まず、アバランシェ効果
単場合のマイクロサービスアーキテクチャでは、サービスとサービスとの間の各呼び出し、ジョブを完了するためには、マイクロ依存コールサービスモジュールの複数が、その理由ネットワークまたは独自の理由かもしれないので、このサービスは、100%の利用可能な保証するものではありませんサービスの問題、多数のリクエスト、サーブレットコンテナのスレッドリソースの流入は、サービスの麻痺が生じ、完成消費された場合、サービスは、この時点で、スレッドがブロックされているだろう呼び出す;プラスサービスとサービス間の依存関係、麻痺これは、「膣出血」エフェクトサービス障害で全体のマイクロサービスシステム、のために重大な結果を引き起こし、急速に広がります。
サービスアバランシェ効果の形成段階
1、サービスプロバイダは使用できません。
- ハードウェア障害。ハードウェアの損傷は、サーバホストがダウンしているネットワークハードウェアの障害、またはアクセスできないサービスプロバイダの原因となります。
- プログラムのバグ
- キャッシュの内訳。一般的に、すべてのキャッシュがクリアされるキャッシュアプリケーションの再起動、およびキャッシュの無効化の多数の短い時間で起こります。キャッシュミスの多くは、要求は、サービスが利用できない原因と、オーバーロードされたサービスプロバイダで、その結果、バックエンドをご覧ください。
- ユーザー要求の数が多いです
2、再試行の流量を増加
- ユーザーが再試行します
- コードのロジックを再試行
3、サービスコールは使用できません。
- 同期はリソースの枯渇によって引き起こされるのを待ちます。同期呼び出し、大量のシステムリソースは、スレッドを待っているとき。
第二に、サービス応答雪崩
サービス雪崩のためのさまざまな理由により、異なる応答を使用することができます。
1、フロー制御
- 制限ゲートウェイ
- 、ロード時間を待っているユーザーの忍耐力を向上させるために、アニメーションを使用した1:のような、ユーザーの操作を制限します。2.メカニズムを待つことを余儀なく追加するボタンを提出してください。
- 閉じる再試行
図2に示すように、改良されたキャッシュモード
- キャッシュのプリロード
- 変更同期、非同期リフレッシュ
図3に示すように、自動サービス拡張
- AWS的自動スケーリング
4、サービス呼び出し側のダウングレード
- リソースの分離。主にサービススレッドプールのアイソレーションを呼び出すため。
- サービスの分類に頼ります。事業によっては、依存サービスが強く、弱い依存性依存性に分類され、現在のサービスの強い依存性は、弱いが利用できないサービスに依存しません事業の停止につながる利用できません。
- 利用できないサービスはすぐに失敗を呼び出します。通常によってタイムアウトメカニズム、ヒューズの後とヒューズダウングレード方法を達成します。
第三に、予防サービスの利用は、アバランシェHystrix
設計原理3.1、Hystrixは、次のとおりです。
- リソースの分離(1つのバスケットにすべての卵を入れないでください)
- ヒューズ(時間で停止)
- コマンドモード
リソースの分離
非常にサービス指向のシステムでは、ビジネスロジックは、多くの場合、例えば、下の図は、左、複数のサービスモジュールに依存する必要があり、ビジネスの観点製品の詳細は製品の説明、価格のお問い合わせに依存する必要があり、製品には、3つのサービスモジュールを見直し、3つの依存サービスを呼び出します。シェアリスティングサービススレッドプール1つのモジュールが利用できない場合、すべてのスレッドプールのスレッドが雪崩のサービスを引き起こし、なぜなら応答を待つのでブロックされます。
