問題の10月20日のレース・シミュレーション・ソリューション
カード
説明
そこデスクトップ上の\(N \)カード、各書かれた整数の各カードの長所と短所をプレイし、最初に立ち向かいます。数字のアップデジタル少なくとも半分が同じであるか、という解決策が決定されていないので、あなたは今、最小限のフリップカードが必要です。
制限事項
\(1 \ n型のLeq \ 1当量3 \ ^。5回10 \) 、全ての入力データが以下である\(10 ^ 9 \)非負整数。
解決
出席問題、通知は、少なくとも同図の半分、のみの合計を必要とするので\(2Nの\)番号、数を超えないように、最終的な数字は同じであってもよいので、\(4 \)ヶ月。でmap/hashちょうど約メンテナンスの出現、そしてより多くの列挙の数字の半分よりも、暴力を判断することができます。
コード
#include <cstdio>
#include <map>
#include <vector>
const int maxn = 300005;
int n, ans = maxn, dn;
int a[maxn], b[maxn];
std::map<int, int> oc;
std::vector<int> ansv;
int main() {
freopen("card.in", "r", stdin);
freopen("card.out", "w", stdout);
qr(n); dn = (n >> 1) + (n & 1);
for (int i = 1; i <= n; ++i) {
qr(a[i]); qr(b[i]);
if (a[i] != b[i]) {
if (++oc[a[i]] == dn) {
ansv.push_back(a[i]);
}
if (++oc[b[i]] == dn) {
ansv.push_back(b[i]);
}
} else {
if (++oc[a[i]] == dn) {
ansv.push_back(a[i]);
}
}
}
if (ansv.size() == 0) {
puts("Impossible");
return 0;
}
for (auto v : ansv) {
int cnt = 0;
for (int i = 1; i <= n; ++i) {
cnt += a[i] == v;
}
ans = std::min(ans, dn - cnt);
}
printf("%d\n", std::max(0, ans));
}グループBの接尾辞木
説明
長さを考えると、\(\ N-)を各位置の文字列\(私は\) 、およびそれが戻ってそれを取る\((M - 1)\ ) 文字がされた\(m個\)最初などの文字を\(私は\)ストリング。(場合は、サブストリングの長さは、端部に到達\(N--。1 I + \) )。現在、これらの\(N \)辞書式順序に従い、それらの行の最初の文字、位置に応じて配置されたサブストリングが、あなたは取引所の最小数を見つけ、隣接する文字列のみを入れ替えることができます。
制限事項
すべてのデータのために、\(1 \のLeq m個の\ n型のLeq \のLeq 50000 \) 、ストリングは、小文字が含まれています
最初のための\(60 \%の\)データ、\(1 \ n型のLeq \のLeq 5000 \) 。
別の\(10 \%の\)データ、\(1 \のLeq M \ 1当量5 \)
別の\(10 \%\)データ、ランダムに生成された文字列。
解決
最初の結論は、降順に配列に従って、隣接するアイテムを交換するだけでなく、交換の最適な数は、シーケンス番号を逆にすることである、ということです。証明は最初のシーケンスの末尾に移動する最大の要素を考慮することができ、必要とされている最大の要素をされた動画の数が、数を逆にして、最後の要素の配列を除去するために貢献し、残りの配列は、数学的誘導を行うためにソートし続けそれはすることができます。
だから、各サブ文字列が辞書順のランキングは、私たちができることを知っている(O(N \ログを\ n \)) 答えを計算しています。
考慮前(\ 60 \%\)データであってもよい\(O(NM)\)次にソートするバブリングすることにより、各サブストリングを識別するために、((N ^ 2)Oを\ \) 逆で測定しました番号。しかし、おそらく唯一のzxy、これはsb(逆転しようとするバブルを取るだろう
以下のために\(m個\当量5 \)のデータは、使用して並べ替えBITたりmergesortうまく追求します。
ランダムデータ列のために、我々は、同じ確率が比較を入力する最初の文字である場合に比べ辞書式順序で、注意\(\ FRAC。1 {{25} \}タイムズ26 \である)、次いで、上記の正方形の確率のビット比較の確率が。同様に、我々はすべての時間を超えない、比較的非常に少ない数、予想されることを見出した\(5 \)をするので、時間の複雑さの一種である\(O(NT \ログN ) \) 、ここで\(T \)は比較の所望の数はランダムな文字列で2つの文字列を検知されています。しかし、彼はすべての文字列にスペースが行のオリジナルシリーズスイープにそう直接、アウトバーストします求めていることを指摘しています。だけではなくについてある鉄漢漢は、すべてのサブ文字列は、一対を求めています(zxy
