この記事では、メインメモリ管理システムのスパークを分析します。
前回の記事では 、スパークソースコード解析の14 -放送はどのように達成することですか?あまりにも多くの分析をしない関連するストレージの内容は、次の計画には、Sparkメモリメカニズムを分析して、メモリに格納し、最終的にディスクストレージを分析します。この記事では、メインメモリ管理メカニズムを分析します。
全体的に説明
パッケージorg.apache.spark.memoryスパークコアモジュール内のメモリ管理に関連するクラスをスパーク。
次のようにこのパッケージのドキュメントを説明し、例示されています:
このパッケージには、Sparkのメモリ管理システムを実装しています。このシステムは、2つの主要コンポーネント、JVM全体のメモリマネージャごとのタスクマネージャで構成されています
- org.apache.spark.memory.MemoryManagerは、JVM内でスパークの全体的なメモリ使用量を管理します。このコンポーネントは、タスクを横切って利用可能なメモリを分割すると、ストレージ(メモリ使用キャッシングおよびデータ転送)と実行(例えば、シャッフルなどの計算、結合、ソート、および集計によって使用されるメモリ)との間でメモリを割り当てるためのポリシーを実装します。
- org.apache.spark.memory.TaskMemoryManagerは、個々のタスクによって割り当てられたメモリを管理します。タスクはTaskMemoryManagerと相互作用して、直接JVM全体MemoryManagerと対話することはありません。内部的には、これらの構成要素のそれぞれは、メモリ簿記のための追加的な抽象化を持っています:
- org.apache.spark.memory.MemoryConsumersはTaskMemoryManagerのクライアントであり、タスク内の個々の演算子およびデータ構造に対応します。TaskMemoryManagerは、メモリが不足したときにこぼれトリガーするために消費者にMemoryConsumersと課題コールバックからのメモリ割り当て要求を受信します。
- org.apache.spark.memory.MemoryPoolsストレージと実行の間のメモリの分割を追跡するためにMemoryManagerによって使用簿記抽象化です。
メモリ管理およびメモリ管理、単一のタスクのJVMの範囲:そのメモリ管理は、主に二つの成分を含みます。
- JVMでMemoryManager管理スパーク全体のメモリ使用量。コンポーネントは、使用可能なメモリを横切るタスクの分割を実装し、(例えば、シャッフル、連結、ソートおよび集約として、メモリを使用して計算された)メモリ(キャッシュメモリの使用とデータ送信)にとの間でメモリ割り当てポリシーを実行します。
- TaskMemoryManagerは、メモリから割り当てられたさまざまなタスクを管理します。TaskMemoryManagerタスクと相互作用して、JVM全体MemoryManagerと直接対話することはありません。
TaskMemoryManager内では、各コンポーネントは、メモリ使用量を記録するための追加のメモリーブックを持っています:
- MemoryConsumersは、各オペレータに対応するTaskMemoryManagerクライアントタスク、およびデータ構造です。TaskMemoryManagerメモリ割り当て要求がMemoryConsumersから受信され、そしてそれは、低メモリ状態でオーバーフローをトリガするために、コールバック消費者を開始します。
- メモリプールはMemoryManagerは、分割されたメモリ簿記抽象的に格納され、実行の間を追跡するために使用されます。
図:
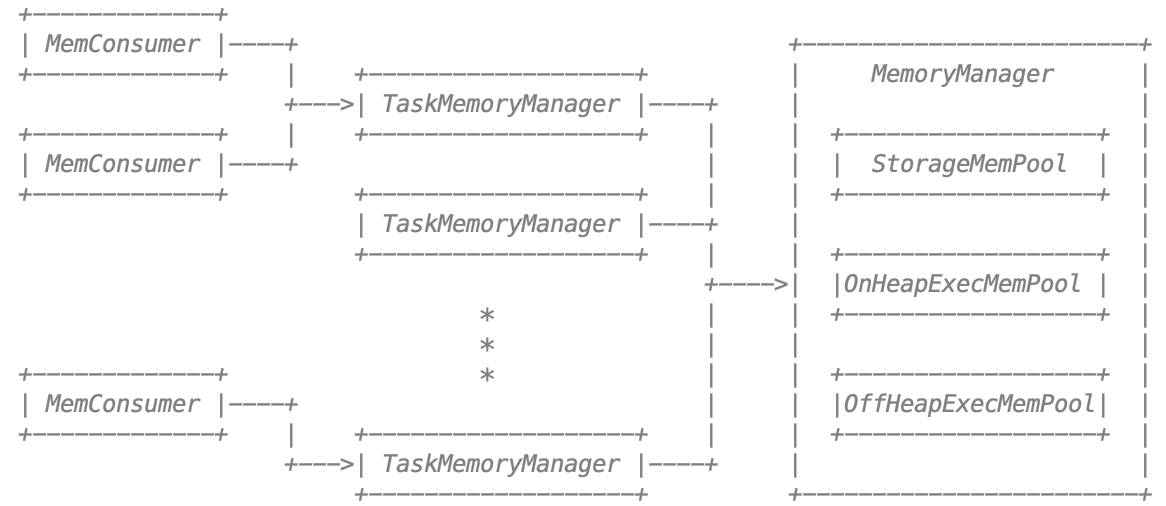
MemoryManager実現の二種類:
彼らは、メモリ・プールのサイズを処理する方法が異なりorg.apache.spark.memory.MemoryManagerの2つの実装があります:
- org.apache.spark.memory.UnifiedMemoryManager、スパーク1.6+でのデフォルトは、ストレージ間のソフトな境界を強制しますそして一方の領域にメモリの要求を許可する実行メモリは、他からメモリを借りて満たされます。
- org.apache.spark.memory.StaticMemoryManager静的スパークのメモリを分割し、互いからメモリを借りからストレージと実行を防止することによって記憶および実行メモリとの間の硬質の境界を強制します。このモードは、レガシー互換性のためにのみ保持されます。
org.apache.spark.memory.MemoryManagerが2で実装され、彼らが扱うメモリプールサイズの点で異なります。
- org.apache.spark.memory.UnifiedMemoryManager、メモリと実行用メモリの記憶の間の境界を強制1.6+スパークのデフォルト値は、一つの領域内の要求を満たすために、メモリの別のメモリ領域から借りることができます。
- スタティックメモリパーティションをorg.apache.spark.memory.StaticMemoryManagerスパーク、強制的にハードのメモリとストレージメモリと実行の間の境界は保存され、他から借りたメモリを防ぐために実行されます。のみと互換性のために、この伝統的なパターンを維持します。
ファーストクラス図独自の絵画に、関連するクラス間の関係をより直接的に理解があります:
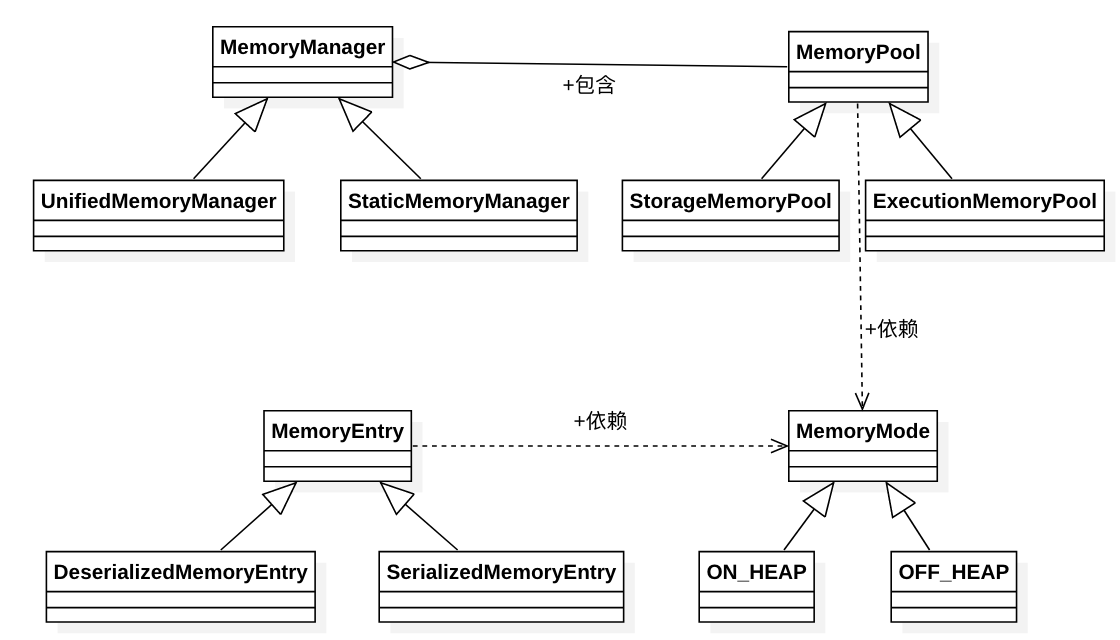
さんが関わったクラスの1つの記述によっていずれかを実行してみましょう。
MemoryMode
メモリモード:内側と外側の分割されたヒープメモリヒープメモリ、memorymodeは、本質的に、ON_HEAP OFF_HEAPはmemorymodeおよびサブクラスであり、列挙型です。
