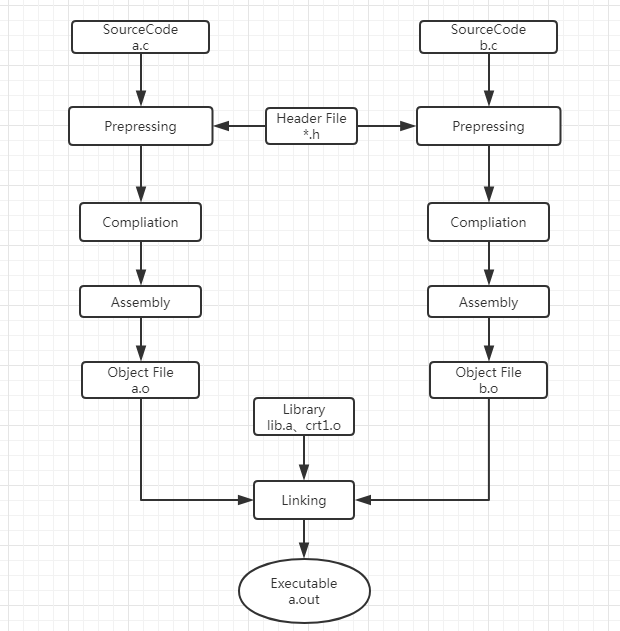
2.1は、プロセスを隠されています
通常、このプロセスはと呼ばれ、一般的なIDE開発環境で直接実行可能ファイルを生成し、一緒に単一のステップにまとめてコンパイルとリンクされますので、通常のアプリケーション開発では、一般的に、あなたは、プロセスをコンパイルとリンクに焦点を当てる必要はありません(釜を構築します)。
古典的な「Hello World」のコードのC言語のバージョンの場合:
#include <stdio.h>
int main()
{
printf("Hello World\n");
return 0;
}私たちは、上記のコードとLinuxの下で(ソースファイルhello.cをという名前と仮定して)一連の処理をコンパイルするためのコード、簡単なコマンドの数行をコンパイルするためにGCCを使用して、プログラムの生成を直接実行することができます:
$gcc hello.c
$./a.oout
Hello World実際に、上記のプロセスは、4つのステップ、すなわち、に分解することができる前処理(前処理)、コンパイル(編集)、アセンブラ(アセンブリ)とリンク(リンク)以下に示すように、プロセスの第三段階は、テキスト形態です、ショー:
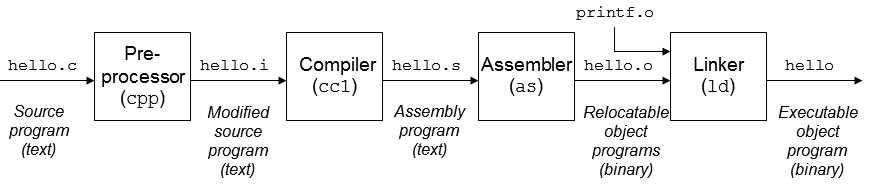
以下は、実質的に各工程の作用下で導入しました。
プリコンパイル済み
プリコンパイルプロセスは、主に「#」にそれらの前のコンパイラディレクティブのソースコードファイルを扱う始めました。例えば、「の#include」、「#定義」と、次のように他の共通の処理規則は次のとおりです。
- すべての「の#define」を削除し、すべてのマクロ定義を展開します。
- こうした「の#if」、「#のIFDEF」、「#endifの」などのすべての条件を、処理するプリコンパイル済み命令。
- 処理「の#include」プリコンパイラ・ディレクティブは、ファイルには、事前にコンパイラ・ディレクティブが含まれている位置に挿入されています。このプロセスは再帰的であることに注意してください、含まれているファイルも追加ファイルが含まれていてもよいです。
- すべてのコメント "//" を削除し、 "/ * * /。"
すべてのマクロが展開されており、およびファイルも含むファイル.Iに挿入されているので、プリコンパイラが生成しhello.iファイルの後、任意のマクロ定義が含まれていません。
コンパイル
コンパイル・プロセスはファイル字句解析、意味解析及び最適化に応答してアセンブラコードファイルを生成する構文解析一連の事前終了することである。次のセクションでは、具体的にはこれらのステップの内容を説明します。
テキスト形式でコンパイルされた出力ファイルhello.sアセンブラはまだです。
編集
作業アセンブラは、実行可能なマシン命令にアセンブリコードにあります。このプロセスは、それはそれでバイナリマシンコードにアセンブリ命令とマシン命令に従って最適化命令、ちょうど11変換テーブルをしない、それはない複雑な構文とセマンティクスを行い、比較的簡単です。
このプロセスが完了した後世代は、ターゲット・ファイル(オブジェクトファイル)を認識し、バイナリマシンコードを実行することができる機械を含んhello.o、。
