勧告(遭遇ピット):
-
彼らは、オペレーティング・システムを使用している場合はLinuxのですが、私はのDeepinシステムでした、結果として2台の仮想マシンをインストールするHadoopマスター・ノードの起動時に、デフォルトのユーザー名は、スレーブマスターマシンであるため、ユーザー名が、起動しないにつながる、構成されていませんユーザ名。そのため、3台のマシン、ユーザ名が同じであることを確実にするために!!
-
ウィンドウでのデバッグのMapReduceプログラムは、winutilsをインストールする必要がほとんどないだろう。
-
(環境、構成を含む)完全な勧告をビルドし、テーブルのSCPのクローンを作成またはコピーします。
-
あなたはすべて一緒でも飼育係やカフカをしたい場合は、それも直接設定することができます。その後、SCPパス、かなりの面積を使用し、それをインストールしないでください。
-
クローニングは、ホスト名の変更が終了しました!
-
少しラフ全体のプロセスは、出会いのいくつかの詳細は、レコードを忘れてしまいました。ようこそアドバイス、問題がある場合、通知してください、私は速やかに訂正します。
仮想マシンのインストール
-
-
仮想マシンにファイルを転送します。私はすぐにscpコマンドのパスを使用しています。ユーザーは、Windowsの下で、xshell SFTPをお勧めします。
-
デフォルトNAT、CentOSの最小インストールに仮想マシンのネットワーク構成
構成:
-
ファイアウォールをオフにします
ステータスfirewalld systemctl $ #ビューファイアウォール状態 の$ systemctl停止firewalldの #は、一時的にファイアウォールを停止 $のsystemctl無効firewalldの #は、ファイアウォールの起動を禁止します
-
閉じるSELinuxの
セキュリティ強化のLinux(セキュリティ強化Linuxは)SELinuxの言及、それはLinuxカーネルモジュールで、Linuxはセキュリティサブシステムです。
Vimの$の/ etc / SELinuxは/ コンフィグ #がSELINUX =執行するには、SELinuxが無効=変更されます
-
NTP時刻同期サービスをインストールします。
yumをインストール- Y-NTP 位カイからのブートを設定し ntpd.serviceを有効systemctl #は起動 ntpdの有効systemctl systemctlステータスのntpd #を有効にするかどうかをチェックします
:原因にあります開始されない場合がありchronyd 紛争:
chronyd systemctlを無効にする :NTPを開始、オフのことができます。
-
ホスト名を変更し、静的IPを設定します
(ホスト名を変更するためにいくつかの変更を行う必要があり、クローニング、後は、何をすることができますを変更するには、ip)
ステップ1:修正/ etc / sysconfig / network-scriptsに/のifcfg-xxxのファイル
メインは、次のパラメータを変更します。
BOOTPROTO = " 静的" ONBOOT = " はい" IPADDR = " 172.16.125.128 " NETMASK = " 255.255.255.0 " GATEWAY = " 172.16.125.2 "
第二部:/ etc / sysconfig / networkファイルの内容を変更します。
同上
#アナコンダによって作成 = 172.16.125.2 GATEWAY DNS = 172.16.125.2
第三ステップ:ネットワークを再起動します
サービスネットワークの再起動
-
SSHの構成
マスターシークレットは、無料のスレーブノードにログオンすることができます
$ sshを-keygenは-t rsaの
3つの以下のファイルを開きますの〜/ .ssh
-rw-rを- 。r--の1つのルートルート392 9越21時05 authorized_keysに26個の #認定キー 。-rw ------- 1ルートルート1679 20時57 id_rsaと9越26 #プライベート -rw-R - r--の1ルートルート393 26 9越20時57 id_rsa.pub #公衆
上のマスターで公衆3台のマシンのauthorized_keys年に。コマンド:$ sudoの猫id_rsa.pub >> authorized_keysに
他のLinux〜/ .sshディレクトリに配置されたマスターのauthorized_keys
$ sudoのSCPのauthorized_keys [email protected]:の〜/ .ssh
