私たちは、それはそれを暗号化して行う方法についてお話しましょう。
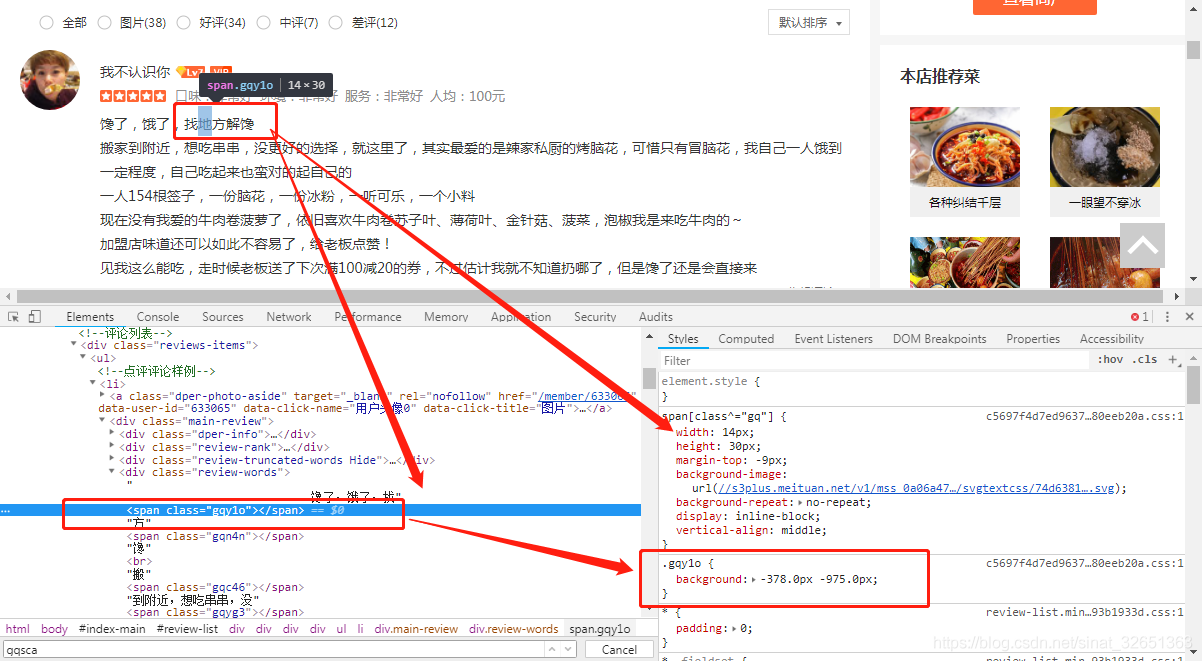
図は次のとおり部分のフォントは、<span>のタグが含まれている、図CSSスタイル表示積雪荷重制御で、実際のSVGの背景である、と彼のCSSのbackgroundプロパティを見ることができ、そして自分自身の効果を確認するために変更することができ、注目のフォントです幅:14px、後で解読役立ちます。
私たちは、それはそれを暗号化して行う方法についてお話しましょう。
図は次のとおり部分のフォントは、<span>のタグが含まれている、図CSSスタイル表示積雪荷重制御で、実際のSVGの背景である、と彼のCSSのbackgroundプロパティを見ることができ、そして自分自身の効果を確認するために変更することができ、注目のフォントです幅:14px、後で解読役立ちます。
アイデア:
完全なHTMLスタイルのコメントセクション1.は、リストの内容全体が追いついて。
2.以下に示すように位置CSSスタイル、ソースコード内のスタイルを取得し、我々はそれがバックグラウンドに対応するための座標情報、各タグのクラス属性値に及ぶ必要があります。
3. SVG画像リンクから動的CSSスタイルは、辞書データベースを生成し、その後、CSSは第二のステップは、実際の値に対応する単語を見つけるために処理され、最終的な実際のコメントを返す座標使用します。
ステップ:
図1は、各タグはまだポジションについて知っておく必要があります。
まず、ソースコードを表示し、CSSスタイルがリンクを保存し、リンク場所を知ります。

二、CSSリンクスタイルはしばらくの間、CSSファイル***** {背景、パスを保存し、暗号化されたパスSVGフォントが含まれている背景画像のタグを取得するための最初のステップがあります: - 。*、 - *}構成された辞書を保存します。
黒板にノック:写真14pxのフォントスタイル幅に述べたように、私たちはバックグラウンド/ 14のx座標を取得し、暗号化はSVGフォントの最終的な位置は、各ラインのSVG列ので、記憶装置のアレイに変換することができます。私たちは、対応を確立することができるようになります。そしてyは値を比較して<パス>にSVG背景座標、彼はフォローアップという。
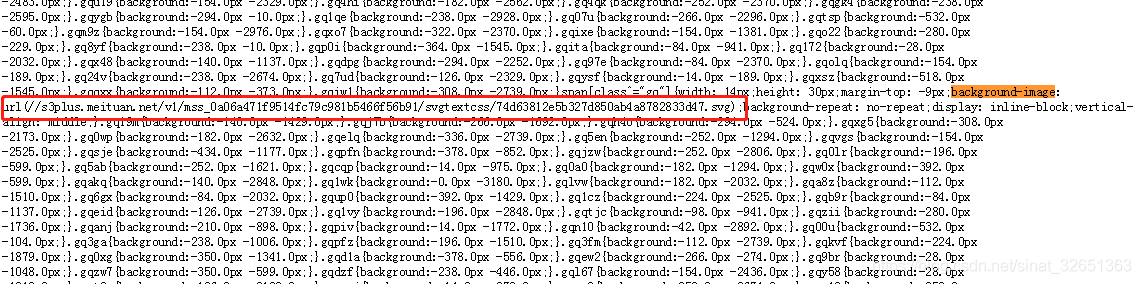
第三に、それはSVGフォントファイル、ノート<パス>はid値のhrefの後に<textPath>タグに対応したタグは、それがDの非常に興味深い値であり、鍵が解読されているが暗号化されています。
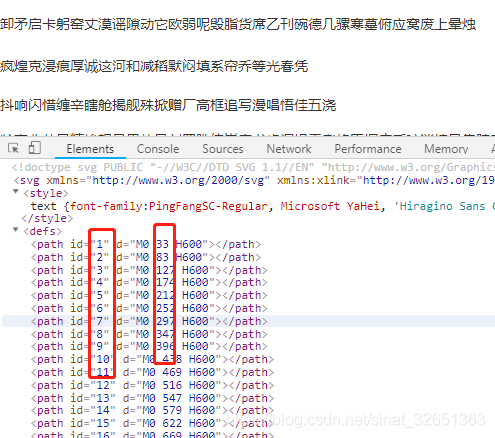

敲黑板了:步骤二中提到过background的y值,再和d列的M0后面值做比较就有意思了,比如
.gqi4j {background: -98.0px -130.0px;} 中的y:-130,取正数130,小于<path>标签中的d属性第二列的174这个值,则对应加密字库实际y轴为174,对应的id=4,就是<textPath>中的href标签,也就是加密字体的y轴坐标,而它的x就是98/14,对应的id=4,href="#4"行里的低98/14个的值,至此一个加密的字就取出来了。
最终效果:
如下图,完整评论内容,右侧部分没显示完部分,需要点开更多评论,原网页中有两个标签,一个完整的,一个局部的。

代码:
1 #!/usr/bin/env python 2 # encoding: utf-8 3 """ 4 @version: v1.0 5 @author: W_H_J 6 @license: Apache Licence 7 @contact: [email protected] 8 @software: PyCharm 9 @file: dazhongdianping.py 10 @time: 2018/12/19 17:45 11 @describe: 大众点评评论抓取-解析 12 """ 13 import sys 14 import os 15 import re 16 import requests 17 from pyquery import PyQuery as pq 18 19 sys.path.append(os.path.abspath(os.path.dirname(__file__) + '/' + '..')) 20 sys.path.append("..") 