メモリプール
ドキュメント次のように:
メモリの調整可能なサイズの領域のために簿記を管理します。このクラスは、MemoryManagerの内部にあります。
それは簿記の仕事かなり大きなメモリ領域を管理する責任があること。理解することができ、それは融資リターンの記憶を記録するための主に担当し、会計の責任スチュワードで、メモリの宝庫です。このクラスは、MempryManagerのために特別に設計されています。
メモリを占め、実際には、本質的に、それはコア機能スパークメモリ管理ではなく、非常に重要な、それは方法がMemoryManagerに呼び出されるコアです。
このクラスを理解し、そのサブクラスをよりよく理解されています。会計家政婦は、二つの、それぞれStorageMemoryPool及びExecutionMemoryPoolに実装します。
StorageMemoryPool
文書は説明します:
記憶(キャッシュ)するために使用されるメモリの調整可能なサイズのプールを管理するための簿記を行います。
端的に言えば、それは責任ストアまたはキャッシュメモリ領域会計に専用されています。
そのクラス構造次のように:
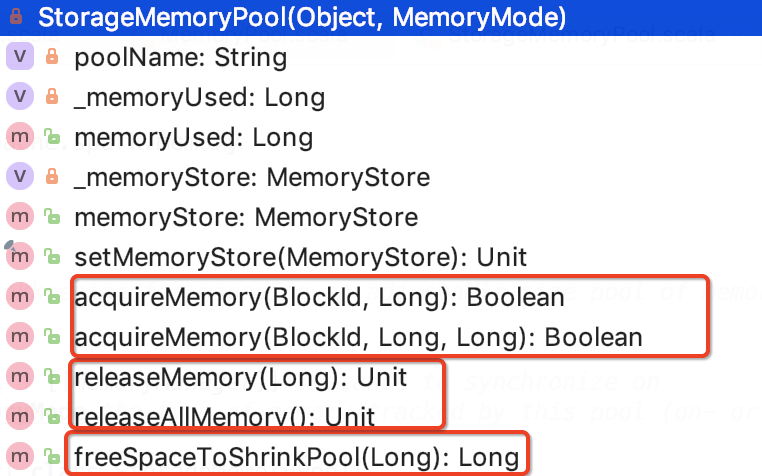
3つの方法があります。
1. acquireMemory:指定されたブロックへのメモリのNバイトを得るには、必要であれば、即ち、メモリが十分ではない、他のメモリから追い出されてもよいです。ソースは以下のとおりです。

図ロジックは、以下の基準分析MemoryStore標識。
2. releaseMemory:释放内存。源码如下:
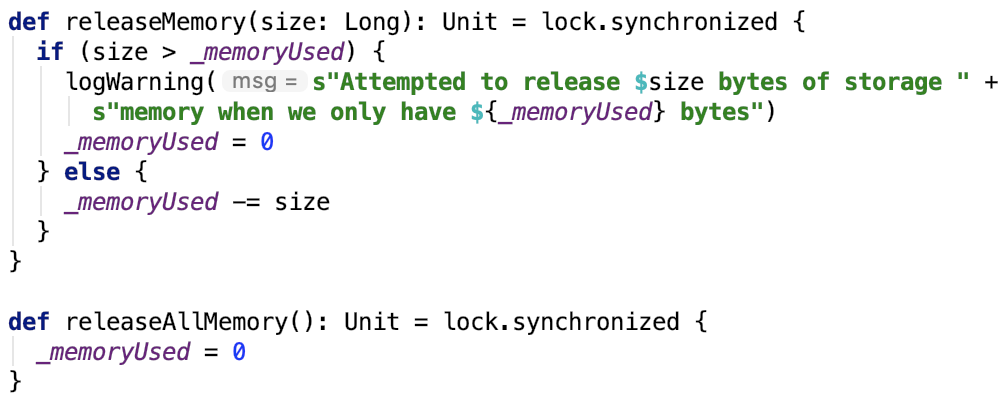
很简单,就只是在统计值_memoryUsed 上面做减法。
3. freeSpaceToShrinkPool:可用空间通过`spaceToFree`字节缩小此存储内存池的大小。源码如下:
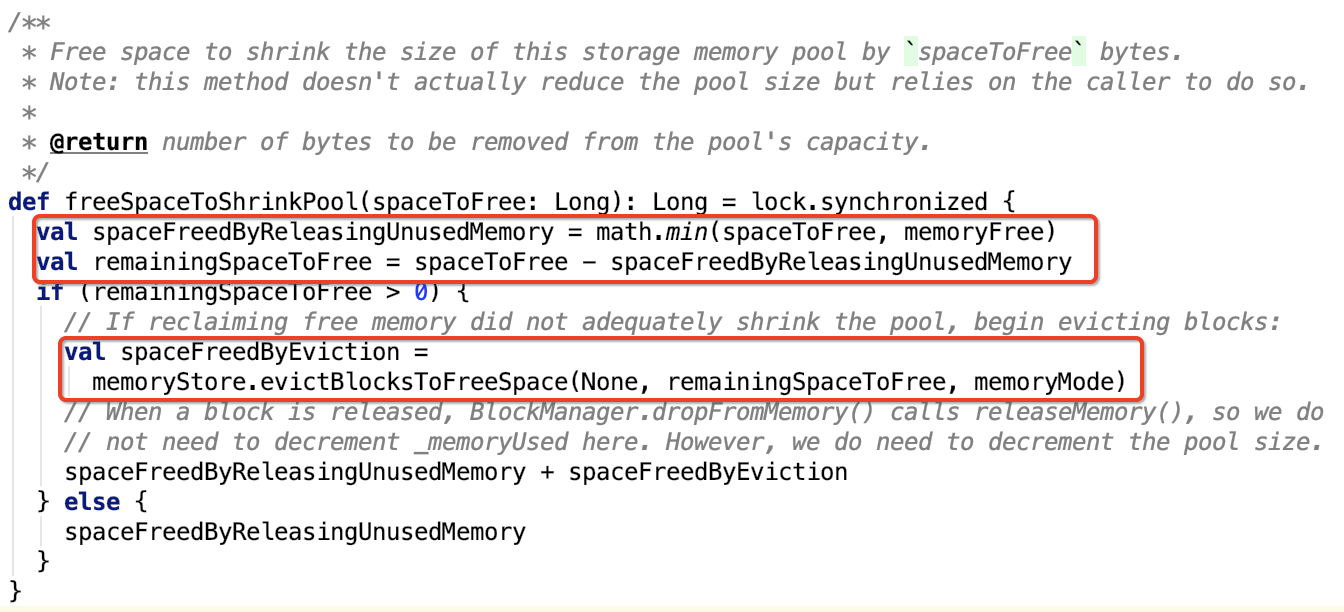
简单地可以看出,这个方法是在收缩存储内存池之前调用的,因为这个方法返回值是要收缩的值。
收缩存储内存池是为了扩大执行内存池,即这个方法是在收缩存储内存,扩大执行内存时用的,这个方法只是为了缩小存储内存池作准备的,并没有真正的缩小存储内存池。
实现思路,首先先计算需要驱逐的内存大小,如果需要驱逐内存,则跟 acquireMemory 方法类似,调用MemoryStore 的 evictBlocksToFreeSpace方法,否则直接返回。
总结:这个类是给存储内存池记账的,也负责不够时或内存池不满足缩小条件时,通知MemoryStore驱逐内存。
ExecutionMemoryPool
文档解释:
Implements policies and bookkeeping for sharing an adjustable-sized pool of memory between tasks.
