09線形回帰行列演算
直線回帰
定義:1つまたは複数の独立変数と従属変数の間の回帰モデルによって分析しました。1つ以上の独立変数間の線形の組み合わせであってもよいです。
線形回帰は:1つの変数のみが含ま
2つの以上の変数:線形回帰を一般式:H(W)= W0 + w1x1 + w2x2 +···= WTX
式中、W、X行列:WT =(W0、W1、 W2)X =(1、X1、X2)T
シナリオの回帰(連続データ)
- 価格予測
- 売上高予想(広告、R&Dコスト、サイズ、およびその他の要因)
- 融資額
リニア関係モデル
- 定義:の線形結合の性質(特性)によって予測された機能:
- F(X)= w1x1 + w2x2 + w3x3 + ... + wdxd + B
- W:Bの重量(重量):バイアス(バイアス項)
- 複数の特徴:(W1:家の面積、W2:家の場所..)
損失関数(エラー)
- 「統計的学習」 - アルゴリズム、戦略、最適化
- 線形回帰、最小二乗法、正規方程式&グラデーションディセント
- 損失関数(サイズエラー)
- 李氏は学習サンプルのi番目の実際の値であり、
- HW(XI)がI TH訓練サンプル特性値の組み合わせの予測関数(予測値)であります
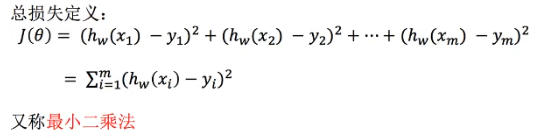
- ワットの検索エンジン最適化
- 最小二乗正規方程式(最小に直接溶液は、特徴は、複雑な解決する方法はないかもしれません)
- 溶液:W =(XTX)-1 xTy
- Xは、Yが目標行列の固有値行列であります
- デメリット:機能は、解決に時間がかかる、複雑すぎます
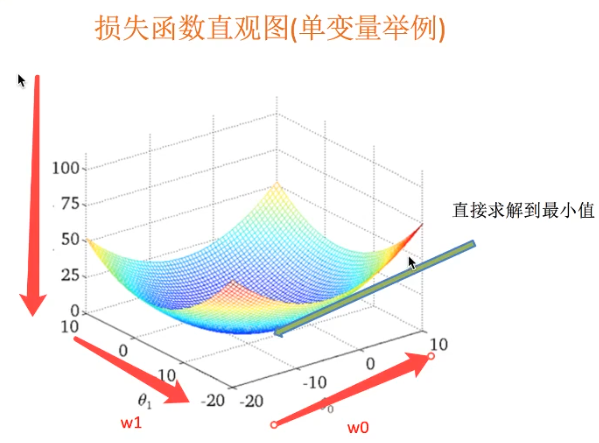
最小二乗勾配降下

- 使用シナリオ:トレーニングデータのタスクの大規模を考えます
- スーパーパラメータ:A
- 最小二乗正規方程式(最小に直接溶液は、特徴は、複雑な解決する方法はないかもしれません)
線形回帰アルゴリズムケース
API
- sklearn.linear_model.LinealRegression()
- 回帰線形最小二乗
- coef_:回帰係数(W値)
- sklearn.linear_model.SGDRegressir()
- 線形モデルを使用することによって最小化さSGD
- coef_:回帰係数
- 手動で学習率を指定することはできません
波士顿房价预测
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
"""
线性回归预测房价
:return: None
"""
# 1. 获取数据
lb = load_boston()
# 2. 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 3. 进行标准化处理(特征值和目标值都必须标准化处理)
# 实例化两个标准化API,特征值和目标值要用各自fit
# 特征值
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 4. estimator预测
# 4.1 正规方程求解预测结果
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_)
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print('正规方程测试集里面每个房子的预测价格:', y_lr_predict)
print('正规方程的均方误差:',mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
# 4.1 梯度下降进行梯度预测
sgd = SGDRegressor()
lr.fit(x_train, y_train)
print(sgd.coef_)
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print('梯度下降测试集里面每个房子的预测价格:', y_sgd_predict)
print('梯度下降的均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
return None
if __name__ == '__main__':
mylinear()
回归性能评估
均方误差 (Mean Squared Error MSE) 评价机制
- mean_squared_error(y_true, y_pred)
- 真实值和预测值为标准化话之前的值

两种预测方式的选择
- 样本量选择
样本量大于100K --> SGD 梯度下降
样本量小于100K --> 其他
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量大时也能较好使用 | 需要计算(xTx)-1,运算量大 |
| 适用于各种类型的模型 | 只适用于线性模型 |
- 特点:线性回归器是最为简单、易用的回归模型,在不知道特征之间关系的情况下,
可以使用线性回归器作为大多数系统的首要选择。LinearRegression 不能解决拟合问题。
过拟合与欠拟合
- 定义:
过拟合(overfitting):一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外却不能很好拟合。(模型过于复杂)
模型复杂的原因: 数据的特征和目标值之间的关系不仅仅是线性关系。欠拟合(underfitting):一个假设在训练数据上不能获得更好的拟合,但是在训练数据外也不能很好的拟合。 (模型过于简单)
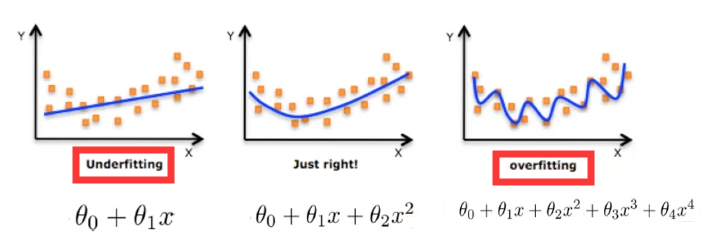
欠拟合原因及解决方法
- 原因: 学习到的数据特征过少
- 解决方法: 增加数据的特征数量
过拟合原因及解决方法
- 原因: 原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点
- 解决方法:
- 进行特征选择,消除关联性很大的特征(人为排除,很难做)
- 交叉验证(让所有数据都有过训练)- 检验但不能解决
- 正则化 :不断尝试,减少权重(高次项特征的影响)
- 特征选择:
- 过滤式:低方差特征
- 嵌入式:正则化,决策树,神经网络
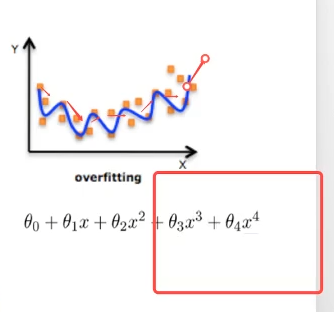
(减少高指数项系数,趋近于0,减少权重)
L2正则化
- 作用:可以使得W的每个元素都很小,都接近于0
- 优点:越小的参数说明模型越简单,越简单的模型越不容易产生过拟合现象。