21 22 23 header_pinlun = { 24 'Host': 'www.dianping.com', 25 'Accept-Encoding': 'gzip', 26 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36' 27 } 28 29 header_css = { 30 'Host': 's3plus.meituan.net', 31 'Accept-Encoding': 'gzip', 32 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36' 33 34 } 35 36 37 # 0-详情页 38 def get_msg(): 39 """ 40 url: http://www.dianping.com/shop/+ 商铺ID +/review_all 41 :return: 42 """ 43 # url = "http://www.dianping.com/shop/110620927/review_all" 44 url = "http://www.dianping.com/shop/96658933/review_all" 45 # url = "https://www.dianping.com/shop/77307732/review_all" 46 html = requests.get(url, headers=header_pinlun) 47 print("1 ===> STATUS", html.status_code) 48 doc = pq(html.text) 49 # 解析每条评论 50 pinglunLi = doc("div.reviews-items > ul > li").items() 51 """ 52 调用评论里的css样式处理和加密字体svg处理 53 :return: 54 dict_svg_text: svg整个加密字库,以字典形式返回 55 list_svg_y:svg背景中的<path>标签里的[x,y]坐标轴,以[x,y]形式返回 56 dict_css_x_y:css样式中,每个加密字体的<span> 标签内容,用于匹配dict_svg_text 中的key,以字典形式返回 57 """ 58 dict_svg_text, list_svg_y, dict_css_x_y = css_get(doc) 59 60 for data in pinglunLi: 61 # 用户名 62 userName = data("div.main-review > div.dper-info > a").text() 63 # 用户ID链接 64 userID = "http://www.dianping.com" + data("div.main-review > div.dper-info > a").attr("href") 65 # 用户评分星级[10-50] 66 startShop = str(data("div.review-rank > span").attr("class")).split(" ")[1].replace("sml-str", "") 67 # 用户描述:机器:非常好 环境:非常好 服务:非常好 人均:0元 68 describeShop = data("div.review-rank > span.score").text() 69 # 关键部分,评论HTML,待处理,评论包含隐藏部分和直接展示部分,默认从隐藏部分获取数据,没有则取默认部分。(查看更多) 70 pinglun = data("div.review-words.Hide").html() 71 try: 72 len(pinglun) 73 except: 74 pinglun = data("div.review-words").html() 75 # 该用户喜欢的美食 76 loveFood = data("div.main-review > div.review-recommend").text() 77 # 发表评论的时间 78 pinglunTime = data("div.main-review > div.misc-info.clearfix > span.time").text() 79 print("userName:", userName) 80 print("userID:", userID) 81 print("startShop:", startShop) 82 print("describeShop:", describeShop) 