ApacheのFLINKとルールエンジンのためのリアルタイムリスク管理ソリューション
インターネットの製品、典型的なリスク管理のシナリオは、次のとおりです。登録、リスク管理、リスク管理の着陸、取引リスク管理、リスク管理やその他の活動、およびリスク管理は、事前にそのイベントの後に最高の予防対策、そうなものです3つの実装シナリオ、再び前に警報や制御物事最高。これは、風がリアルタイム制御システムを持っている必要があります。本論文では、リアルタイムリスク管理ソリューションを提供します。次のようにリスクコントロールは、ビジネスシナリオの製品、リスク管理システムを直接ビジネス・システムを提供し、同様に罰則や分析システムの関連するシステム、関係や役割のシステムです。
ビジネスシステム、通常はAPP +の背景やウェブは、インターネットビジネスのキャリア、ビジネスシステムからのトリガのリスクです。
- 風力制御システム運用システム又は埋め込みポイント情報のデータによれば、現在のユーザまたはイベントのリスクかどうかを決定するために、ビジネス・システムをサポートします。
- 罰システムは、ビジネス・システムは、制限はそうで注文を禁止し、着陸、そのようなコードを追加するなどのリスク管理ユーザまたはイベントまたは罰のリスク管理システムの結果を呼び出します。
- 分析システムは、そのようなキャッチレート政策の急激な低下などのデータに基づいて、リスク管理システムのパフォーマンスを測定するために、風制御システムをサポートするためのシステムは、そのような突然の時間を奪わ完成品として活動、戦略が失敗したことを意味するかもしれません短い、システムも運用/分析は、新しいポリシーことを発見し支援すべきであるなど、全体的なキャンペーン戦略が問題であり得ることを示しています。
風制御システムおよび分析システムは、この記事の焦点であるが、議論のためここで、我々は次のようなビジネスシナリオがあることを前提としています。
風の制御システムは、ルールやモデルの2つの手法を持って、利点のルールはシンプルで直感的な、解釈強い、柔軟、風制御システムにおける限り有効ですが、欠点は壊れやすいですが、黒の生産推測しましたそれは、多くの場合、空気制御部に基づいて、モデルの頑健性を高める必要性と組み合わせて、実際の風力発電制御システムを、失敗します。スペースが限られているリスク管理モデルの要求がある場合でも、この記事では、我々は唯一のリスク管理規則に基づくシステムアーキテクチャを集中、もちろん、アーキテクチャも完全にサポートされています。ルールは、物事のための条件を決定することで、我々は登録に焦点を当て、ログイン、取引活動は、いくつかのルールに想定され、例えば:
- 10以上の登録口座数の最後の時間をIP。
- アカウントグループは最近、100以上の1時間のオファーを購入しました。
ルールはルールのセットにまとめることができ、簡単にするために、我々は唯一のルールを議論します。
- 事実、等口座番号とログイン、IPおよび登録番号として本体と属性の決意即ち、上記のルール。
- インデックスのしきい値など、このような登録アカウントの重要なしきい値数などの重要なしきい値数を、着陸として裁判官によると、。
ルールは経験的に業務の専門家を記入するだけでなく、過去のデータマイニングに基づくデータアナリストが、黒の生産との攻防のルールは、失敗にリードを推測するので、そう常に動的に調整する必要がありますすることができます。
- 風データストリームのリアルタイム制御赤線により識別、同期呼制御コア風コールリンク。
- リアルタイム・データ・ストリームの近くにインデックスは、非同期ブルーライン識別、風のリアルタイム制御のための準備のインデックスデータ部によって書き込みます。
- データストリームのリアルタイム/オフライン分析近く、非同期空気制御システム解析の性能のためのデータを提供するために、緑の線識別によって書き込みます。
リアルタイムのリスク管理は、システムの中核である、システムが運用同期呼び出し、完全に対応するリスク管理の判断です。上記のルールは、多くの場合、人によって書かれ、動的に調整する必要があるので、私たちは離れてセクションとルール管理セクションを判断コントロールを巻くますされています。運用担当者による操作サービス管理の背景のためのルールは、関連する操作を実行するには:
- シーン管理は、イベントシーンをオフにすることができた後のシーンは、このようなアクティブシーンとして、リスク管理を実施するかどうかを決定します。
- ブラックリストとホワイトリスト、マニュアル/プログラムは、黒と白のリスト方式、直接ろ過を見つけました。
- ルール管理そのような単一の新しい周波数チェックなどのような新しいランディング判定のIPアドレスなどの追加、削除または修正を含め、管理ルール、、、。
- 閾値管理、そのような時間の数最後の登録アカウントのIPルールとして閾値の管理指標は、10以上とすることができず、1と10の閾値に属します。
完成した管理の背景、非常に明確にも判決の論理的規則の一部は、プレフィルター、ルールのために必要なデータが3つのリンクを決定するという事実が含まれます。
2.1.1プレフィルター
业务系统在特定事件(如注册、登陆、下单、参加活动等)被触发后同步调用风控系统,附带相关上下文,比如 IP 地址,事件标识等,规则判断部分会根据管理后台的配置决定是否进行判断,如果是,接着进行黑白名单过滤,都通过后进入下一个环节。
2.1.2 实时数据准备
在进行判断之前,系统必须要准备一些事实数据,比如:
- 注册场景,假如规则为单一 IP 最近 1 小时注册账号数不超过 10 个,那系统需要根据 IP 地址去 Redis/Hbase 找到该 IP 最近 1 小时注册账号的数目,比如 15;
- 登陆场景,假如规则为单一账号最近 3 分钟登陆次数不超过 5 次,那系统需要根据账号去 Redis/Hbase 找到该账号最近 3 分钟登陆的次数,比如 8;
Redis/Hbase 的数据产出我们会在第 2.2 节准实时数据流中进行介绍。
2.2.3 规则判断
在得到事实数据之后,系统会根据规则和阈值进行判断,然后返回结果,整个过程便结束了。整个过程逻辑上是清晰的,我们常说的规则引擎主要在这部分起作用,一般来说这个过程有两种实现方式:
- 借助成熟的规则引擎,比如 Drools,Drools 和 Java 环境结合的非常好,本身也非常完善,支持很多特性,不过使用比较繁琐,有较高门槛,可参考文章【1】;
- 基于 Groovy 等动态语言自己完成,这里不做赘述。可参考文章【2】;
这部分属于后台逻辑,为风控系统服务,准备事实数据。把数据准备与逻辑判断拆分,是出于系统的性能/可扩展性的角度考虑的。前边提到,做规则判断需要事实的相关指标,比如最近一小时登陆次数,最近一小时注册账号数等等,这些指标通常有一段时间跨度,是某种状态或聚合,很难在实时风控过程中根据原始数据进行计算,因为风控的规则引擎往往是无状态的,不会记录前面的结果。同时,这部分原始数据量很大,因为用户活动的原始数据都要传过来进行计算,所以这部分往往由一个流式大数据系统来完成。在这里我们选择 Flink,Flink 是当今流计算领域无可争议的 No.1,不管是性能还是功能,都能很好的完成这部分工作。
-
业务系统把埋点数据发送到 Kafka;
-
Flink 订阅 Kafka,完成原子粒度的聚合;
注:Flink 仅完成原子粒度的聚合是和规则的动态变更逻辑相关的。举例来说,在注册场景中,运营同学会根据效果一会要判断某 IP 最近 1 小时的注册账号数,一会要判断最近 3 小时的注册账号数,一会又要判断最近 5 小时的注册账号数……也就是说这个最近 N 小时的 N 是动态调整的。那 Flink 在计算时只应该计算 1 小时的账号数,在判断过程中根据规则来读取最近 3 个 1 小时还是 5 个 1 小时,然后聚合后进行判断。因为在 Flink 的运行机制中,作业提交后会持续运行,如果调整逻辑需要停止作业,修改代码,然后重启,相当麻烦;同时因为 Flink 中间状态的问题,重启还面临着中间状态能否复用的问题。所以假如直接由 Flink 完成 N 小时的聚合的话,每次 N 的变动都需要重复上面的操作,有时还需要追数据,非常繁琐。
- Flink 把汇总的指标结果写入 Redis 或 Hbase,供实时风控系统查询。两者问题都不大,根据场景选择即可。
通过把数据计算和逻辑判断拆分开来并引入 Flink,我们的风控系统可以应对极大的用户规模。前面的东西静态来看是一个完整的风控系统,但动态来看就有缺失了,这种缺失不体现在功能性上,而是体现在演进上。即如果从动态的角度来看一个风控系统的话,我们至少还需要两部分,一是衡量系统的整体效果,一是为系统提供规则/逻辑升级的依据。
- 判断规则是否多余,比如某规则从来没拦截过任何事件;