Tries to ensure that each task gets a reasonable share of memory,
instead of some task ramping up to a large amount first and then causing others to spill to disk repeatedly.
If there are N tasks, it ensures that each task can acquire at least 1 / 2N of the memory before it has to spill,
and at most 1 / N. Because N varies dynamically, we keep track of the set of active tasks and redo the calculations
of 1 / 2N and 1 / N in waiting tasks whenever this set changes. This is all done by synchronizing access to mutable
state and using wait() and notifyAll() to signal changes to callers. Prior to Spark 1.6, this arbitration of memory
across tasks was performed by the ShuffleMemoryManager.
实现策略和簿记,以便在任务之间共享可调大小的内存池。 尝试确保每个任务获得合理的内存份额,而不是首先增加大量任务然后导致其他任务重复溢出到磁盘。
如果有N个任务,它确保每个任务在溢出之前至少可以获取1 / 2N的内存,最多1 / N.
由于N动态变化,我们会跟踪活动任务的集合并在每当任务集合改变时重做等待任务中的1 / 2N和1 / N的计算。
这一切都是通过同步对可变状态的访问并使用 wait() 和 notifyAll() 来通知对调用者的更改来完成的。 在Spark 1.6之前,跨任务的内存仲裁由ShuffleMemoryManager执行。

memoryForTask声明如下:
1 @GuardedBy("lock") 2 private val memoryForTask = new mutable.HashMap[Long, Long]()
其中,key 指的是 taskAttemptId, value 是内存使用情况(以byte计算)。它用来记录每一个任务内存使用情况。
它也有三类方法:
1. 获取总的或每一个任务的内存使用大小,源码如下:

memoryForTask 记录了每一个task使用的内存大小。
