入るサンプルの数を計算します。
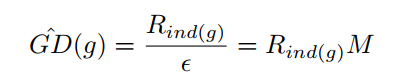
前記\(\イプシロン\)は、各ビンの幅である(M \)\である\(\イプシロン\)の逆数、ショービンに0-1カットの数、\(R_ {IND(G)} \ )、サンプル数が各ビン内に入る表し、以下のように計算されます。
\ [R_ {IND(G)} = \ sum_ {k = 1} ^ {N} \デルタ(g_k、G)\クワッド\デルタ(g_k、G)= \ {ケース} 1つの\クワッドを開始する場合\クワッドG - \ FRAC {\イプシロン} {2} <= g_k <= G + \ FRAC {\イプシロン} {2} \\ 0 \クワッドさもなければ\端{ケース} \]
\ [\ Beta_i = \ FRAC {N} {GD(G_i)} \]
\(G \)は、点の勾配ノルムであり、これはビンを作成するように、理解することができる\(G_k \)サンプルの勾配ノルムであります、Nは全サンプル数です。
これは、係数が小さいほど、勾配が大きいほど、上記の式から分かります。
グラデーションノルムを計算します
具体的には第二のカテゴリーで、クロスエントロピー機能の喪失は、上記の関数である
- \ [L_ {CE} = ] [P ^ *(ログ(P)+(1-P ^ *)ログ(1-P)\ \ P =シグモイド(X)\
] xの勾配
\ [\開始{整列} \ FRAC {\部分L_ {CE}} {\部分X}&= \ FRAC {\部分L_ {CE}} {\部分P} \回\ FRAC {\部分P} {\部分X} \\&=( - \ FRAC {P ^ *} {P} + \ FRAC {1-P ^ *} {1-P})\回P(1-P)\\&
= PP ^ * \端{整列} \] 定義勾配モード\(G = | P-P ^ * | \)
改善します
GHM-Cの損失関数
したがって、著者らは、GHMの分類C-損失関数を提案する
\ [のGHM-L_ {C} = \ FRAC。1 {N} {} \ {CE beta_i} SUM \ L_(P_I、P_ ^ {} * {I})\ ]
勾配が小さい場合、多数のサンプル、勾配プロファイルまたは例えば、この図では、 \(GD(G)は\) 、次いで係数が小さい大きいされ、損失が効果的にサンプルの単純な多数の効果を減少させる、小さいです。そして、その逆。同じことが、抑制されたサンプルを分析するのが特に困難であり得ます。また、これは参照するには、著者ほしいですです。
このグラフの下方横軸は元の勾配分布、勾配分布縦軸はプロセスを表します。言及特に価値がある任意の処理をせずにCEコントラスト曲線、勾配0の近傍に、GHM-C後処理勾配が低減され、約0.5の勾配が増幅された試料は、前述の異常なサンプルについて、それであります勾配は、同様に抑制されました。比較焦点損失曲線GHM-Cは、より優れて明らかです。

GHM-Rの損失関数
それだけで罰金下勾配を求めて以前のように理にかなっているが、問題があります。
伝統的なボーダー損失関数の戻り値についてはsmooth_L1
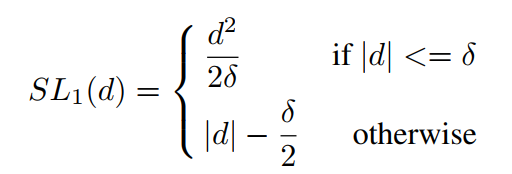
探している勾配ノルム
\(D = T_I - T_I ^ * \)
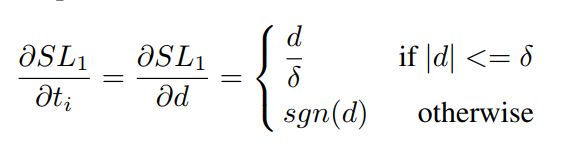
見ることができる、その場合 \(D> \デルタ\) 水平勾配モジュール1は、試料を測定することができない難易度。そこで、著者はここに少し変更しました
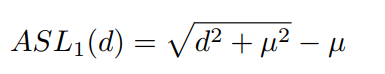
Dと同様、比較的小さな \(L_2 \) 同様の場合も大きいと、D \(L_2 \) 、および \(SL_1は\) と同様です。最終損失の機能は以下のとおりです。
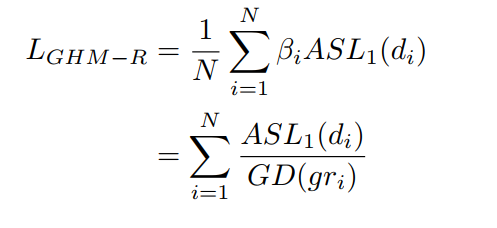
関数の戻り値の損失が唯一の陽性サンプルを計算されますので注意してください。
最終結果
データセットCOCOの比較
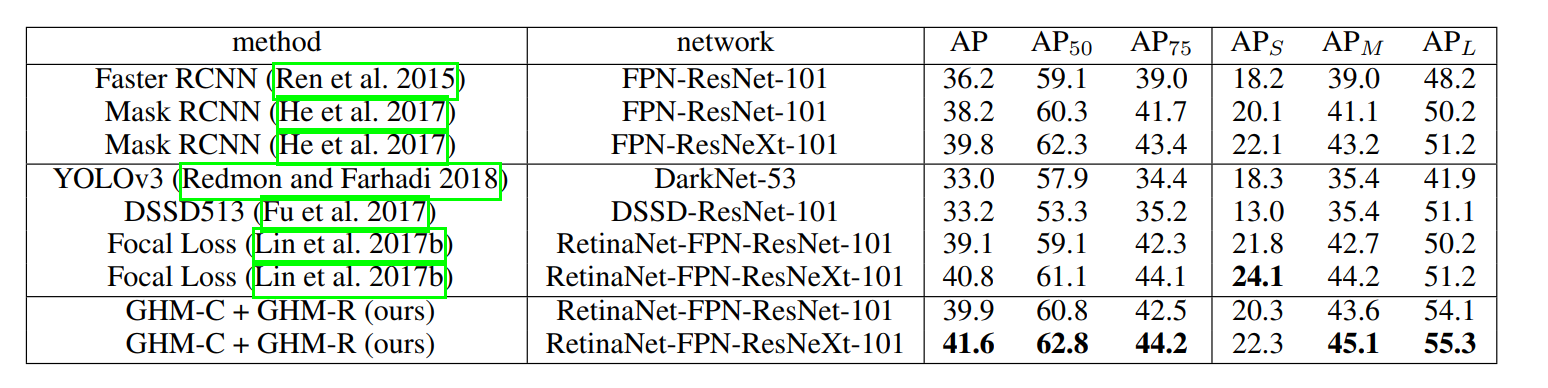
比較的GHM-C
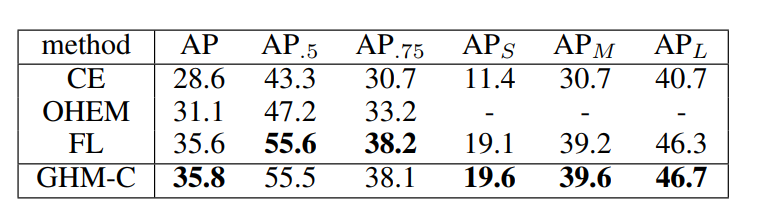
比較GHM-Rでのみ
