タイトル: KMP アルゴリズム推論の概要
日付: 2023-07-17 16:07:13
タグ:
- アルゴリズムの
カテゴリ: - データ構造とアルゴリズム
カバー: https://cover.png
機能: false
KMP アルゴリズムの控除
Fan's Web文字列マッチングの BF アルゴリズムと RK アルゴリズムの部分を最初に見ることができ、BM アルゴリズムと KMP アルゴリズムを一緒に見ることができます。
KMP アルゴリズムの核となるのは部分一致テーブルと呼ばれる配列ですが、まず PMT の値が何であるかを説明します。
文字列「abababca」の PMT を次の表に示します。

例に示すように、一致するパターン文字列が 8 文字の場合、PMT には 8 つの値が含まれます。
ここではまず文字列のプレフィックスとサフィックスについて説明します。文字列 A と B について、A=BS (S が空でない文字列) が存在する場合、B は A のプレフィックスであると言われます。たとえば、「Harry」の接頭辞には {"H"、"Ha"、"Har"、"Harr"} が含まれます。すべての接頭辞のセットを文字列の接頭辞セットと呼びます。
サフィックス A=SB も定義できます。S が空でない文字列の場合、B は A のサフィックスと呼ばれます。たとえば、「Potter」のサフィックスには {"otter"、"tter"、"ter"、"er"、"r"} が含まれ、すべてのサフィックスのセットは文字列のサフィックス セットと呼ばれます。文字列自体は独自のサフィックスではないことに注意してください。
この定義により、PMT の値の意味が説明できます。PMT の値は、文字列のプレフィックス セットとサフィックス セットの交差部分にある最長の要素の長さです。たとえば、「aba」の場合、プレフィックス セットは {"a", "ab"}、サフィックス セットは {"ba", "a"} です。2 つのセットの共通部分は {"a"} であり、最長の要素は長さ 1 の文字列 "a" となるため、"aba" の場合、PMT テーブル内の対応する値は 1 になります。別の例として、文字列「ababa」の場合、そのプレフィックス セットは {"a", "ab", "aba", "abab"}、サフィックス セットは {"baba", "aba", "ba", "a"}、2 つのセットの共通部分は {"a", "aba"}、最も長い要素は長さ 3 の "aba" です。
このテーブルが何であるかを説明した後、このテーブルを使用して文字列の検索を高速化する方法と、このテーブルを使用する理由を見てみましょう。
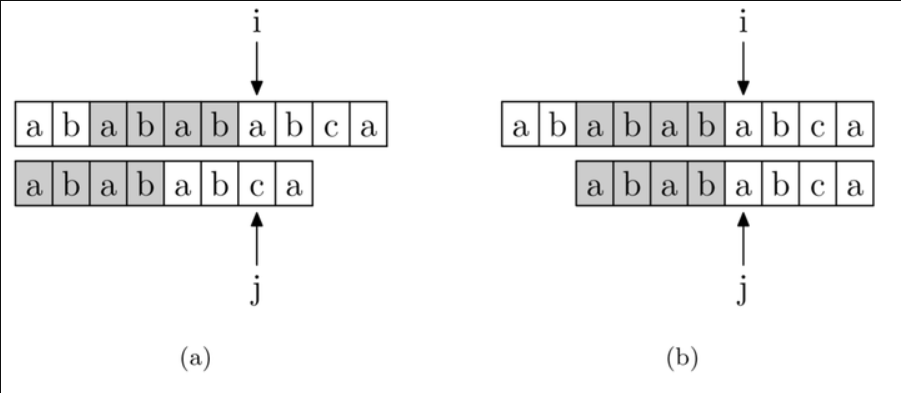
次の図に示すように、パターン文字列「abababca」はメイン文字列「ababababca」内にあります。文字が j で一致しない場合、前述のパターン文字列 PMT の性質により、メイン文字列の i ポインタの前の PMT[j−1] ビットは、パターン文字列の 0 番目から PMT[j−1] ビットと同じでなければなりません。これは、メイン文字列が位置 i で不一致であるためです。つまり、i-j から i までのメイン文字列は 0 から j までのパターン文字列とまったく同じです。
上で説明したように、パターン文字列は 0 から j−1 であり、この例では「ababab」であり、プレフィックス セットとサフィックス セットの共通部分の最も長い要素は長さ 4 の「abab」です。したがって、メイン文字列の i ポインタの前の 4 ビットは、パターン文字列の 0 番目から 4 番目のビットと同じである必要があります。つまり、長さ 4 のサフィックスはプレフィックスと同じであると言えます。このようにして、これらの文字フィールドの比較を省略できます。具体的な方法は、i ポインタを静止させたままにして、j ポインタをパターン文字列の PMT[j −1] ビットに指すようにすることです。
上記の考え方により、PMT を使用して文字列の検索を高速化できます。ビット j で不一致がある場合、実際には j ポインタの後戻り位置に影響を与えるのはビット j −1 の PMT 値であることがわかります。そのため、プログラミングの便宜上、PMT 配列を直接使用せず、PMT 配列を 1 ビット後方にシフトします。
次の図に示すように、新しく取得した配列を次の配列と呼びます。注意すべきトリックの 1 つは、PMT を右にシフトするときに、0 番目のビットの値を -1 に設定することです。これは、プログラミングの便宜のためだけであり、他の意味はありません。