すべてのデータのために、我々は、このような2つの異なる文字列が長さに相当する長さである限り、二つの文字列の接頭辞を掃引前から後ろに、二つの文字列辞書式順序を比較するプロセスを検討し、文字によって比較することができます2つの文字列が辞書的に、私たちは別のプレフィックスが最初の2つの文字列を見つけることを検討してください。プレフィックスの長さは、2つの点、すなわち、種々の長さを発見した場合、2つの文字列のプレフィックス長の長さが、第一の長さの異なるプレフィックス長がこれより大きくてはならないように、異なる第1またはプレフィックスの長さでありますこの長さよりも大きくなければなりません。
2つの文字列を分析することはHASHによって解決することができる同じ接頭辞です。これは、時間複雑行うことができる\(O(N Nログ\ M)\ログ\) A、\(O(\ Mログ) \)は2点の複雑さを。
なぜなら、文字列に関連する場所と文字要件の良いが、何もする(見つける方法については\(AB \)と\(BAの\)オーダーに関する異なる要件を、しかしとして\(ABABの\)は、裁判官の前に2つの文字が必要です2文字の組成、およびの文字位置独立クレーム)文字列と同じhash関数は、元の文字列は、可能性がhash再び、元の配列の違いhash再び、元の2次微分文字列がhash再びされているhashダウン(のような
コード
(80点)
#include <cstdio>
#include <algorithm>
typedef long long int ll;
const int maxn = 50005;
int n, m, ans;
int v[maxn], w[maxn];
char S[maxn];
struct BIT {
int A[maxn];
inline int lowbit(const int x) { return x & -x; }
inline void update(int x, const int v) { do A[x] += v; while ((x += lowbit(x)) <= n); }
inline int query(int x) { int _ret = 0; do _ret += A[x]; while (x -= lowbit(x)); return _ret; }
};
BIT tree;
bool cmp(const int &a, const int &b);
int main() {
freopen("sort.in", "r", stdin);
freopen("sort.out", "w", stdout);
scanf("%d %d\n%s", &n, &m, S + 1);
for (int i = 1; i <= n; ++i) { v[i] = i; }
std::sort(v + 1, v + 1 + n, cmp);
for (int i = 1; i <= n; ++i) {
w[v[i]] = i;
}
for (int i = 1; i <= n; ++i) {
ans += tree.query(n) - tree.query(w[i]);
tree.update(w[i], 1);
}
qw(ans, '\n', true);
return 0;
}
inline bool cmp(const int &a, const int &b) {
for (int len = 1, i = a, j = b; len <= m; ++i, ++j, ++len) {
if ((i > n) || (j > n)) {
return i > n;
} else if (S[i] != S[j]) {
return S[i] < S[j];
}
}
return a < b;
}(STD)
#include <cstdio>
#define mo 1000000007
#define N 50055
int f[N],s[N],tmp[N],n,m,i,ch,ans;
long long hash[N],pow[N];
//二分+哈希求以i开头的和以j开头的两个子串哪个字典序更小
bool lessThanOrEqual(int i, int j)
{
if (i == j) return true;
int l, r, k;
long long hsi, hsj;
//二分求i和j开始从左向右第一位不同的位
l = 0;
r = m+1;
if (n-j+2 < r) r = n-j+2;
if (n-i+2 < r) r = n-i+2;
while (r-l > 1)
{
k = (l+r)/2;
//子串[i,i+k-1]的哈希值
hsi = hash[i+k-1]-hash[i-1]*pow[k]%mo;
