次のようにキーのデータ型のRedisのサポートは、以下のとおりです。
- 文字列型
- ハッシュタイプ
- リストタイプ
- コレクション型
- インデックス付きのコレクション
文字列型
Redisの文字列型は、データの最も基本的なタイプである、それは、バイナリデータを含む文字列の任意の種類を、保存することができます。キーは、文字列型は、512メガバイトの最大容量のデータを格納していることができます。
1、コマンドの文字列
1.1課題と値
キーの値を設定します
キーGET
例としては、次のとおりです:

![]()
ヒント:キーに名前を付けるためのRedisは必須ではありませんが、「オブジェクトタイプ:オブジェクトID:オブジェクトのプロパティ」を使用することをお勧め名前にし、区切られた複数の単語をお勧めします。「」
1.2デジタルインクリメント
INCRキー
文字列がコマンドINCRを可能にすることにより、整数形式で格納されている場合、現在のキーをインクリメントし、例えば、インクリメントされた値を返します。

![]()
INCRBYキー増分
INCRBYコマンドINCRコマンドは、前者は、例えば、指定可能なパラメータの増分値だけ増加させ、基本的に同じです。

![]()
1.3デジタルが減少
DECRキー
DECRBYキーデクリメント
DECR現在のキーコマンドはデクリメントされ、DECREBYコマンドは、例えば、換算値、同じ用法及びINCRBYコマンドを指定します。

![]()
1.4増加し、指定されたfloat
INCRBYFLOATキー増分
例えば、倍精度浮動小数点数をインクリメントするINCRBYFLOATコマンド:

![]()
値1.5は尾に追加されます
キーの値を追加
APPEND関数値にキー値の末尾に追加され、キーの値は、キーが現在の値でない場合、戻り値は、追加の文字列の合計の長さ変更される設定。例:

![]()
1.6のGet文字列の長さ
STRLENキー
キーが0、例戻る存在しない場合STRLENコマンドは、キーの長さを返します。

![]()
同時に、1.7 /複数のキーを設定します
MGETキー[キー...]
MSETキー値[キー値...]
例としては、キーセットの複数のキーを取得するために、別々に又はMSETコマンドMGETして使用してもよいです。

![]()
ハッシュの第二に、タイプ
散列类型的键值是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型。散列类型适合存储对象:使用对象类别和ID构成键名,使用字段表示对象的属性,字段值则存储属性值。例如要存储ID为2的汽车对象,可以设置键为car:2,键值为name:"奥迪",其中键值中"name"为字段,"奥迪"为字段值。
1、散列常用命令
1.1 赋值与取值
HSET key field value
HGET key field
这两个命令分别用来给字段赋值和获得字段的值,HSET命令不区分是对字段的插入还是更新操作,当字段不存在时为插入操作,当字段存在时为更新操作,示例如下:
![]()
提示:在Redis中每个键都属于一个明确的数据类型,如通过HSET命令建立的键是散列类型,通过SET命令建立的键是字符串类型等。使用一个数据类型的命令操作另一种数据类型的键会提示错误:(error) WRONGTYPE Operation against a key holding the wrong kind of value。但也不是所有命令都是如此,如SET命令可以覆盖已经存在的键,不论键原来是什么类型。
HMSET key field value [field value ...]
HMGET key field [field ...]
当需要同时设置或获取多个字段的值时,可以使用HMSET/HMGET命令,示例如下:

![]()
HGETALL key
HGETALL命令可以获取键中的所有字段和字段值,示例如下:

![]()
1.2 判断字段是否存在
HEXISTS key field
HEXISTS命令用来判断一个字段是否存在,存在则返回1,否则返回0,示例如下:

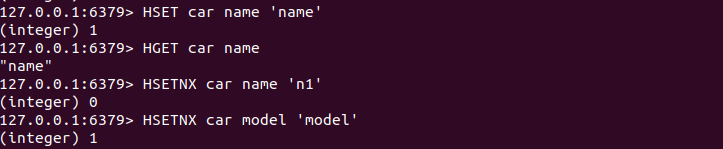
1.3 当字段不存在时赋值
HSETNX key field value
如果字段已经存在,HSETNX命令将不执行任何操作,示例如下:
1.4 增加数字
HINCRBY key field increment
HINCRBY命令可使字段增加指定的整数,示例如下:

1.5 删除字段
HDEL key field [field ...]
HDEL命令可以删除一个或多个字段,返回值是被删除的字段个数,示例如下:

1.6 只获取字段名或字段值
HKEYS key
HVALS key

1.7 获取字段数量
HLEN key

三、 列表类型
列表类型可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。列表类型内部是使用双向链表实现的,所以向列表两端添加元素的时间复杂度为O(1),获取越接近两端的元素速度越快。
1、列表常用命令
1.1 向列表两端增加元素
LPUSH key value [value ... ]
RPUSH key value [value ... ]
LPUSH命令和RPUSH命令分别用来向列表左边和右边增加元素,返回值表示增加元素后的列表长度,示例如下:

1.2 从列表两端弹出元素
LPOP key
RPOP key
LPOP命令可以从列表的左边弹出一个元素,LPOP命令执行步骤:第一步是将列表左边的元素从列表中移除,第二步是返回被移除的元素值,RPOP命令类似,示例如下:

1.3 获取列表中元素的个数
LLEN key
当键不存在时LLEN会返回0,示例如下:

1.4 获取列表片段
LRANGE key start stop
LRANGE命令能够获取列表中的某一片段,返回索引从start到stop之间的所有元素(包括两端的元素),Redis的列表起始索引为0。

LRANGE命令也支持负索引,表示从右边开始取数,如"-1"表示最右边第一个元素,依次类推。

注意两种特殊情况:
(1)如果start的索引位置比stop的索引位置靠后,则会返回空列表
(2)如果stop大于实际的索引范围,则会返回到列表最右边的元素

1.5 删除列表中指定的值
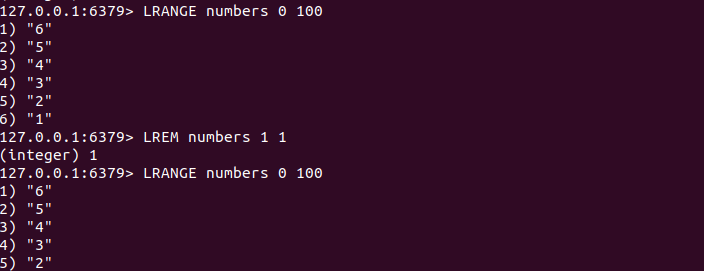
LREM key count value
LREM命令会删除列表中前count个值为value的元素,返回值是实际删除的元素个数,根据count值的不同,LREM命令的执行方式会有差异:
(1)当count>0时LREM命令会从列表左边开始删除前count个值为value的元素;
(2)当count<0时LREM命令会从列表右边开始删除前|count|个值为value的元素;
(3)当count=0时LREM命令会删除所有为value的元素。
1.6 获取/设置指定索引的元素值
LINDEX key index
LSET key index value
LINDEX命令用来返回指定索引的元素,索引从0开始

如果index是负数则表示从右边开始计算的索引,最右边元素的索引为-1

LSET命令是为指定索引设置值

1.7 只保留列表指定片段
LTRIM key start end
LTRIM命令可以删除指定索引范围之外的所有元素,示例:

1.8 向列表中插入元素
LINSERT key BEFORE|AFTER pivot value
LINSERT命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定value插入到该元素的前面还是后面,返回值是插入后列表的元素个数


1.9 将元素从一个列表转到另一个列表中
RPOPLPUSH source destination
RPOPLPUSH命令会先从source列表的右边弹出一个元素,然后将其加入到destination列表的左边,并返回这个元素的值,整个过程是原子的。
当把列表类型作为队列使用时,RPOPLPUSH命令可以很直观地在多个队列中传递数据。当source和destination相同时,RPOPLPUSH命令会不断地将队尾地元素移到队首。
四、集合类型
集合中的每个元素都是唯一的,且没有顺序。集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,且多个集合之间还可以进行并集、交集和差集运算。
1、集合常用命令
1.1 增加/删除元素
SADD key member [member ... ]
SREM key member [member ... ]
SADD命令用来向集合中增加一个或多个元素,如果键不存在则会自动创建。因为集合中的元素是唯一的,如果要加入的元素已经存在于集合中就会忽略这个元素,返回值是成功加入的元素数量。