- 回归解决过拟合的方式:
L2正则化, Ridge:岭回归:带有正则化的线性回归,解决过拟合。
Ridge API
sklearn.linear_model.Ridge(alpha=1.0)
- 具有L2正则化的线性最小二乘法
- alpha: 正则化力度 0~1(小数), 1~10(整数)
- coef_: 回归系数
正则化力度对权重的影响 (力度越大,越趋向于0)
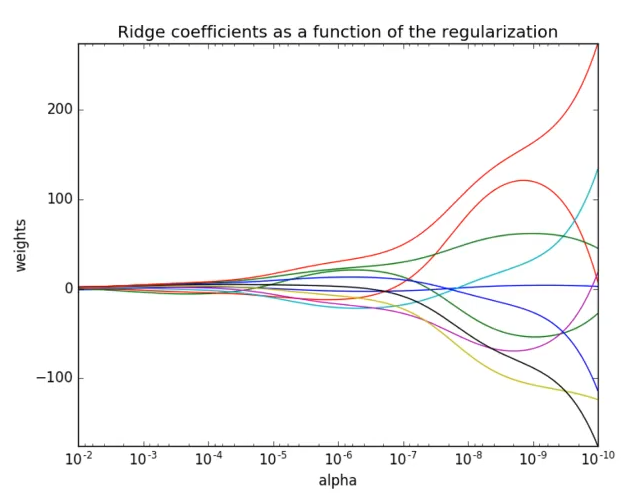
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
"""
线性回归预测房价
:return: None
"""
# 1. 获取数据
lb = load_boston()
# 2. 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 3. 进行标准化处理(特征值和目标值都必须标准化处理)
# 实例化两个标准化API,特征值和目标值要用各自fit
# 特征值
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 4. estimator预测
# 4.1 正规方程求解预测结果
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_)
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print('正规方程测试集里面每个房子的预测价格:', y_lr_predict)
print('正规方程的均方误差:',mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
# 4.2 梯度下降进行梯度预测
sgd = SGDRegressor()
lr.fit(x_train, y_train)
print(sgd.coef_)
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print('梯度下降测试集里面每个房子的预测价格:', y_sgd_predict)
print('梯度下降的均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
# 4.3 岭回归预测
rd = Ridge(alpha=1.0)
rd.fit(x_train, y_train)
print(rd.coef_)
y_rd_predict = std_y.inverse_transform(rd.predict(x_test))
print('岭回归测试集里面每个房子的预测价格:', y_rd_predict)
print('岭回归的均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict))
return None
if __name__ == '__main__':
mylinear()
线性回归LinearRegression 与 Ridge对比
岭回归:回归得到的回归系数更符合实际,更可靠。另外,能让估计参数的波动范围变小,变得更稳定。在存在病态数据偏多的研究中有较大的使用价值。
模型的保存与加载
sklearn API
sklearn.Externals import joblib
- 保存: joblib.dump(rf, 'test.pkl') - 保存的实例和路径 , rf - 训练生成的实例,文件格式为pkl
- 加载: joblib.load( 'test.pkl') - 加载路径
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
def mylinear():
"""
线性回归预测房价
:return: None
"""
# 1. 获取数据
lb = load_boston()
# 2. 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 3. 进行标准化处理(特征值和目标值都必须标准化处理)
# 实例化两个标准化API,特征值和目标值要用各自fit
# 特征值
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 4. estimator预测
# 4.1 正规方程求解预测结果
# lr = LinearRegression()
# lr.fit(x_train, y_train)
# print(lr.coef_)
# y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
# print('正规方程测试集里面每个房子的预测价格:', y_lr_predict)
# print('正规方程的均方误差:',mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
# 保存训练好的模型
joblib.dump(lr, './test.pkl')
# 导出模型
model = joblib.load('./test.pkl')
y_predict = model.predict(x_test)
print('保存的模型预测的结果:', y_predict)
# # 4.2 梯度下降进行梯度预测
# sgd = SGDRegressor()
# lr.fit(x_train, y_train)
# print(sgd.coef_)
# y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
# print('梯度下降测试集里面每个房子的预测价格:', y_sgd_predict)
# print('梯度下降的均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
#
# # 4.3 岭回归预测
# rd = Ridge(alpha=1.0)
# rd.fit(x_train, y_train)
# print(rd.coef_)
# y_rd_predict = std_y.inverse_transform(rd.predict(x_test))
# print('岭回归测试集里面每个房子的预测价格:', y_rd_predict)
# print('岭回归的均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict))
return None
if __name__ == '__main__':
mylinear()