if (hsi < 0) hsi += mo;
//子串[j,j+k-1]的哈希值
hsj = hash[j+k-1]-hash[j-1]*pow[k]%mo;
if (hsj < 0) hsj += mo;
if (hsi == hsj) l = k; else r = k;
}
//s[i+l]和s[j+l]是第一位不同的位
if (l == m) return true;
return s[i+l] < s[j+l];
}
//归并排序
void sort(int l, int r)
{
if (l == r) return;
int mi = (l+r)/2;
sort(l, mi);
sort(mi+1, r);
int i=l, j=mi+1;
int nt = l;
while (i<=mi || j<=r)
{
bool ilej;
if (i > mi) ilej = false;
else
if (j > r) ilej = true;
else ilej = lessThanOrEqual(f[i],f[j]);
if (ilej) tmp[nt++] = f[i++];
else
{
tmp[nt++] = f[j++];
//从右区间取数时,右区间和左区间之间产生了继续对
//累加答案
ans += mi-i+1;
}
}
for (i=l; i<=r; ++i) f[i] = tmp[i];
}
int main()
{
freopen("sort.in", "r", stdin);
freopen("sort.out", "w", stdout);
scanf("%d%d", &n, &m);
hash[0] = 0;
pow[0] = 1;
for (i=1; i<=n; ++i)
{
for (ch=getchar(); ch<=32; ch=getchar());
s[i] = ch-96;
//预处理hash[i]=子串[1,i]的哈希值
hash[i] = (hash[i-1]*29+s[i])%mo;
//预处理pow[i]=29^i
pow[i] = pow[i-1]*29%mo;
f[i] = i;
}
s[n+1] = 0;
sort(1, n);
printf("%d\n", ans);
return 0;
}Cチョコレート
そこに分割される(N \回M \)\形状に非常に規則的なものの、格子長方形のチョコレートが、品質が均一に分布しているわけではない、各セルは、それ自身の重量有する\(W_ {I、J} \)と、\を( N \回数M \)は正の整数。もしチョコレートのブロックに切断する必要があります\(K \)片を、各要件が矩形であり、かつ重量がそのいる\(A_1 \ SIM a_k \) 。チョコレートの重量に等しい重量のすべてのグリッドとそれが含まれています。
グリッドの水平または垂直線が二つの小さなチョコレートに切断し沿って、あなたは、各大チョコレートから選択することができ、チョコレートを切ります。切断を続けることができますチョコレートの小片を削減。切削パスは、ポリラインまたはスラッシュすることはできません。いつでも、現在のすべてのチョコレートは長方形でなければなりません。
与えられたチョコレートとセグメンテーションの要件については、あなたは、上記の要件を満たすために、カット・ソリューションがあるかどうかを判断します。
そこ\(T \)データのセット、タイムリミット\(2S \) 。
制限事項
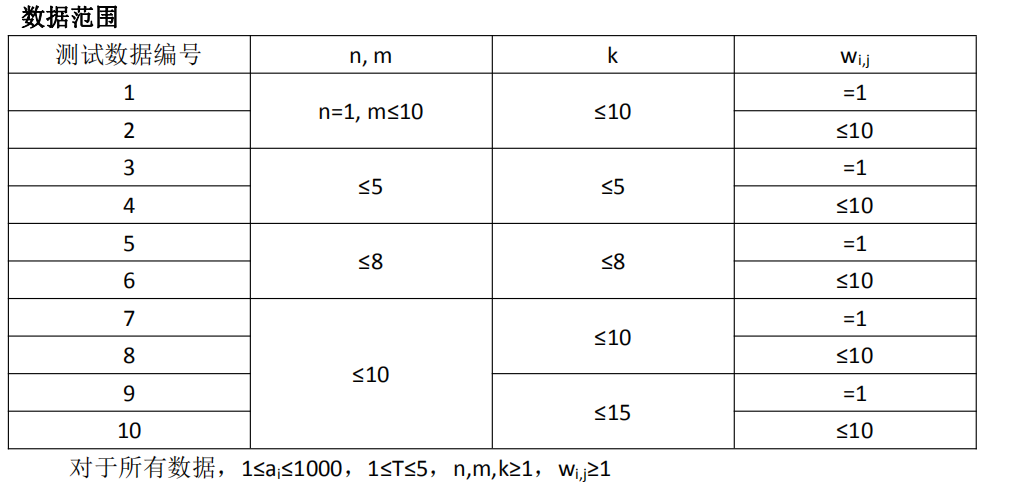
解決
アルゴリズム\(1 \)
判定は、結合に等しい\(m個\)場合、\は(W \)常に等しく\(1 \)フォロー限り、一つだけの行を\(\)カットにします。
テスト可能ポイント:\(1 \) 。予想スコア\(10〜PTS \)
アルゴリズム\(2 \)
BLAST検索カットを複数回切断する場合、各ノートはそう最大カット、チョコレート片が生成される新たなカットを持っています\(K \)ナイフ、およびチョコレートの各部分のために、唯一持っている(O(N + M)\ \) 種カット法、従って探索木の深さである(K \)\は、各ノードが有する(\(N + M)\ ) 子供。バーストの検索の複雑\(O(〜T(N-M +)の^ K)\) 。
テストポイント:\(1、2〜3〜4〜\) 、所望のスコア\(40〜PTS \)
アルゴリズム\(3 \)
同様ダフト鉄それぞれが満たすために戻って切断しなければならないことを、間違った質問を読んとして、\(\)をした後、ゴミバースト検索を書くに得ることができる\(40のPTSを\) 。zxy
アルゴリズム\(4 \)
ことに注意してください\(k個の\)が非常に小さく、等圧のために極めて適しています。
セット\(F_ {I、J、 X、Y、S}は\) 左上隅がある((I、J)\)\、右下隅の\((X〜Y) \) 長方形満たす\ (\)状態にある\(S \)は、プロセスが列挙は、どのような状況に合うようにカットしたものナイフ限り移動します。書かれたノートは、非常に良好な書き込みを発見しました。