2. 给一个任务分配内存,源码如下:
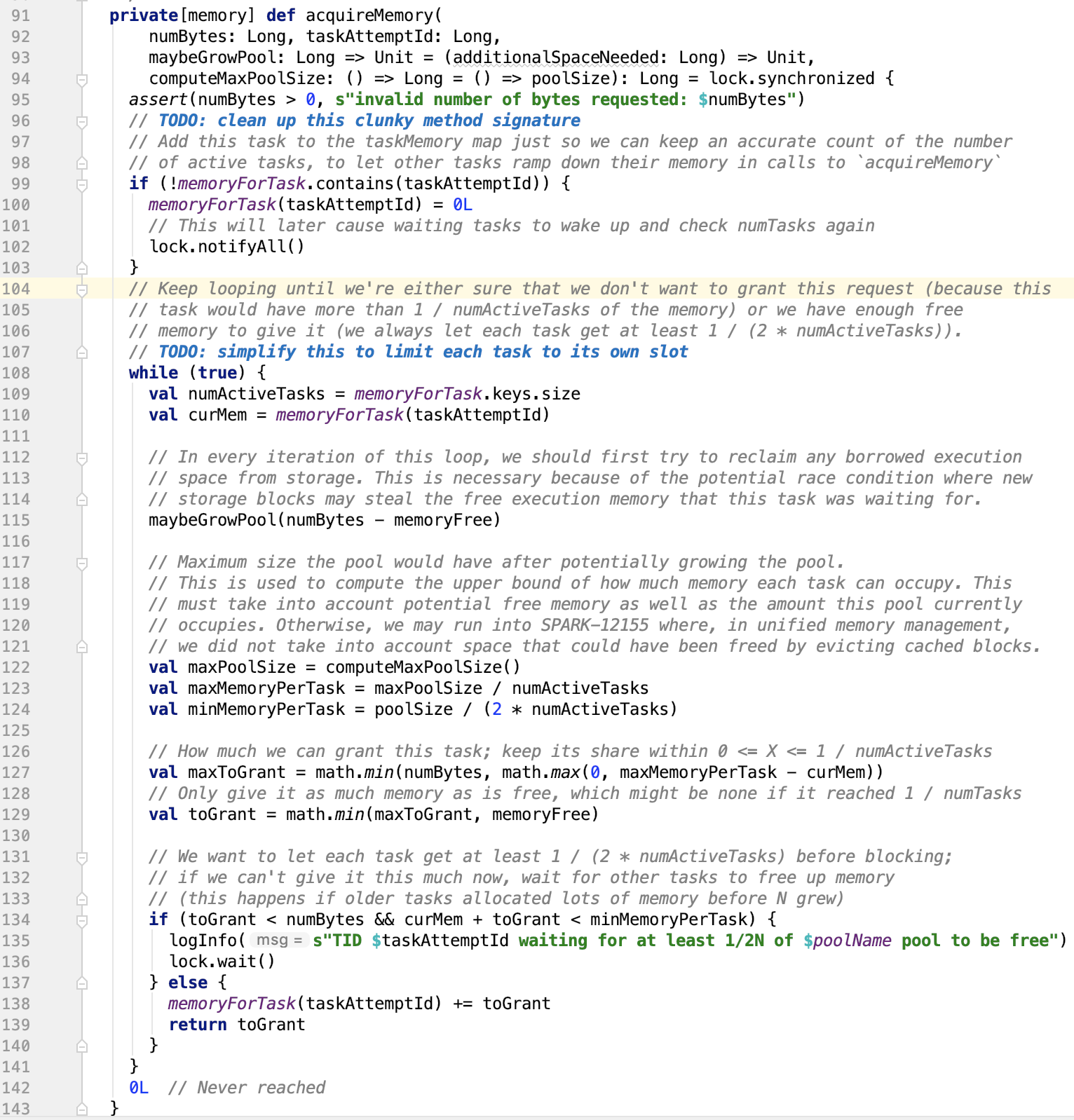
numBytes表示申请的内存大小(in byte),taskAttemptId 表示申请内存的 task id,maybeGrowPool 表示一个可能会增加执行池大小的回调。 它接受一个参数(Long),表示应该扩展此池的所需内存量。computeMaxPoolSize 表示在此给定时刻返回此池的最大允许大小的回调。这不是字段,因为在某些情况下最大池大小是可变的。 例如,在统一内存管理中,可以通过驱逐缓存块来扩展执行池,从而缩小存储池。
如果之前该任务没有申请过,则将(taskAttemptId <- 0) 放入到 memoryForTask map 中, 然后释放锁并唤醒lock锁等待区的线程。
被唤醒的因为synchronized实现的是一个互斥锁,所以当前仅当只有一个线程执行while循环。
首先根据 (需要的内存大小 - 池总空闲内存大小)来确认是否需要扩大池,由于存储池可能会偷执行池的内存,所以需要执行 maybeGrowPool 方法。
computeMaxPoolSize计算出此时该池允许的最大内存大小。然后分别算出每个任务最大分配内存和最小分配内存。进而计算出分配给该任务的最大分配大小(maxToGrant)和实际分配大小(toGrant)。
如果实际分配大小 小于需要分配的内存大小 并且 当前任务占有内存 + 实际分配内存 < 每个任务最小分配内存,则该线程进入锁wait区等待,等待内存可用时唤醒,否则将内存分配给任务。
可以看到这个方法中的wait和notify方法并不是成对的,因为新添加的taskAttemptId不能满足内存可用的条件。因为这个锁是从外部传过来的,即MemoryManager也可能对其做了操作,使内存空余下来,可供任务分配。
3. 释放task内存,源码如下:
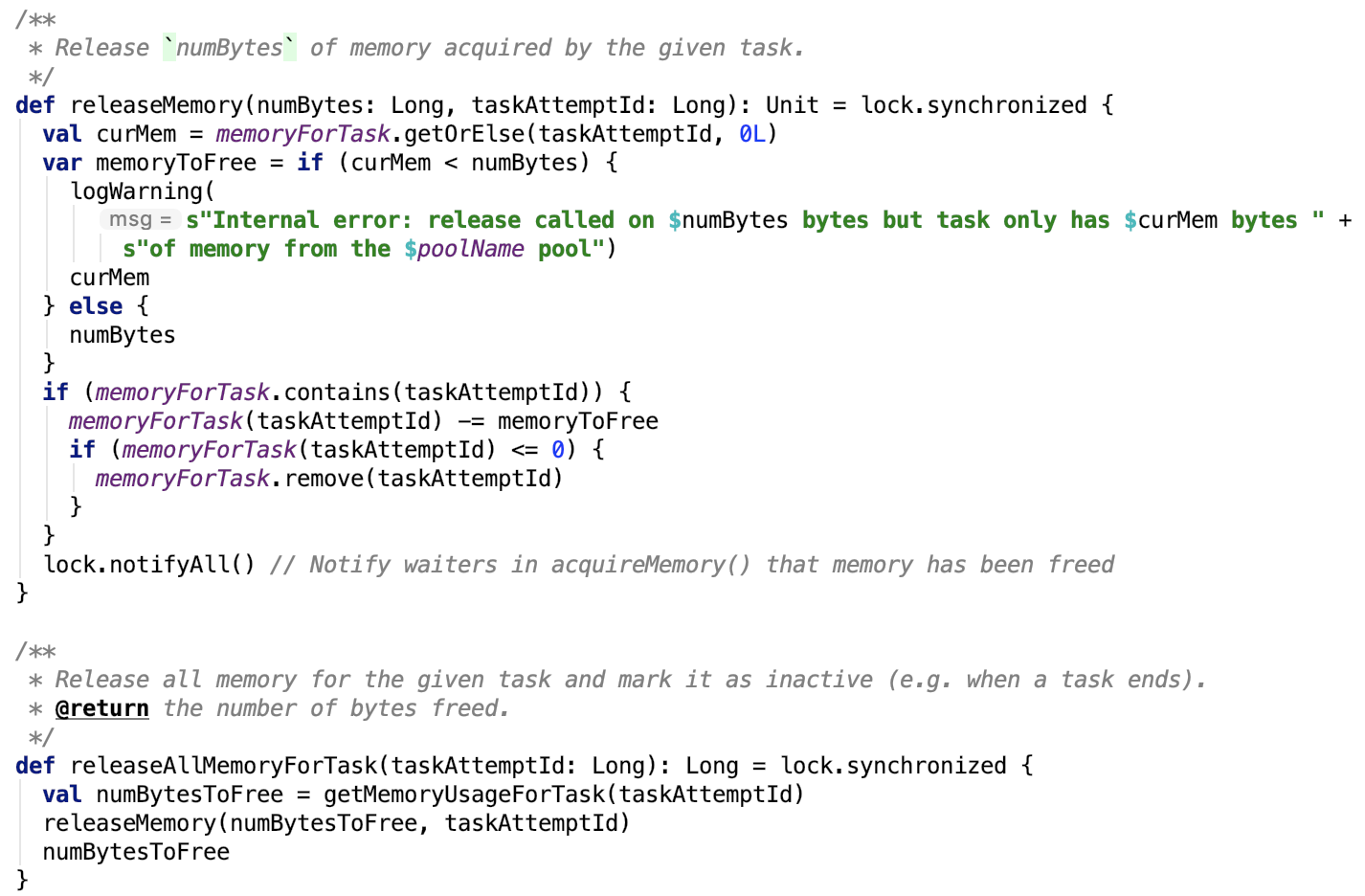
它有两个方法,分别是释放当前任务已经使用的所有内存空间 releaseAllMemoryForTask 和释放当前任务的指定大小的内存空间 releaseMemory。
思路:
releaseAllMemoryForTask 先计算好当前任务使用的全部内存,然后调用 releaseMemory 方法释放内存。
releaseMemory 方法则会比对当前使用内存和要释放的内存,如果要释放的内存大小小于 当前使用的 ,做减法即可。释放之后的任务内存如果小于等于0,则移除task即可,最后通知lock锁等待区的对象,让其重新分配内存。
在这个记账的实现里,每一个来的task不一定是可以分配到内存的,所以,锁在其中起了很大的资源协调的作用,也防止了内存的溢出。
MemoryManager
文档说明:
An abstract memory manager that enforces how memory is shared between execution and storage. In this context, execution memory refers to that used for computation in shuffles, joins, sorts and aggregations, while storage memory refers to that used for caching and propagating internal data across the cluster. There exists one MemoryManager per JVM.
一种抽象内存管理器,用于强制执行和存储之间共享内存的方式。在这个上下文下,执行内存是指用于在shuffle,join,sort和aggregation中进行计算的内存,而存储内存是指用于在群集中缓存和传播内部数据的内存。 每个JVM都有一个MemoryManager。
先来说一下其依赖的MemoryPool,源码如下:

MemoryPool中的lock对象就是MemoryManager对象
存储内存池和执行内存池分别有两个:堆内和堆外。
onHeapStorageMemory和onHeapExecutionMemory 是从构造方法传过来的,先不予考虑。
maxOffHeapMemory 默认是 0, 可以根据 spark.memory.offHeap.size 参数设置,文档对这个参数的说明如下:
The absolute amount of memory in bytes which can be used for off-heap allocation.
This setting has no impact on heap memory usage, so if your executors' total memory consumption must fit within some hard limit
then be sure to shrink your JVM heap size accordingly. This must be set to a positive value when spark.memory.offHeap.enabled=true.
存储堆外内存 = 最大堆外内存(offHeapStorageMemory) X 堆外存储内存占比,这个占比默认是0.5,可以根据 spark.memory.storageFraction 来调节
执行堆外内存 = 最大堆外内存 - 存储堆外内存
还有跟 Tungsten 管理内存有关的常量:

这三个常量分别定义了tungsten的内存形式、内存页大小和内存分配器。
