杭では、ポストの畳み込みを紹介し、色が発芽している中で、この例では、ユニークである、それは睡眠の前に読み取りが周Gongziを見ることができることを保証するために、当然のことながら、非常に直感的なビジュアル・ドロップで、輝いています。
https://でtowardsdatascience.com/ タイプ・オブ・コンボリューション・カーネル・簡易f040cb307c37
直感的には、様々な魅力的なCNN層を説明します
簡単な紹介
入力画像から「カーネル」を抽出いくつかの「機能」を使用して畳み込み。カーネル行列であるので、いくつかの拡張出力における所望の行動こと、画像上に摺動自在に入力を乗じました。以下のGIFを見てください。

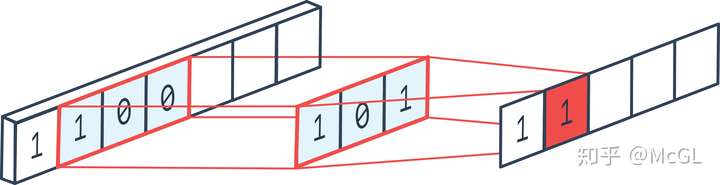
上記画像カーネルを鮮鋭化するために使用することができます。しかし、カーネルはそれについてとても特別な何ですか?図に示される二つの入力画像を考えます。最初の画像、中心値+ 2 * 3 * 5 * -1 -1 + 2 + 2 + 2 * -1 * -1 = 7、3~7の値。第2の画像が、出力は1 + 5 * 2 * 2 * -1 + -1 + 2 * -1 = -1 + 2 -3は、1の値が小さくなる-3。明らかに、3と7との間のコントラストとは、1~3、より鮮明な画像を増加させました。

深いCNNすることにより、我々は、手動設計機能のカーネルを抽出する必要はありませんが、これらのカーネルの抽出潜在的な価値が直接学ぶことができます。
カーネルとフィルタ
私は多くの人々がそれらを混同見てきたので、徹底的な議論の前に、私は、「カーネル」と「フィルタ」二つの用語を明確に区別したいと思います。上述したように、カーネルは重み行列であり、重み行列は、関連する特徴を抽出する入力と乗算されます。コンボリューションカーネルの名前は、行列の次元です。例えば、2D畳み込みカーネル行列は、2次元行列です。