こうして全体のサービス雪崩を避け、別のスレッドプールのリソースの分離を割り当てることによって各依存サービスのためHystrix。下の右図、たとえサービスモジュールエラーは、唯一のコール他の依存サービスに影響を与えずに、待機状態でそれに割り当てられたスレッドにつながります。

そうすることのコストは、複数のスレッドプールのパフォーマンス・オーバーヘッドを維持する必要性をもたらすことです。
ヒューズ
ヒューズのヒューズパターンを開閉変換を定義します。
サービスモジュールの健康=失敗したリクエスト/総要求の数を定義します。
ヒューズは、私たちが医療サービスのためのしきい値を設定する必要があり、動作します:
- ヒューズスイッチが閉じられ、その要求を直接ヒューズを介して裏面に達することができます。
- 保健サービスの現在の状態が設定されたしきい値よりも高い場合、スイッチは閉じたまま、開いた状態にそれ以外の場合はスイッチ。
- ヒューズスイッチが開いている場合、要求はヒューズ、直接戻り不良を介して禁止されています。
- スイッチは、時間ヒューズ(ヒューズ時間窓)の期間に開かれている場合は、自動的に半開きの状態になり、その要求を渡すことができ、呼び出しが成功した要求は、履歴書・オフを融合し、要求が失敗した場合、開いたままになります。
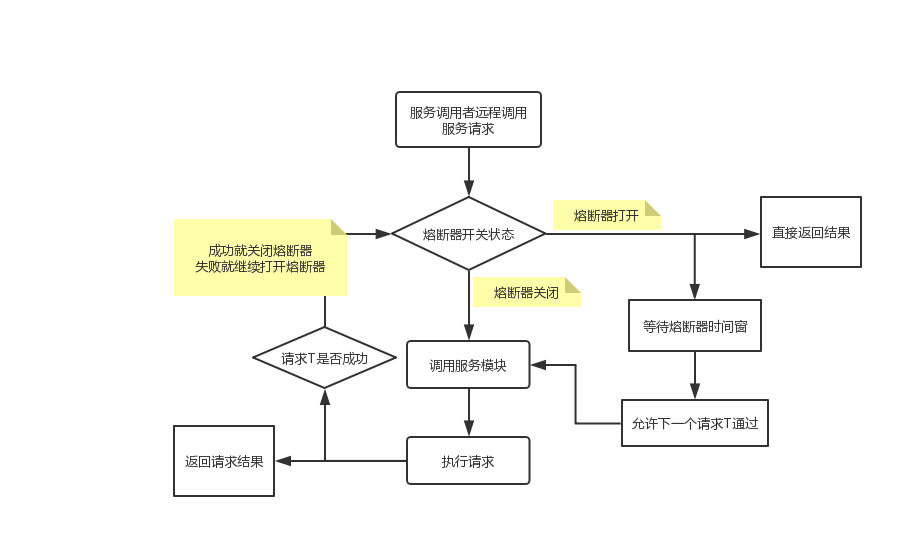
ヒューズは、呼び出し側のサービス時間中にサービスコール例外を確保同期のために待機しているクライアントの数が多いと、無効な多数の要求が、システムのスループットに影響を与える原因を避けるためにすぐに結果を返すように切り替え、ヒューズは自動的に一定期間後に実行するための要求を検出することができますサービスコールを復元したかもしれない結果、。
コマンドモード
Hystrixは、特定のサービス呼び出しロジック(実行方法)をラップする(HystrixCommandクラスから継承)コマンドモードを使用して、サービスコールは、コマンドモードで失敗した後降格ロジック(getFallback)を追加するだけでなく、中にコンストラクタコマンドで定義することができます現在のスレッドプールのパラメータおよびヒューズ。
3.2、Hystrix応答
- それぞれの依存性は、単離全コール依存性またはパッケージHystrixCommand HystrixObservableCommand
- 時間のかかる呼び出ししきい値を設定するためには、閾値を超えるへの依存は直接タイムアウト判定されます
- 对每个依赖维护一个连接池,如果连接池满直接拒绝访问
- 评估服务模块的健康状态,超过指定的阈值的话直接熔断处理,对依赖的请求访问直接fallback处理(由开发者自己实现)
- 熔断生效后,时间窗后放出一个请求探测,决定是否要恢复服务
- 近乎实时生效
3.3、Hystrix的内部处理逻辑

- 构建Hystrix的Command对象, 调用执行方法.
- Hystrix检查当前服务的熔断器开关是否开启, 若开启, 则执行降级服务getFallback方法.
- 若熔断器开关关闭, 则Hystrix检查当前服务的线程池是否能接收新的请求, 若超过线程池已满, 则执行降级服务getFallback方法.
- 若线程池接受请求, 则Hystrix开始执行服务调用具体逻辑run方法.
- 若服务执行失败, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务健康状况.
- 若服务执行超时, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务健康状况.
- 若服务执行成功, 返回正常结果.
- 若服务降级方法getFallback执行成功, 则返回降级结果.
- 若服务降级方法getFallback执行失败, 则抛出异常