其方法解释如下:
1. 获取存储池最大使用内存,抽象方法,待子类实现。

2. 获取已使用内存

3. 获取内存,这也是抽象方法,待子类实现

4. 释放内存

这些请求都委托给对应的MemoryPool来做了
1.6 之前 使用MemoryManager子类 StaticMemoryManager 来做内存管理。
StaticMemoryManager
这个静态内存管理中的执行池和存储池之间有严格的界限,两个池的大小永不改变。
注意:如果想使用这个内存管理方式,设置 spark.memory.useLegacyMode 为 true即可(默认是false)
下面我们重点看1.6 之后的默认使用的MemoryManager子类 -- UnifiedMemoryManager
UnifiedMemoryManager
先来看文档说明:

这个MemoryManager保证了存储池和执行池之间的软边界,即可以互相借用内存来满足彼此动态的内存需求变化。执行和存储的占比由 spark.memory.storageFraction 配置,默认是0.6,即偏向于存储池。其中存储池的默认占比是由 spark.memory.storageFraction 参数决定,默认是 0.5 ,即 存储池默认占比 = 0.6 * 0.5 = 0.3 ,即存储池默认占比为0.3。存储池可以尽可能多的向执行池借用空闲内存。但是当执行池需要它的内存的时候,会把一部分内存池的内存对象从内存中驱逐出,直到满足执行池的内存需求。类似地,执行池也可以尽可能地借用存储池中的空闲内存,不同的是,执行内存不会被存储池驱逐出内存,也就是说,缓存block时可能会因为执行池占用了大量的内存池不能释放导致缓存block失败,在这种情况下,新的block会根据StorageLevel做相应处理。
我们主要来看其实现的父类MemoryManager 的方法:
1. 获取存储池最大使用内存:

其中,maxHeapMemory 是从构造方法传进来的成员变量,maxOffHeapMemory 是根据参数 spark.memory.offHeap.size 配置生成的。
可以看出,存储池的允许的最大使用内存是实时变化的,因为总内存不变,执行池内存使用情况随任务执行情况变化而变化。
2. 获取内存,逐一来看:

实现思路:先根据存储方式(堆内还是堆外)确定存储池,执行池,存储区域内存大小和最大总内存。
然后调用执行池的 acquireMemory 方法申请内存,computeMaxExecutionPoolSize是随存储的实时变化而变化的,增大ExecutionPool的回调也被调用来确保有足够空间可供执行池分配。
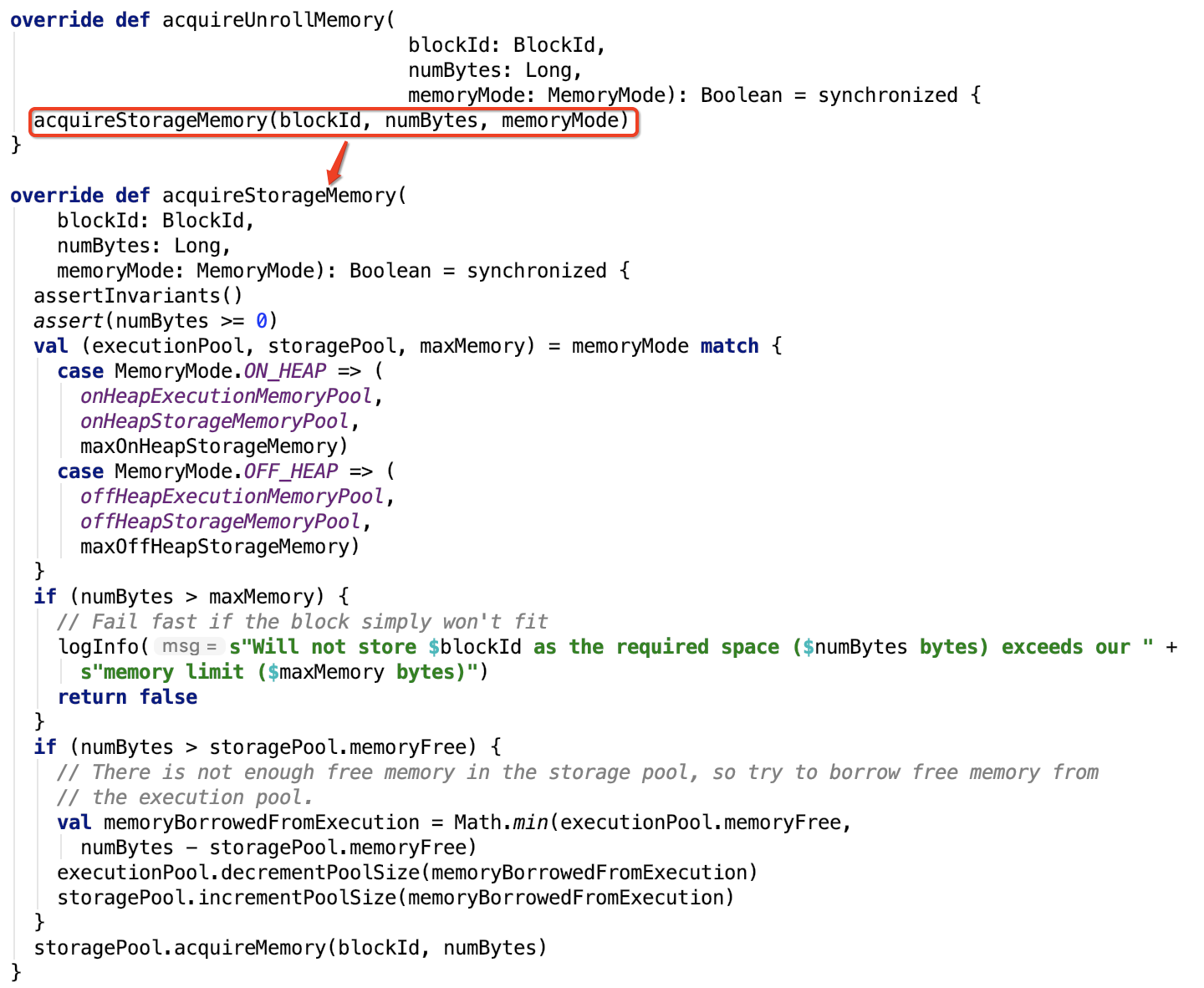