しかし、フィルタカーネルは、一連の複数であり、各カーネルは、特定の入力チャンネルに割り当てられます。常に新入生より次元フィルタカーネルです。例えば、2次元畳み込みで、フィルタは、3Dマトリックス(シリーズの本質的に2次元マトリクス(すなわち、カーネル))です。このように、入力チャネル、フィルタサイズk * H * WのカーネルサイズH * W kのCNN層用。
共通の畳み込み層は、実際にそのようなフィルタの複数から構成されています。特に断りのない限り、フィルタはすべて同じ操作を繰り返すことになりますので、以下の議論を単純化するために、、、1つのフィルタのみが存在することを前提としています。
1D、2Dおよび3Dコンボリューション
(入力された一次元のため、この場合には)、一般に時系列データを分析するために使用される二次元畳み込み。上述したように、一次元データは、複数の入力チャネルを有していてもよいです。フィルタは、一方向のみに移動するので、1Dの出力。単一チャネルの一次元畳み込みの以下の例を参照してください。
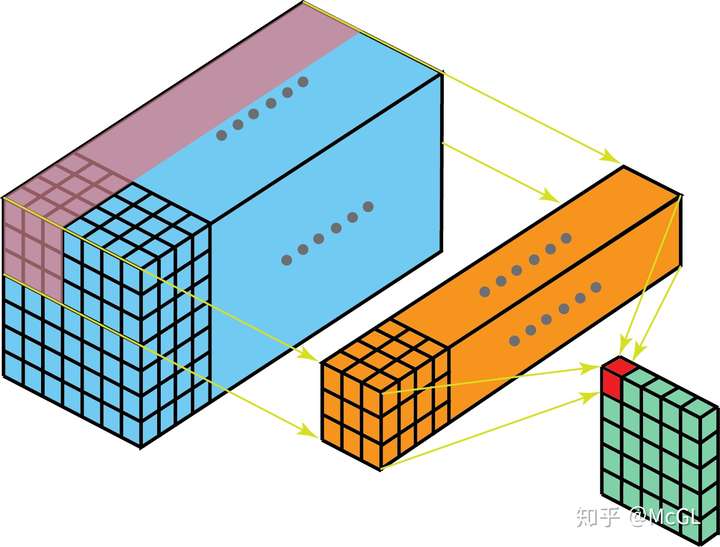
我々はすでにので、私たちは、マルチチャンネルの2D畳み込みを視覚化し、それを理解してみましょう、私の記事の冒頭でシングルチャネルの2Dコンボリューションの例を見てきました。以下の図では、カーネルの3×3のサイズ、および(黄色でマークされた)そのようなフィルタカーネルが複数存在します。入力チャネル(青でマークされた)各チャネルが複数存在するためである、と我々は、入力に対応するカーネルを持っています。明らかに、ここでフィルタは、二つの方向に移動させることができるので、最終的な出力は、2Dです。2Dコンボリューションコンボリューションは、広くコンピュータビジョンで使用される、最も一般的です。
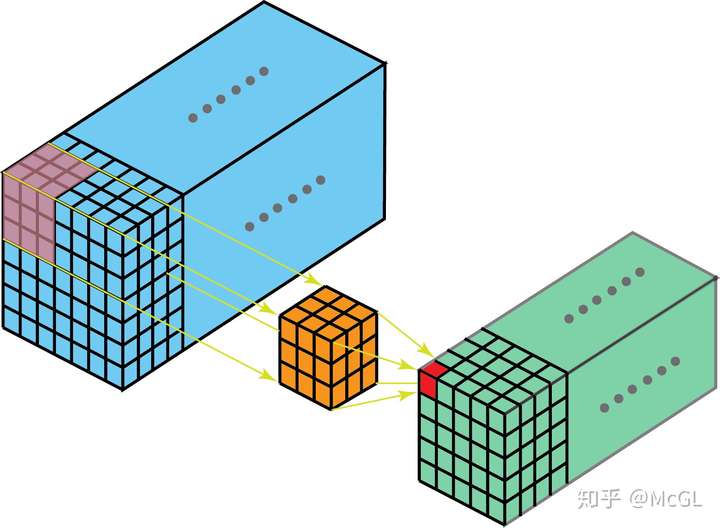
(それがあるので、4D行列)我々は唯一の単一チャネルの3D畳み込みを議論するように、3Dフィルタを視覚化することは困難です。三次元畳み込みに示され、カーネルは、このように、3D出力も取得、三の方向に下に移動させることができます。
