MDPについての最後のポスト、私たちは、環境は5つの基本要素で構成されて知っています:
環境の状態空間。
環境が許すというアクションスペース。
遷移表:アクションが取られている別のからどのような環境状態に遷移する確率
報酬:アクションが取られており、環境の状態はエージェントが環境から受けることができますどのくらいの報酬、変更します。
γ:どのように時間によって割引を報います。
どのように異なるMDPとMRPの間:
キーワード:アクション
MDPの5つの要素は、緑色の円がオレンジ円がアクションであると、2つの報酬が存在する状態、された、以下のチャートによって示すことができます。MRPとマルコフ過程で、我々は直接遷移行列を知っています。しかしながら、ある状態から別の状態への遷移経路にアクションによってinteruptedれます。そして、それは環境が特定の状態にあるときに、アクションのための確率が存在しないことは注目に値します。その理由は非常に理解しやすいです:我々はいくつかの世界(環境)に住んでいるが、異なる人々が異なる動作を持っています。

エージェントとポリシー
エージェントは、強化学習における環境と対話する人やロボットです。人間と同じように、誰もが同じ条件で異なる動作を有することができます。異なる状態の下で行動の確率分布がポリシーです。そこ環境で非常に多くの確率がありますが、特定のエージェント(人)のために、彼または彼女は、特定の状態の下で1つまたはいくつかの可能な措置をとることがあります。状態を考えると、ポリシーは以下のように定義されています。
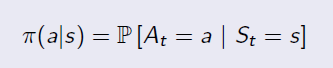
ポリシーの例を以下に示します。

MDPからMRPへ
遷移表:別のエージェントが行動を取るために、異なるprobabilitieを持っている可能性があるため、政策がなければ、我々はまさに、状態の移行からsの確率を知りません。限り、我々はπを取るにつれて、私たちは行動の期待を計算することができます。これは、以下のformalorによって定義されます。
This means we know the state transition matrix of a certain agent who adopts policy π. 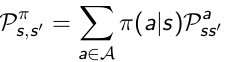
In the chart above, for example, if an agent has probabilitie 0.4 and 0.6 for action a0 and a1, the transition probability from s0 to s1 is: 0.4*0.5+0.6*1=0.8
Reward:
In MDP the reward function is related to actions, which average the uncertainties of the result from an action.
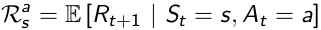
Once we've got the Policy π, we know the action distribution of a specific agent, so we can average the uncertaintie of actions, then measure how much immediate reward can receive from state s under policy π.

So now we go back from MDP to MRP, and the Markov Reward Process is defined by the tuple

Two Value Functions:
State Value Function:
State Value Function is the same as the value function in MRP. It is used to evaluate the goodness of being in a state s(by immedate and future reward), and the only difference is to average the uncertainty of actions under policy π. It is in the form of:
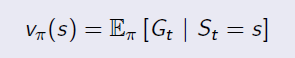
Action Value Function:
Action Value Function reveals whether an action is good or bad when an agent is in state s:

If we get expectation of Action Value Functions in the same state s, we will end up with the State Value Function v:
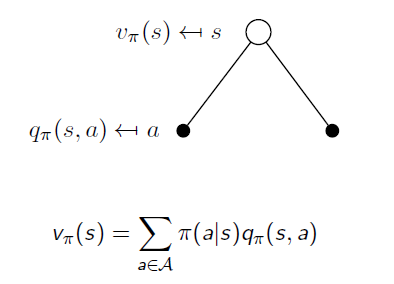
Similarly, when an action is taken, the system may end up with different states. When we remove the uncertainty of state transition, we go back from State Value Function to Action Value Function:
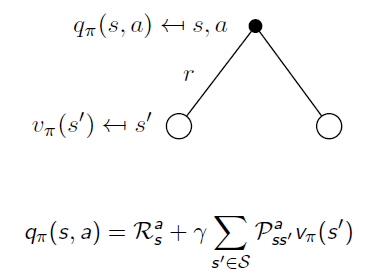
If we put them together:
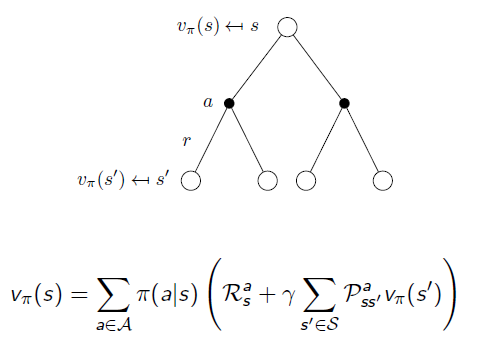
Another way:
