8つのデジタル
呼ばれる8つのデジタルJiuGongTuは、問題のように記述されている人工知能の探索状態で古典的な問題である:3×3のチェス盤には、8個を入れ、それぞれの作品は、1-8ででマークされ数字の主題にデジタル、異なる部分は同じではありません。ボード上のスペースがあり、作品は隣接スペースに設けられた空間に移動することができます。問題を解決するために必要とされる初期状態と目標状態が与えられると、ポーン移動ステップを移動する手順の目標最小数の初期状態からの遷移を見つけること。
これは典型的なグラフ探索問題であるが、問題が解決されるデータ構造を確立する必要がありますが、検索方法抽象的な数字ではない、問題に適用されます。以下の分析です。
まず、抽象化と符号化アルゴリズムの問題を考えます。スペースレコード場合は0に、ボード上のすべての状態9の合計!=
362880種類。私たちは、最初のボードの状態をエンコードする方法を見つける必要があります。
容易に、すなわちエンコードされた文字列を、使用して、状態の視覚的表現を発生する文字列は、例えば、全体のデジタルディスクに現在の状態を表すように、平らに3x3の正方形は、列9の長さ:ステータス次のように123456780を発現しました:
| 1 | 2 | 3 |
|---|---|---|
| 4 | 5 | 6 |
| 7 | 8 | 0 |
さらに、例えば遷移状態を考慮して起動するだけ0からスペースと交換に数ので、デジタル位置によって与えられた状態を、(変更)転送を考える:この状態遷移は、両方向で行うことができ、 8 0は次のように示され、スワップ、スワップ0と6です。
| 1 | 2 | 3 |
|---|---|---|
| 4 | 5 | 0 |
| 7 | 8 | 6 |
モードを転送
| 1 | 2 | 3 |
|---|---|---|
| 4 | 5 | 6 |
| 7 | 0 | 8 |
左方向へのシフト
これは、探索木の状態のため、目標状態に初期状態から拡張することができ、次のとおりです。
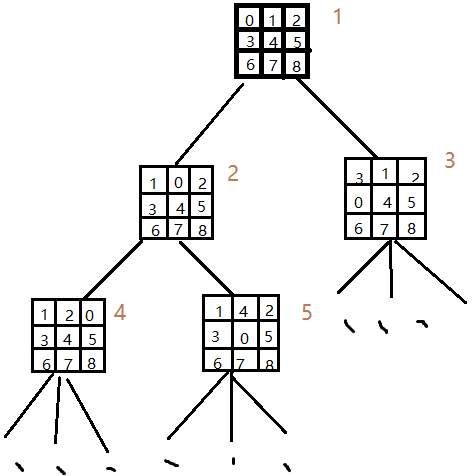
探索木の写真1つのステータス
探索木の深さを確認することは困難ではない、スペースの現在の数が交換されています。
アルゴリズム分析
列挙状態暴力
スペースとして0の場合、状態の総数は数0-9、すなわち9内に配置する必要があります!= 362880の状態、使用される列挙アルゴリズムはバイナリであり、すなわち列挙し、すべてのそのようなアルゴリズムは非効率的であり、すべての可能な次の状態を列挙するかどうか、転送要求の一部に沿って装置の現在の状態を満たすとあるいは限られた時間内に解くことができません。
- 深さ優先探索
開始転送状態条件考慮さらに反射、およびその他のデジタルモバイルあるいは0 0考察の位置から各状態遷移に、従って、交換する、その移動位置0の周りの位置に相当します。この検索は、優れた検索深さと幅優先探索に分けることができ、さらに分割され、検索の概念を定義します。
深さ優先探索の場合、それは現在の状態があなたの検索条件に一致するまで「最後に行くには、心の電流経路」、である、または新しい状態が中断として拡大し続けることができませんでした。このような検索が離れて探索木の探索方向の初期配信対象から、深い枝の上に長時間滞在する可能性があり、効率が非常に低いです。検索ツリーの拡張検索状態は以下の通り:
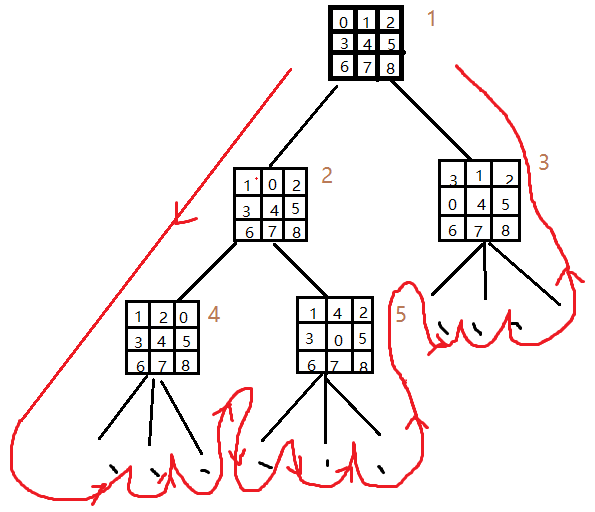
写真2幅優先探索パス
この例の場合である:パスBFSの言葉のように説明することができます。
| ルートの状態(初期状態1) |
|---|
現在のノード(ノード2)へのアクセスは、左のほとんどを訪問していない、とノードがターゲット状態ではありません。
現在のノード(ノード4)へのアクセスは、左のほとんどを訪問していない、ノードは、ターゲット状態ではありません。
現在のノード(ノードサブツリー部4)未訪問の最も左、ノードへのアクセスは、ターゲット状態ではありません。
現在のノードのノードの拡張子ない、(バックノード4へ)後戻り
現在のノードのノードの拡張子ない、(バックノード2)後戻り
現在のノード(ノード5)へのアクセスは、左のほとんどを訪問していない、とノードがターゲット状態ではありません。
...(など)
現在のノードがターゲットノード、検索が終了すると、出力電流と探索木の深さです。
それ以外の場合は、背面に拡張されたルートノードへ行くと、検索は、検索のうち、対象の状態よりも少ないです。
したがって、検索は右端のサブツリーの右端の子ノードの目標状態(溶液)は、非常に非効率的な検索効率が左側のサブツリーは、最初の検索にあると仮定し、表示することが明らかである、検索回数は順列の数にほぼ等しいです。 9!= 362880。ターゲット状態が左部分木の最も最も左のノードに配置されている場合と、検索は、ツリーを出力することができ、最適なソリューションのリーフノードを落ちてくる一定のレベルになります。
以下のように疑似コードを記述することができます。
| まず、スタックへのルートノード。 |
|---|
- スタックから最初のノードを取り、そしてそれがゴールであることを確認してください。
ターゲットが見つかった場合、検索の終わりとは、結果を返します。
それ以外の場合は、直接の子の一つがスタックに参加することで確認されていませんでした。
手順2を繰り返します。
直接の子ノードを介して検出されない場合は存在しません。
上位ノードがスタックに追加されます。
手順2を繰り返します。
手順4を繰り返します。
スタックが空の場合は、マップ全体を表してチェックした - それは、検索対象をしたくなかったの図です。検索とリターンの終わり「ターゲットを見つけることができません。」
だから、要約、深さ優先探索アルゴリズムは、時間の許容期間内に取得したその時、暴力列挙の状態を改善し、まだのようないくつかの質問を、持っています:
検索時間が不安定。運が優れている場合は、すぐに運が悪い場合には、目標状態に到達するまで、帰り道を必要とする、解決策を得ることができるので、タイムサーチは、目標状態と初期探索方向と木の浅いの分布と類似し、ターゲット状態の分布に依存しますサブツリーが配置され、このような効率は、探索空間が膨大であり、列挙しにくい順列の数にほぼ等しいです。
その他のブルートフォースアルゴリズム。ツリーの各ブランチのための慎重な分析、目標状態への検索は、情報検索と深さ優先探索を最適化するように、異なる、およびこれらの確率が一定であることができることがある確率は、すべての各ブランチのためであります同等の状態確率が同じであるターゲットへの検索は、これは、最適化の欠如は明らかに不合理であると考えています。
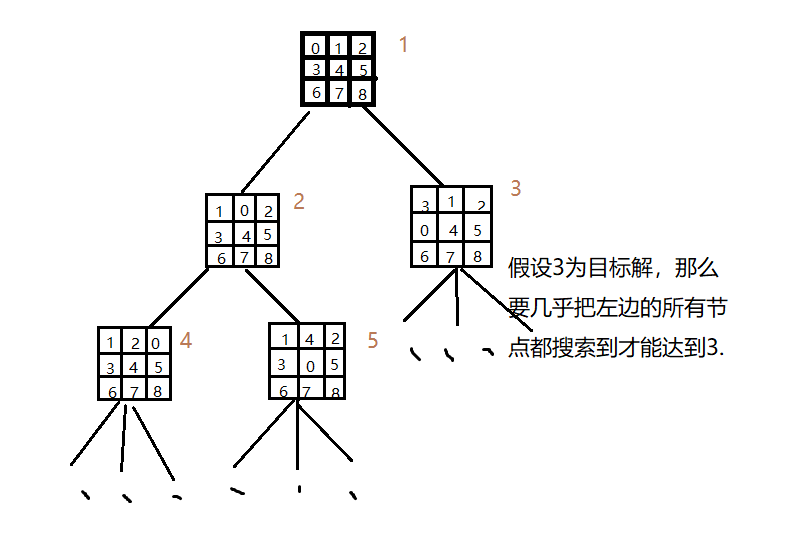