時間複雑度\(O(M ^ T 2 ^ N-2(N-M +)を3 ^ K)\) 。宇宙複雑\(O(N-2M ^ 2 ^ \ K ^タイムズ。3)\) 。
テストポイント:\(1〜\ SIM 6 \。) 、所望のスコア\(60〜PTS \)
アルゴリズム\(5 \)
これは、状態の数のボトルネックの複雑さが最適な状態と考えると述べています。
私たちは、決定した矩形トップを左右することを発見し、我々はそれが満足して判断した場合(\)\その後、彼の下の左右を決定することができ、合計。だから私たちは、限り、決定されたことがわかります\(I、〜J、〜 X \) と\(S \) 、その後、\(Yは、\)を決定することができますので、検索は長方形であり、と等しくないときS \(\します)状態\(\)カット状態の場合、状態の数に対する検索となる\(O(N-M ^ 2 \ 2 ^ K回)\) 。
したがって、この時間複雑\(O(T \ ^ N-2回\タイムズM \タイムズ(N-M +)を\ K ^回3)\) 。
:によってテストポイント(1〜\ SIM 8 \)\、所望のスコア\(PTS〜80 \) 。
アルゴリズム\(6 \)
以下の場合(W = 1 \)\のポイントは、我々はいくつかの小さな四角形を取るのと同等に注意し、このような大きな長方形を構成します。小さな四角形のそれぞれが同一であるので、我々は、特に長方形の列の最初の数行を記録する必要はありません。したがって、それが提供されてもよい\(F_は{I、J、 S} \) の長さである\(Iは\) 、幅\(J \)長方形ステート綴ることができ\(S \)\(\ )、転送がまだナイフが切断された方法を列挙することができるとき。
時間複雑度\(O(N-タイムズM \タイムズ(N-M +)を\ K ^回3)\ \) 。
試験によって点:\(1、1-3、1-5、1-7、1-9 \) 、所望のスコア\(PTS〜50 \) 。
アルゴリズム\(7 \)
転送時に、我々はコレクションに移された列挙されていることを注意しない、我々はもはやどこナイフカット列挙する必要があり、一定のため、両方の垂直および一つだけにカットアップ横方向ナイフ法、特定の切断ナイフ、この位置は、バイナリとすることができます。そのような複雑さはに転送するように最適化されている\(O(\ログM)\) 。合計時間複雑度\(O(N-M。3 ^ 2 ^ K \ログM)\) 。あなたは、すべてのテストポイントを渡すことができます。
予想スコア\(100のPTS〜\) 。
コード
(80点)
#include <cstdio>
#include <cstring>
typedef long long int ll;
const int maxn = 11;
const int maxt = 1030;
bool vis[maxn][maxn][maxn][maxn][maxt], frog[maxn][maxn][maxn][maxn][maxt];
int n, m, k, T;
int MU[maxn][maxn], A[maxn], sum[maxn][maxn], val[maxt];
void work();
void clear();
bool dfs(const int x, const int y, const int z, const int w, const int S);
int main() {
freopen("chocolate.in", "r", stdin);
freopen("chocolate.out", "w", stdout);
qr(T);
while (T--) {
clear();
work();
}
return 0;
}
void clear() {
memset(A, 0, sizeof A);
memset(MU, 0, sizeof MU);
memset(val, 0, sizeof val);
memset(vis, 0, sizeof vis);
memset(sum, 0, sizeof sum);
memset(frog, 0, sizeof frog);
n = m = k = 0;
}
void work() {
qr(n); qr(m); qr(k);
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
qr(MU[i][j]);
sum[i][j] = sum[i - 1][j] + sum[i][j - 1] - sum[i - 1][j - 1] + MU[i][j];
}
}
for (int i = 0; i < k; ++i) {
qr(A[i]);
}
int ALL = (1 << k) - 1;
for (int S = 1; S <= ALL; ++S) {
for (int i = 0; i < k; ++i) if (S & (1 << i)) {
val[S] += A[i];