修正で行われた作業とカスタムCNN層の大半は、私だけが唯一の2Dコンボリューションの変異体を説明しますので、今から、2次元畳み込みの側面に焦点を当てました。
転置(転置)コンボリューション
入力のサイズを小さくする方法を、次のよく文書GIF 2D畳み込み。しかし、時には我々は(また、「サンプリング」という。)及びその上で、このようなサイズの増加などの入力を処理する必要があります。

この目標を達成するために使用するコンボリューションするために、我々は、畳み込み変更(多くの人が長期的なデコンボリューションを使用して好きではないので、それは、真の「逆転」畳み込み演算ではありません)転置畳み込みまたはデコンボリューションと呼ばれる使用します版。破線ブロック下のGIFは、パディングを表します。
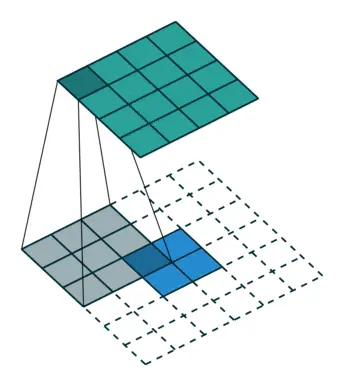
这些动画很直观的展示了如何基于不同的padding模式从同一输入产生不同的上采样输出。这种卷积在现代CNN网络中非常常用,主要是因为它们具有增加图像尺寸的能力。
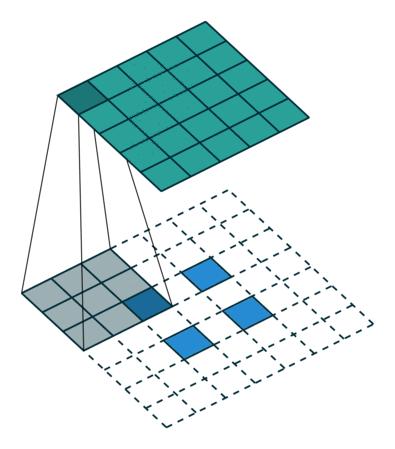
可分离卷积
可分离卷积是指将卷积kernel分解为低维kernel。可分离卷积有两种主要类型。首先是空间上可分离的卷积,如下
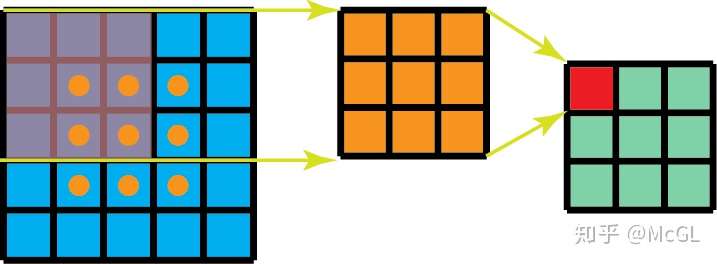 标准的2D卷积核
标准的2D卷积核
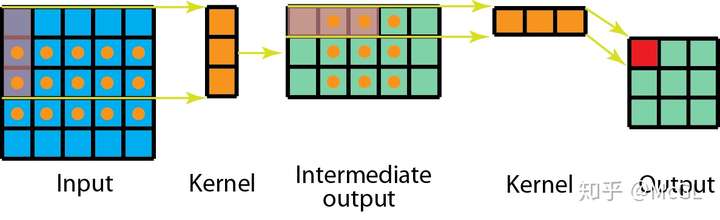 空间可分离的2D卷积
空间可分离的2D卷积
空间可分离的卷积在深度学习中并不常见。但是深度可分离卷积被广泛用于轻量级CNN模型中,并提供了非常好的性能。参见以下示例。
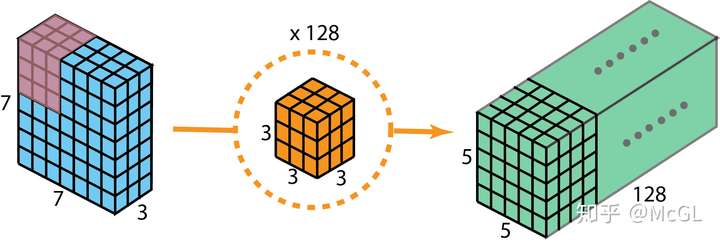 具有2个输入通道和128个filter的标准2D卷积
具有2个输入通道和128个filter的标准2D卷积
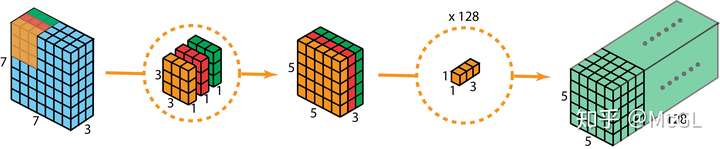 深度可分离的2D卷积,它首先分别处理每个通道,然后进行通道间卷积