83 print("loveFood:", loveFood) 84 print("pinglunTime:", pinglunTime) 85 print("pinglun:", css_decode(dict_css_x_y, dict_svg_text, list_svg_y, pinglun)) 86 print("*"*100) 87 88 89 # 1-评论隐含部分字体css样式, 获取svg链接,获取加密汉字background 90 def css_get(doc): 91 css_link = "http:"+doc("head > link:nth-child(11)").attr("href") 92 background_link = requests.get(css_link, headers=header_css) 93 r = r'background-image: url(.*?);' 94 matchObj = re.compile(r, re.I) 95 svg_link = matchObj.findall(background_link.text)[0].replace(")", "").replace("(", "http:") 96 """ 97 svg_text() 方法:请求svg字库,并抓取加密字 98 dict_svg_text: svg整个加密字库,以字典形式返回 99 list_svg_y:svg背景中的<path>标签里的[x,y]坐标轴,以[x,y]形式返回 100 """ 101 dict_avg_text, list_svg_y = svg_text(svg_link) 102 """ 103 css_dict() 方法:生成css样式中background的样式库 104 dict_css: 返回css字典样式 105 """ 106 dict_css = css_dict(background_link.text) 107 return dict_avg_text, list_svg_y, dict_css 108 109 110 # 2-字体库链接 111 def svg_text(url): 112 html = requests.get(url) 113 dict_svg, list_y = svg_dict(html.text) 114 return dict_svg, list_y 115 116 117 # 3-生成svg字库字典 118 def svg_dict(csv_html): 119 svg_text_r = r'<textPath xlink:href="(.*?)" textLength="(.*?)">(.*?)</textPath>' 120 svg_text_re = re.findall(svg_text_r, csv_html) 121 dict_avg = {} 122 # 生成svg加密字体库字典 123 for data in svg_text_re: 124 dict_avg[data[0].replace("#", "")] = list(data[2]) 125 """ 126 重点:http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/74d63812e5b327d850ab4a8782833d47.svg 127 svg <path> 标签里内容对应css样式中background的y轴参数,小于关系, 128 如果css样式中的background的y参数小于 svg_y_re 集合中最小的数,则向上取y轴,('18', 'M0', '748', 'H600'), 129 如.gqi4j {background: -98.0px -745.0px;} 中的y-745,取正数745,小于748,则对应加密字库实际y轴为748,对应的18就是<textPath>中的x轴 130 """ 131 svg_y_r = r'<path id="(.*?)" d="(.*?) (.*?) (.*?)"/>' 132 svg_y_re = re.findall(svg_y_r, csv_html) 133 list_y = [] 134 # 存储('18', 'M0', '748', 'H600') eg:(x坐标,未知,y坐标,未知) 135 for data in svg_y_re: 136 list_y.append([data[0], data[2]]) 137 return dict_avg, list_y 138 139 140 # 4-生成css字库字典 141 def css_dict(html): 142 css_text_r = r'.