}
}
puts(dfs(1, 1, n, m, ALL) ? "yes" : "no");
}
bool dfs(const int x, const int y, const int z, const int w, const int S) {
bool &thisv = vis[x][y][z][w][S], &thisf = frog[x][y][z][w][S];
if (thisv) { return thisf; }
thisv = true;
if ((sum[z][w] - sum[x - 1][w] - sum[z][y - 1] + sum[x - 1][y - 1]) != val[S]) {
return false;
}
if ((S & (S - 1)) == 0) {
return thisf = true;
}
for (int i = x; i < z; ++i) {
for (int S0 = S; S0; S0 = (S0 - 1) & S) if (dfs(x, y, i, w, S0) && dfs(i + 1, y, z, w, S ^ S0)) {
return thisf = true;
}
}
for (int i = y; i < w; ++i) {
for (int S0 = S; S0; S0 = (S0 - 1) & S) if (dfs(x, y, z, i, S0) && dfs(x, i + 1, z, w, S ^ S0)) {
return thisf = true;
}
}
return false;
}(STD)
#include <cstdio>
#include <list>
#define MAXK 15
#define N 11
struct Quad
{
int a, b, c, d;
Quad(int _a, int _b, int _c, int _d): a(_a), b(_b), c(_c), d(_d) {}
};
std::list<Quad> lf, lfx, lfy;
char f[N][N][N][1<<MAXK],fx[N][N][N][1010],fy[N][N][N][1010];
int sumx[N][N][N],sumy[N][N][N],suma[1<<MAXK],bg[1<<MAXK],ed[1<<MAXK],c[15000000],e[MAXK+1],a[20],
n,m,K,i,j,l,r,T,sta,nc,w;
/*
求:以j1为左边界、j2为右边界、i1为上边界的矩形中,下边界为多少的矩形
重量和是w。如果不存在则返回-1
用二分求
*/
int calcx(int j1, int j2, int i1, int w)
{
// fx[j1][j2][i1][w]用于记录该子问题有没有被求结果
// 已求结果则直接返回结果
if (fx[j1][j2][i1][w] != 0) return fx[j1][j2][i1][w];
// 未求结果,将该状态加入待清空队列
lfx.push_back(Quad(j1,j2,i1,w));
// 二分求i2的位置
int l, r, k;
l = i1-1;
r = n+1;
while (r-l > 1)
{
k = l+r>>1;
if (sumx[j1][j2][k]-sumx[j1][j2][i1-1] <= w) l = k; else r = k;
}
if (sumx[j1][j2][l]-sumx[j1][j2][i1-1] != w) l = -1;
return fx[j1][j2][i1][w]=l;
}
/*
求:以i1为上边界、i2为下边界、j1为左边界的矩形中,右边界为多少的矩形
重量和是w。如果不存在则返回-1
和上面对称
*/
int calcy(int i1, int i2, int j1, int w)
{
if (fy[i1][i2][j1][w] != 0) return fy[i1][i2][j1][w];
lfy.push_back(Quad(i1,i2,j1,w));
int l, r, k;
l = j1-1;
r = m+1;
while (r-l > 1)
{
k = l+r>>1;
if (sumy[i1][i2][k]-sumy[i1][i2][j1-1] <= w) l = k; else r = k;
}
if (sumy[i1][i2][l]-sumy[i1][i2][j1-1] != w) l = -1;
return fy[i1][i2][j1][w]=l;
}
/*
求(i1,j1)~(i2,j2)的矩形能否切出sta中的巧克力
*/
bool work(int i1, int i2, int j1, int j2, int sta)
{
//记忆化:求过了则直接返回
if (f[i1][i2][j1][sta] != 0) return f[i1][i2][j1][sta]==1;
if (bg[sta] == ed[sta]) return true;