写真3は不十分深さ優先探索
BFS
幅優先探索は、他の大きな枝で検索戦略である、という考えは、「最終的に離れて落ちる」はもはやありませんが、「パン拡張。」したがって、ターゲットノード探索木において同じ深さプロファイルおよび検索ツリーノードは検索回数に分布しているの左側に右に実質的に同じです。
同じことは、凡例を用いて説明します。

その後、その子ノードの次のレベルに子ノードから延長されているルートノードのノードを展開して始まるから、最初の訪問は、子ノードのルートで見ることができる拡張の階層があることがあります。レベルのセットは、リーフ・ノードの近くに位置しているためこのように、私たちは、公正な確率検索を持つことができます。ノードのアクセス順序は、ターゲットソリューションに検索されるまで、レベル2のすべてのノードに続くノード1の全てのアクセスのレベルを、上記第一の図であり、又は終了を拡大し続けることができません。したがって、幅優先探索のために、検索は、状態の現在の状態が検索が各層の木であることを広げることができるたびに延長されます。
以下のように疑似コードを記述することができます。
| キューQは、[N] = 0を訪問しました。 |
|---|
Vの頂点の訪問は、Q頂点vキュー; [V] = 1訪れました。
(非空キューQ)一方
、ヘッド素子デキューV = Qキュー
; =最初の隣接頂点v W
(本w)のながら
W頂点のアクセスがアクセスされないW場合;
= [W]訪問1。
Q wの頂点をキューに入れ、
頂点v = W次の隣接ポイント。
以下同様に、深さ優先探索アルゴリズムは、力まかせ探索と短所性能です。
未分化の検索、および同じ深さ優先探索、幅優先探索はまた、選択分岐検索の無差別等しい確率であり、左右の極端な不均衡のツリーの幅優先探索は、探索の低い効率をもたらすことができます。しかしながら、本問題に起因わずか約4例の垂直方向の膨張、したがって、拡張された枝は、よりバランスしています。ツリーは、サイドに傾けていません。だから、幅優先探索は、この問題にある深さ優先探索よりも優れています。
巨大なスペースの消費量、オーバーヘッド近いとテーブルを開き、テーブルスペースは、幅優先探索は、2つのテーブルを必要と維持しながら、莫大です。
幅優先探索は、ハッシュテーブルが来ます
最後に行くには良い解決策のアルゴリズムは、問題の深さの最初の検索に分類し、2つの8のデジタルの違いを解析します。幅優先探索は、限られた時間内に解決することができましたし、受け入れることができますが、非常にラフな解決方法である必要があります、が、最適化すべき多くの場所があります。
まず、各時間の延長のために、現在のノードが再チェック動作を伴うであろう、訪問されておらず、幅優先方法は、データ構造を再チェックする前に、マップを使用することで、そのようなデータ構造クエリの効率を見つけるべきですレベルの数が、各クエリ拡張ニーズのためのスペースがあり、時間と蓄積の空間でのコストが高くなります。
この問題を解決するために、我々は、このようなハッシュテーブルとしてクエリ非常に効率的なデータ構造は、データ構造であることを検討してください。一定の滝の複雑度を照会する時、及び保管のためのスペースは、ハッシュ関数が設計されている場合、ほぼ線形速度の損失を考えることができるようにすることができます。
ハッシュアルゴリズムセクションは次のように記述することができます。