リンク
最後に、リンク後の実行可能ファイルの.outを生成することができます(Windowsで.exeファイルです)。しかし、それはなぜオブジェクト・ファイルを直接実行するだけで、実行可能ファイルを生成するためのリンクを通過することができない、出力先ファイルのコンパイルプロセスがすでに実行可能なコンピュータのマシンコードに含まれていると言いますか?なぜそれをわざわざ。2.3節の背面には、リンク・プロセスの下で、私たちの詳細を聞かせて何を、なぜリンクが含まれています。
2.2コンパイラがやりました
字句解析、構文解析、意味解析、ソースコードの最適化、コード生成およびコード最適化目標:コンパイラは、おおよその翻訳原則であるが、一般的に6つのステップに分け何かを、学んだん。
非常に単純なCコードで最終の宛先コードのソースから次の世代約プロセスの一例です。
array[index] = (index + 4) * (2 + 6)字句解析
まず、ソースコードがスキャナ(スキャナ)に入力され、の使用有限状態機械この文字列のためのアルゴリズムは、トークンの一連(トークン)に分割され、上記のコードは28の非空白文字が含まれ、スキャンした後、それは16のマークを作成しました:
| マーク | タイプ |
|---|---|
| アレイ | 識別子 |
| [ | 左角括弧 |
| 指数 | 識別子 |
| ] | 右ブラケット |
| = | 割り当て |
| ( | 左括弧 |
| 指数 | 識別子 |
| + | プラス |
| 4 | デジタル |
| ) | 右括弧 |
| * | 乗算記号 |
| ( | 左括弧 |
| 2 | デジタル |
| + | プラス |
| 6 | デジタル |
| ) | 右括弧 |
キーワード、識別子、リテラル(数値、文字列、など):字句解析トークン生成は、一般的に次のカテゴリに分類されます。識別記号が、スキャナはまた、次の工程を調製するために使用されるシンボルテーブルに識別子番号と文字列定数記憶テーブル等としてストア他のものを完成させました。
パージング
次パーサー(文法パーサー)を使用して、トークンスタックスキャナ解析によって生成された文脈自由文法(文脈自由文法)を構文木(構文木)を生成します。構文木があるある式(式)ノードツリーです。
C言語の文で表現され、かつ複雑な文は、式のたくさんの組み合わせです。上記のステートメントの例は、複合代入式によってステートメント、発現加え、括弧内の式の他の構成要素です。次のように構文木を生成しました:
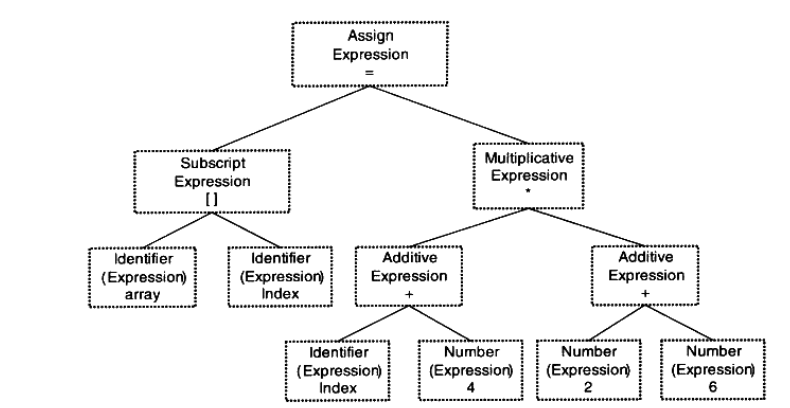
上記のステートメントは、全体代入式のように見ることができる;代入式の左辺は、数値式で、右側は、乗算式であり、この再帰、記号および数字は、最小の表現であり、それらは他によって発現されません型の組成物。
オペレータがありません式など不一致括弧の多様など違法な状況、およびその他の式の場合、コンパイラは、分析フェーズで構文エラーを報告します。
意味解析
フロントの解析だけで文法の発現レベルの解析を完了したが、それはこの文は本当に意味があるかどうかわかりません。たとえば、乗算演算のための2つのポインタは、この文は構文的に合法であるが、それは意味がありません。コンパイラは、静的セマンティクスのセマンティクスを分析することができる(対応する除数がランタイムセマンティックエラーであるようなゼロとしてのみ実行セマンティクスで決定することができる動的なセマンティクスです)。
