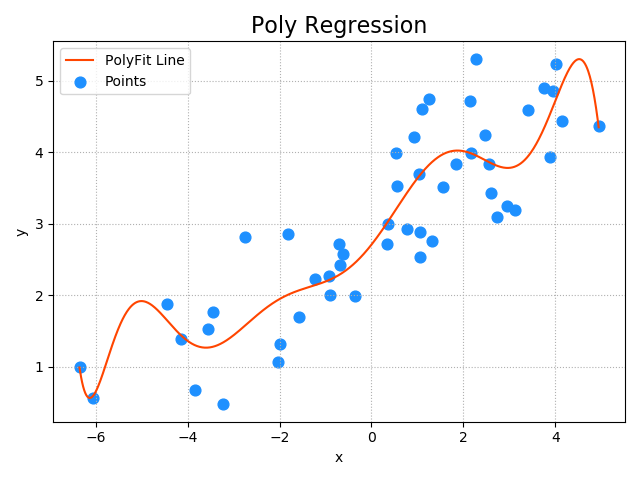
「」 ' 多項式回帰を:あなたはより良いトレーニングサンプルデータに合うように回帰モデルをしたい場合は、多項式回帰をされて使用することができます。 単変量多項式回帰: 数理モデル:Y = W 0 + W 1 * X ^ 1 + W2 * X ^ 2 + ... + WN * X N ^ 得られた長期特性の高次の項まで拡張と見ることができる: Y = W0 + W1 * X1 + W2 * X2 + ... + WN * XN 多重線形回帰モデルとして見ることができるので、多項式回帰は、線形回帰サンプルデータモデルのトレーニングを使用することができます。 :達成される単変量多項式回帰は、2つのステップが必要 1.(最大次数多項式にのみ与えられる)多項式回帰、多重線形回帰問題を変換します。 2.結果は、ステップ1多項式W1、W2、W3、...、で得られた WN 線形回帰、多変量線形モデルが訓練された、サンプル特性として。 そのモデルの適切な最大数は、線形回帰モデルスコアをR2よりも高いスコア数が高すぎると、上が存在するであろう選択-フィット、スコアは線形回帰スコアよりも低くなる 二つのステップによって提供される「データ線」sklearn実装を使用して実行順序: PL ASインポートsklearn.pipeline SPとしてインポートがsklearn.preprocessing インポートLM AS sklearn.linear_model = pl.make_pipelineモデル( #10:多項式の最高次数 sp.PolynomialFeatures(10)、#特性多項式パンダ lm.LinearRegression())#線形回帰の 過剰適合とunderfitting: 1.オーバーフィッティング:あまりにトレーニングデータのための複雑なモデルは、より良い精度を得ることができますが、精度は、この現象は、オーバーフィッティングと呼ばれ、テストデータのための一般的に低いです。 2. underfitting:あまりにも単純なモデル、両方のトレーニングデータやテストデータについては、十分に高い予測精度、underfittingと呼ばれる現象を与えることはできません。 3.学習モデルの性能は、トレーニングデータとテストデータの許容可能な予測精度であるべき接近しているが、精度が低すぎることはできません。 トレーニングはR2に設定R2テスト設定 0.3 0.4 underfitting:単純すぎるが、ルールはデータ反映していない 0.9 0.2オーバーフィッティング:あまりにも特別な、あまりにも複雑に、一般の欠如 許容0.6 0.7:適度な複雑さは、ルールデータの両方を反映して、一般性を失うことなくしながら、 データsingle.txtファイルをロードし、回帰モデルを訓練するために、多項式回帰アルゴリズムに基づいています。 ステップ: パッケージガイド---> ---は、モデルによって予測多項式回帰を作成---> ---予測モデルとトレーニング>得られpred_y、画像レンダリングの多項式関数>データを読み込む '「」 のインポートがPL AS sklearn.pipeline インポートsklearn LM .linear_modelのAS インポートsklearn.preprocessing SP AS インポートMP AS matplotlib.pyplot インポートNP AS numpyの インポートAS sklearn.metrics SM #の収集データ X、Y = np.loadtxt(' ./ml_data/single.txt '、DELIMITER = " 、'、usecols =(0 ,. 1)は、アンパック= TRUE) #の入力は、この線のような2次元配列の特徴となる Xのx.reshape =(-1 ,. 1 ) #は、モデルの作成 =モデルpl.make_pipeline( sp.PolynomialFeatures( 10)、 #多項式展開装置特徴 lm.LinearRegression() #の線形回帰 ) #のトレーニングモデル model.fit(X、Y) #は、予測値Yを決定 pred_y = model.predict(X)を #のモデル評価 印刷(' 絶対平均誤差:' 、sm.mean_absolute_error(Y、pred_y)) を印刷(' 平均二乗誤差:' 、sm.mean_squared_error(Y、pred_y)) を印刷(' 中央絶対エラー:' 、sm.median_absolute_error(Y、pred_y)) を印刷(「R2スコア:' 、Sm.r2_score(Y、pred_y)) #は、多項式回帰直線描画 PX = np.linspace(x.min()、x.max()1000 ) PX = px.reshape(-1 ,. 1 ) pred_py = モデル。 (PX)を予測 #描画画像 mp.figure(" ポリ回帰"、のFaceColor = ' LightGrayの' ) mp.title(' ポリ回帰'、のfontSize = 16 ) mp.tick_params(labelsize = 10 ) mp.grid(をlineStyle = ' :' ) mp.xlabel(' X ") mp.ylabel(' Y ' ) mp.scatter(X、Y、S = 60、マーカー= ' O '、C = ' ドジャーブルー'、ラベル= ' ポイント' ) mp.plot(PX、pred_py、C = ' オレンジレッド'ラベル= ' 関数polyfitライン" ) mp.tight_layout() mp.legend() mp.show() 出力: 絶対平均誤差: 0.4818952136579405は、 平均二乗誤差: 0.35240714067500095 中央絶対エラー: 0.47265950409692536 R2スコア: 0.7868629092058499を