要素を挿入します。
| ハッシュ値を要素に挿入される計算 |
|---|
- ハッシュの競合があるかどうかを確認するには
あなたが挿入できるまでの紛争、ジャンプが、あります。
競合のない、要素を挿入します。
要素を削除します:
| ハッシュ値を計算します。 |
|---|
- 見る現在位置が要素を削除します。
はい、要素を削除
いいえ、計算されたハッシュジャンプは、どこの場所で要素を削除見つけるために知っています。
双方向BFS
ここで、その更なる拡大正面幅優先探索アルゴリズムの説明については、非常に詳細です。より効率的なアルゴリズムについて話し合います。
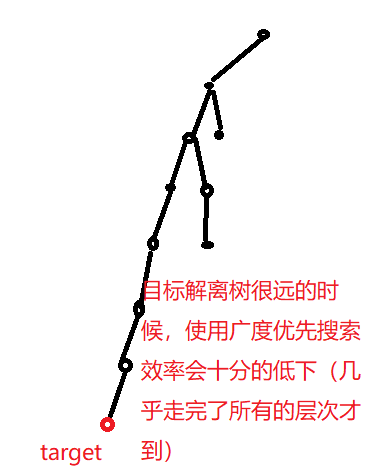
幅優先探索のために、検索は、一方向のみにすることができ、それは方向における初期探索状態から目標状態にある、すなわち、全体探索経路は、三角形の拡張プロセスとみなすことができます。
図:

写真4つのBFSの探索方向
ターゲットノードが非常に低くなる幅優先探索効率の開始から開始位置、リーフノード位置に近接して配置されている場合、上記に述べました。
状態は木出会っの拡張ノードの初期状態でターゲットツリーに拡大し始めたので、我々はターゲットの方向から、検討することができますが、検索し始め、それは検索が目標であったことを示しています。これは、リーフノードは、ボトムアップの枝を素早く検索することができますし、トップダウンの枝が収束する場合解離に非常に近い双方向深さ優先探索アルゴリズム、である、効果的に解決策を解決できるルートと原因に近いです非効率。
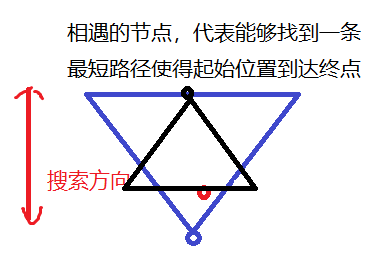
双方向BFSの両側から延びる画像5
両側から延長し、開いているテーブルの検索に追加されました。
ヒューリスティックアルゴリズムA *
で、以前に述べたチャンスは、各探索経路上の同じではない解決策を見つけるためにするので、無差別の検索を使用することは、合理的ではありません。そのため、可能な限り最大の検索ソリューションへのルート上の検索を優先順位付けするアルゴリズムを見つけるための方法を見つける必要があります。*探索アルゴリズムは、このような機構の追加である、ことが可能可能ブランチを検索する高い確率嗜好を持って行う、深さ優先探索の評価関数と呼ばれます。
ここで評価関数は目標確率推定値に現在のブランチを検索する可能性があります。
メインループの各反復で、
*は、パスを拡大して決定されます。これは、パスのコストに基づいており、パスはターゲットを操作するために必要な費用の見積もりに拡張されました。具体的には、
*パス選択は、最小
{\ displaystyleのF(N)= G(N)+(N)H}
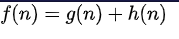
写真6値関数
nは、経路上のノードであり、G(n)は、パスの始点ノードからコストであるN、H(n)はヒューリスティック関数であり、安いからターゲットへのn個のパスを推定するためのコスト。
このように、評価関数の影響の下で、ルートは現在の状況の評価関数により決定合理的な選択であろう検索すると、より合理的なルートです。
評価関数の設計では、動的な変更を加える必要があることを、いくつかのデータを検討し、見つかった後、
一般的な基準は、プライマーBaiduの百科事典を:

写真7評価、設計基準関数