シンプルなアイデアは、一般的な情報のページがあるクロール
1、ページのソースコードを表示
2、スパイダーは、ウェブをクロール
3、Webコンテンツを解析し、
図4に示すように、ファイルに格納されています
今クロールハリネズミインターンシップ位置Pythonの給与状況にBeautifulSoupの解析ライブラリを使用
まず、ページのソースコードを表示します

これは、私たちが必要なものの一部に対応するソースコードです:
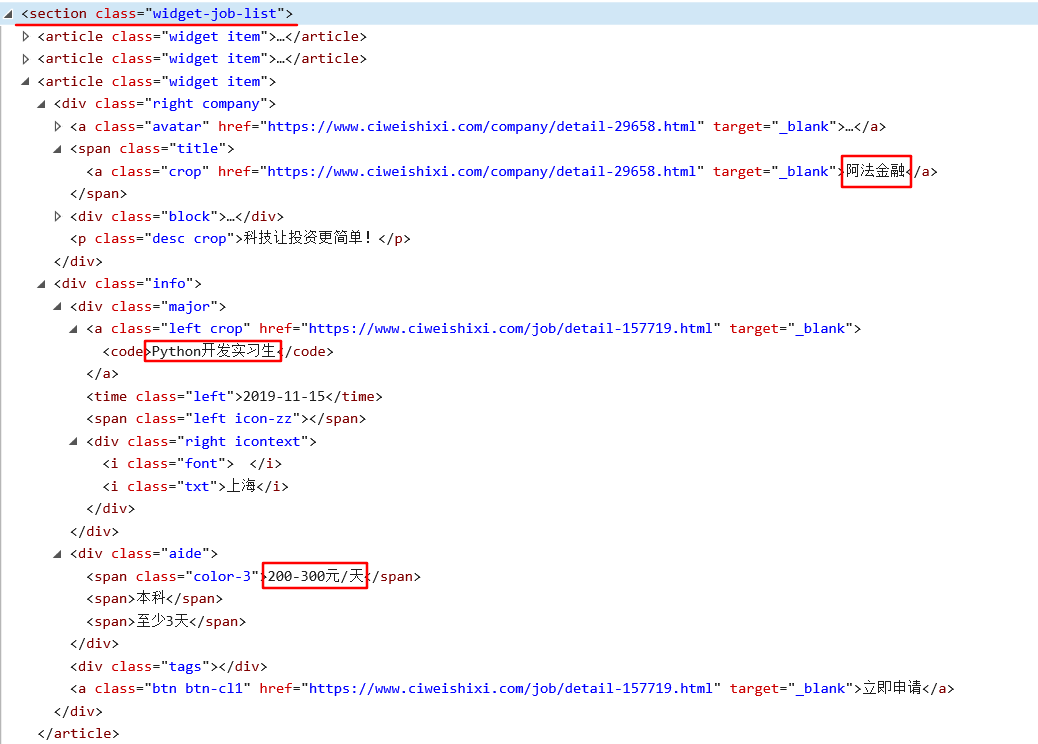
ソースコードの分析では、あなたが学ぶことができます。
図1に示すように、ジョブ情報リスト<部クラス=「ウィジェットジョブ -list」> で
図2に示すように、内の各情報<文書クラス=「ウィジェット項目」 > で
3は、それぞれの情報のために、私たちは、会社名、役職、給与の内容を抽出する必要があります
第二に、スパイダーは、ウェブをクロール
使用request.get()クロール、リターンスープは、テキスト情報のページです
デフget_one_page(URL): 応答 = requests.get(URL) スープ = BeautifulSoup(response.text、" html.parser " ) の戻りスープ
第三に、解決のWebコンテンツ
1の場所開始<セクション>
2、<記事>情報にマッチ
3、店舗への情報の一覧に戻ります
DEFのparse_page(スープ): #は情報リストに格納される return_list = [] #開始位置 グリッドsoup.find =(' sectionTop '、ATTRS = { " クラス":" ウィジェットジョブ・リスト" }) IF グリッド: #すべてのポジションを見つけるリスト job_list = soup.find_all(「この記事はだっ条」、attrsに= { 「クラス」:「ウィジェットの項目を」}) #マッチコンテンツ のための仕事でjob_list: #の検索は、()、一致するタグ見つけることが最初です 会社job.find =(' A '、attrsに= { " クラス":" 作物はあなたができます" GET_TEXT()ストリップを。})。 () #は、ブランクを除去することができる)、改行文字列のタイプ、ストリップ(返し タイトルjob.find =(「コード」)().get_textを 給与 = job.find(' スパン'、ATTRS = { " クラス":" 色- 3 " })GET_TEXT() #のリストに格納された情報と戻る (会社+ return_list.append " " + +タイトルを" " + 給与) の戻りreturn_list
第四に、保存されたファイル
ファイルshixi.csvに保存されているリスト情報
DEF write_to_file(コンテンツ): #コード形式の歪みを防止するために、さらに開放することができるが、提供される オープン(と" shixi.csv "、" A "、コード= " GB18030 " )AS F: f.write(" \ nは" .join(コンテンツ))
情報のページをクロールV.
あなたは、ページのURLに代表の最後のページを見ることができる情報のページ数です
だから、mainメソッドでページを渡され、その後、あなたはへの情報のページをクロールすることができますメインループ(ページ)を実行します
デフメイン(ページ): URL = ' https://www.ciweishixi.com/search?key=python&page= ' + STR(ページ) スープ = get_one_page(URL) return_list = parse_page(スープ) write_to_file(return_list) もし __name__ == " __main__ " : 用 I における範囲(4 ): メイン(I)
第六に、業績

七つの完全なコード
インポート要求が インポート再 から BS4 インポートBeautifulSoup デフget_one_page(URL): 応答 = requests.get(URL) スープ = BeautifulSoup(response.text、" html.parser " ) の戻りスープ DEFのparse_page(スープ): #は情報リストに格納される return_list = [] #開始位置 グリッドsoup.find =(' sectionTop '、ATTRS = { " クラス":" ウィジェットジョブ・リスト" }) IF グリッド: #すべてのポジションを見つけるリスト job_list = soup.find_all(「この記事はだっ条」、attrsに= { 「クラス」:「ウィジェットの項目を」}) #マッチコンテンツ のための仕事でjob_list: #の検索は、()、一致するタグ見つけることが最初です 会社job.find =(' A '、attrsに= { " クラス":" 作物はあなたができます" GET_TEXT()ストリップを。})。 () #は、ブランクを除去することができる)、改行文字列のタイプ、ストリップ(返し タイトルjob.find =(「コード」)().get_textを 給与 = job.find(' スパン'、ATTRS = { " クラス":" 色- 3 " })GET_TEXT() #のリストに格納された情報と戻る (会社+ return_list.append " " + +タイトルを" " + 給与) の戻りreturn_list DEF write_to_file(コンテンツ): #コード形式の歪みを防止するために、さらに開放することができるが、提供される オープン(と" shixi.csv "、" A "、コード= " GB18030 " )AS F: f.write(" \ nは" .join(コンテンツ)) デフメイン(ページ): URL = ' https://www.ciweishixi.com/search?key=python&page= ' + STR(ページ) スープ = get_one_page(URL) return_list = parse_page(スープ) write_to_file(return_list) もし __name__ == " __main__ " : 用 I における範囲(4 ): メイン(I)