- 判断规则是否有漏洞,比如在举办某个促销活动或发放代金券后,福利被领完了,但没有达到预期效果;
- 发现全局规则,比如某人在电子产品的花费突然增长了 100 倍,单独来看是有问题的,但整体来看,可能很多人都出现了这个现象,原来是苹果发新品了……
- 识别某种行为的组合,单次行为是正常的,但组合是异常的,比如用户买菜刀是正常的,买车票是正常的,买绳子也是正常的,去加油站加油也是正常的,但短时间内同时做这些事情就不是正常的。
- 群体识别,比如通过图分析技术,发现某个群体,然后给给这个群体的所有账号都打上群体标签,防止出现那种每个账号表现都正常,但整个群体却在集中薅羊毛的情况。
这便是分析系统的角色定位,在他的工作中有部分是确定性的,也有部分是探索性的,为了完成这种工作,该系统需要尽可能多的数据支持,如:
- 业务系统的数据,业务的埋点数据,记录详细的用户、交易或活动数据;
- 风控拦截数据,风控系统的埋点数据,比如某个用户在具有某些特征的状态下因为某条规则而被拦截,这条拦截本身就是一个事件数据;
这是一个典型的大数据分析场景,架构也比较灵活,我仅仅给出一种建议的方式。
相对来说这个系统是最开放的,既有固定的指标分析,也可以使用机器学习/数据分析技术发现更多新的规则或模式,限于篇幅,这里就不详细展开了。http://archive.keyllo.com/L-编程/drools-从Drools规则引擎到风控反洗钱系统v0.3.2.pdfhttps://www.jianshu.com/p/d6f45f91bedehttps://jinfei21.github.io/2018/09/29/基于规则的风控系统/https://sq.163yun.com/blog/article/183314611296591872https://sq.163yun.com/blog/article/213006222321659904https://github.com/sunpeak/riskcontrol
Apache Flink 及大数据领域盛会 Flink Forward Asia 2019 将于 11月28-30日在北京国家会议中心举办,大会议程已上线,点击「阅读原文」可了解大会议程详情。