静的セマンティクスは通常、宣言と型が一致変換の種類が含まれます。セマンティック分析の後、位相、全粒式の構文木は種類を同定されています:
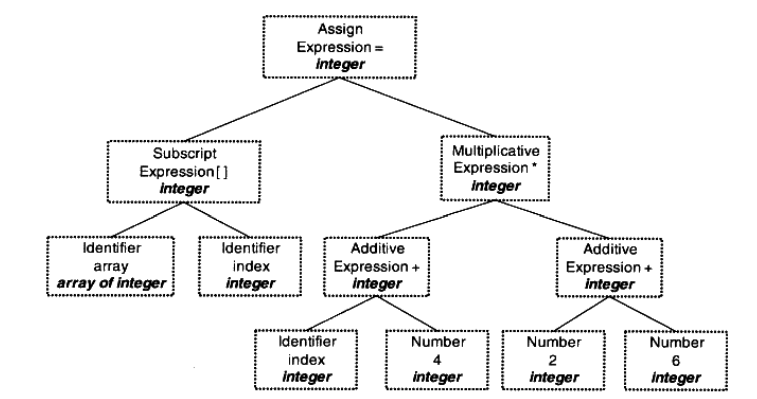
外の更新を行うには、シンボルタイプのシンボルテーブルの上にも、セマンティックアナライザで割った値。
中間言語生成
現代のコンパイラは、ソースレベルでの最適化プロセスを持っている傾向があります。その値が8のようにコンパイル時に決定することができるので、上記の例では、この式は離れて最適化することができる(2 + 6)を見つけることは容易であり、多くの他の類似の複雑な最適化プロセスがあります。
この最適化プロセスは、多くの場合に、全粒構文木を変換構文木最適化ソースで直接実行されていない中間コード(中間コード)構文木の順序で表されます。中間コードは、ターゲットマシンとオペレーティング環境から独立して、そのようなデータサイズ、アドレスおよびその他の変数などの情報が含まれていません。
把上面例子的语法树翻译成中间代码(三地址码的形式)后是这样的:
t1 = 2 + 6
t2 = index + 4
t3 = t2 * t1
array[index] = t3在这样的三地址码形式的基础上进行优化,优化程序会将2 + 6的结果计算出来得到t1 = 8,并可以省去一个临时变量t3:
t2 = index + 4
t2 = t2 * 8
array[index] = t2目标代码生成与优化
首先是目标代码生成;这个过程是由代码生成器将中间代码转换成目标机器代码,因而十分依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等。假如我们用X86汇编语言来表示,代码生成器可能会生成下面的代码序列:
movl index, %ecx
addl $4, %ecx
mull $8, %ecx
movl index, %eax
movl %ecx, array(,eax,4)最后由目标代码优化器对上述的目标代码进行优化,比如选择合适的寻址方式、使用位移运算代替乘法运算、删除多余的指令等。
链接器年龄比编译器长
在经过词法分析、语法分析、语义分析、源码优化、目标代码生成和优化,上面的源代码终于被编译成了目标代码。但是这个目标代码还有一个问题:index和array的地址还未确定。如果index和array定义在跟上面源码同一个编译单元里,那么编译器可以为index何array分配空间并确定它们的地址;而如果是定义在其他的程序模块中的话,要怎么确定它们的访问地址呢?这时候,就需要到链接器了。
在“上古时代”,是没有高级语言甚至汇编语言的;那个时候写程序是直接写机器码的,存储程序的最原始的设置之一就是纸带,即在纸带上打相应的孔格:

假设现在有一段如上图右侧所示的机器码程序,其所运行的目标机器上 每条指令都是一字节;上面有一种跳转指令,高4位是0001,表示这是一条跳转指令,低4位存放的是跳转目的地的绝对地址。从上图可以看出,第一条就是跳转指令,要跳转到第5条指令(第5条指令的绝对地址是4)。