//未求过,将该状态加入待清空队列
lf.push_back(Quad(i1,i2,j1,sta));
int i, sta2, x, y;
//枚举sta的每个非空真子集
for (i=bg[sta]; i<ed[sta]; ++i)
{
sta2 = c[i];
//尝试横向切
x = calcx(j1,j2,i1,suma[sta2]);
if (x != -1)
if (work(i1,x,j1,j2,sta2) && work(x+1,i2,j1,j2,sta-sta2))
{
f[i1][i2][j1][sta] = 1;
return true;
}
//尝试纵向切
y = calcy(i1,i2,j1,suma[sta2]);
if (y != -1)
if (work(i1,i2,j1,y,sta2) && work(i1,i2,y+1,j2,sta-sta2))
{
f[i1][i2][j1][sta] = 1;
return true;
}
}
f[i1][i2][j1][sta] = -1;
return false;
}
void dfs(int sta, int t)
{
if (t == MAXK)
{
if (sta > 0) c[nc++] = sta;
return;
}
if (sta&e[t]) dfs(sta-e[t], t+1);
dfs(sta, t+1);
}
int main()
{
freopen("chocolate.in", "r", stdin);
freopen("chocolate.out", "w", stdout);
e[0] = 1;
for (i=1; i<=MAXK; ++i) e[i] = e[i-1]*2;
//预处理每个sta有哪些非空真子集,连续存储在队列c中
nc = 1;
for (sta=1; sta<e[MAXK]; ++sta)
{
bg[sta] = nc; //bg表示sta的子集在c中的开头位置
dfs(sta, 0); //dfs求sta的非空真子集
--nc;
ed[sta] = nc; //ed表示sta的子集在c中的结尾位置
}
scanf("%d", &T);
while (T--)
{
scanf("%d%d%d", &n, &m, &K);
for (i=1; i<=n; ++i)
for (j=1; j<=m; ++j)
{
scanf("%d", &w);
//sumy[i][j][k]:从第i行到第j行,从第1列到第k列构成的矩形的重量和
sumy[i][i][j] = sumy[i][i][j-1]+w;
//sumx[i][j][k]:从第i列到第j列,从第1行到第k行构成的矩形的重量和
sumx[j][j][i] = sumx[j][j][i-1]+w;
}
for (l=1; l<n; ++l)
for (r=l+1; r<=n; ++r)
for (j=1; j<=m; ++j) sumy[l][r][j] = sumy[l][r-1][j]+sumy[r][r][j];
for (l=1; l<m; ++l)
for (r=l+1; r<=m; ++r)
for (i=1; i<=n; ++i) sumx[l][r][i] = sumx[l][r-1][i]+sumx[r][r][i];
for (i=1; i<=K; ++i) scanf("%d", &a[i]);
//求出{ai}的各个子集的重量和
//suma[sta]:sta中的巧克力的总重量
for (sta=0; sta<e[K]; ++sta)
{
suma[sta] = 0;
for (i=sta, j=1; i>0; i>>=1, ++j)
if (i&1) suma[sta] += a[j];
}
// 如果所有ai的总重量!=巧克力的总重量
if (suma[e[K]-1] != sumy[1][n][m])
{
printf("no\n");
continue;
}
//lf、lfx、lfy用于记录哪些状态被记忆化了,用于之后清零
lf.clear();
lfx.clear();
lfy.clear();
if (work(1,n,1,m,e[K]-1)) printf("yes\n");
else printf("no\n");
//清零记忆化过的状态
for (std::list<Quad>::iterator it=lf.begin(); it!=lf.end(); ++it) f[it->a][it->b][it->c][it->d] = 0;
for (std::list<Quad>::iterator it=lfx.begin(); it!=lfx.end(); ++it) fx[it->a][it->b][it->c][it->d] = 0;
for (std::list<Quad>::iterator it=lfy.begin(); it!=lfy.end(); ++it) fy[it->a][it->b][it->c][it->d] = 0;
}
return 0;
}