深度可分离的2D卷积,它首先分别处理每个通道,然后进行通道间卷积
但是为什么用可分离的卷积呢?效率!!使用可分离卷积可以显著减少所需参数的数量。随着当今我们的深度学习网络的复杂性不断提高和规模越来越大,迫切需要以更少的参数提供相似的性能。
扩张/空洞(Dilated/Atrous)卷积
如你在以上所有卷积层中所见,无一例外,它们将一起处理所有相邻值。但是,有时跳过某些输入值可能更好,这就是为什么引入扩张卷积(也称为空洞卷积)的原因。这样的修改允许kernel在不增加参数数量的情况下增加其感受野。
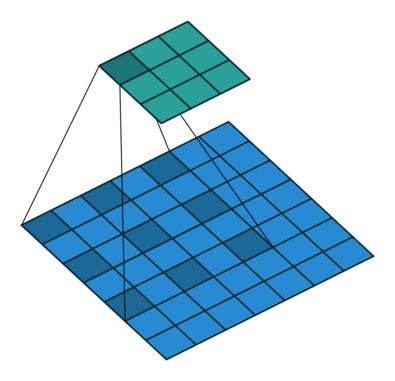
显然,可以从上面的动画中注意到,kernel能够使用与之前相同的9个参数来处理更广阔的邻域。这也意味着由于无法处理细粒度的信息(因为它跳过某些值)而导致信息丢失。但是,在某些应用中,总体效果是正面的。
可变形(Deformable)卷积
就特征提取的形状而言,卷积非常严格。也就是说,kernel形状仅为正方形/矩形(或其他一些需要手动确定的形状),因此它们只能在这种模式下使用。如果卷积的形状本身是可学习的呢?这是引入可变形卷积背后的核心思想。
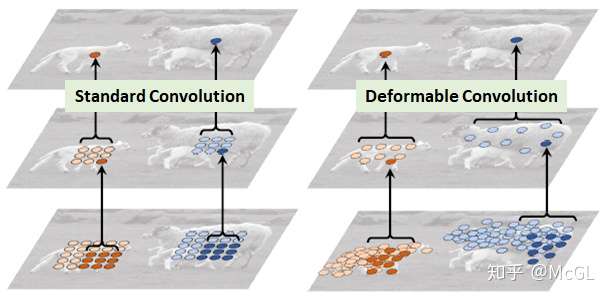
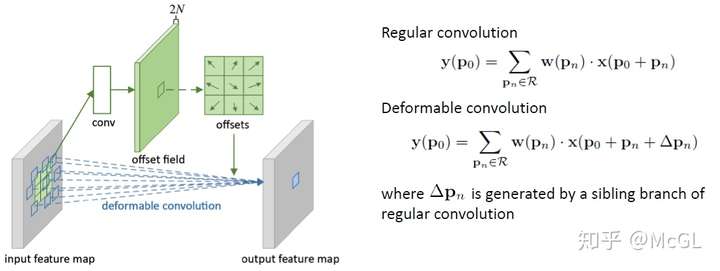
实际上,可变形卷积的实现非常简单。每个kernel都用两个不同的矩阵表示。第一分支学习从原点预测“偏移”。此偏移量表示要处理原点周围的哪些输入。由于每个偏移量都是独立预测的,它们之间无需形成任何刚性形状,因此具有可变形的特性。第二个分支只是卷积分支,其输入是这些偏移量处的值。
What's next?
CNN层有多种变体,可以单独使用或彼此结合使用以创建成功且复杂的体系结构。每个变化都是基于特征提取应如何工作的直觉而产生的。因此,尽管这些深层CNN网络学到了我们无法解释的权重,但我相信产生它们的直觉对于它们的性能非常重要,朝着这个方向进行进一步的研究工作对于高度复杂的CNN的成功至关重要。