那么问题来了,这段程序在日后是可能会修改的,如果我们在第1条指令和第5条指令之间插入了新的指令,那么第1条跳转指令的目的地址就得做修改了。如果我们有多条纸带程序,这些程序之间可能会有类似的跨纸带之间的跳转。每当有这修改时,我们都得重新计算各个目标地址(这个过程被叫做重定位) 显然是不能容忍的。
后来,先驱者发明了汇编语言,在两点上极大地解放了生产力:
- 采用助记符来替代机器指令,例如jmp代表跳转指令
- 可以使用符号来标记位置,例如在前面的纸带程序中,把第5条指令开始的子程序命名为“foo”, 那么第一条指令的汇编就是:
jmp foo
当人们可以使用这种符号命名子程序或跳转目标以后,不管这个“foo”之前插入或减少了指令导致“foo”目标地址发生变化,汇编器在每次汇编程序的时候都会重新计算“foo”这个符号的地址,然后把所有引用了“foo”的指令修正到正确的地址。
有了汇编语言后,生产力大大提高,随之而来的是软件程序的规模也日渐庞大,人们开始将代码按照功能或性质划分。在一个程序被分割成多个模块之后,这些模块之间最后如何组合形成一个单一的程序是需要解决的问题。模块之间如何组合的问题可以归结为模块之间如何通信的问题,主要有两方面:一是模块间的函数调用,另一是模块间的变量访问。而这两种方式都可以归结为一种方式,即模块间符号的引用。 我们将各个模块“拼合”到一起形成一个可执行程序,并为各个模块中的符号引用确定最终访问地址 的这个过程就是本书的一个主题:链接(Linking)。
模块拼装——静态链接
这里先举一个例子来阐述静态链接的最基本的过程和作用:
比如我们在程序模块main.c中使用了另一个模块fun.c中的函数foo()。那么在main.c模块中每一处调用foo的时候都必须确切知道foo这个函数的地址,但由于每个模块都是单独编译的,在编译器编译main.c的时候它并不知道foo函数的地址,所以它暂时把这些调用foo的指令的目标地址搁置,等待最后链接的时候由链接器去将这些指令的目标地址修正。 使用链接器,你可以直接引用其他模块的函数和全局变量而无需知道它们的地址,因为链接器在链接的时候,会根据你所引用的符号foo,自动去相应的fun.c模块查找foo的地址,然后将main.c模块中所有引用到foo的指令重新修正,让它们的目标地址为真正的foo函数的地址。
链接器所做的工作其实跟前面所说的机器码程序中因指令增减而需要“手工调整地址”本质上是一样的,只不过现代高级语言拥有诸多特性与功能,使得编译器、链接器更为复杂,功能更为强大,但从原理上讲,它的工作无非就是把一些指令对其他符号地址的引用加以修正。链接过程主要包括了地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定位(Relocation)等这些步骤。(符号决议大致就是 为每个目标文件确定符号并在其他目标文件找到引用符号的定义的过程,后面的链接章节会详细介绍)
最基本的静态链接过程如下图所示。每个模块的源代码文件(如.c文件)经过编译器编译成目标文件(Object File,一般扩展名为.o或.obj),目标文件和库(Library)一起链接形成最终可执行文件。而最常见的库就是运行时库(Runtime Library),它是支持程序运行的基本函数的集合。库其实是一组目标文件的包,就是一些常用的代码编译成目标文件后打包存放。关于库本书的后面还会详细分析。