SREM命令用来从集合中删除一个或多个元素,并返回成功删除的元素个数。

1.2 获取集合中的所有元素
SMEMBERS key
SMEMBERS命令会返回集合中的所有元素,示例如下:

1.3 判断元素是否存在集合中
SISMEMBER key member

1.4 集合间运算
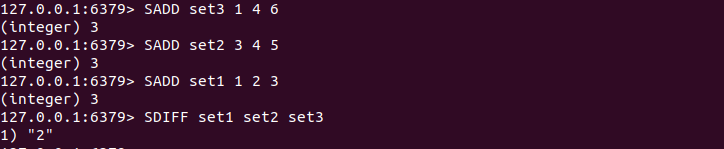
SDIFF key [key ... ]
SDIFF命令用来对多个集合执行差集运算。集合A与集合B的差集表示为A-B,代表所有属于A且不属于B的元素构成的集合,示例如下:

SDIFF命令还支持同时传入多个键
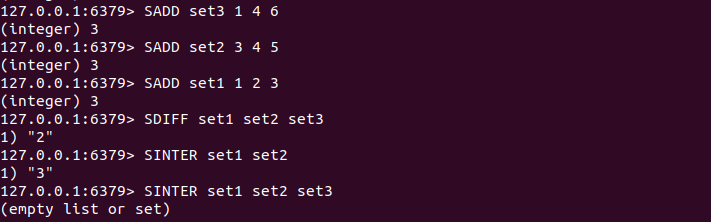
SINTER key [key ... ]
SINTER命令用来对多个集合执行交集运算。
SUNION key [key ... ]
SUNION命令用来对多个集合执行并集运算。
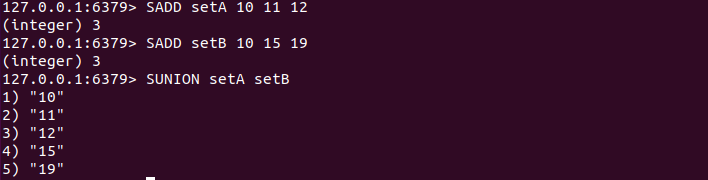
1.5 获取集合中元素个数
SCARD key
SCARD命令用来获取集合中的元素个数。

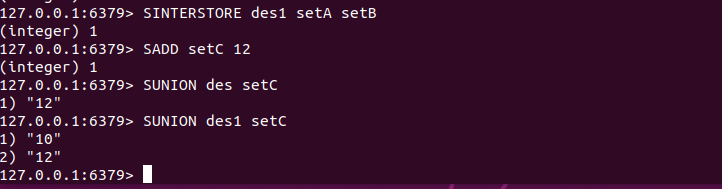
1.6 进行集合运算并将结果存储
SDIFFSTORE destination key [key .... ]
SINTERSTORE destination key [key ... ]
SUNIONSTORE destination key [key ... ]
SDIFFSTORE命令和SDIFF命令类似,区别在于SIDFFSTORE命令不会直接返回运算结果,而是将结果存储在destination键中,常用于需要进行多步集合运算的场景中,如需要先计算差集再将结果和其他键计算交集等。
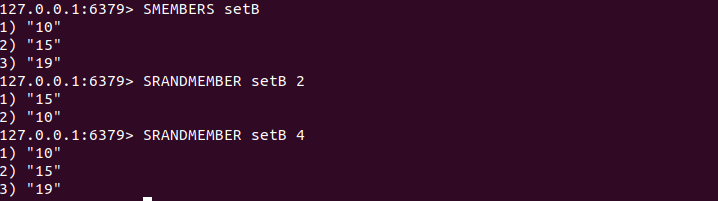
1.7 随机获取集合中的元素
SRANDMEMBER key [count]
SRANDMEMBER命令用来随机从集合中获取一个元素,如:

还可以根据count参数来一次随机获取count个元素,根据count的正负不同,表现不同。
(1)当count为正数时,SRANDMEMBER会随机从集合中获取count个不重复的元素。如果count的值大于集合中的元素个数,则返回集合中的所有元素
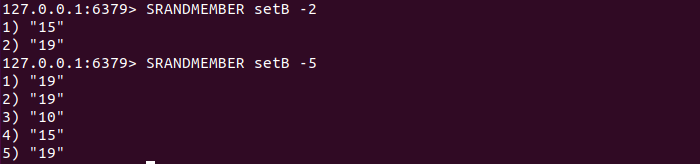
(2)当count为负数时,SRANDMEMBER会随机从集合中获取|count|个元素,元素有可能相同。
1.8 从集合中弹出一个元素
SPOP key
SPOP命令会从集合中随机选择一个元素弹出。

五、有序集合类型
1、介绍
在集合的基础上,有序集合类型为集合中的每个元素都关联了一个分数,使得我们不仅可以完成插入、删除元素和判断元素是否存在等类型的操作,还能够获得分数最高的前N个元素、获得指定分数范围内的元素等与分数有关的操作。
2、有序集合与列表的区别
(1)列表类型是通过链表实现的,获取靠近两端的数据速度较快,而当元素增多后,访问中间数据的速度会较慢,所以更适合实现如“新鲜事”、“日志”这样很少访问中间元素的应用。
(2)有序集合类型是使用散列表和跳跃表实现的,所以即使读取位于中间部分的数据速度也很快。
提示:散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
(3)列表中不能简单地调整某个元素的位置,有序集合可通过更改元素的分数进行调整。
(4)有序集合比列表类型更耗费内存。
3、有序集合常用命令
3.1 增加元素
ZADD key score member [score member ... ]
ZADD命令用来向有序集合中加入一个元素和该元素的分数,如果元素已经存在,则会用新的分数替换原来的分数。返回值是加入到集合中的元素个数。
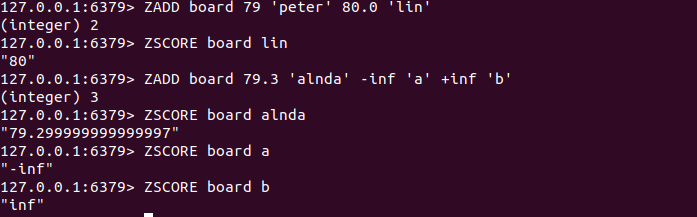
3.2 获取元素的分数
ZSCORE key member

3.3 获取排名在某个范围内的元素列表
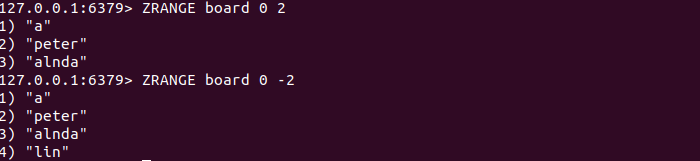
ZRANGE key start stop [WITHSCORES]
ZREVRANGE key start stop [WITHSCORES]
ZRANGE命令会按照元素分数从小到大返回索引从start到stop之间的所有元素(包含两端的元素,同时支持负数索引)。
如果需要在获取元素的同时获得元素的分数,可在ZRANGE命令后加上WITHSCORES参数。
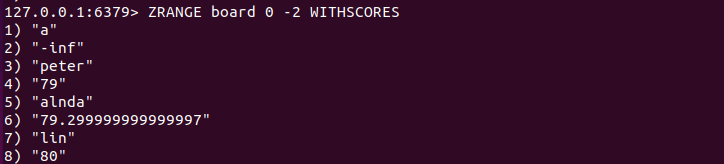
如果两个元素的分数相同,Redis会按照字段顺序进行排序("0"<"9"<"A"<"Z"<"a"<"z")
3.4 获取指定分数范围的元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZRANGEBYSCORE命令按照元素分数从小到大的顺序返回分数在min和max之间的元素(包含min和max)。