(点击图片可查看 Flink Forward Asia 2019 详情)
从滴滴的Flink CEP引擎说起

CEP业务场景
复杂事件处理(Complex Event Process,简称CEP)用来检测无尽数据流中的复杂模 式,拥有从不同的数据行中辨识查找模式的能力。模式匹配是复杂事件处理的一个强 大援助。 例子包括受一系列事件驱动的各种业务流程,例如在安全应用中侦测异常行为;在金 融应用中查找价格、交易量和其他行为的模式。其他常见的用途如欺诈检测应用和传 感器数据的分析等。
说了这么多可能还是觉得比较抽象,那么我们可以看看这次滴滴分享的FlinkCEP在滴滴中的业务场景。



吐槽时刻:
虽然,业务场景ppt写的很好,但是最近几次顺风车事故,给大家留下了糟糕的印象。大数据没用起来,cep其实应该也可以用在顺风车安全检测上吧。
Flink CEP
Flink的CEP是基于Flink Runtime构建的实时数据规则引擎,擅长解决跨事件的匹配问题。
可以看看,滴滴的屁屁踢上给出的两个demo
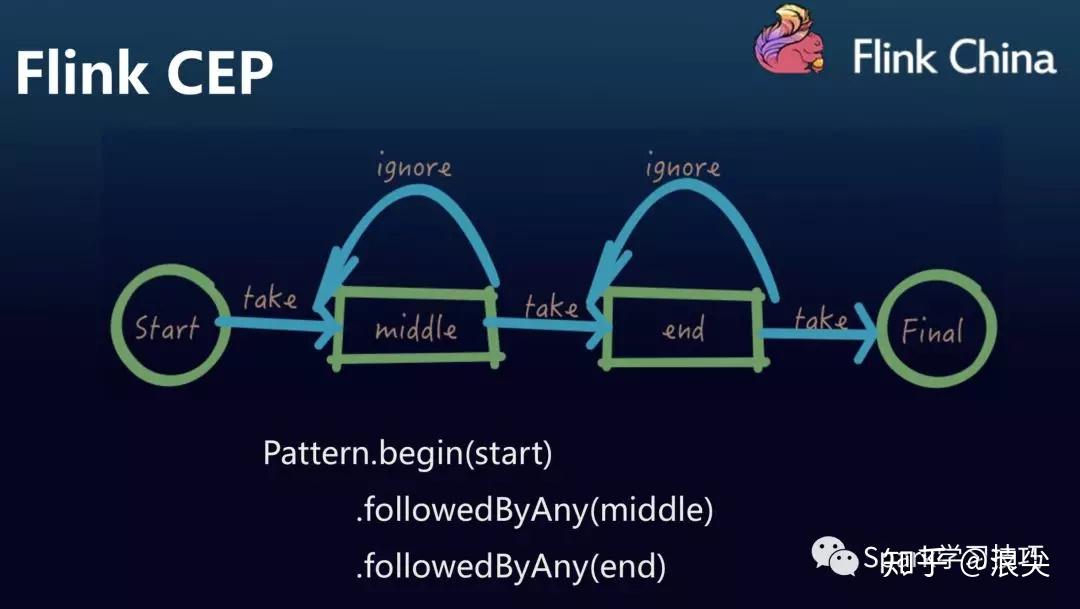
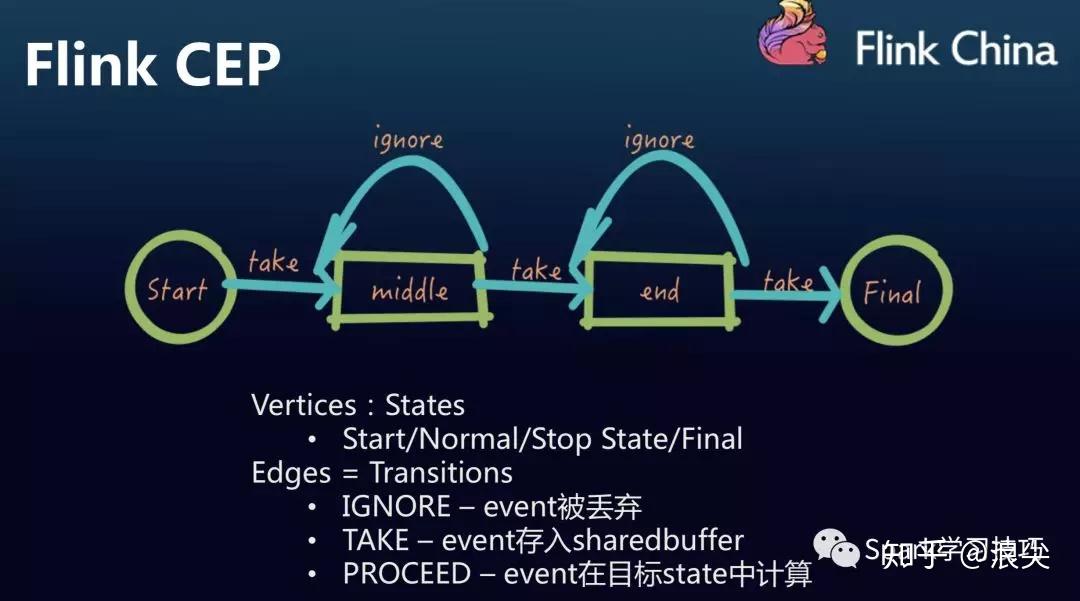
Flink CEP的特点

动态规则
其实,对于实时领域的规则引擎,我们不想每次修改都要打包编码,只希望简单修改一下规则就让它能执行。
当然,最好规则是sql 的形式,运营人员直接参与规则编写而不是频繁提需求,很麻烦。。。。此处,省略万字。。
要知道flink CEP官网给出的API也还是很丰富的,虽然滴滴这比也给出了他们完善的内容。

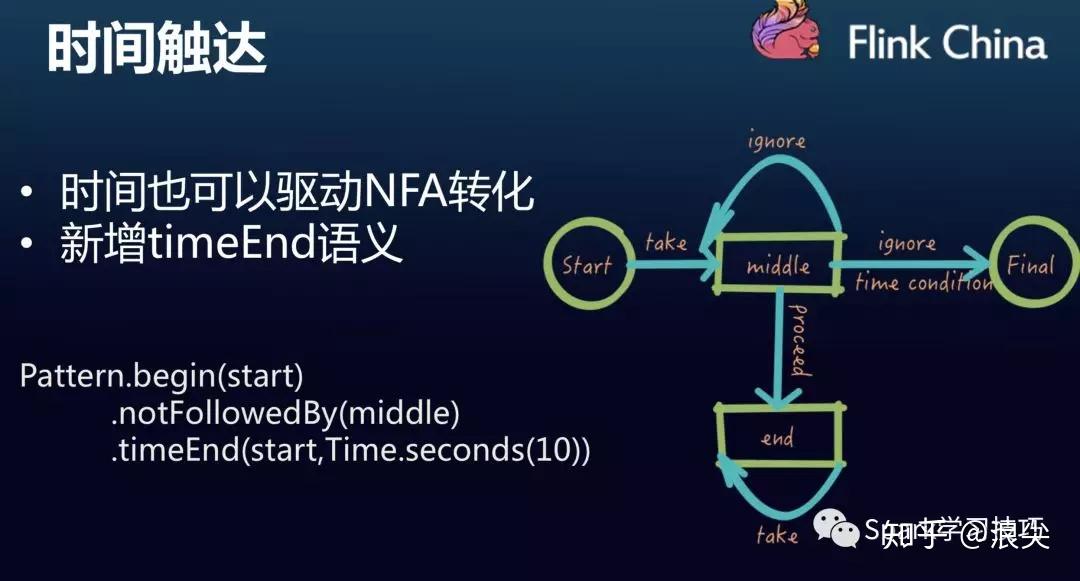
flink官方的CEP文章,浪尖及浪尖组织的flink小团队,已经翻译过了。链接如下:
https://github.com/crestofwave1/oneFlink/blob/master/doc/CEP/FlinkCEPOfficeWeb.md
那么,为了实现动态规则编写,滴滴的架构如下:
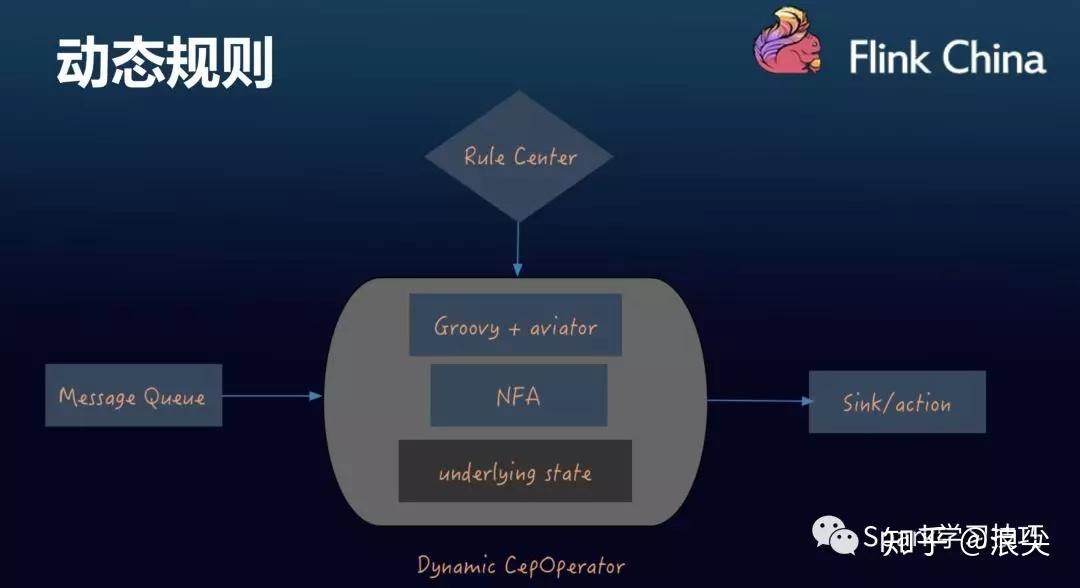