(.*?){background:(.*?)px (.*?)px;}' 143 css_text_re = re.findall(css_text_r, html) 144 dict_css = {} 145 for data in css_text_re: 146 """ 147 加密字库.gqi4j {background: -98.0px -745.0px;}与svg文件对应关系,x/14,就是svg文件加密字体下标 148 y,原样返回,需要在svg函数中做处理 149 """ 150 x = int(float(data[1])/-14) 151 """ 152 字典参数:{css参数名:(background-x,background-y,background-x/14,background-y)} 153 """ 154 dict_css[data[0]] = (data[1], data[2], x, data[2]) 155 return dict_css 156 157 158 # 5-最终评论汇总 159 def css_decode(css_html, svg_dict, svg_list, pinglun_html): 160 """ 161 :param css_html: css 的HTML源码 162 :param svg_dict: svg加密字库的字典 163 :param svg_list: svg加密字库对应的坐标数组[x, y] 164 :param pinglun_html: 评论的HTML源码,对应0-详情页的评论,在此处理 165 :return: 最终合成的评论 166 """ 167 css_dict_text = css_html 168 csv_dict_text, csv_dict_list = svg_dict, svg_list 169 # 处理评论源码中的span标签,生成字典key 170 pinglun_text = pinglun_html.replace('<span class="', ',').replace('"/>', ",").replace('">', ",") 171 pinglun_list = [x for x in pinglun_text.split(",") if x != ''] 172 pinglun_str = [] 173 for msg in pinglun_list: 174 # 如果有加密标签 175 if msg in css_dict_text: 176 # 参数说明:[x,y] css样式中background 的[x/14,y] 177 x = int(css_dict_text[msg][2]) 178 y = -float(css_dict_text[msg][3]) 179 # 寻找background的y轴比svg<path>标签里的y轴小的第一个值对应的坐标就是<textPath>的href值 180 for g in csv_dict_list: 181 if y < int(g[1]): 182 # print(g) 183 # print(csv_dict_text[g[0]][x]) 184 pinglun_str.append(csv_dict_text[g[0]][x]) 185 break 186 # 没有加密标签 187 else: 188 pinglun_str.append(msg.replace("\n", "")) 189 str_pinglun = "" 190 for x in pinglun_str: 191 str_pinglun += x 192 # 处理特殊标签 193 dr = re.compile(r'</?\w+[^>]*>', re.S) 194 dr2 = re.compile(r'<img+[^;]*', re.S) 195 dr3 = re.compile(r'&(.*?);', re.S) 196 dd = dr.sub('', str_pinglun) 197 dd2 = dr2.sub('', dd) 198 pinglun_str = dr3.sub('', dd2) 199 return pinglun_str 200 201 202 if __name__ == '__main__': 203 get_msg()