次の配列による文字列マッチングの高速化のための文字列マッチング プログラムは次のとおりです。
int KMP(char *t, char *p) {
int i = 0;
int j = 0;
while (i < (int) strlen(t) && j < (int) strlen(p)) {
if (j == -1 || t[i] == p[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j == strlen(p)) {
return i - j;
} else {
return -1;
}
}
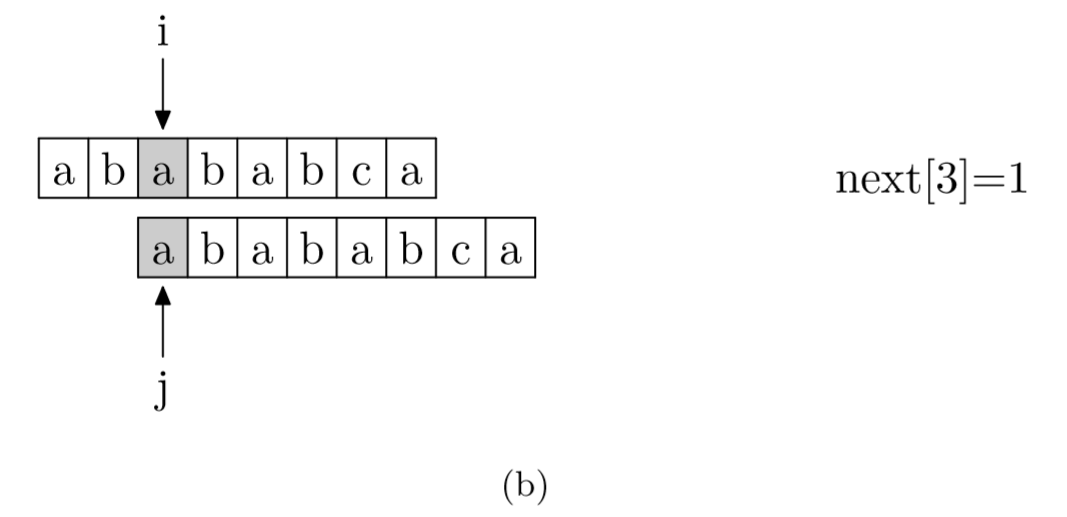
次の配列をすばやく取得する方法を見てみましょう。実際、次の配列を見つけるプロセスは、文字列マッチングのプロセスとみなすことができます。つまり、パターン文字列がメイン文字列で、パターン文字列のプレフィックスがターゲット文字列です。文字列が正常に一致すると、現在の次の値は、正常に一致した文字列の長さになります。
具体的には、パターン文字列の最初のビット (0 番目のビットは含まない) から開始して、それ自体に対して照合操作を実行します。次の図に示すように、どの位置でも、一致できる最長の長さは現在位置の次の値になります。




コードは以下のように表示されます。
void getNext(char *p, int *next) {
next[0] = -1;
int i = 0, j = -1;
while (i < (int)strlen(p)) {
if (j == -1 || p[i] == p[j]) {
++i;
++j;
next[i] = j;
} else {
j = next[j];
}
}
}