authorized_keysには、権限、コマンドを変更します。
$ chmodの644のauthorized_keysに
テストが成功したかどうか
ssh host2が直接システムに、もう一度パスワードなしでユーザー名とパスワードを入力し、[終了し、SSH host2という。これは成功を意味します。
ログインはsshの時がある場合:
ホストの信頼「hadoop2(192.168.238.130)が」できる」tを確立すること
/ etc / ssh / ssh_configの設定ファイルを変更配置され、以下の2行を追加する必要があります。
StrictHostKeyChecking何 UserKnownHostsFileを/ dev / nullありません -
最後に:インストール設定JDK、Hadoopの
コアstie.xml
< 設定> < プロパティ> < 名前> fs.defaultFS </ 名前> <! - デフォルトのファイルシステムの場所- > < 値> HDFS://マスター:9000 / </ 値> </ プロパティ> < プロパティ> < 名前> hadoop.tmp.dir </ 名前を> <! - Hadoopの作業ディレクトリ、名前ノード、データノードデータ- > < 値> /ホーム/ WHR /ベンチ/ Hadoopの/データ/ </ 値> </プロパティ> </ 設定>
hdfs.site.xml
< 設定> < プロパティ> < 名前> dfs.replication </ 名前> <! - コピー数- > < 値> 2 </ 値> </ プロパティ> < プロパティ> <! - 二子ノードの位置1つの設定- > < 名前> dfs.namenode.secondary.httpアドレス</ 名前> < 値>スレーブ1:50090 </ 値> </ プロパティ> </ 設定>
mapreduce.site.xml
< 設定> < プロパティ> <! - 糸と指定MapReduceの実行中のクラスタを達成するためには、分散- > < 名前> mapreduce.framework.name </ 名前> < 値>糸</ 値> </ プロパティ> < / 設定>
yarn.site.xml
< 設定> < プロパティ> < 名前> yarn.resourcemanager.hostname </ 名前> < 値> hadoop1 </ 値> </ プロパティ> < プロパティ> < 名前> yarn.nodemanager.aux-サービス</ 名前> < 値> mapreduce_shuffle </ 値> </ プロパティ> </ 設定>
スレーブの設定ファイル
スレーブ1 スレーブ2マスターズ・コンフィギュレーション・ファイル(CDHのバージョンがあれば、私が使用して、このファイルを持っていません)
主人
クローン
-
VMwareは何も言うことをクローニングしません
-
クローニングは、/ etc / hostnameファイル内のホスト名を変更し、完了です!
-
/ etc / hostsファイル:3台のマシンにIPアドレスマッピングを追加します。
クラスタを起動
- (私がクローンをフォーマットした後)ノードをフォーマット
Hadoopの名前ノード$ - 書式 #が遂に登場、その成功は、最終ステータスコードを見ることができます0で 保存ディレクトリを/ tmp / Hadoopのルート/ DFS /名前が正常にフォーマットされています。
-
開始:ディレクトリへsbinに(ディレクトリが最初sbinに環境変数に設定することができます。ディレクトリにスイッチする必要はありません)
[スタート] - dfs.shが
開始 -yarn.sh
-
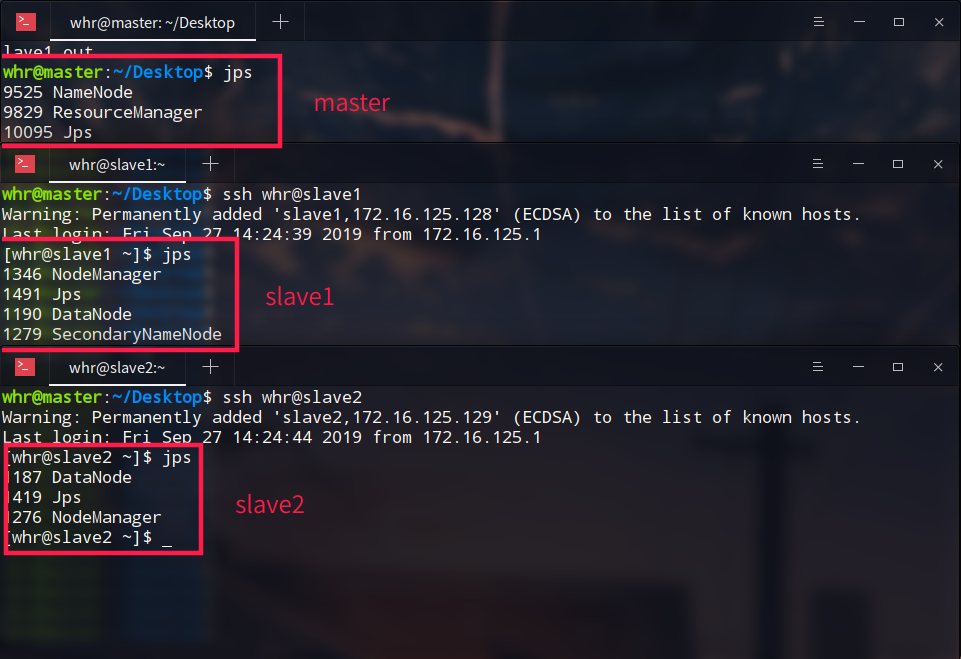
jpsコマンド
すべての起動が完了すると、スレーブマスターにログインする結果:( SSHを見ます)
あなたは、名前ノードのマスター、2つのデータノード、SecondaryNameNodeが起動している見ることができます
ResourceManagerの下糸、ノードマネージャで2つのスレーブも、完了するまでに開始します
4.これは、ブラウザのポート50070を介してアクセスすることができます
あなたは、MapReduceのサンプルプログラムについて実行することができます。
$ HadoopのジャーのHadoopのMapReduce--例-2.6.0-cdh5.15.2.jarパイ5
Hadoopの設定ファイル
参照プロフィール
https://www.cnblogs.com/xhy-shine/p/10530729.html