具体的规则实现如下:

可以看到,其规则还是要编码成java代码,然后再用groovy动态编译解析,不知道效率如何。。。
对于规则引擎,当然很多人想到的是drools,这个跟flink结合也很简单,但是效率不怎么苟同。
Flink CEP的SQL实现
熟悉flink的小伙伴肯定都知道Flink的SQL引擎是基于Calcite来实现的。那么细心的小伙伴,在calcite官网可以发现,calcite有个关键字MATCH_RECOGNIZE。可以在这个网页搜索,找到MATCH_RECOGNIZE关键字使用。
http://calcite.apache.org/docs/reference.html
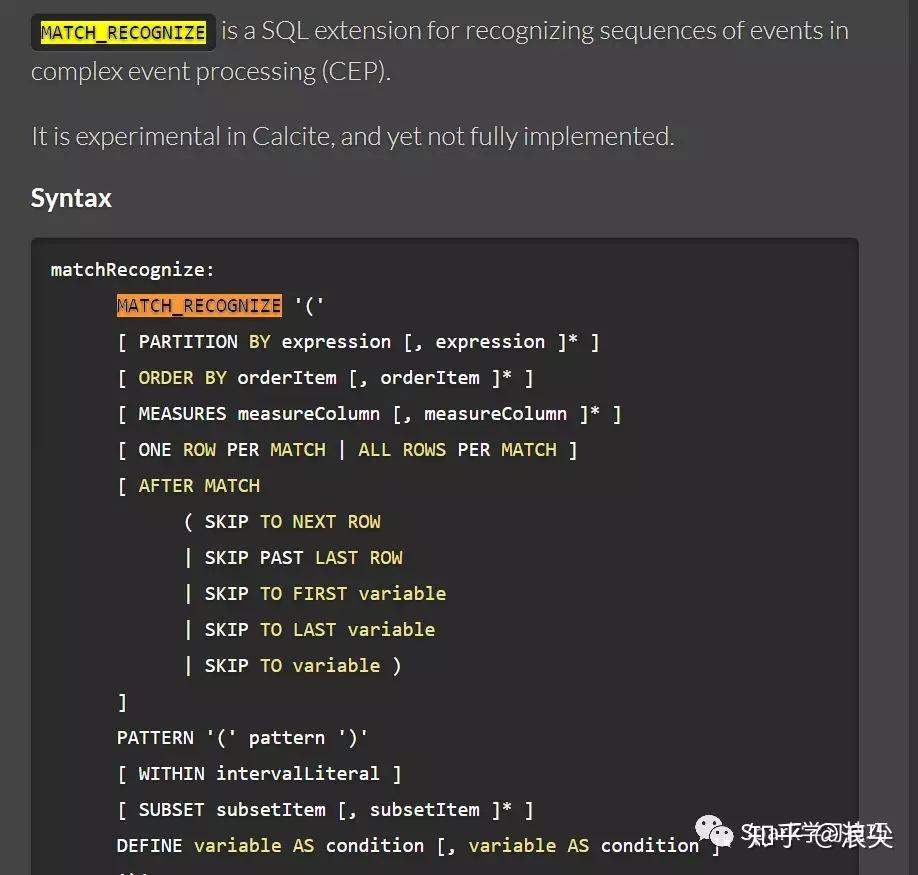
那么这时候可能会兴冲冲写个demo。
final String sql = "select frequency,word,timestamp1 "
+ " from wc match_recognize "
+ " ("
+ " order by timestamp1 "
+ " measures A.timestamp1 as timestamp1 ,"
+ " A.word as word ,"
+ " A.frequency as frequency "
+ " ONE ROW PER MATCH "
+ " pattern (A B) "
+ " within interval '5' second "
+ " define "
+ " A AS A.word = 'bob' , "
+ " B AS B.word = 'kaka' "
+ " ) mr";很扫兴的它报错了:
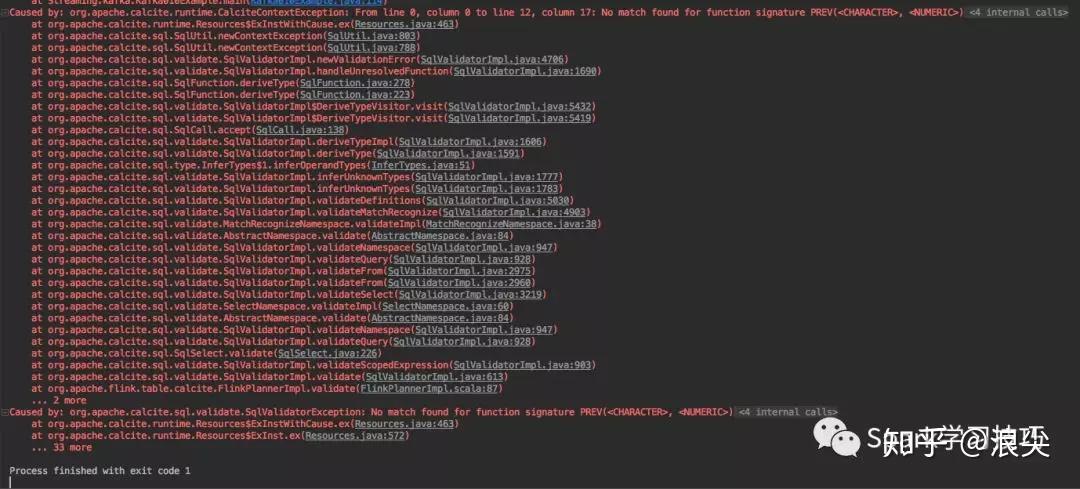
那么问题来了,calcite支持而flink不支持,为啥?
赶紧发了个issue,然后迅速得到官方回复:

但是,翻翻阿里的blink使用手册和华为的flink使用手册发现两者都支持。
好吧。其实,很不服气,周末,除了健身就是加班。
波折一番,解决了,需要修改flink-table相关的内容,执行计划,coden等。
最终,实现了。