acquireUnrollMemory 直接调用 acquireStorageMemory 方法。
acquireStorageMemory实现思路:先根据存储方式(堆内还是堆外)确定存储池,执行池,存储区域内存大小和最大总内存。
存储内存如果大于最大内存,直接存储失败,否则,继续查看所需内存大小是否大于内存池最大空闲内存,如果大于,则从执行池中申请足够的空闲空间,注意,真正申请的空间大小在0 和numBytes - storagePool.memoryFree 之间,继续调用storagePool的acquireMemory 方法去申请内存,如果不够申请,则会驱逐出旧或空的block块。
最后,我们来看一下其伴生对象:

首先 apply 方法就类似于工厂方法的创造方法。我们对比下面的一张图,来说明一下Spark内存结构:
系统内存:可以根据 spark.testing.memory 参数来配置(主要用于测试),默认是JVM 的可以使用的最大内存。
保留内存:可以根据 spark.testing.reservedMemory 参数来配置(主要用于测试), 默认是 300M
最小系统内存:保留内存 * 1.5 后,再向下取整
系统内存的约束:系统内存必须大于最小保留内存,即 系统可用内存必须大于 450M, 可以通过 --driver-memory 或 spark.driver.memory 或 --executor-memory 或spark.executor.memory 来调节
可用内存 = 系统内存 - 保留内存
堆内内存占比默认是0.6, 可以根据 spark.memory.fraction 参数来调节
最大堆内内存 = 堆内可用内存 * 堆内内存占比
堆内内存存储池占比默认是 0.5 ,可以根据spark.memory.storageFraction 来调节。
默认堆内存储内存大小 = 最大堆内内存 * 堆内内存存储池占比。即堆内存储池内存大小默认是 (系统JVM最大可用内存 - 300M)* 0.6 * 0.5, 即约等于JVM最大可用内存的三分之一。
注意: 下图中的spark.memory.fraction是0.75,是Spark 1.6 的默认配置。在Spark 2.4.3 中默认是0.6。
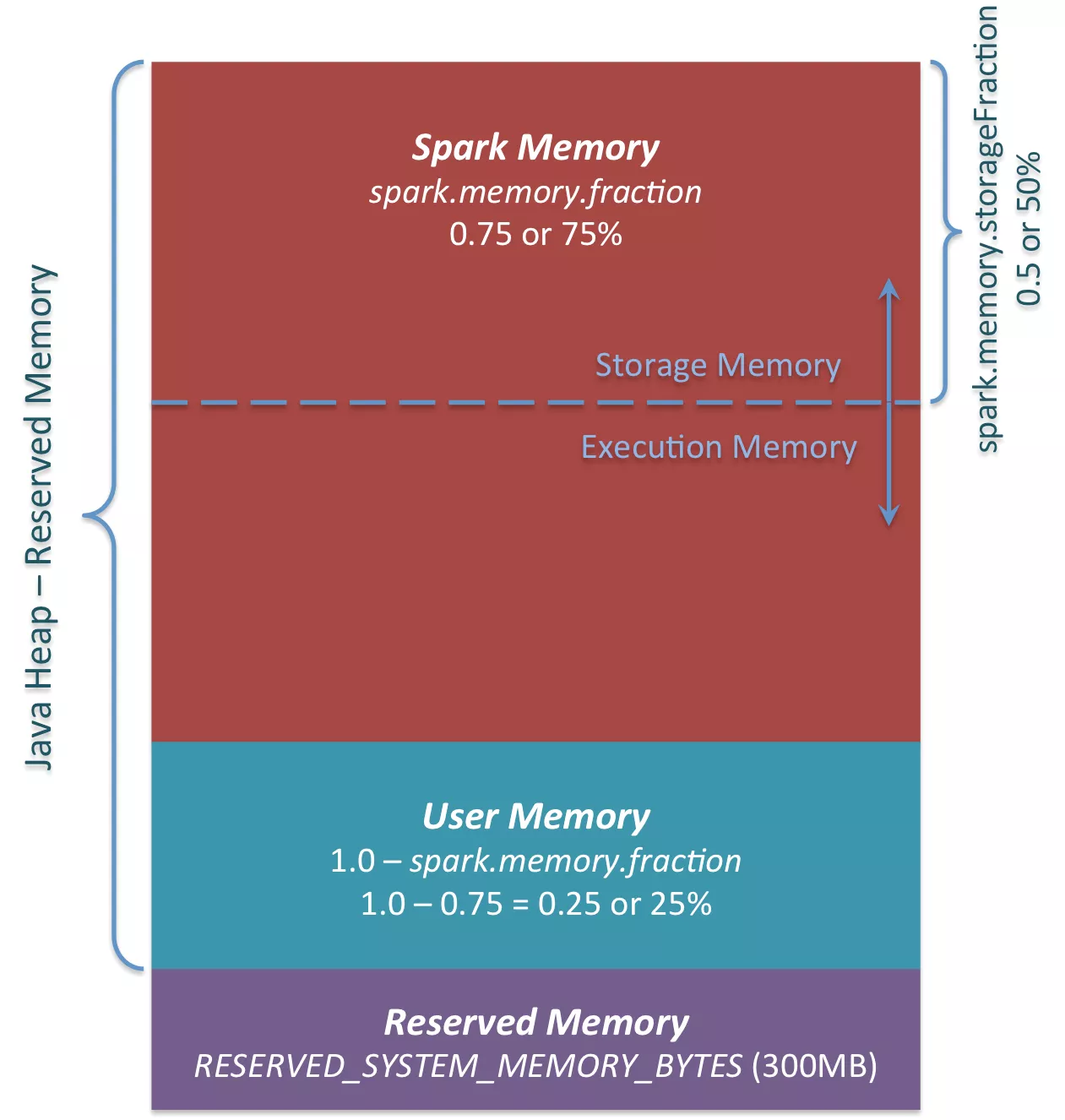
图片来源:https://0x0fff.com/spark-memory-management/
至此,Saprk 的内存管理模块基本上剖析完毕。
总结:先介绍了内存的管理池,即MemoryPool的实现,然后重点分析了Spark 1.6 以后的内存管理机制,着重说明Spark内部的内存是如何划分以及如何动态调整内存的。
注,关于堆内内存和堆外内存的介绍,可参照:https://www.jianshu.com/p/50be08b54bee