如果希望分数范围不包含端点值,可以在分数前加上"("符号,示例如下:

[LIMIT offset count]参数的作用:在获取的元素列表的基础上向后偏移offset个元素,并且只获取前count个元素。

3.5 增加某个元素的分数
ZINCRBY key increment member
ZINCRBY命令可以增加一个元素的分数,返回值是更改后的分数。如果指定元素不存在,Redis在执行命令前会先建立它并将它的分数赋值为0再执行操作。
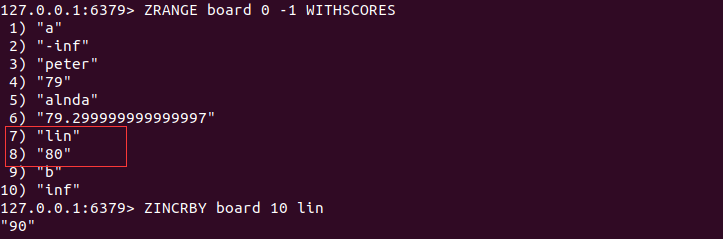
3.6 获取集合中元素的数量
ZCARD key

3.7 获取指定分数范围内的元素个数
ZCOUNT key min max

3.8 删除一个或多个元素
ZREM key member [member ... ]
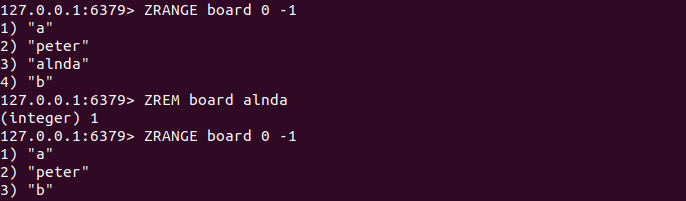
3.9 按照排名范围删除元素
ZREMRANGEBYRANK key start stop
ZREMRANGEBYRANK命令按照元素分数从小到大的顺序删除处在指定排名范围内的所有元素,并返回删除的元素数量。

3.10 按照分数范围删除元素
ZREMRANGEBYSCOREキー最小最大

3.11のランキング要素を取得
ZRANK主要メンバー
ZREVRANK主要メンバー
小さいから指定された要素のランクを取得するために応じて、要素の大部分にZRANKコマンド(最小スコアランキングの要素が0)、ZREVRANKコマンドコントラスト(最大スコアランキングの要素は0です)。

3.12計算交差点順序集合
ZINTERSTORE先numkeysキー[キー...] [WEIGHTS重量[重量...]] [集合のSUM | MIN | MAX]
交差点と宛先複数のキーの順序付けられた集合の存在の結果を計算するZINTERSTOREコマンド、戻り値は、先のキーの要素数です。主な目的地のポイントはAGGREAGTEパラメータによって決定されます。
AGGREGATE SUMの場合(1)、スコアが中スコアの計算に関わる要素の各セットにおける重要な要素の宛先であると、デフォルトの合計によって。
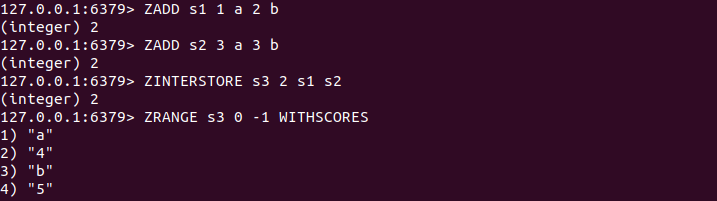
MIN集合体である場合には(2)、宛先鍵要素スコアは、それぞれの計算に関与する要素のセットの最小スコアです。

AGGREGATEがMAXである場合(3)、フラクション先重要な要素は、集合の計算に関係する各要素のスコアの最大値です。

ZINTERSTOREコマンドは、各セットのスコアは、右体重セットの計算に関わる要素が乗算されたパラメータの重みの各セットの重い重量、によって提供することができます。

ZUNINONSTOREコマンドセットを計算し、類似したコマンドZINTERSTOREを設定するために使用されます。